全文链接:https://tecdat.cn/?p=38289
分析师:Cucu Sun
近年来,由于诸如自动编码器等深度神经网络(DNN)的高表示能力,深度聚类方法发展迅速。其核心思想是表示学习和聚类可以相互促进:好的表示会带来好的聚类效果,而好的聚类为表示学习提供良好的监督信号(点击文末“阅读原文”获取完整代码数据)。
关键问题包括:1)如何优化表示学习和聚类?2)是否应始终考虑自动编码器的重建损失?在本文中,我们提出深度k-均值聚类(深度嵌入K - 均值)来回答这两个问题。
由于自动编码器生成的嵌入空间可能没有明显的聚类结构,我们建议将嵌入空间进一步转换为能显示聚类结构信息的新空间。这通过一个正交变换矩阵实现,该矩阵包含K - 均值类内散度矩阵的特征向量。特征值表明特征向量对新空间中聚类结构信息贡献的重要性。我们的目标是增加聚类结构信息。为此,我们舍弃解码器并提出一种贪心方法来优化表示。深度k-均值聚类交替优化表示学习和聚类。在真实数据集上的实验结果表明,深度k-均值聚类达到了最先进的性能。
引言
聚类作为一种重要的数据探索分析工具,已被广泛研究。
得益于深度神经网络(DNN)的高表示能力,自动编码器近年来被广泛用作聚类的降维方法。自动编码器可以通过无监督方式学习输入数据的有意义表示。它由编码器和解码器组成。编码器将输入数据转换为低维空间(嵌入空间),解码器负责从该嵌入空间重构输入数据。
深度聚类的关键问题之一是如何设计合适的聚类损失函数。诸如DEC[41]和IDEC[10]等方法最小化聚类分布和辅助目标分布之间的Kullback - Leibler(KL)散度。其基本思想是通过从高置信度分配中学习来细化聚类。然而,为了获得更好的聚类结果,辅助目标分布很难选择。其他方法如DCN[43]和DKM[6]将K - 均值的目标与自动编码器的目标相结合并联合优化它们。然而,嵌入空间中聚类的区分度与自动编码器的重建损失并无直接关系。因此,在本文中,使用自动编码器生成嵌入空间后,我们舍弃解码器且不再优化重建损失。因为无论我们对嵌入空间做什么,我们都可以单独训练解码器从其嵌入中重构输入数据。考虑到K - 均值的简单性,我们将其扩展为一个深度版本,即深度k-均值聚类,它使用自动编码器生成嵌入空间。由于此嵌入空间对于聚类可能没有区分度,我们建议通过一个正交变换矩阵将此嵌入空间进一步转换为新空间,该矩阵由K - 均值类内散度矩阵的特征向量组成。这些特征向量根据其特征值升序排列。在这个新空间中,聚类结构信息得以显示。每个特征值表明其对应的特征向量对新空间中聚类结构信息数量的贡献大小。最后一个特征向量贡献最小。为了增加最后一个特征向量方向上的聚类结构信息,我们舍弃解码器并提出一种贪心方法来优化表示。优化表示等同于最小化熵。这种优化也与K - 均值的损失一致。受“好的表示有利于聚类,聚类为表示学习提供监督信号”[44]这一思想的启发,我们交替优化表示学习和聚类,直到满足某些标准。
相关工作
A. K - 均值及其变体
K - 均值是最基本的聚类方法之一。它常作为许多高级聚类方法(如谱聚类[31,36,40,45])的构建模块之一。K - 均值启发了许多扩展。例如,[14]的基本思想是用中位数代替均值。K - means++ [2]改进了初始质心的选择方法,其依据是质心与之前所选质心的比例距离。SubKmeans [26]假设输入空间可分为两个独立子空间,即聚类子空间和噪声子空间。前者只包含聚类结构信息,后者只包含噪声信息。SubKmeans在聚类子空间中进行聚类。Nr - Kmeans [27,28]通过正交变换矩阵在多个相互正交的子空间中找到非冗余的K - 均值聚类。模糊C - 均值[5]按比例将每个数据点分配到多个聚类中。它将K - 均值的硬聚类分配放宽为软聚类分配。小批量K - 均值[34]将K - 均值扩展到面向用户的网络应用场景。小批量K - 均值可用于深度学习框架,因为它支持在线随机梯度下降(SGD)。
讲解视频
对于真实世界的数据集,聚类数是未知的。为解决此问题,研究人员提出自动找到合适的聚类数。X - 均值[33]使用贝叶斯信息准则(BIC)或赤池信息准则(AIC)作为衡量标准,评估不同聚类数k下的聚类结果。G - 均值[12]假设每个聚类遵循高斯分布。它以递增的k分层运行K - 均值,直到统计检验表明聚类遵循高斯分布。PG - 均值[7]首先构建数据集和学习模型的一维投影,然后在投影空间中评估模型拟合度,它能够发现合适数量的高斯聚类。Dip - 均值[15]假设每个聚类遵循单峰分布。它首先计算一个数据点与其他数据点之间的成对距离,然后对距离分布应用单变量统计假设检验[13](称为Hartigans’ dip - test)以找到单峰聚类和合适的聚类数。
B. 深度聚类
由于浅层聚类模型受现实世界数据非线性的影响,它们表现不佳。深度聚类模型使用具有更强非线性表示能力的深度神经网络(DNNs)来提取特征,从而获得更好的聚类性能。早期的深度聚类方法[4,37]按顺序执行表示学习和聚类。最近的研究[6,8,10,11,23,35,41,43,44]表明,联合执行表示学习和聚类能产生更好的性能。
JULE [44]提出了一个循环框架,用于联合无监督学习深度表示和聚类。在优化过程中,前向传播进行聚类,后向传播进行表示学习。DCC [35]联合执行非线性降维和聚类,聚类过程包括自动编码器的优化。由于目标函数是连续的,没有离散的聚类分配,因此可以通过标准的基于梯度的方法求解。DEC [41]用重建损失预训练自动编码器并进行聚类,以获得每个数据点的软聚类分配。然后,从当前软聚类分配中导出辅助目标分布。最后,通过最小化软分配和辅助目标分布之间的Kullback - Leibler(KL)散度来迭代细化聚类。DCN [43]将K - 均值的目标与自动编码器的目标相结合,以找到一个“对K - 均值友好”的空间。DCN的聚类分配不像DEC那样是软(概率)的,而是严格(离散)的,这限制了基于梯度的SGD求解器的直接使用。DCN通过交替优化自动编码器和K - 均值的目标来细化聚类。DEPICT [8]由两部分组成,即用于学习嵌入空间的卷积自动编码器和用作判别聚类模型的多项逻辑回归层。为了联合学习嵌入空间和聚类,DEPICT采用交替方法来优化统一目标函数。IDEC [10]将欠完备自动编码器与DEC相结合。欠完备自动编码器不仅学习嵌入空间,还保留数据的局部结构。与IDEC类似,DCEC [11]将卷积自动编码器与DEC相结合。DKM [6]提出了一种新方法,用于联合K - 均值聚类和学习表示。K - 均值目标被视为可微函数的极限,以便通过简单的随机梯度下降优化表示学习和聚类。RED - KC(用于鲁棒嵌入深度K - 均值聚类)[46]使用δ - 范数度量来约束自动编码器的特征映射,使数据嵌入更有利于鲁棒的K - 均值聚类。
