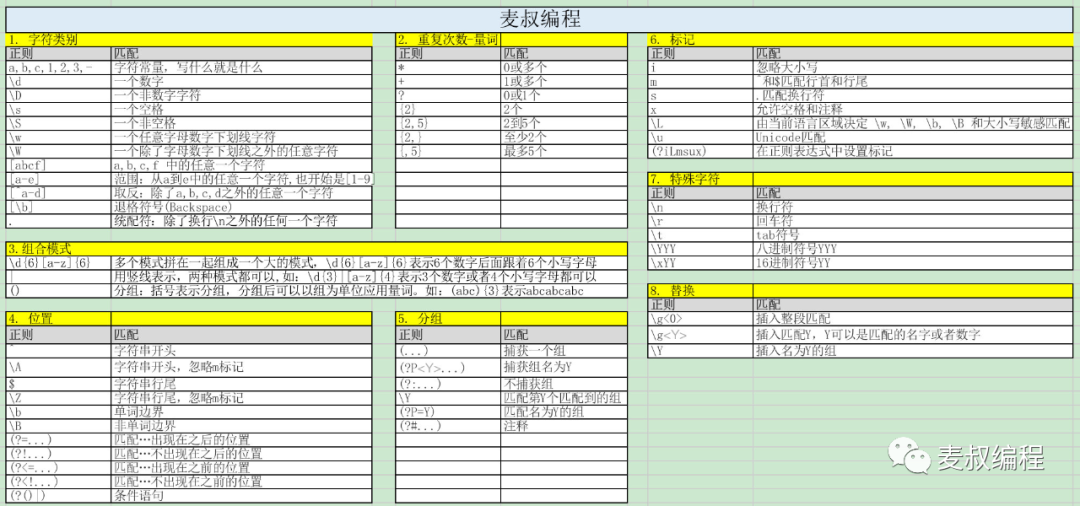
文章目录
- 一、数据汇聚概述
- 二、 汇聚数据类型
- 2.1 结构化数据
- 2.2 半结构化数据
- 2.3 非结构化数据
- 三、汇聚数据模式
- 四、汇聚数据方法
- 四、数据汇聚工具
- 五、数据汇聚使用经验
数据小伙伴们,之前咱们长篇大论的聊聊过【数据中台建设方法论从0到1】,从数据中台建设的概念,建设理论,到数据中台支撑技术,以及开源解决方案。因此今天嘛,就阐述数据中台的数据汇聚吧,也算是整个平台的入口。
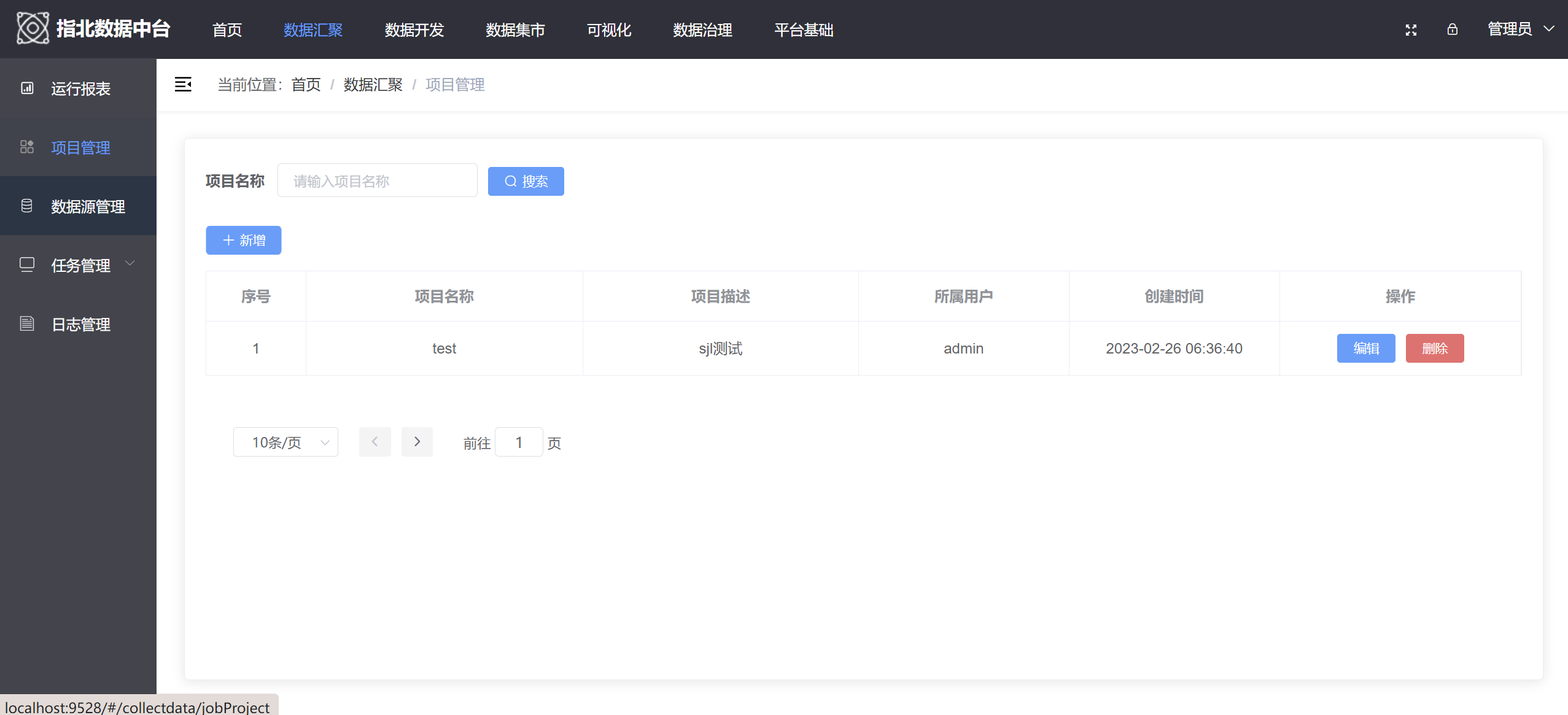
核心:构建企业级数据中台的第一步就是解决数据的流通问题。
一、数据汇聚概述
数据汇聚和数据采集虽然看似相似,但实际上它们有不同的目的和实施方式。数据采集是一种主动的数据生产过程,涉及到通过合适的方法记录终端对象的业务流程信息,并借助中间系统进行数据流转,最终写入目标存储系统中。

而数据汇聚则是从另一个维度来考虑的问题,它关注的是已存在数据的迁移与同步,即通过一定的手段将一个数据源中的数据搬运到另一个数据源上,这个过程有时也被称作“数据集成”。因此,企业可以根据需要汇聚的数据类型以及数据模式等因素,选择合适的数据汇聚工具。
二、 汇聚数据类型
2.1 结构化数据
可以用二维数据库表来抽象,抽取数据规律。以数据库数据和文本数据为结构化数据。简单来说就是关系型数据库里的表数据。
