来源:B站/麦叔编程

1. 正则表达式的7个境界
假设有一段文字:
text = '身高:178,体重:168,学号:123456,密码:9527'
要确定文本中是否包含数字123456,我们可以用in运算符,也可以使用index函数:
text = '身高:178,体重:168,学号:123456,密码:9527'
target = '123456'
if target in text:
print('找到了')
print(text.index(target))
"""
找到了
17
"""
但当问题变得复杂的时候,比如找出字符串中所有数字,用基本的字符串处理就不行了。
这不再是一个固定的字符串匹配问题,而是一个模式,一种规则的匹配。为了解决这个问题,有位叫Stephen的大神在1951年提出了正则表达式。
几乎任何一门通用编程语言都有专门的正则表达式的模块,正则表达式英文是regular expressesion,所以编程语言中的模块名字一般叫re,或者regex等。Python中的正则表达式处理模块是re。
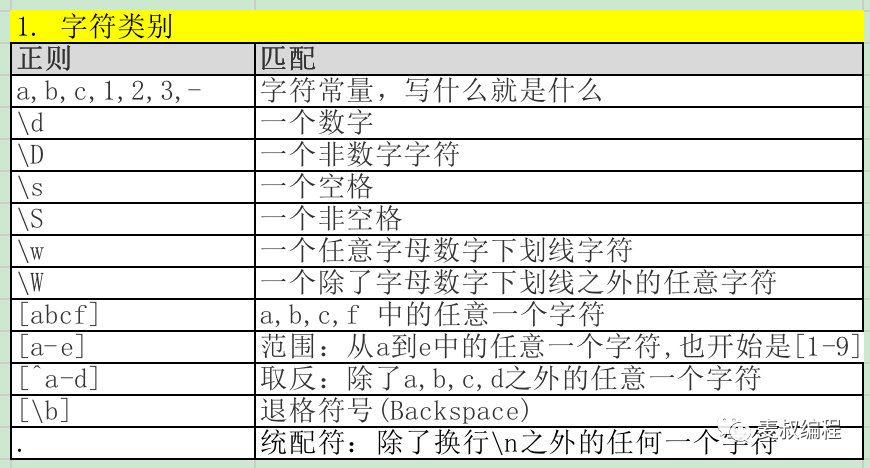
正则表达式就是为了找到符合某种模式的字符串,这些模式包括:是什么字符,重复多少次,在什么位置,有哪些额外的约束。请注意:这里的每一句话都对应了正则表达式中的一类语法。
下面我们通过8个例子,来熟悉正则表达式,后面再讲写正则表达式的套路和正则表达式的语法。
level1 - 固定的字符串(传统方法)
要求:确定字符串中是否有123456
import re
text = '麦叔身高:178,体重:168,学号:123456,密码:9527'
print(re.findall(r'123456', text))
代码说明:
- 第1行,引入正则表达式模块re
- 第3行,使用re的findall()方法找到所有符合模式的字符串,这里的模式就是123456,也就是说找到字符串中所有的123456。
- findall()方法的第1个参数是模式,第2个参数是要查找的字符串。
- 模式中会有一些特殊字符,所以用r表示这是一个raw字符串,让Python不要去转义里面的特殊字符。
上面程序的运行结果是:[123456],因为整个字符串中就1个123456。
level1就是一个固定的字符串匹配,可以用传统的字符串匹配解决。
level2 - 某一类字符
要求:找出所有的单个的数字
import re
text = '麦叔身高:178,体重:168,学号:123456,密码:9527'
print(re.findall(r'\d', text))
# ['1', '7', '8', '1', '6', '8', '1', '2', '3', '4', '5', '6', '9', '5', '2', '7']
这个表达式\d表示所有的数字,所以1,7,8,1,6,8等都可以匹配到。这是很简单的模式,只匹配1个单独的数字。
level3 - 重复某一类字符__\d+
要求:找所有的数字,比如178,168,123456,9527等。
text = '麦叔身高:178,体重:168,学号:123456,密码:9527'
print(re.findall(r'\d+', text))