我们提出的深度k-均值聚类也是一种联合执行表示学习和聚类的方法。与DCEC类似,深度k-均值聚类首先使用自动编码器找到嵌入空间,然后舍弃解码器并优化表示以获得更好的聚类。深度k-均值聚类的表示优化与DCEC不同,它不优化聚类分布和辅助目标分布之间的Kullback - Leibler(KL)散度,而是通过降低熵来优化表示。
III. 深度嵌入K - 均值
我们假设聚类结构存在于低维子空间中。深度k-均值聚类不是直接在原始空间中聚类,而是在聚类前使用自动编码器将原始空间转换为嵌入空间以降低维度。深度k-均值聚类交替优化表示学习和聚类。深度k-均值聚类有三个步骤:(1) 用自动编码器生成嵌入空间,(2) 用K - 均值在嵌入空间中检测聚类,(3) 优化表示以增加聚类结构信息。后两个步骤交替优化,以生成更好的嵌入空间和聚类结果。表I展示了本文使用的符号及其相应解释。

A. 生成嵌入空间
自动编码器是一种深度神经网络(DNNs),它能够以无监督的方式学习输入数据的低维表示。它由一个编码器和一个解码器组成。编码器f(⋅)f(·)将输入数据转换到一个低维空间(即嵌入空间),解码器g(⋅)g(·)则从嵌入空间重构输入数据。自动编码器经过训练以最小化重建损失,比如最小二乘误差:
其中xixi是第ii个数据点,f(xi)f(xi)是编码器f(⋅)f(·)的输出,xixi是解码器g(⋅)g(·)的重构输出。嵌入空间的维度通常设置为远小于原始空间的维度。这不仅能缓解维度诅咒问题,还有助于避免自动编码器出现平凡解(即f(⋅)f(·)和g(⋅)g(·)都等于单位矩阵的情况)。
import torch
import torch.nn as nn
# 定义自动编码器类
class Autoencoder(nn.Module):
def \\_\\\_init\\\_\\_(self, input\\\_dim, embedding\\\_dim):
super(Autoencoder, self).\\_\\\_init\\\_\\_()
self.encoder = nn.Linear(input\\\_dim, embedding\\\_dim)
self.decoder = nn.Linear(embedding\\\_dim, input\\\_dim)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
# 训练自动编码器并生成嵌入空间的函数
def train\\\_autoencoder\\\_and\\\_generate\\\_embedding\\\_space(data, input\\\_dim, embedding\\\_dim, num\\\_epochs, learning_rate):
autoencoder = Autoencoder(input\\\_dim, embedding\\\_dim)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=learning_rate)
data_tensor = torch.tensor(data, dtype=torch.float32)
for epoch in range(num_epochs):
optimizer.zero_grad()
output = autoencoder(data_tensor)
loss = criterion(output, data_tensor)
loss.backward()
optimizer.step()
embedding\\\_space = autoencoder.encoder(data\\\_tensor)
return embedding_spaceB. 检测聚类
在上一节中,我们使用最小二乘误差损失训练自动编码器以生成嵌入空间H=f(X)H=f(X),但未考虑嵌入空间的特性。这个嵌入空间可能不包含任何聚类结构。DCN [43]将自动编码器的目标函数与K - 均值的目标函数相结合,并交替对它们进行优化。DCN想要找到一个“对K - 均值友好”的子空间。然而,这两个目标函数之间的相对重要性参数很难设置。此外,由于自动编码器的重建损失,这种模式很难生成一个“对K - 均值友好”的子空间。在优化过程中,不应再使用自动编码器的重建损失。原因是无论我们对编码器进行何种修改,我们仍然可以训练解码器以使公式(1)最小化。
我们使用K - 均值[24]来找到嵌入空间HH中数据点的一个划分{Ci}ki=1{Ci}i=1k。其目标函数如下:
其中hh是嵌入空间中的一个数据点,kk是聚类数,CiCi表示分配到第ii个聚类的数据集,μi=1|Ci|∑h∈Cihμi=1|Ci|∑h∈Cih表示第ii个聚类的质心。
为了揭示嵌入空间中的聚类结构,我们建议通过一个正交变换矩阵VV将嵌入空间HH转换到一个新空间。在新空间Y=VHY=VH中,公式(2)变为如下形式:
其中我们在最后一步使用了迹技巧,因为标量也可被视为大小为1×11×1的矩阵。由于VTV=IVTV=I,最小化公式(3)等同于最小化公式(2)。上述公式可进一步写为:
其中Sw=∑ki=1∑h∈Ci(h−μi)(h−μi)TSw=∑i=1k∑h∈Ci(h−μi)(h−μi)T是K - 均值的类内散度矩阵。由于VV是正交矩阵,最小化公式(4)是一个标准的迹最小化问题。瑞利 - 里兹定理[25]的一个版本表明,解VV包含SwSw的特征向量,且特征值按升序排列。特征值表明了特征向量对转换空间Y=VHY=VH中聚类结构贡献的重要性。特征值越小,其对应的特征向量对转换空间YY中的聚类结构贡献越重要。需要注意的是,SwSw是对称的,因此它是正交可对角化的,所以找到正交矩阵VV是可行的。
import numpy as np
from sklearn.cluster import KMeans
# 假设已经得到嵌入空间数据embedding_space(比如通过前面的自动编码器生成)
def detect\\\_clusters\\\_and\\\_transform\\\_space(embedding_space, k):
kmeans = KMeans(n_clusters=k)
kmeans.fit(embedding_space)
clusters = kmeans.labels_
centroids = kmeans.cluster\\\_centers\\\_
within\\\_class\\\_scatter\\\_matrix = np.zeros((embedding\\\_space.shape\\\[1\\\], embedding_space.shape\\\[1\\\]))
for i in range(k):
cluster\\\_data = embedding\\\_space\\\[clusters == i\\\]
centroid = centroids\\\[i\\\]
within\\\_class\\\_scatter\\\_matrix += np.dot((cluster\\\_data - centroid).T, (cluster_data - centroid))
eigenvalues, eigenvectors = np.linalg.eig(within\\\_class\\\_scatter_matrix)
sorted_indices = np.argsort(eigenvalues)
orthonormal\\\_transformation\\\_matrix = eigenvectors\\\[:, sorted_indices\\\]
new\\\_space = np.dot(embedding\\\_space, orthonormal\\\_transformation\\\_matrix)
return new_space, clusters, centroidsC. 优化表示
如前所述,最小化公式(3)等同于最小化公式(2)。我们可以首先在嵌入空间HH中执行K - 均值算法以得到SwSw,然后对SwSw进行特征分解以得到VV。最后,我们将嵌入空间转换到一个新空间YY,该空间能揭示聚类结构信息。我们还知道了YY的每个维度在聚类结构信息方面的重要性,即最后一个维度具有最少的聚类结构信息。我们可以将公式(3)重写如下:
其中y=Vhy=Vh且mi=Vμimi=Vμi。现在的问题是如何优化表示以提高YY中的聚类结构信息。在本文中,我们通过熵来衡量聚类结构信息。数据的熵越低,其包含的聚类结构信息就越高。
我们在最后维度的质心附近优化表示,这样表示就容易被优化以增加聚类结构信息。我们在实验中发现这种贪心方法效果最佳。贪心方法的具体细节如下:我们首先复制yy得到y′y′,然后用mimi的最后维度替换y′y′的最后维度。最后,目标函数定义如下:
我们不使用将所有数据点在最后维度都移向其质心的全批量更新策略。相反,我们使用小批量更新策略,只将一些小批量的数据点移向其质心。我们发现小批量更新策略优于全批量更新策略。
在优化表示之后,我们得到一个新的嵌入空间HH。然后,我们再次执行K - 均值算法以找到聚类及其各自的质心。我们交替重复第二和第三步,直到满足某些标准,比如预定义的迭代次数或者在连续两次迭代之间改变聚类分配的样本少于0.1%。深度k-均值聚类的伪代码如算法1所示。第1行使用公式(1)训练自动编码器。第3行使用编码器生成嵌入空间H=f(X)H=f(X)。然后在嵌入空间中,第4行执行K - 均值算法以找到聚类。第5 - 6行计算类内散度矩阵SwSw并对其进行特征分解以得到正交变换矩阵VV。第7行使用公式(6)优化表示。我们重复这个过程进行IterIter次迭代,并返回最终的聚类集CC。
实验评估
A. 数据集
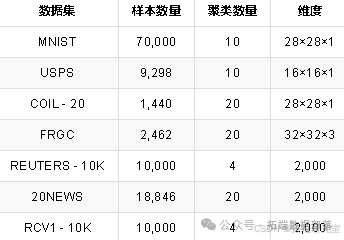
为评估深度k-均值聚类的性能和通用性,我们在基准数据集上进行实验,并与最先进的方法进行比较。为表明深度k-均值聚类在各种数据集上均能良好运行,我们选择了四个图像数据集(涵盖手写数字、物体、人脸等领域)和三个文本数据集。表对每个数据集进行了简要描述。
1. MNIST [20]
由70,000张手写灰度数字图像组成,每张图像大小为28×28像素。
2. USPS
来自邮政服务的手写灰度数字图像数据集,包含9,298张尺寸为16×16像素的图像。
3. COIL - 20 [30]
包含20个物体的1,440张彩色图像(每个物体72张图像),这些物体具有多种复杂的几何和反射特性,每张图像大小被调整为28×28像素。
4. FRGC
一个人脸数据集。按照[44]的方法,我们从原始数据集中随机选取20个对象,并收集他们的2,462张人脸图像,同样裁剪人脸区域并将其调整为28×28像素。
对于所有图像数据集,每张图像都通过在0到1之间缩放进行归一化处理。
5. REUTERS - 10K [41]
包含路透社数据集的一个随机子集,该子集有10,000个样本,而路透社数据集约有810,000篇英语新闻报道。REUTERS - 10K包含四个类别:企业/工业、政府/社会、市场和经济。