2.2 半结构化数据
介于结构化和非结构化之间,主要指XML、HTML、JSON文档、Email等等,也可称非结构化。

2.3 非结构化数据
指信息没有一个预先定义好的数据模型或者没有以一个预先定义的方式来组织,不可用二维表抽象,比如图片,图像,音频,视频等 。
三、汇聚数据模式
数据汇聚的形式有两种,分别是离线和实时。这两种模式不仅影响着数据处理的效率,还关系到系统能够支持的数据量级和业务逻辑的复杂度。
因此,在进行系统设计时,我们需要根据实际需求选择合适的数据汇聚方式,以确保系统既能满足当前的需求,也能适应未来的扩展性。
离线:
这种模式主要用于大批量数据的周期性转移,对实时性的要求并不高。通常采用分布式批量数据同步的技术,通过数据库连接读取数据。读数据的方式有全量和增量两种,先进行统一处理,然后将数据写入到目标存储系统中。
实时:
主要针对低时延的数据应用场景,通常采用增量日志或通知消息的方式进行数据传输。例如,可以通过读取数据库的操作日志(如redo log、binlog)来实现实时的数据处理需求。
四、汇聚数据方法
由于不同的数据汇聚需求、硬件成本及网络带宽要求,可以选择ETL或ELT这两种汇集数据的方法。ETL代表提取-转换-加载,而ELT则为提取-加载-转换,这种方式可以根据实际业务需要灵活选择,以达到更好的数据处理效果。
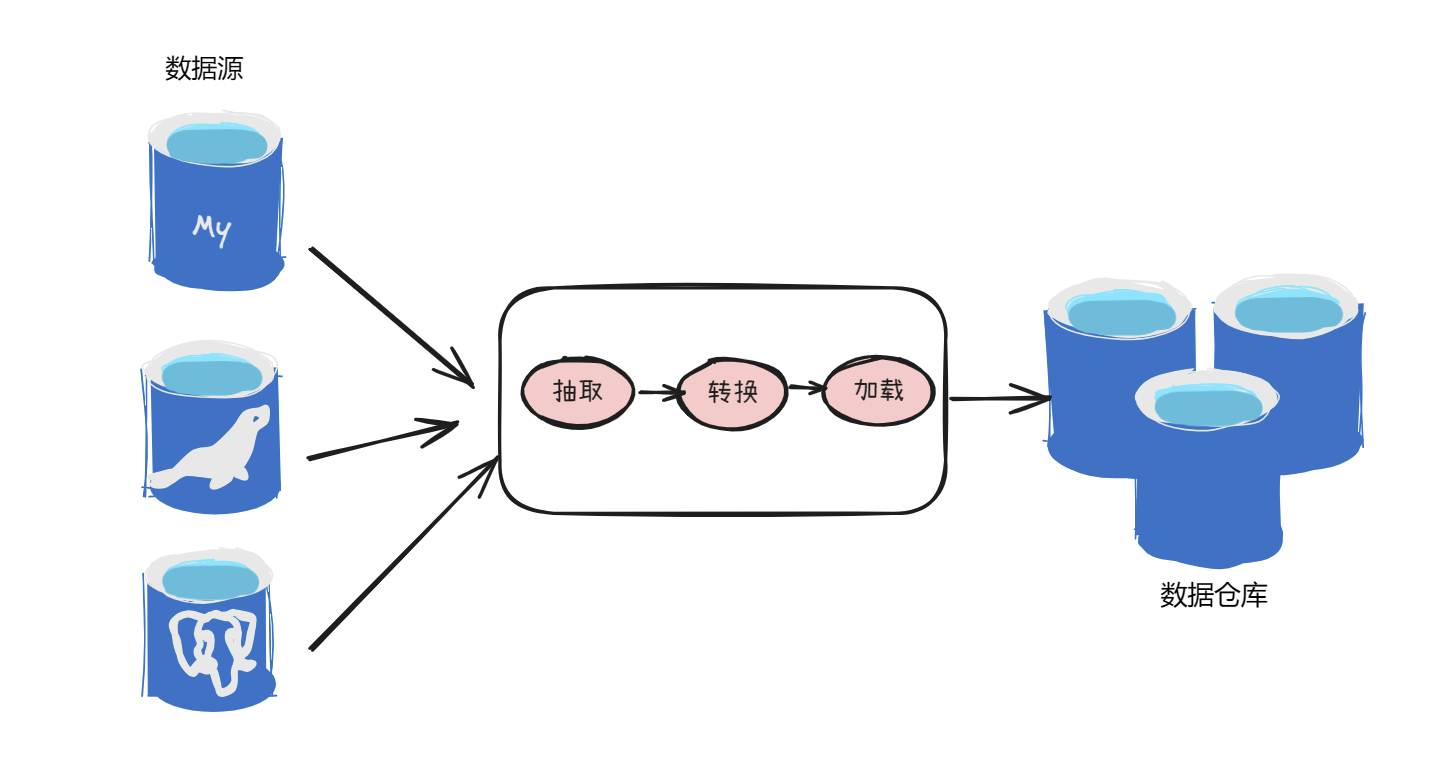
