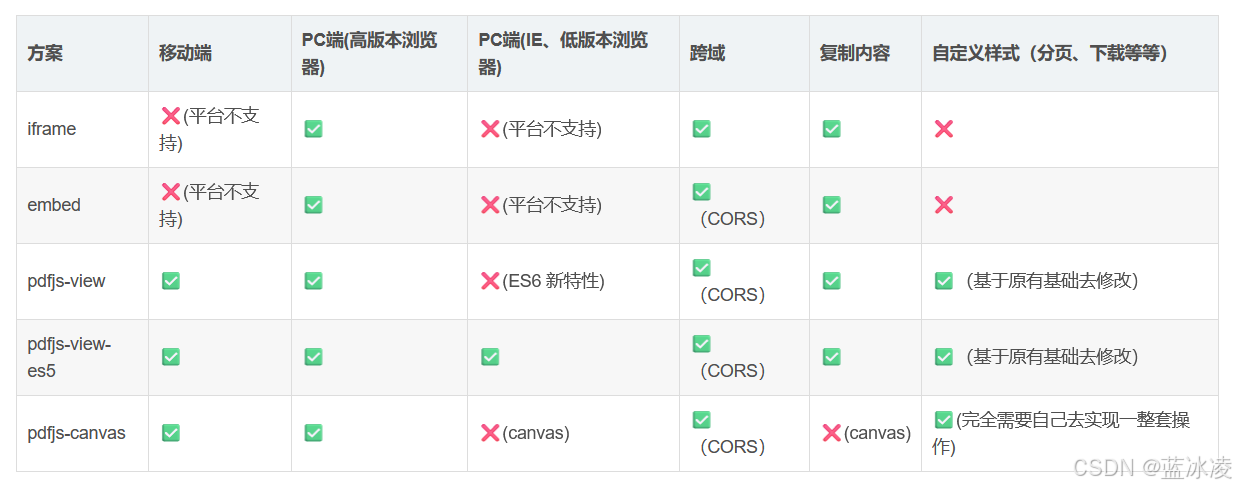
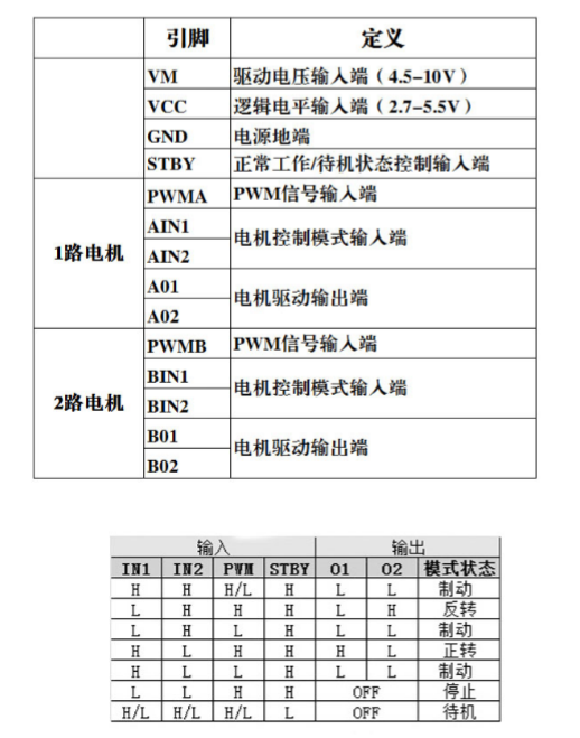
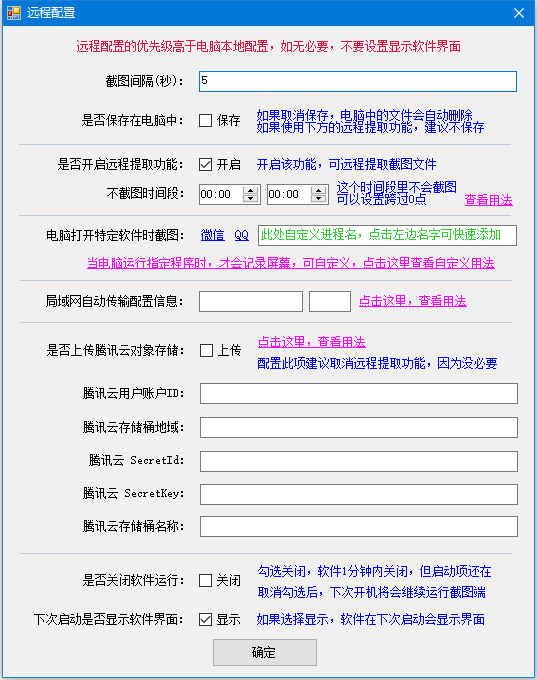
sglang
项目github仓库:
https://github.com/sgl-project/sglang
项目说明书:
https://sgl-project.github.io/start/install.html
资讯:
https://github.com/sgl-project/sgl-learning-materials?tab=readme-ov-file#the-first-sglang-online-meetup
快得离谱:

[外链图片转存中…(img-E3n1Ivz9-1731913508383)]
图来源:https://lmsys.org/blog/2024-09-04-sglang-v0-3/
Docker使用:
docker run --gpus device=0 \
--shm-size 32g \
-p 30000:30000 \
-v /root/xiedong/Qwen2-VL-7B-Instruct:/Qwen2-VL \
--env "HF_TOKEN=abc-1234" \
--ipc=host \
-v /root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4:/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4 \
lmsysorg/sglang:latest \
python3 -m sglang.launch_server --model-path /Qwen2-VL --host 0.0.0.0 --port 30000 --chat-template qwen2-vl --context-length 8192 --log-level-http warning
启动成功:

接口文档:
http://101.136.22.140:30000/docs
速度测试代码
import time
from openai import OpenAI
# 初始化OpenAI客户端
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:30000/v1')
# 定义图像路径
image_paths = [
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo256.jpeg",
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo512.jpeg",
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo768.jpeg",
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo1024.jpeg",
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo1280.jpeg",
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo2560.jpeg"
]
# 设置请求次数
num_requests = 10
# 存储每个图像的平均响应时间
average_speeds = {}
# 遍历每张图片
for image_path in image_paths:
total_time = 0
# 对每张图片执行 num_requests 次请求
for _ in range(num_requests):
start_time = time.time()
# 发送请求并获取响应
response = client.chat.completions.create(
model="/Qwen2-VL",
messages=[{
'role': 'user',
'content': [{
'type': 'text',
'text': 'Describe the image please',
}, {
'type': 'image_url',
'image_url': {
'url': image_path,
},
}],
}],
temperature=0.8,
top_p=0.8
)
# 记录响应时间
elapsed_time = time.time() - start_time
total_time += elapsed_time
# 打印当前请求的响应内容(可选)
print(f"Response for {image_path}: {response.choices[0].message.content}")
# 计算并记录该图像的平均响应时间
average_speed = total_time / num_requests
average_speeds[image_path] = average_speed
print(f"Average speed for {image_path}: {average_speed} seconds")
# 输出所有图像的平均响应时间
for image_path, avg_speed in average_speeds.items():
print(f"{image_path}: {avg_speed:.2f} seconds")
速度测试结果
sglang 测试结果:
| Model | 显存占用 (MiB) | 分辨率 | 处理时间 (秒) |
|---|---|---|---|
| Qwen2-VL-7B-Instruct | 70G | 256 x 256 | 1.71 |