# ['178', '168', '123456', '9527']
这个模式\d+在\d的后面增加了+号,表示数字可以出现1到多次,所以178等都符合它的要求。
leve4 - 组合level2_组合范围__{范围}
要求:找出座机号码
text = '麦叔电话是18812345678,他还有一个电话号码是18887654321,他爱好的数字是01234567891,他的座机是:0571-52152166'
print(re.findall(r'\d{4}-\d{8}', text))
# ['0571-52152166']
\d{4}-\d{8}这是一个组合的模式,表示前面4个数字,中间一个横杠,后面8个数字。
这里会匹配一个结果:0571-52152166
\d{3,4}可以表示匹配3位或者4为等等
text = '麦叔电话是18812345678,他还有一个电话号码是18887654321,他爱好的数字是01234567891,他的座机是:0571-52152166,他的对象座机是:571-2152166'
print(re.findall(r'\d{3,4}-\d{7,8}', text))
# ['0571-52152166', '571-2152166']
leve5 - 多种情况__或者___|
要求:找出手机号码或者座机号码
text = '麦叔电话是18812345678,他还有一个电话号码是18887654321,他爱好的数字是01234567891,他的座机是:0571-52152166'
print(re.findall(r'\d{4}-\d{8}|1\d{10}', text))
['18812345678', '18887654321', '0571-52152166']
比上面有复杂了点,因为使用竖线(|)来表示”或“的关系,就是手机号码和电话号码都可以。
这里会匹配三个结果:18812345678,18887654321,0571-52152166。
level6 - 限定位置____头尾
要求:在句子开头的手机号码,或座机
text = '18812345678,他还有一个电话号码是18887654321,他爱好的数字是01234567891,他的座机是:0571-52152166'
print(re.findall(r'^1\d{10}|^\d{4}-\d{8}', text))
在表达式的最开始使用了^符号,表示一定要在句子的开头才行。这时候只有18812345678能匹配上。
text = '18812345678,他还有一个电话号码是18887654321,他爱好的数字是01234567891,他的座机是:0571-52152166,他的对象座机是:0876-52152166'
print(re.findall(r'^1\d{10}|0876-\d{8}', text))
#['18812345678', '0876-52152166']
-
^:匹配字符串的开始。 -
$:匹配字符串的结束。^在[]里面是取反,在外面是头部
level7 - 内部约束
要求:找出形如barbar, dardar的前后三个字母重复的字符串
text = 'barbar carcar harhel'