6. 20 Newsgroups数据集(20NEWS)[19]
包含18,846份文档,被标记为20个不同类别,每个类别对应一个不同主题。
7. 路透社语料库第一卷(RCV1)[22]
包含804,414篇人工分类的新闻专线报道。按照[6]的方法,我们从完整的RCV1集合中从最大的四个类别中随机抽取一个10,000份文档的子集,记为RCV1 - 10K。
对于三个文本数据集,我们将每份文档表示为基于2,000个最常见词干的tf - idf特征向量,并且对每个样本xixi进行归一化,使得1d∥xi∥22≈11d‖xi‖22≈1,其中dd是输入空间的维度。
点击标题查阅往期内容

Python复杂网络社区检测:并行谱聚类算法设计与多种算法应用实战研究

左右滑动查看更多
01

02
03

04
B. 基准方法
我们将提出的深度k-均值聚类与以下方法进行比较:
1. K - 均值
在原始数据上执行K - 均值算法。
2. PCA + K - 均值
使用主成分分析(PCA)在数据的前pp个主成分所张成的空间中执行K - 均值算法,其中pp的选择是为了保留90%的数据方差。
3. AE + K - 均值
在我们预训练的卷积/多层感知机(MLP)自动编码器的嵌入空间中执行K - 均值算法。
4. DEC [41]
使用MLP自动编码器找到嵌入空间,然后通过最小化聚类分布与目标学生t分布之间的Kullback - Leibler(KL)散度在嵌入空间中进行聚类。
5. DCEC [11]
用卷积自动编码器替换DEC中的MLP自动编码器。
6. IDEC [10]
用保留数据局部结构的欠完备自动编码器替换DEC中的MLP自动编码器。
7. DCN [43]
将MLP自动编码器的目标函数与K - 均值的目标函数相结合,并交替对它们进行优化。
8. DKM [6]
将K - 均值目标视为可微函数的极限,并采用随机梯度下降来联合优化表示学习和聚类。
C. 实验设置
由于卷积神经网络(CNN)擅长捕捉输入图像的语义视觉特征,对于图像数据集,我们利用卷积自动编码器来找到嵌入空间。具体来说,在编码器到解码器路径中,我们使用三个卷积层后接一个密集层(嵌入层)。三个卷积层的通道数分别为32、64和128,卷积核大小分别设置为5×5、5×5和3×3,所有卷积层的步长设置为2。嵌入层的神经元数量设置为数据集的聚类数。解码器是编码器的镜像,解码器每层的输出都进行适当的零填充以匹配相应编码器层的输入大小。卷积自动编码器的所有中间层都由ReLU [17]激活。
对于文本数据集,我们使用全连接多层感知机(MLP)作为自动编码器的主干。按照DEC [41]中的设置,编码器维度为d−500−500−2000−10d−500−500−2000−10,其中dd是输入数据的维度。解码器是编码器的镜像,所有中间层都由ReLU激活。所有层的权重都通过Xavier方法[9]初始化。采用Adam [16]优化器,初始学习率l=0.001l=0.001,β1=0.9β1=0.9,β2=0.999β2=0.999。当连续两次迭代之间改变聚类分配的样本少于0.1%时,我们停止聚类过程。
D. 评估指标
为评估聚类方法,我们采用两个标准评估指标:归一化互信息(NMI)[39]和无监督聚类准确率(ACC)[42]。NMI和ACC的值都在[0, 1]范围内,值越高,聚类结果越好。
1. 归一化互信息(NMI)
是一种信息论度量,用于计算真实标签与获得的聚类分配之间相似性的归一化度量。NMI定义如下:
其中GG是真实情况,CC是聚类分配,II表示互信息,HH表示熵。
2. 无监督聚类准确率(ACC)
衡量聚类分配能正确映射到真实标签的样本比例。ACC定义如下:
其中gigi是第ii个数据点的真实标签,cici是第ii个数据点的聚类分配,mm遍历真实标签与聚类分配之间所有可能的一一映射,该映射基于匈牙利算法[18]。
E. 聚类结果
从表可以看出,深度k-均值聚类在大多数数据集上优于比较方法。
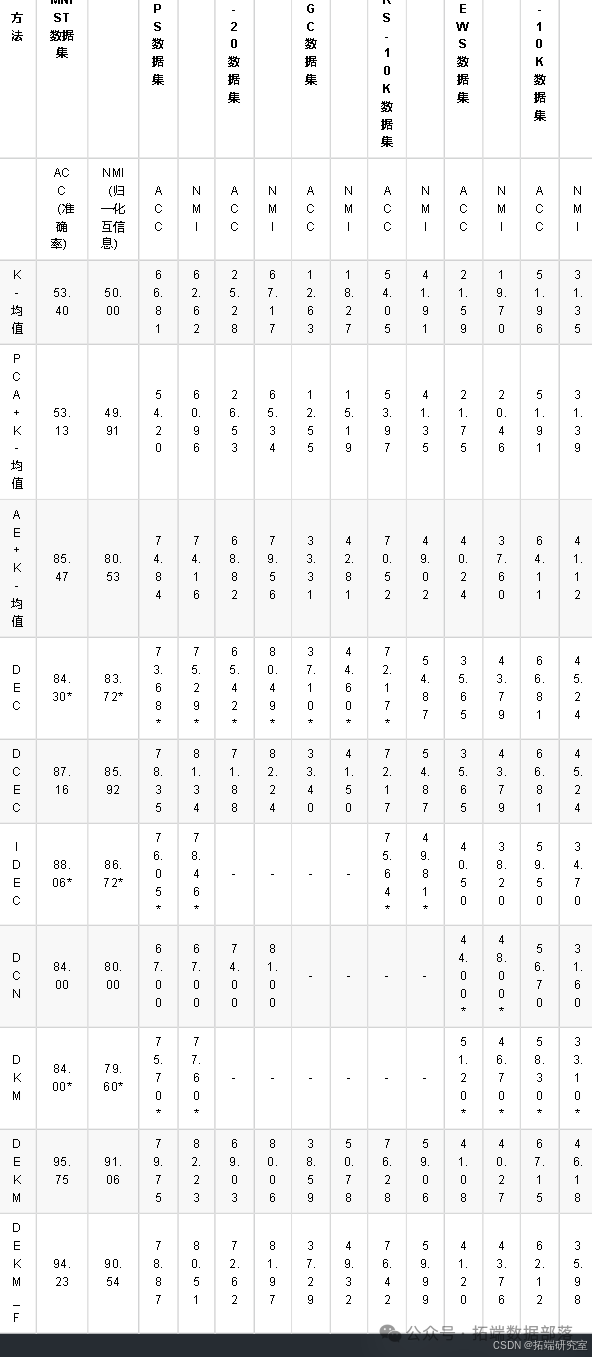
在COIL - 20数据集上,就NMI而言,深度k-均值聚类与DCEC取得了有竞争力的结果。在MNIST、20NEWS和RCV1 - 10K数据集上,深度k-均值聚类大幅优于所有比较方法。深度k-均值聚类\_F使用全批量更新策略来优化表示,与深度k-均值聚类相比,深度k-均值聚类\_F在MNIST、USPS、FRGC和RCV1 - 10K这四个数据集上表现略差。
可以看出,所有深度聚类方法的性能都远优于传统的浅层聚类方法(即K - 均值和K - 均值 + PCA),这表明自动编码器生成的嵌入空间对聚类更有利。深度k-均值聚类与AE + K - 均值之间的性能差距较大,这意味着我们的表示优化策略很有前景。深度k-均值聚类和DCEC都使用卷积自动编码器为图像数据集找到嵌入空间,深度k-均值聚类和DCEC之间的性能差距反映了不同表示优化策略的影响,深度k-均值聚类的表示优化策略优于DCEC的策略。需要注意的是,DCEC是用卷积自动编码器替换DEC中的MLP自动编码器。对于文本数据集,使用MLP自动编码器的DCEC等同于DEC,与文本数据集上的DCEC相比,我们可以看到深度k-均值聚类也表现得更好,因此,深度k-均值聚类的表示优化策略在不同场景下都有效,使深度k-均值聚类成为一个通用的聚类框架。
pretrain_epochs = 200
pretrain\\\_batch\\\_size = 256
batch_size = 256
update_interval = 40
hidden_units = 10
parser = argparse.ArgumentParser(description='select dataset:MNIST,COIL20,FRGC,USPS')
parser.add\\\_argument('ds\\\_name', default='MNIST')
