并行优化策略汇总
并行优化策略
数据并行(DP)
将数据集分散到m个设备中,进行训练。得到训练数据后在进行allreduce操作。确保每个worker都有相同模型参数。
整体流程如下

- 若干块计算GPU,如图中GPU0~GPU2;1块梯度收集GPU,如图中AllReduce操作所在GPU。
- 在每块计算GPU上都拷贝一份完整的模型参数。
- 把一份数据X均匀分给不同的计算GPU。
- 每块计算GPU做一轮FWD和BWD后,算得一份梯度G。
- 每块计算GPU将自己的梯度push给梯度收集GPU,做聚合操作。这里的聚合操作一般指梯度累加。当然也支持用户自定义。
- 梯度收集GPU聚合完毕后,计算GPU从它那pull下完整的梯度结果,用于更新模型参数W。更新完毕后,计算GPU上的模型参数依然保持一致。
- 聚合再下发梯度的操作,称为AllReduce
梯度异步更新

上图刻画了在梯度异步更新的场景下,某个Worker的计算顺序为:
- 在第10轮计算中,该Worker正常计算梯度,并向Server发送push&pull梯度请求。
- 但是,该Worker并不会实际等到把聚合梯度拿回来,更新完参数W后再做计算。而是直接拿旧的W,吃新的数据,继续第11轮的计算。这样就保证在通讯的时间里,Worker也在马不停蹄做计算,提升计算通讯比。