print(re.findall(r'(\w{3})(\1)', text))
#[('bar', 'bar'), ('car', 'car')]
这里barbar和carcar会匹配上,但harhel不会被匹配,因为它不是3个字符重复的。
\w{3}表示3个字符,放在小括号中(\w{3})就成为一个分组,而后面的(\1)表示它里面的内容和第1个括号里的内容必须相同,其中的1就表示第1个括号,也就是说3个字符要重复出现两次。
2. 写正则表达式的步骤
如何写正则表达式呢?我总结了几个步骤。不管多复杂,基本上都百试不爽。
我们仍然以包含分机号码的座机电话号码为例,比如0571-88776655-9527,演示下面的步骤:
-
确定模式包含几个子模式
它包含3个子模式:0571-88776655-9527。这3个子模式用固定字符连接。
-
各个部分的字符分类是什么
这3个子模式都是数字类型,可以用\d。现在可以写出模式为:
\d-\d-\d -
各个子模式如何重复
第1个子模式重复3到4次,因为有010和021等直辖市
第2个子模式重复7到8次,有的地区只有7位电话号码
第3个子模式重复3-4次
加上次数限制后,模式成为:
\d{3,4}-\d{7,8}-\d{3,4}但有的座机没有分机号,所以我们用或运算符让它支持两者:
\d{3,4}-\d{7,8}-\d{3,4}|\d{3,4}-\d{7,8} -
是否有外部位置限制
没有
-
是否有内部制约关系
没有
经过一通分析,最后的正则就写成了,测试一下:
import re
text = '随机数字:01234567891,座机1:0571-52152166,座机2:0571-52152188-1234'
print(re.findall(r'\d{3,4}-\d{7,8}-\d{3,4}|\d{3,4}-\d{7,8}', text))
#['0571-52152166', '0571-52152188-1234']
最后的结果是:两个座机都可以找出来。
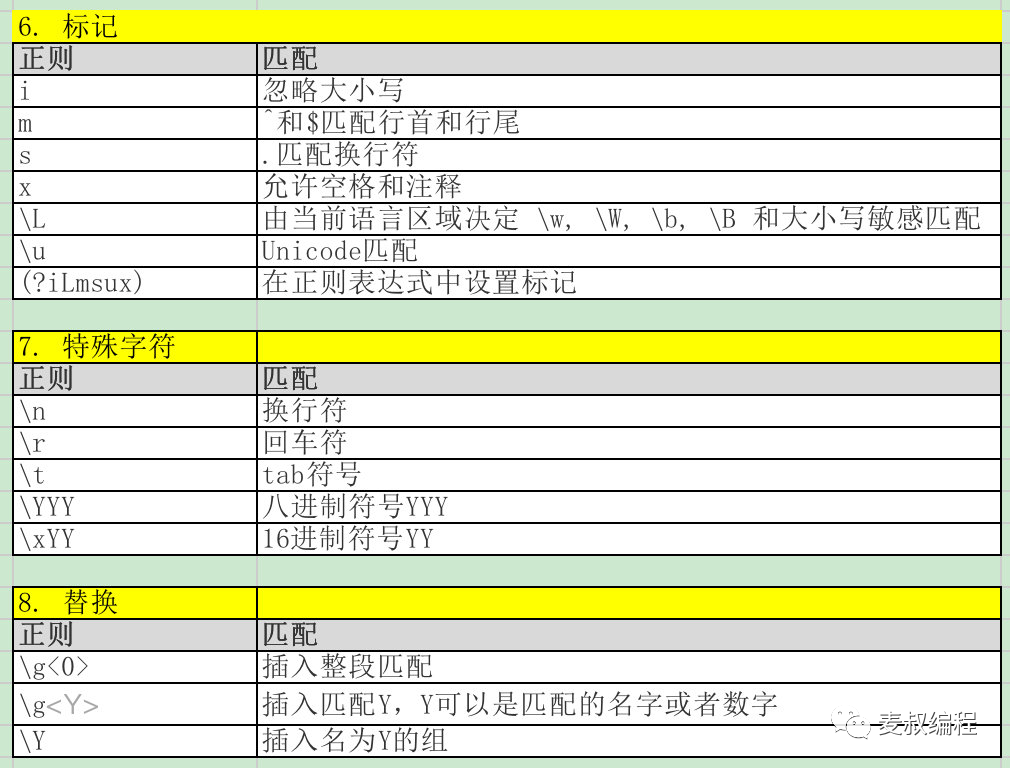
3. 语法规则
正则表达式几十个符号,看似很复杂,但如果能否分清楚类别和作用,就没那么复杂了。
- 字符类别表达 - 表达某一类字符,比如数字,字母,3到9之间的任何数字等
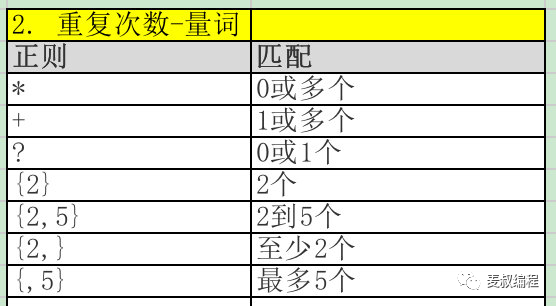
- 字符的重复次数,也叫做量词。比如身份证是数字重复15或18次,也就是:\d{15}或者\d{18}。
-
组合模式:把多个简单的模式组合在一起,可以是拼接,也可以是二者选其一。

-
位置:限定模式出现的位置,比如行首,行尾,或者在特定字符之后等。
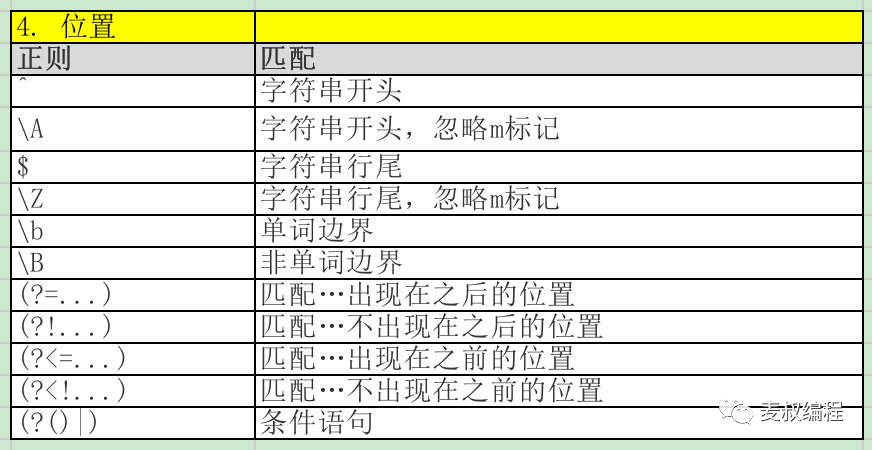
-
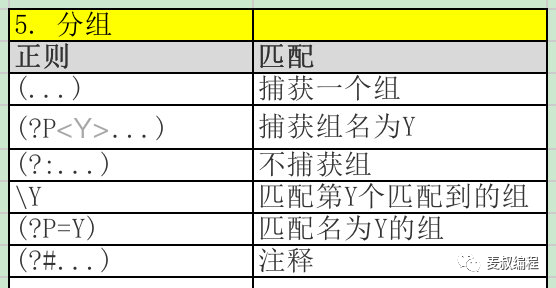
分组,把一个正则表达式分成几个部分,这样可以重复某个分组,或者指定两个分组必须相同等额外的要求。
1. ^: 匹配字符串的开头
^ 符号用来匹配字符串的开头。它确保匹配的模式从字符串的最开始位置开始。
代码示例:
import re
text = "Hello World!"