args = parser.parse_args()F. 表示优化策略
我们在MNIST数据集上检验了几种表示优化策略的效果。具体来说,我们比较了以下策略:
降低YY的最后维度的熵。
降低YY的一个随机维度的熵。
降低YY的所有维度的熵。
我们还比较了另外两种策略:降低HH的一个随机维度的熵。
降低HH的所有维度的熵。
需要注意的是,所有这些策略都使用小批量更新策略。图4展示了比较结果,我们可以看到第一种策略(降低YY的最后维度的熵)效果最佳,它大幅优于其他四种策略。策略2的表现优于策略4,策略3的表现与策略5相似。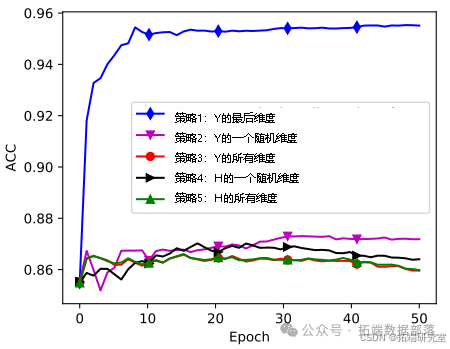
G. 嵌入空间比较
图展示了不同算法在MNIST数据集上嵌入空间的t - SNE [38]可视化结果。
(a) Raw data + PCA

(b) AE

(c)DEC
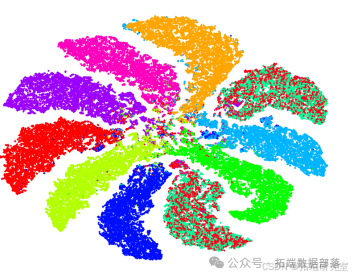
(d) 深度k-均值聚类

图(a)展示了PCA的嵌入空间,图(b)展示了卷积自动编码器的嵌入空间(这是深度k-均值聚类的初始嵌入空间),图(c)展示了DEC的嵌入空间,图(d)展示了深度k-均值聚类的嵌入空间。需要注意的是,所有这些嵌入空间都用于获取表III中的聚类结果。
与卷积自动编码器初始嵌入空间(如图(b)所示)中的聚类相比,深度k-均值聚类嵌入空间(如图(d)所示)中的聚类更加集中且各向同性,这对K - 均值有利。DEC嵌入空间中的两个聚类是混合的,这导致其与深度k-均值聚类相比性能较低。PCA嵌入空间中的聚类不是各向同性的高斯聚类,这就是K - 均值在其上表现不佳的原因。
参考文献
[1]:G. Andrew、R. Arora、J. Bilmes和K. Livescu所著的“Deep canonical correlation analysis”,发表于ICML会议,页码为1247 - 1255,由PMLR出版于2013年。该文献主要涉及深度典型相关分析方面的研究内容。
[2]:D. Arthur和S. Vassilvitskii的“k-means++: The advantages of careful seeding”,这是一份斯坦福大学的技术报告,发表于2006年。主要探讨了K - means++算法中精心选择初始种子的优势相关内容。
[3]:C. M. Bishop所著的“Pattern recognition and machine learning”,由Springer出版社于2006年出版。是关于模式识别和机器学习领域的重要著作,为相关研究提供了全面的理论知识体系。
[4]:C. Ding和X. He的“K-means clustering via principal component analysis”,发表于2004年的ICML会议,在第29页。阐述了通过主成分分析进行K - means聚类的相关方法和研究。
[5]:J. C. Dunn于1973年发表的“A fuzzy relative of the isodata process and its use in detecting compact well-separated clusters”,主要介绍了一种与isodata过程相关的模糊方法及其在检测紧密且分离良好的聚类中的应用。
[6]:M. M. Fard、T. Thonet和E. Gaussier的“Deep k - means: Jointly clustering with k - means and learning representations”,发表于《Pattern Recognition Letters》期刊,2020年,卷138,页码为185 - 192。该文献提出了深度K - means方法,涉及联合K - means聚类和学习表示的相关内容。
[7]:Y. Feng和G. Hamerly的“Pg - means: learning the number of clusters in data”,发表于2006年的NeurIPS会议,页码为393 - 400。主要围绕学习数据中聚类数量的Pg - means方法展开研究。
[8]:K. Ghasedi Dizaji、A. Herandi、C. Deng、W. Cai和H. Huang的“Deep clustering via joint convolutional autoencoder embedding and relative entropy minimization”,发表于2017年的ICCV会议,页码为5736 - 5745。介绍了通过联合卷积自动编码器嵌入和相对熵最小化进行深度聚类的方法。
[9]:X. Glorot和Y. Bengio的“Understanding the difficulty of training deep feedforward neural networks”,发表于2010年的AISTATS会议,页码为249 - 256,收录于JMLR Workshop and Conference Proceedings。主要探讨了训练深度前馈神经网络的困难之处相关内容。
[10]:X. Guo、L. Gao、X. Liu和J. Yin的“Improved deep embedded clustering with local structure preservation”,发表于2017年的IJCAI会议,页码为1753 - 1759。提出了具有局部结构保留的改进型深度嵌入聚类方法。
[11]:X. Guo、X. Liu、E. Zhu和J. Yin的“Deep clustering with convolutional autoencoders”,发表于2017年的NeurIPS会议,页码为373 - 382,由Springer出版。阐述了使用卷积自动编码器进行深度聚类的相关研究。