- 当然,异步也不能太过份。只计算梯度,不更新权重,那模型就无法收敛。图中刻画的是延迟为1的异步更新,也就是在开始第12轮对的计算时,必须保证W已经用第10、11轮的梯度做完2次更新了。
张量并行(TP)
它的基本思想就是把模型的参数纵向切开,放到不同的GPU上进行独立计算,然后再做聚合。
切分权重方式:
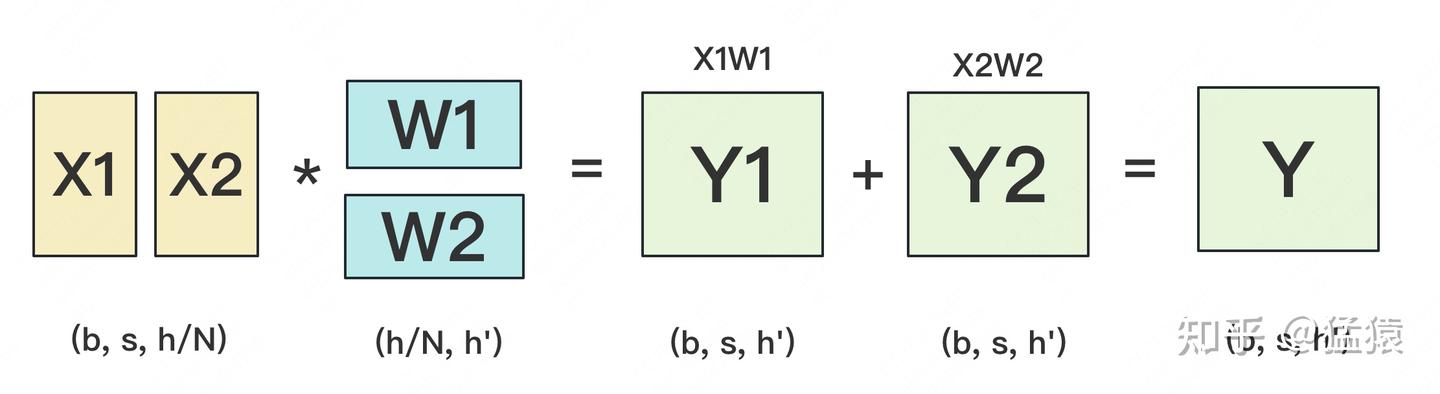
设输入数据为X,参数为W。X的维度 = (b, s, h),W的维度 = (h, h')。
横向
当GPU数量为2的时候,将权重分成2份,再将input按照h分开成2列即可做矩阵乘法。
反向传播时
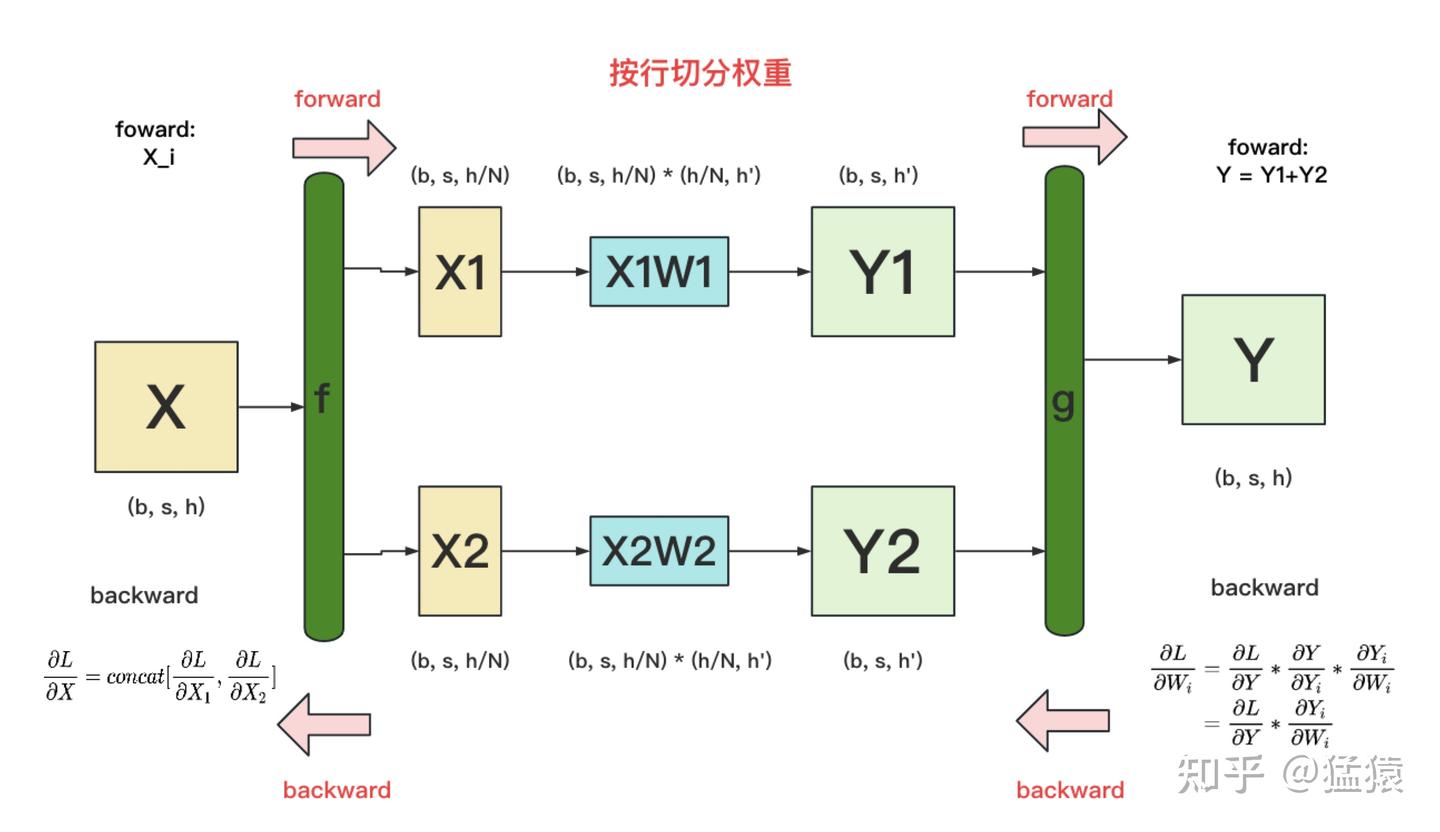
g 的 backward:
假定现在我们要对 W_i 求梯度,则可推导出:
因为
所以
=1
也就是说,只要把同时广播到两块 GPU 上,两块 GPU 就可以独立计算各自权重的梯度了。
f 的 backward:
在上图中,我们只画了模型其中一层的计算过程。当模型存在多层时,梯度要从上一层向下一层传播。例如图中,梯度要先传播到 X ,然后才能往下一层继续传递。这就是 f 的 backward 的作用。
这里也易推导出:
• 如果X被分解为多个子部分,则需要先对每个部分计算梯度。
• 最后,通过 concat 将这些分部分梯度拼接,得到输入 X 的整体梯度。
纵向
将w按照列切分

反向传播

f与g的区别
f与g都是算子
f层的作用
• 前向操作:
将输入 X 分成多个部分,分别通过不同的分支(如 XW1 和 XW2)。
• 反向传播:
梯度来自多个路径,需要相加汇总
表示在第i块gpu上计算x的梯度
g层的作用
• 前向操作:
合并多个分支结果(如将 Y1 和 Y2 拼接成 Y)。
• 反向传播:
梯度从整体拆分为各分支,分配到对应的输出:
Pipeline并行(PP)
将模型分成不同层,每层放到一块卡上。
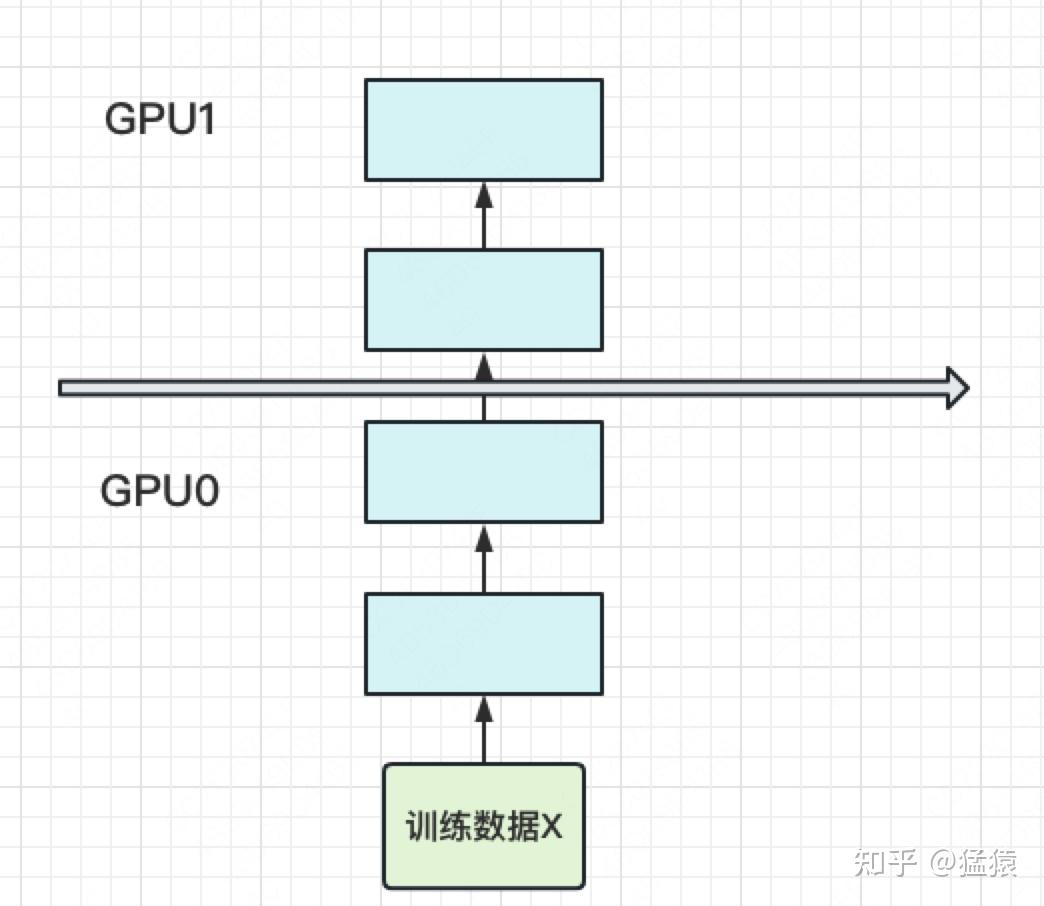
模型做forward和backward过程:
gpu0中做一次forward,然后数据传入到gpu1,然后gpu1处理完再传到gpu2.。。。
backward反过来即可。
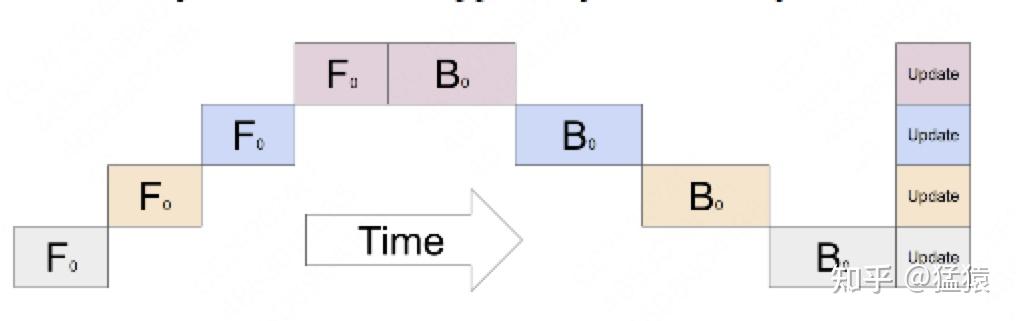