pattern = "^Hello"
# 使用 re.match 检查字符串是否以 "Hello" 开头
result = re.match(pattern, text)
if result:
print("Match found:", result.group())
else:
print("No match found")
输出:
Match found: Hello
2. $: 匹配字符串的结尾
$ 符号用来匹配字符串的结尾。它确保匹配的模式在字符串的最后位置结束。
代码示例:
import re
text = "Hello World!"
pattern = "World!$"
# 使用 re.match 检查字符串是否以 "World!" 结尾
result = re.match(pattern, text)
if result:
print("Match found:", result.group())
else:
print("No match found")
输出:
No match found
解释: re.match 只检查字符串的开头,所以我们需要使用 re.search 来检查整个字符串。
import re
text = "Hello World!"
pattern = "World!$"
# 使用 re.search 检查字符串是否以 "World!" 结尾
result = re.search(pattern, text)
if result:
print("Match found:", result.group())
else:
print("No match found")
输出:
Match found: World!
3. \b: 单词边界
\b 符号用来匹配单词的边界,即单词的开始或结束位置。
代码示例:
import re
text = "Hello World!"
pattern = r"\bWorld\b"
# 使用 re.search 检查 "World" 是否作为一个完整的单词出现
result = re.search(pattern, text)
if result:
print("Match found:", result.group())
else:
print("No match found")
输出:
Match found: World
4. \B: 非单词边界
\B 符号用来匹配非单词边界,即不在单词的开始或结束位置。
代码示例:
import re
text = "HelloWorld"
pattern = r"\BWorld\B"
# 使用 re.search 检查 "World" 是否不在单词的边界
result = re.search(pattern, text)
if result:
print("Match found:", result.group())
else:
print("No match found")
输出:
Match found: World
5. (?=...): 前向肯定预查
(?=...) 用来匹配某个模式后面紧跟着另一个模式,但不包括后面的模式。
代码示例:
import re
text = "HelloWorld"
pattern = r"Hel(?=lo)"
# 使用 re.search 检查 "Hel" 后面是否紧跟着 "lo"
result = re.search(pattern, text)
if result:
print("Match found:", result.group())
else:
print("No match found")
输出:
Match found: Hel
6. (?!...): 前向否定预查
(?!...) 用来匹配某个模式后面不紧跟着另一个模式。
代码示例:
import re
text = "HelloWorld"
pattern = r"Hel(?!lo)"
# 使用 re.search 检查 "Hel" 后面不紧跟着 "lo"
result = re.search(pattern, text)
if result:
print("Match found:", result.group())
else:
print("No match found")
输出:
No match found
7. (?<=...): 后向肯定预查
(?<=...) 用来匹配某个模式前面紧跟着另一个模式,但不包括前面的模式。
代码示例:
import re
text = "HelloWorld"
pattern = r"(?<=Hel)lo"
# 使用 re.search 检查 "lo" 前面是否紧跟着 "Hel"
result = re.search(pattern, text)
if result:
print("Match found:", result.group())
else:
print("No match found")
输出:
Match found: lo
8. (?<!...): 后向否定预查
(?<!...) 用来匹配某个模式前面不紧跟着另一个模式。
代码示例:
import re
text = "HelloWorld"
pattern = r"(?<!Hel)lo"