[12]:G. Hamerly和C. Elkan的“Learning the k in k - means”,发表于2004年的NeurIPS会议,卷16,页码为281 - 288。主要围绕在K - means算法中学习K值的相关内容展开研究。
[13]:J. A. Hartigan、P. M. Hartigan等人的“The dip test of unimodality”,发表于《Annals of statistics》期刊,1985年,卷13(1),页码为70 - 84。介绍了单峰性的dip检验相关方法和理论。
[14]:A. K. Jain和R. C. Dubes的“Algorithms for clustering data”,由Prentice - Hall, Inc.出版社于1988年出版。是关于聚类数据算法方面的重要著作,为相关研究提供了多种聚类算法的详细介绍和分析。
[15]:A. Kalogeratos和A. Likas的“Dip - means: an incremental clustering method for estimating the number of clusters”,发表于2012年的NeurIPS会议,卷25,页码为2393 - 2401。提出了一种用于估计聚类数量的增量聚类方法Dip - means。
[16]:D. P. Kingma和J. Ba的“Adam: A method for stochastic optimization”,是一篇发表于2014年的arXiv预印本,编号为arXiv:1412.6980。介绍了一种随机优化方法Adam。
[17]:A. Krizhevsky、I. Sutskever和G. E. Hinton的“Imagenet classification with deep convolutional neural networks”,发表于2012年的NeurIPS会议,卷25,页码为1097 - 1105。主要阐述了使用深度卷积神经网络进行ImageNet分类的相关研究成果。
[18]:H. W. Kuhn的“The hungarian method for the assignment problem”,发表于《Naval Research Logistics (NRL)》期刊,2005年,卷52(1),页码为7 - 21。介绍了用于分配问题的匈牙利方法相关理论和应用。
[19]:K. Lang的“Newsweeder: Learning to filter netnews”,发表于《Machine Learning Proceedings 1995》,页码为331 - 339,由Elsevier出版社于1995年出版。主要围绕学习过滤网络新闻的Newsweeder相关内容展开研究。
[20]:Y. LeCun、L. Bottou、Y. Bengio和P. Haffner的“Gradient - based learning applied to document recognition”,发表于《Proceedings of the IEEE》期刊,1998年,卷86(11),页码为2278 - 2324。阐述了基于梯度的学习在文档识别中的应用相关研究成果。
[21]:D. D. Lee和H. S. Seung的“Learning the parts of objects by non - negative matrix factorization”,发表于《Nature》期刊,1999年,卷401(6755),页码为788 - 791。介绍了通过非负矩阵分解学习物体部分的相关方法和研究成果。
[22]:D. D. Lewis、Y. Yang、T. Russell - Rose和F. Li的“Rcv1: A new benchmark collection for text categorization research”,发表于《JMLR》期刊,2004年,卷5(Apr),页码为361 - 397。主要围绕用于文本分类研究的新基准集合Rcv1展开介绍。
[23]:F. Li、H. Qiao和B. Zhang的“Discriminatively boosted image clustering with fully convolutional auto - encoders”,发表于《Pattern Recognition》期刊,2018年,卷83,页码为161 - 173。阐述了使用全卷积自动编码器进行判别式增强图像聚类的相关研究。
[24]:S. Lloyd的“Least squares quantization in pcm”,发表于《IEEE transactions on information theory》期刊,1982年,卷28(2),页码为129 - 137。主要围绕脉冲编码调制中的最小二乘量化相关内容展开研究。
[25]:H. Lutkepohl的“Handbook of matrices. Computational statistics and Data analysis”,1997年,卷2(25),页码为243。是关于矩阵手册以及计算统计学和数据分析方面的相关著作。
[26]:D. Mautz、W. Ye、C. Plant和C. Bohm的“Towards an optimal subspace for k - means”,发表于2017年的SIGKDD会议,页码为365 - 373。主要围绕为K - means寻找最优子空间的相关研究展开。
[27]:D. Mautz、W. Ye、C. Plant和C. Bohm的“Discovering non - redundant k - means clusterings in optimal subspaces”,发表于2017年的SIGKDD会议,页码为1973 - 1982。阐述了在最优子空间中发现非冗余K - means聚类的相关研究内容。