缺点就是利用率太低了
1) 当gpu数量越多,空闲的比例越大,gpu资源都浪费了。
2) 中间结果的内存占用量太大,当backwards的时候会使用forward时的中间结果,假如有n层模型,中间结要存n-1次。
GPipe
把原先的数据再划分成若干个batch,送入GPU进行训练。
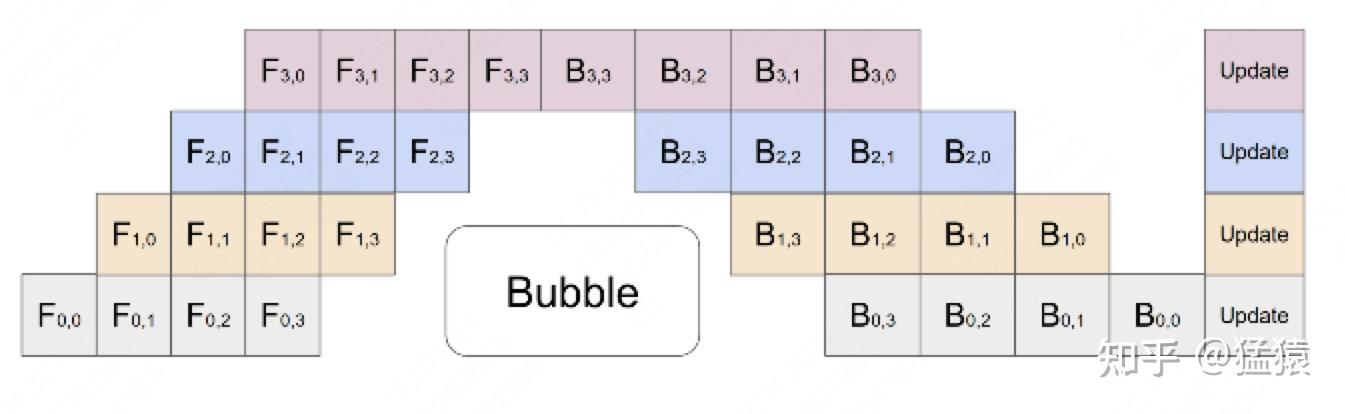
Gpipe通过实验证明,当 M>=4K 时,bubble产生的空转时间占比对最终训练时长影响是微小的,可以忽略不计。
内存问题:
1) 检查点机制
只保存上一块GPU的激活值,剩下的结果等backwards时再进行计算。
如何计算:使用上一块的激活值再执行一遍forward得到结果
2) PipeDream
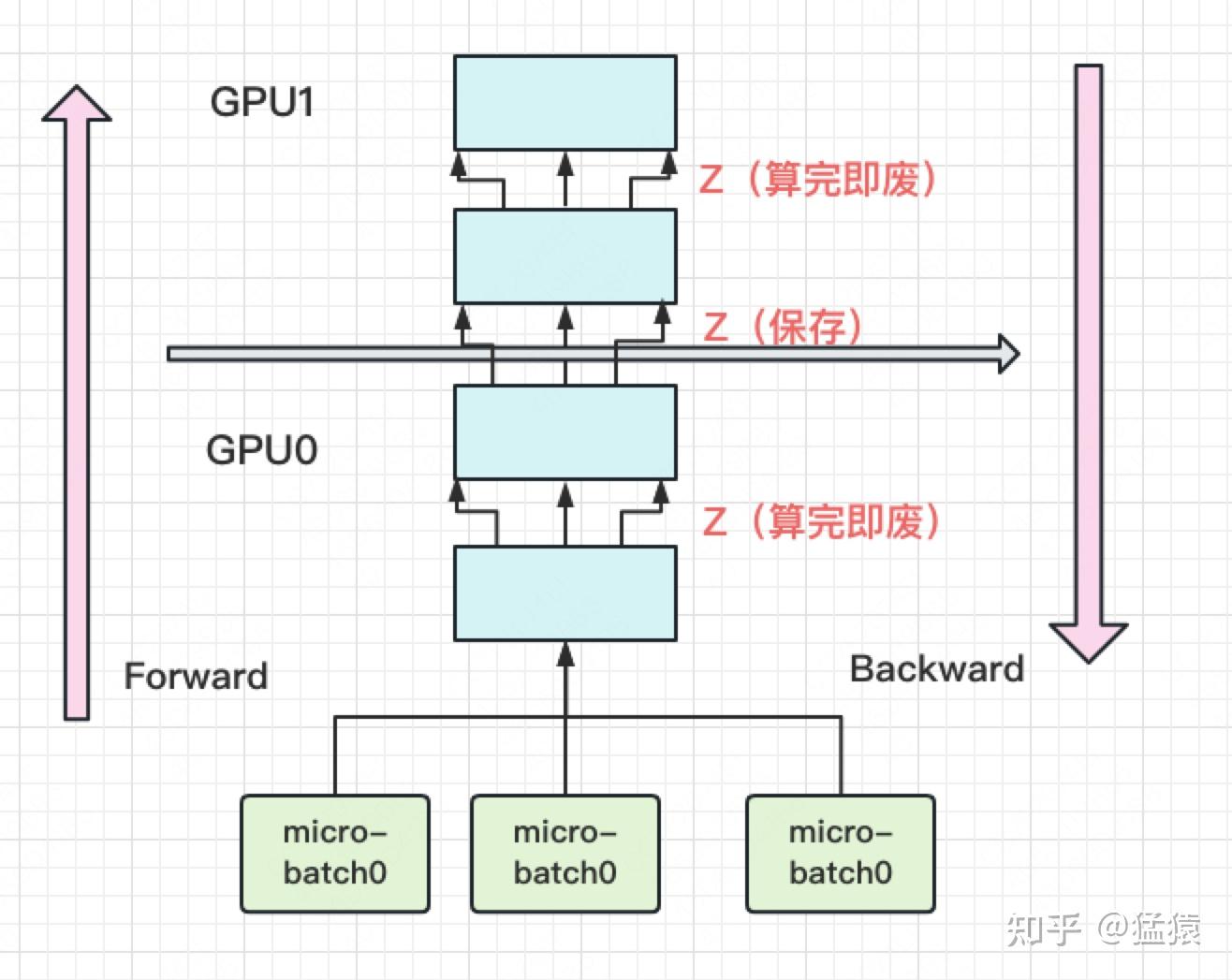
每块GPU峰值时刻存储大小 = 每块GPU上的输入数据大小 + 每块GPU在forward过程中的中间结果大小
使用Pytorch提供的pipeline接口,其中有一个参数叫checkpoint可以实现PP的检查点机制。
PipeDream