ETL是将业务系统的数据抽取到一个中间数据库里,在里面经过各种规则的转换之后,装载到数据仓库的过程。目的是将分散、凌乱、标准不统一的数据整合到一起,帮助企业将沉睡的数据最大价值利用起来。
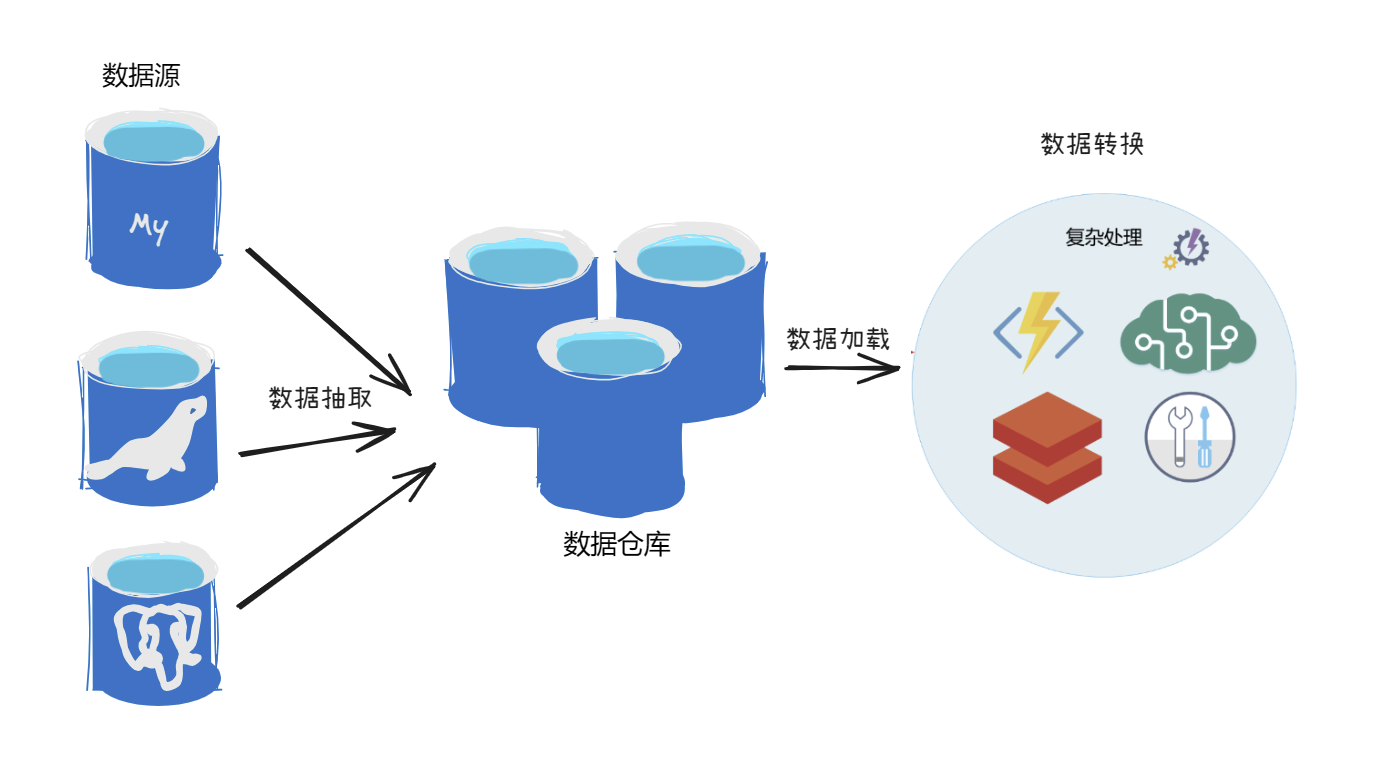
ELT是将数据抽取并装载到目的端,利用目的端的数据处理能力,完成数据转换工作。通常越大量的数据、复杂的转换逻辑、目的端为较强运算能力的数据库,越偏向使用ELT,以便运用目的端数据库的处理能力。这种方法更适合大规模数据场景,它将数据抽取后直接加载到存储系统中,再通过大数据和人工智能相关技术对数据进行清洗与处理。在数据存储成本越来越低廉、数据量越来越庞大的今天,ELT是更好的选择。
四、数据汇聚工具
多源异构数据采集的大数据技术栈,目前广泛的是 Sqoop、Datax、Flink CDC、Canal等。
离线模式:
(1)sqoop

SQL–to–Hadoop。正如 Sqoop 的名字所示,主要用于在 Hadoop、Hive 与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
(2)Datax
阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。

实时模式:
(1)FlinkCDC(重点)