[28]:D. Mautz、W. Ye、C. Plant和C. Bohm的“Non - redundant subspace clusterings with nr - kmeans and nr - dipmeans”,发表于《TKDD》期刊,2020年,卷14(5),页码为1 - 24。主要围绕使用nr - kmeans和nr - dipmeans进行非冗余子空间聚类的相关研究展开。
[29]:R. J. McEliece的“Theory of information and coding. A mathematical framework for communication”,1977年出版。是关于信息理论和编码的相关著作,为通信提供了数学框架方面的理论基础。
[25]:H. Lutkepohl的“Handbook of matrices. Computational statistics and Data analysis”,1997年,卷2(25),页码为243。是关于矩阵手册以及计算统计学和数据分析方面的相关著作。
[26]:D. Mautz、W. Ye、C. Plant和C. Bohm的“Towards an optimal subspace for k - means”,发表于2017年的SIGKDD会议,页码为365 - 373。主要围绕为K - means寻找最优子空间的相关研究展开。
[27]:D. Mautz、W. Ye、C. Plant和C. Bohm的“Discovering non - redundant k - means clusterings in optimal subspaces”,发表于2017年的SIGKDD会议,页码为1973 - 1982。阐述了在最优子空间中发现非冗余K - means聚类的相关研究内容。
[28]:D. Mautz、W. Ye、C. Plant和C. Bohm的“Non - redundant subspace clusterings with nr - kmeans and nr - dipmeans”,发表于《TKDD》期刊,2020年,卷14(5),页码为1 - 24。主要围绕使用nr - kmeans和nr - dipmeans进行非冗余子空间聚类的相关研究展开。
[29]:R. J. McEliece的“Theory of information and coding. A mathematical framework for communication”,1977年出版。是关于信息理论和编码的相关著作,为通信提供了数学框架方面的理论基础。
[30]:S. Nene、S. Nayar和H. Murase的“Columbia image object library (coil - 20)”,发表于《Technical Report CUCS - 006 - 96》,由哥伦比亚大学计算机科学系发布于1996年。主要介绍了哥伦比亚图像物体库(coil - 20)的相关情况。
[31]:A. Y. Ng、M. I. Jordan、Y. Weiss等人的“On spectral clustering: Analysis and an algorithm”,发表于2002年的NeurIPS会议,卷2,页码为849 - 856。主要围绕光谱聚类的分析和算法相关内容展开研究。
[32]:K. Pearson的“Liii. on lines and planes of closest fit to systems of points in space”,发表于《The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science》期刊,1901年,卷2(11),页码为559 - 572。主要围绕空间中与点系统最拟合的线和平面相关内容展开研究。
[33]:D. Pelleg、A. W. Moore等人的“X - means: Extending k - means with efficient estimation of the number of clusters”,发表于2002年的ICML会议,卷1,页码为727 - 734。介绍了通过有效估计聚类数量来扩展K - means的X - means方法。
[34]:D. Sculley的“Web - scale k - means clustering”,发表于2003年的WWW会议,页码为1177 - 1178。主要围绕网络规模的K - means聚类相关内容展开研究。
[35]:S. A. Shah和V. Koltun的“Deep continuous clustering”,是一篇发表于2018年的arXiv预印本,编号为arXiv:1803.01449。阐述了深度连续聚类的相关研究内容。
[36]:J. Shi和J. Malik的“Normalized cuts and image segmentation”,发表于《TPAMI》期刊,2000年,卷22(8),页码为888 - 905。主要围绕归一化割和图像分割相关内容展开研究。
[37]:G. Trigeorgis、K. Bousmalis、S. Zafeiriou和B. Schuller的“A deep semi - nmf model for learning hidden representations”,发表于2014年的ICML会议,页码为1692 - 1700,由PMLR出版。介绍了一种用于学习隐藏表示的深度半非负矩阵分解模型。
[38]:L. Van der Maaten和G. Hinton的“Visualizing data using t - sne”,发表于《JMLR》期刊,2008年,卷9(11)。主要围绕使用t - sne可视化数据的相关内容展开研究。