# 使用 re.search 检查 "lo" 前面不紧跟着 "Hel"
result = re.search(pattern, text)
if result:
print("Match found:", result.group())
else:
print("No match found")
输出:
No match found
- 其他:
4. Python正则模块re的用法
python的re模块还比较简单,包括以下几个方法:
- re.search():查找符合模式的字符,只返回第一个,返回Match对象
- re.match():和search一样,但要求必须从字符串开头匹配
- re.findall():返回所有匹配的字符串列表
- re.finditer():返回一个迭代器,其中包含所有的匹配,也就是Match对象
- re.sub():替换匹配的字符串,返回替换完成的文本
- re.subn():替换匹配的字符串,返回替换完成的文本和替换的次数
- re.split():用匹配表达式的字符串做分隔符分割原字符串
- re.compile():把正则表达式编译成一个对象,方便后面使用

5. 更多例子
下面我举了更多的例子,供大家练习和熟悉。
建议先自己尝试去写出相关的正则表达式,再回来看下面的参考答案。
- 匹配Email地址的正则表达式
- 匹配网址URL的正则表达式
- 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线)
- 匹配国内电话号码(0571-87655322,001-87666622,920-209642-964)
- 匹配腾讯qq号
- 匹配中国邮政编码(6位数字)
- 匹配身份证(15位或18位)
- 匹配ip地址
- 形如"carcar"或"barbar"等会重复的三个字符的单词
分隔符
现在来看参考答案:
-
匹配Email地址的正则表达式:
\w+([-+.]\w+)*@\w+([-.]\w+)*.\w+([-.]\w+)* -
匹配网址URL的正则表达式:
[a-zA-z]+://[^s]* -
匹配帐号是否合法(字母开头,允许5-16字母,允许字母数字下划线):
^[a-zA-Z][a-zA-Z0-9_]{4,15}$ -
匹配国内电话号码,格式为:区号-号码-分机号,分机号可能没有。
d{3,4}-d{7,8}-d{3,4}|d{3,4}-d{7,8} -
匹配腾讯qq号:
[1-9][0-9]{4,} -
匹配中国邮政编码(6位数字):
[1-9]\d{5}(?!\d) -
匹配身份证(15位或18位):
\d{15}|\d{18} -
匹配ip地址:
\d+.\d+.\d+.\d+ -
形如"carcar"或"barbar"等会重复的三个字符的单词
(\w{3})(\1) -
获取以"密码:"开头的数字:
(?<=密码.)\d+
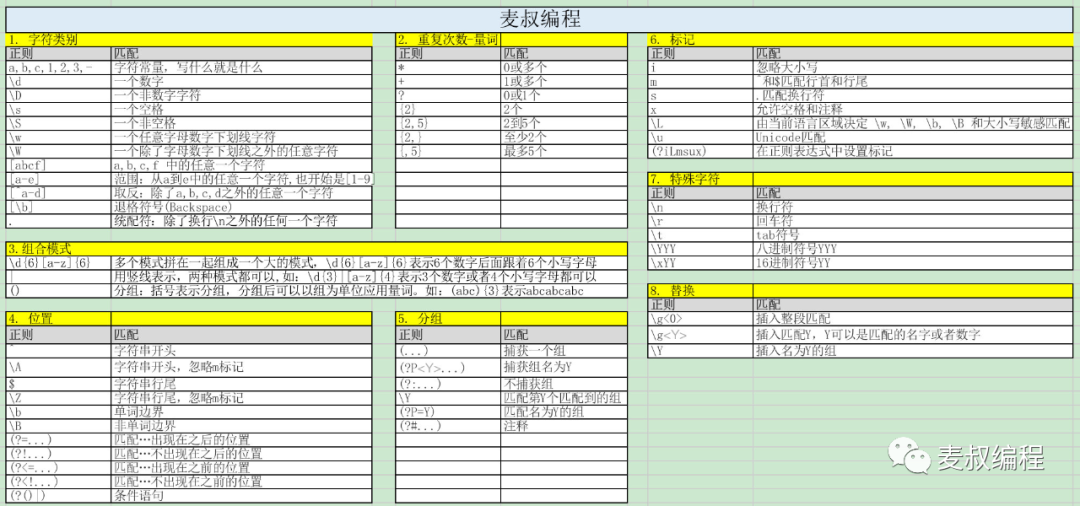
6. 正则表达式Cheatsheet
7.实例
匹配Email地址
-
正则表达式:
^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$ -
示例:
import re email = "example@example.com" pattern = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$' if re.match(pattern, email): print("Valid email") else: print("Invalid email")
^- 这个符号表示字符串的开始。确保整个字符串从这里定义的模式开始。[a-zA-Z0-9_.+-]+- 这是一个字符集,匹配一个或多个(由+号指定)以下任何字符:a-z表示所有小写字母。A-Z表示所有大写字母。0-9表示所有数字。_.+-表示下划线、点、加号和减号。这些通常用于电子邮件地址的用户名部分。
@- 直接匹配 '@' 符号。在电子邮件地址中,'@' 是用来分隔用户名和域名的部分。[a-zA-Z0-9-]+- 又是一个字符集,匹配一个或多个以下任何字符:a-z和A-Z再次代表所有字母。0-9代表所有数字。-代表连字符。这允许域名中使用连字符。
\.- 匹配实际的点字符(.)。由于点在正则表达式中有特殊含义(可以匹配除换行符外的任意单个字符),所以需要通过反斜杠(\)进行转义,以匹配实际的点字符。[a-zA-Z0-9-.]+- 这个字符集匹配一个或多个以下任何字符:a-z和A-Z代表所有字母。0-9代表所有数字。-和.代表连字符和点。这些字符允许出现在顶级域名(如 .com, .net, .info 等)中。
$- 这个符号表示字符串的结束。确保整个字符串以这里定义的模式结束。
匹配网址URL
-
正则表达式:
^https?://[^\s/$.?#].[^\s]*$ -
示例:
url = "https://www.example.com" pattern = r'^https?://[^\s/$.?#].[^\s]*$' if re.match(pattern, url): print("Valid URL") else: print("Invalid URL")