FlinkCDC是一个基于Apache Flink开发的开源项目,主要用于从各种数据库中捕获实时数据变更(CDC)。该项目通过集成Debezium组件,实现了对MySQL、PostgreSQL、Oracle、MongoDB等主流数据库的支持。
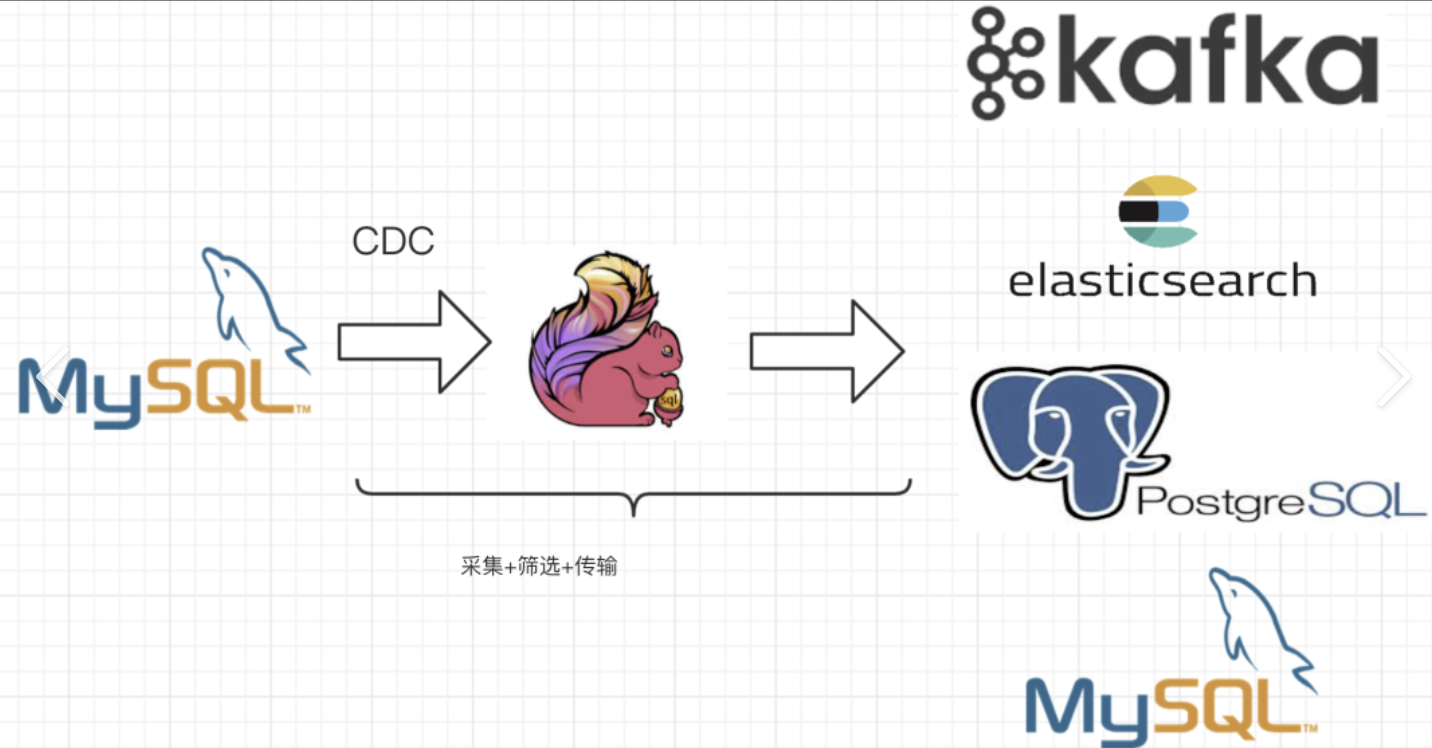
FlinkCDC的工作流程大致可以分为以下几个步骤:
- 数据监听
FlinkCDC在源数据库上配置监听器,实时监控数据库中的变更事件。这些变更事件包括数据的插入、更新和删除操作。
- 日志读取
当数据库中的数据发生变化时,这些变更会被记录在数据库的日志中。FlinkCDC通过读取这些日志,获取到数据变更的详细信息。
- 数据转换
FlinkCDC将捕获到的数据变更转换为Flink可以处理的流式数据格式,并将其发送到Flink计算引擎中进行进一步的处理。
- 数据传输
这些转换后的数据流可以被实时地传输到下游系统,如消息队列(例如Kafka)或其他存储系统,供其他服务订阅和消费。
FlinkCDC的优势在于其能够高效地捕获和处理海量数据的实时变更,同时支持全量和增量数据同步。此外,FlinkCDC避免了传统基于查询的CDC方式可能带来的延迟和数据库负载增加的问题。通过结合Flink计算框架,FlinkCDC能够实现低延迟、高吞吐的数据集成和处理。
(2) Canal

Canal 是一个由阿里巴巴开发并开源的中间件,主要用于实时捕获 MySQL 数据库中的增量数据变更。它通过模拟 MySQL slave 的交互协议,订阅 MySQL 的 binlog 日志,并解析这些日志以捕获表级别的增量数据变化。