[39]:N. X. Vinh、J. Epps和J. Bailey的“Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance”,发表于《JMLR》期刊,2010年,卷11,页码为2837 - 2854。主要围绕聚类比较的信息论度量相关内容展开研究,包括其变体、性质、归一化以及对偶然因素的修正等方面。
[40]:U. Von Luxburg的“A tutorial on spectral clustering”,发表于《Statistics and computing》期刊,2007年,卷17(4),页码为395 - 400。主要围绕光谱聚类教程相关内容展开研究,对光谱聚类进行了详细介绍和分析。
[41]:J. Xie、R. Girshick和A. Farhadi的“Unsupervised deep embedding for clustering analysis”,发表于2016年的ICML会议,页码为478 - 487,由PMLR出版。阐述了用于聚类分析的无监督深度嵌入相关研究内容。
[42]:W. Xu、X. Liu和Y. Gong的“Document clustering based on non - negative matrix factorization”,发表于2003年的SIGIR会议,页码为267 - 273。主要围绕基于非负矩阵分解的文档聚类相关内容展开研究。
[43]:B. Yang、X. Fu、N. D. Sidiropoulos和M. Hong的“Towards k - means-friendly spaces: Simultaneous deep learning and clustering”,发表于2017年的ICML会议,页码为3861 - 3870,由PMLR出版。主要围绕创建对K - means友好的空间,即同时进行深度学习和聚类的相关研究展开。
[44]:J. Yang、D. Parikh和D. Batra的“Joint unsupervised learning of deep representations and image clusters”,发表于2016年的CVPR会议,页码为5147 - 5156。主要围绕联合无监督学习深度表示和图像聚类的相关内容展开研究。
[45]:W. Ye、S. Goebl、C. Plant和C. Bohm的“Fuse: Full spectral clustering”,发表于2016年的SIGKDD会议,页码为1985 - 1994。主要围绕全光谱聚类的相关内容展开研究。
[46]:R. Zhang、H. Tong、Y. Xia和Y. Zhu的“Robust embedded deep k - means clustering”,发表于2017年的CIKM会议,页码为1181 - 1190。主要围绕鲁棒嵌入式深度K - means聚类的相关
关于分析师

在此对 Cucu Sun 对本文所作的贡献表示诚挚感谢,她在南京航空航天大学完成了金融学专业的学位,专注于机器学习领域。擅长 Matlab、Python、SPSS,在数据采集、数理金融以及机器学习等方面有着丰富的经验。
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《【视频讲解】Python深度神经网络DNNs-K-Means(K-均值)聚类方法在MNIST等数据可视化对比分析》。
点击标题查阅往期内容
MATLAB用CNN-LSTM神经网络的语音情感分类深度学习研究
Python用CEEMDAN-LSTM-VMD金融股价数据预测及SVR、AR、HAR对比可视化
Python注意力机制Attention下CNN-LSTM-ARIMA混合模型预测中国银行股票价格|附数据代码
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用CNN-LSTM、ARIMA、Prophet股票价格预测的研究与分析|附数据代码
【视频讲解】线性时间序列原理及混合ARIMA-LSTM神经网络模型预测股票收盘价研究实例
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
用PyTorch机器学习神经网络分类预测银行客户流失模型
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言深度学习Keras循环神经网络(RNN)模型预测多输出变量时间序列
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
MATLAB中用BP神经网络预测人体脂肪百分比数据
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言实现CNN(卷积神经网络)模型进行回归数据分析
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
Python使用神经网络进行简单文本分类
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
R语言基于递归神经网络RNN的温度时间序列预测
R语言神经网络模型预测车辆数量时间序列
R语言中的BP神经网络模型分析学生成绩
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
R语言实现拟合神经网络预测和结果可视化
用R语言实现神经网络预测股票实例
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类



![]()












![[JavaWeb] 尚硅谷JavaWeb课程笔记](https://i-blog.csdnimg.cn/direct/46ec6ca4af454f6bb0aa07aad4a73f11.png)