^- 匹配字符串的开始位置,确保匹配是从字符串的开头开始的。https?://- 这部分匹配HTTP或HTTPS协议的开始部分。http匹配固定的 "http" 字符串。s?匹配零个或一个 "s" 字符,因此可以匹配 "http" 或 "https"。://匹配固定的 "😕/" 字符串,这是URL中协议和主机名之间的分隔符。
[^\s/$.?#]- 这是一个否定字符集,匹配除了空格、斜杠/、美元符号$、问号?、点.和井号#之外的任何一个字符。[^\s...]中的^在方括号内表示“不包含”,即匹配不在括号内的任何字符。- 这个部分确保URL的开始部分不是以这些特殊字符之一开始。
[^\s]*- 这个部分匹配零个或多个非空格字符。[^\s]否定字符集,匹配任何非空格字符。*表示前面的模式可以出现零次或多次。
$- 匹配字符串的结束位置,确保整个字符串都符合上述模式。
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线)
-
正则表达式:
^[a-zA-Z][a-zA-Z0-9_]{4,15}$ -
示例:
username = "user123" pattern = r'^[a-zA-Z][a-zA-Z0-9_]{4,15}$' if re.match(pattern, username): print("Valid username") else: print("Invalid username")
^- 匹配字符串的开始位置,确保整个字符串从这里定义的模式开始。[a-zA-Z]- 匹配一个字母(大写或小写)。这意味着字符串的第一个字符必须是字母。[a-zA-Z0-9_]{4,15}- 这是一个字符集,匹配4到15个以下任何字符:a-z表示所有小写字母。A-Z表示所有大写字母。0-9表示所有数字。_表示下划线。{4,15}指定了前面的字符集必须出现4到15次。
$- 匹配字符串的结束位置,确保整个字符串以这里定义的模式结束。
- 有效:
user1234User_Namea1b2c3d4e5Username123
- 无效:
1user(第一个字符不是字母)user(长度不足5个字符)this_is_a_very_long_username(长度超过16个字符)user name(包含空格)
这个正则表达式通常用于验证用户输入的用户名,确保其符合一定的格式要求
匹配国内电话号码(0571-87655322,001-87666622,920-209642-964)
-
正则表达式:
^(0\d{2,3}-\d{7,8}|00\d{2}-\d{7,8}|0\d{2,3}-\d{7,8}-\d{4})$ -
示例:
phone = "0571-87655322" pattern = r'^(0\d{2,3}-\d{7,8}|00\d{2}-\d{7,8}|0\d{2,3}-\d{7,8}-\d{4})$' if re.match(pattern, phone): print("Valid phone number") else: print("Invalid phone number")
这个正则表达式用于匹配中国电话号码的不同格式,包括固定电话和长途电话。让我们逐部分解析这个正则表达式:
^- 匹配字符串的开始位置,确保整个字符串从这里定义的模式开始。( ... | ... | ... )- 这是一个选择结构,表示匹配其中的任何一个子模式。这里有三个子模式,分别对应不同的电话号码格式。
第一个子模式:0\d{2,3}-\d{7,8}
0- 匹配一个固定的 "0" 字符,表示本地固定电话的区号前缀。\d{2,3}- 匹配2到3个数字,表示区号。-- 匹配一个固定的 "-" 字符,用作分隔符。\d{7,8}- 匹配7到8个数字,表示电话号码的主体部分。
第二个子模式:00\d{2}-\d{7,8}
00- 匹配两个固定的 "0" 字符,表示国际长途电话的前缀。\d{2}- 匹配2个数字,表示国家代码。-- 匹配一个固定的 "-" 字符,用作分隔符。\d{7,8}- 匹配7到8个数字,表示电话号码的主体部分。
第三个子模式:0\d{2,3}-\d{7,8}-\d{4}
0- 匹配一个固定的 "0" 字符,表示本地固定电话的区号前缀。\d{2,3}- 匹配2到3个数字,表示区号。-- 匹配一个固定的 "-" 字符,用作分隔符。\d{7,8}- 匹配7到8个数字,表示电话号码的主体部分。-- 匹配一个固定的 "-" 字符,用作分隔符。\d{4}- 匹配4个数字,表示分机号。
$- 匹配字符串的结束位置,确保整个字符串以这里定义的模式结束。
总结
这个正则表达式可以用于验证以下几种格式的中国电话号码:
- 本地固定电话:
0XX-XXXXXXX或0XXX-XXXXXXXX(区号2或3位,电话号码7或8位) - 国际长途电话:
00XX-XXXXXXX或00XX-XXXXXXXX(国家代码2位,电话号码7或8位) - 带分机号的本地固定电话:
0XX-XXXXXXX-XXXX或0XXX-XXXXXXXX-XXXX(区号2或3位,电话号码7或8位,分机号4位)
示例
- 有效:
010-12345678(北京固定电话)021-12345678(上海固定电话)0086-12345678(国际长途,国家代码86)010-12345678-1234(带分机号的北京固定电话)