| 512 x 512 | 1.52 | ||
| 768 x 768 | 1.85 | ||
| 1024 x 1024 | 2.05 | ||
| 1280 x 1280 | 1.88 | ||
| 2560 x 2560 | 3.26 |
纯transformer,不用加速框架,我之前的测了一张图的速度是:5.22 seconds,很慢。
附录-vllm速度测试
启动:
docker run --gpus device=0 \
-v /root/xiedong/Qwen2-VL-7B-Instruct:/Qwen2-VL \
-v /root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4:/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4 \
-p 30000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model /Qwen2-VL --gpu_memory_utilization=0.9
代码:
import time
import base64
from openai import OpenAI
# 初始化OpenAI客户端
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:30000/v1')
# 定义图像路径
image_paths = [
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo256.jpeg",
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo512.jpeg",
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo768.jpeg",
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo1024.jpeg",
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo1280.jpeg",
"/root/xiedong/Qwen2-VL-72B-Instruct-GPTQ-Int4/demo2560.jpeg"
]
# 设置请求次数
num_requests = 10
# 存储每个图像的平均响应时间
average_speeds = {}
# 将图片转换为 Base64 编码的函数
def image_to_base64(image_path):
with open(image_path, "rb") as img_file:
return base64.b64encode(img_file.read()).decode('utf-8')
# 遍历每张图片
for image_path in image_paths:
total_time = 0
# 将图片转换为 Base64 编码
image_base64 = image_to_base64(image_path)
# 对每张图片执行 num_requests 次请求
for _ in range(num_requests):
start_time = time.time()
# 发送请求并获取响应
response = client.chat.completions.create(
model="/Qwen2-VL",
messages=[{
'role': 'user',
'content': [{
'type': 'text',
'text': 'Describe the image please',
}, {
'type': 'image_url',
'image_url': {
'url': f"data:image/jpeg;base64,{image_base64}", # 使用Base64编码的图片
},
}],
}],
temperature=0.8,
top_p=0.8
)
# 记录响应时间
elapsed_time = time.time() - start_time
total_time += elapsed_time
# 打印当前请求的响应内容(可选)
print(f"Response for {image_path}: {response.choices[0].message.content}")
# 计算并记录该图像的平均响应时间
average_speed = total_time / num_requests
average_speeds[image_path] = average_speed
print(f"Average speed for {image_path}: {average_speed} seconds")
# 输出所有图像的平均响应时间
for image_path, avg_speed in average_speeds.items():
print(f"{image_path}: {avg_speed:.2f} seconds")
速度:
| Model | 显存占用 (MiB) | 分辨率 | 处理时间 (秒) |
|---|---|---|---|
| Qwen2-VL-72B-Instruct-GPTQ-Int4 | 70G | 256 x 256 | 1.50 |
| 512 x 512 | 1.59 | ||
| 768 x 768 | 1.61 | ||
| 1024 x 1024 | 1.67 | ||
| 1280 x 1280 | 1.81 | ||
| 2560 x 2560 | 1.97 |
https://www.dong-blog.fun/post/1856