GPipe需要等所有的microbatch前向传播完成后,才会开始反向传播。PipeDream则是当一个microbatch的前向传播完成后,立即进入反向传播阶段。(1F1B)
PipeDream在bubbles上与GPipe没有区别,但是由于PipeDream释放显存的时间更早,因此会降低对显存的需求。

混合并行
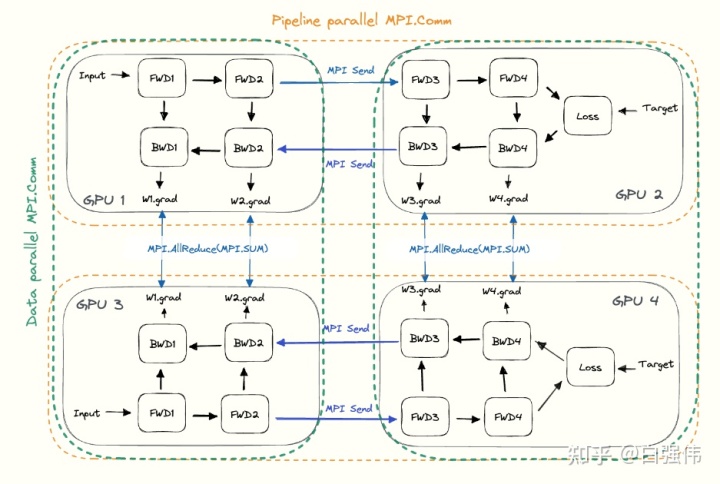
DP与PP并行
如图所示,GPU13 和GPU24 分别为两个子组,他们的参数相同,形成dp并行;
GPU12和GPU34分别组成一个完整的模型,形成了pp并行。
3D并行
3D并行是由DP、TP和PP组成。
例:
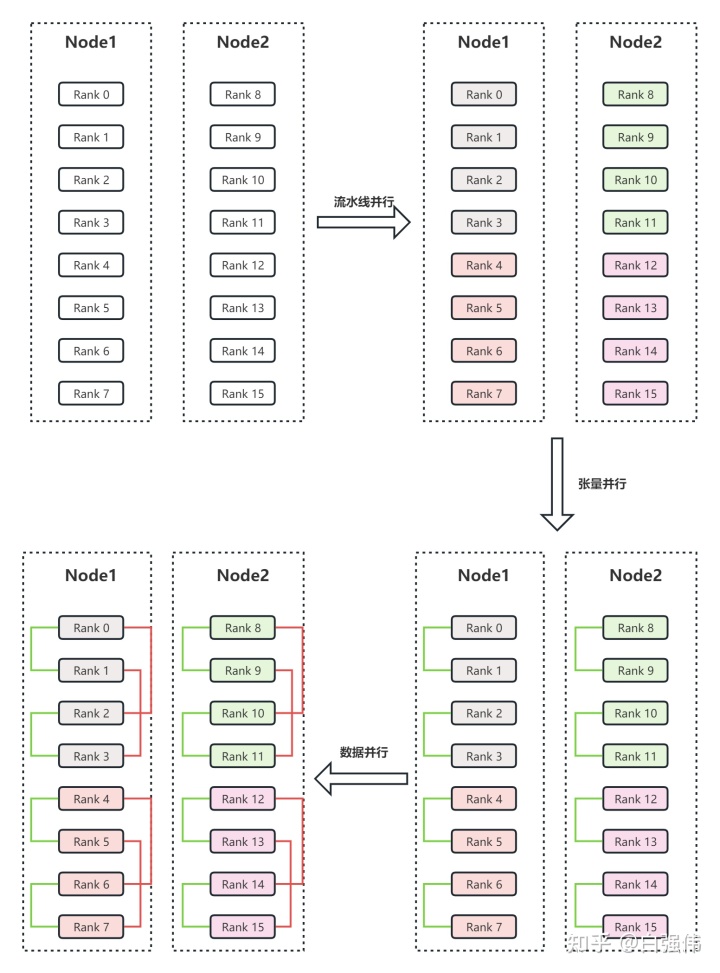
这个并行策略结合了 流水线并行、张量并行 和 数据并行,是一种高效利用多GPU的分布式训练方法。
1. 流水线并行
• 划分方式:
• 将整个模型分为 4 份( 至
)。
• 每连续的 4 张 GPU(颜色相同的rank) 负责一个子模型。
• 目的:
让不同的 GPU 分别负责模型的不同部分,以减小单 GPU 的计算压力,同时利用流水线方式提升吞吐量。
2. 张量并行
• 划分方式:
• 针对每个 ,再细分到多个 GPU 以并行计算单个张量。
• 每个 张量并行组 包含 2 个 GPU。
• 目的:
将张量的计算分散到多个 GPU 上,提高单个子模型的计算效率。
3. 数据并行
• 划分方式:
• 保证并行组中使用相同模型参数的 GPU 读取相同的数据。
• 例如,Rank0 和 Rank2 负责相同的参数,因此它们组成一个 数据并行组。
• 目的:
在不同设备上同步模型权重,保证参数一致性,支持大规模数据训练。
结果:
假设有 16 张 GPU(Rank0 到 Rank15):
• 流水线并行:每 4 张 GPU 分配到一个模型块。
• 张量并行:每 2 张 GPU 形成一个张量并行组。
• 数据并行:跨张量并行组同步相同参数的 GPU 形成数据并行组。
分析
3D并行需要平衡显存效率、计算效率和通信开销.
分配策略
1. 优先模型并行组放置在一个节点内:
• 原因:模型并行(包括张量并行和流水线并行)是三种策略中通信开销最大的。
• 策略:尽量将张量并行组安排在同一个节点内,以利用较大的节点内带宽,减少跨节点通信。
2. 流水线并行跨节点调度:
• 原因:流水线并行通信量最低,不会受限于较低的节点间带宽。
• 策略:流水线的不同分段可以分布在不同节点上。
3. 数据并行是否跨节点:
• 策略:
• 如果张量并行没有跨节点,则数据并行也不需要跨节点;
• 如果张量并行跨节点,则数据并行需要跨节点进行同步。
综合总结
• 显存效率:
• 流水线并行和张量并行通过任务拆分降低单 GPU 的显存需求;
• ZeRO-DP 进一步分布化存储优化器状态和梯度,进一步节省显存。
• 通信开销:
• 优先减少跨节点通信:将模型并行组(特别是张量并行组)优先安排在节点内。
• 流水线并行适合跨节点调度。
• 张量并行的设计决定了数据并行的通信需求,合理分配可以降低数据同步开销。
• 计算效率:
• 模型划分不宜过细,以避免通信开销过大。
• 数据并行结合 ZeRO 技术可以实现显存效率和通信效率的平衡。
参考
PS:看了猛猿答主的文章,非常厉害的up。知乎地址为:https://www.zhihu.com/people/lemonround
https://zhuanlan.zhihu.com/p/617133971
https://zhuanlan.zhihu.com/p/622212228
https://zhuanlan.zhihu.com/p/613196255



