- 无效:
10-12345678(区号少于2位)010-1234567(电话号码少于7位)010-123456789(电话号码多于8位)010-12345678-123(分机号少于4位)010-12345678-12345(分机号多于4位)
这个正则表达式可以用于验证用户输入的电话号码是否符合常见的中国电话号码格式。
匹配腾讯qq号
-
正则表达式:
^[1-9]\d{4,}$ -
示例:
qq = "123456789" pattern = r'^[1-9]\d{4,}$' if re.match(pattern, qq): print("Valid QQ number") else: print("Invalid QQ number")
^- 匹配字符串的开始位置,确保整个字符串从这里定义的模式开始。[1-9]- 匹配一个1到9之间的数字,确保QQ号码的第一个字符不是0。\d{4,}- 匹配4个或更多个数字。\d表示一个数字,{4,}表示至少4个。$- 匹配字符串的结束位置,确保整个字符串以这里定义的模式结束
匹配中国邮政编码(6位数字)
-
正则表达式:
^[1-9]\d{5}$ -
示例:
zip_code = "100000" pattern = r'^[1-9]\d{5}$' if re.match(pattern, zip_code): print("Valid ZIP code") else: print("Invalid ZIP code")
^- 匹配字符串的开始位置,确保整个字符串从这里定义的模式开始。[1-9]- 匹配一个1到9之间的数字,确保邮政编码的第一个字符不是0。\d{5}- 匹配5个数字。\d表示一个数字,{5}表示恰好5个。$- 匹配字符串的结束位置,确保整个字符串以这里定义的模式结束。
匹配身份证(15位或18位)
-
正则表达式:
^(?:[1-9]\d{5}(?:18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12][0-9]|3[01])\d{3}(\d|X|x)|(?:\d{15}))$ -
示例:
id_card = "11010519491231002X" pattern = r'^(?:[1-9]\d{5}(?:18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12][0-9]|3[01])\d{3}(\d|X|x)|(?:\d{15}))$' if re.match(pattern, id_card): print("Valid ID card") else: print("Invalid ID card")
-
^- 匹配字符串的开始位置,确保整个字符串从这里定义的模式开始。 -
(?: ... | ... )- 这是一个非捕获组,表示匹配其中的任何一个子模式。这里有两个子模式,分别对应18位和15位的身份证号码。 -
第一个子模式:
[1-9]\d{5}(?:18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12][0-9]|3[01])\d{3}(\d|X|x)[1-9]\d{5}- 匹配6位数字,第一位不能是0,表示地区码。(?:18|19|20)\d{2}- 匹配4位数字,表示出生年份,年份范围是1800到2099。(0[1-9]|1[0-2])- 匹配2位数字,表示月份,范围是01到12。(0[1-9]|[12][0-9]|3[01])- 匹配2位数字,表示日期,范围是01到31。\d{3}- 匹配3位数字,表示顺序码。(\d|X|x)- 匹配1位数字或字母X(大小写不敏感),表示校验码。
-
第二个子模式:
(?:\d{15})\d{15}- 匹配15位数字,表示旧版的身份证号码。
-
$- 匹配字符串的结束位置,确保整个字符串以这里定义的模式结束
匹配ip地址
-
正则表达式:
^(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)){3}$ -
示例:
ip = "192.168.1.1" pattern = r'^(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)){3}$' if re.match(pattern, ip): print("Valid IP address") else: print("Invalid IP address")
形如"carcar"或"barbar"等会重复的三个字符的单词
-
正则表达式:
^(\w{3})\1$ -
示例:
word = "carcar" pattern = r'^(\w{3})\1$' if re.match(pattern, word): print("Valid repeating word") else: print("Invalid repeating word")
这些示例展示了如何使用正则表达式来验证不同类型的字符串。希望这些示例能帮助您更好地理解和应用正则表达式。如果有任何问题或需要进一步的帮助,请随时提问!