总结表格:
| 特性 | Sqoop | Datax | Flink CDC | Canal |
|---|---|---|---|---|
| 定义 | 用于在Hadoop与传统数据库间进行数据传递。 | 阿里巴巴开源的异构数据源离线同步工具。 | 用于捕获数据库变更并将变更实时写入到下游系统。 | 基于数据库增量日志解析,提供增量数据订阅&消费的中间件。 |
| 用途 | 将关系型数据库中的数据导入到Hadoop的HDFS中,或从HDFS导入到关系型数据库中。 | 实现包括关系型数据库、HDFS、Hive、ODPS、HBase、FTP等异构数据源之间的数据同步。 | 捕获数据库的变更事件,并将这些变更实时输出到Flink的DataStream中。 | 实时采集MySQL中变化的数据,并将修改的数据写到消息队列供实时计算框架使用。 |
| 架构 | 通过Sqoop任务翻译器将命令转换为MapReduce任务,完成数据的拷贝。 | Framework + plugin架构,Reader负责数据采集,Writer负责数据写入,Framework负责传输。 | 深度定制了Flink DataStream的算子链路,Source模块负责生产变更事件。 | 主要支持MySQL的Binlog解析,解析完成后利用Canal Client来处理获得的相关数据。 |
| 特点 | 依赖于Hadoop生态,对HDFS、Hive支持友善,处理数仓大表速度快,但不具备统计和校验能力。 | 无法分布式部署,可以在传输过程中进行过滤,支持统计传输数据信息,适用于业务场景复杂的情况。 | 把表结构变更信息当成事件流转,有效提高数据流转效率。 | 采集日志,支持多种数据库的Binlog解析,适用于实时数据同步。 |
| 支持的数据源 | 支持MySQL、Oracle等传统数据库到Hadoop的HDFS、Hive的数据传递。 | 支持MySQL、Oracle、HDFS、Hive、ODPS、HBase、FTP等多种数据源。 | 支持多种数据库,如MySQL、PostgreSQL、SQL Server等。 | 主要支持MySQL数据库。 |
| 部署方式 | 单机部署,依赖调度系统实现多客户端。 | 单机部署,需要依赖调度系统实现多客户端。 | 支持分布式部署,可以并发读取。 | 支持分布式部署,可以作为独立的服务运行。 |
五、数据汇聚使用经验
在数据平台的离线模式中,通常使用DataX进行数据迁移,因为它支持多种通用的数据源类型。然而,随着数据国产化趋势的出现,需要对DataX的源码进行二次开发,特别是针对像kingbase,达梦这样的国产数据库,编写相应的读写插件。对于实时模式,FlinkCDC同样需要定制化的连接器来处理数据流的传输与转换。之前的工作经验中,涉及从视频和图片数据库中获取数据,以支持算法模型的在线请求与分析任务。