8.实例二
1. 匹配Email地址
-
正则表达式:
^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$ -
示例:
import re emails = [ "example@example.com", "user.name+tag+sorting@example.com", "user-name@example.co.uk", "user_name@example.com", "invalid-email@com" ] pattern = r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$' for email in emails: if re.match(pattern, email): print(f"{email}: Valid email") else: print(f"{email}: Invalid email")
2. 匹配网址URL
-
正则表达式:
^https?://[^\s/$.?#].[^\s]*$ -
示例:
urls = [ "https://www.example.com", "http://example.com/path/to/page?name=value&another=value", "https://subdomain.example.com", "http://localhost:8000", "invalid-url" ] pattern = r'^https?://[^\s/$.?#].[^\s]*$' for url in urls: if re.match(pattern, url): print(f"{url}: Valid URL") else: print(f"{url}: Invalid URL")
3. 匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线)
-
正则表达式:
^[a-zA-Z][a-zA-Z0-9_]{4,15}$ -
示例:
usernames = [ "user123", "User_Name", "u123456789012345", "123user", "short" ] pattern = r'^[a-zA-Z][a-zA-Z0-9_]{4,15}$' for username in usernames: if re.match(pattern, username): print(f"{username}: Valid username") else: print(f"{username}: Invalid username")
4. 匹配国内电话号码(0571-87655322,001-87666622,920-209642-964)
-
正则表达式:
^(0\d{2,3}-\d{7,8}|00\d{2}-\d{7,8}|0\d{2,3}-\d{7,8}-\d{4})$ -
示例:
phones = [ "0571-87655322", "001-87666622", "920-209642-964", "010-12345678", "1234567890" ] pattern = r'^(0\d{2,3}-\d{7,8}|00\d{2}-\d{7,8}|0\d{2,3}-\d{7,8}-\d{4})$' for phone in phones: if re.match(pattern, phone): print(f"{phone}: Valid phone number") else: print(f"{phone}: Invalid phone number")
5. 匹配腾讯qq号
-
正则表达式:
^[1-9]\d{4,}$ -
示例:
qqs = [ "123456789", "12345", "0123456789", "12345678901234567890", "1234" ] pattern = r'^[1-9]\d{4,}$' for qq in qqs: if re.match(pattern, qq): print(f"{qq}: Valid QQ number") else: print(f"{qq}: Invalid QQ number")
6. 匹配中国邮政编码(6位数字)
-
正则表达式:
^[1-9]\d{5}$ -
示例:
zip_codes = [ "100000", "200000", "300000", "000000", "12345" ] pattern = r'^[1-9]\d{5}$' for zip_code in zip_codes: if re.match(pattern, zip_code): print(f"{zip_code}: Valid ZIP code") else: print(f"{zip_code}: Invalid ZIP code")
7. 匹配身份证(15位或18位)
-
正则表达式:
^(?:[1-9]\d{5}(?:18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12][0-9]|3[01])\d{3}(\d|X|x)|(?:\d{15}))$ -
示例:
id_cards = [ "11010519491231002X", "11010519491231002x", "11010519491231002", "110105491231002", "11010519491231002Y" ] pattern = r'^(?:[1-9]\d{5}(?:18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12][0-9]|3[01])\d{3}(\d|X|x)|(?:\d{15}))$' for id_card in id_cards: if re.match(pattern, id_card): print(f"{id_card}: Valid ID card") else: print(f"{id_card}: Invalid ID card")
8. 匹配ip地址
-
正则表达式:
^(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)){3}$ -
示例:
ips = [ "192.168.1.1", "255.255.255.255", "10.0.0.1", "256.0.0.1", "192.168.1" ] pattern = r'^(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)){3}$' for ip in ips: if re.match(pattern, ip): print(f"{ip}: Valid IP address") else: print(f"{ip}: Invalid IP address")
9. 形如"carcar"或"barbar"等会重复的三个字符的单词
-
正则表达式:
^(\w{3})\1$ -
示例:
words = [ "carcar", "barbar", "foofoo", "abcabc", "abcxyz" ] pattern = r'^(\w{3})\1$' for word in words: if re.match(pattern, word): print(f"{word}: Valid repeating word") else: print(f"{word}: Invalid repeating word")
这些示例展示了如何使用正则表达式来验证不同类型的数据。希望这些示例能帮助您更好地理解和应用正则表达式。如果有任何问题或需要进一步的帮助,请随时提问!











![[Docker#11] 容器编排 | .yml | up | 实验: 部署WordPress](https://img-blog.csdnimg.cn/img_convert/7ac46f62a767123235152a959ce7e72e.png)