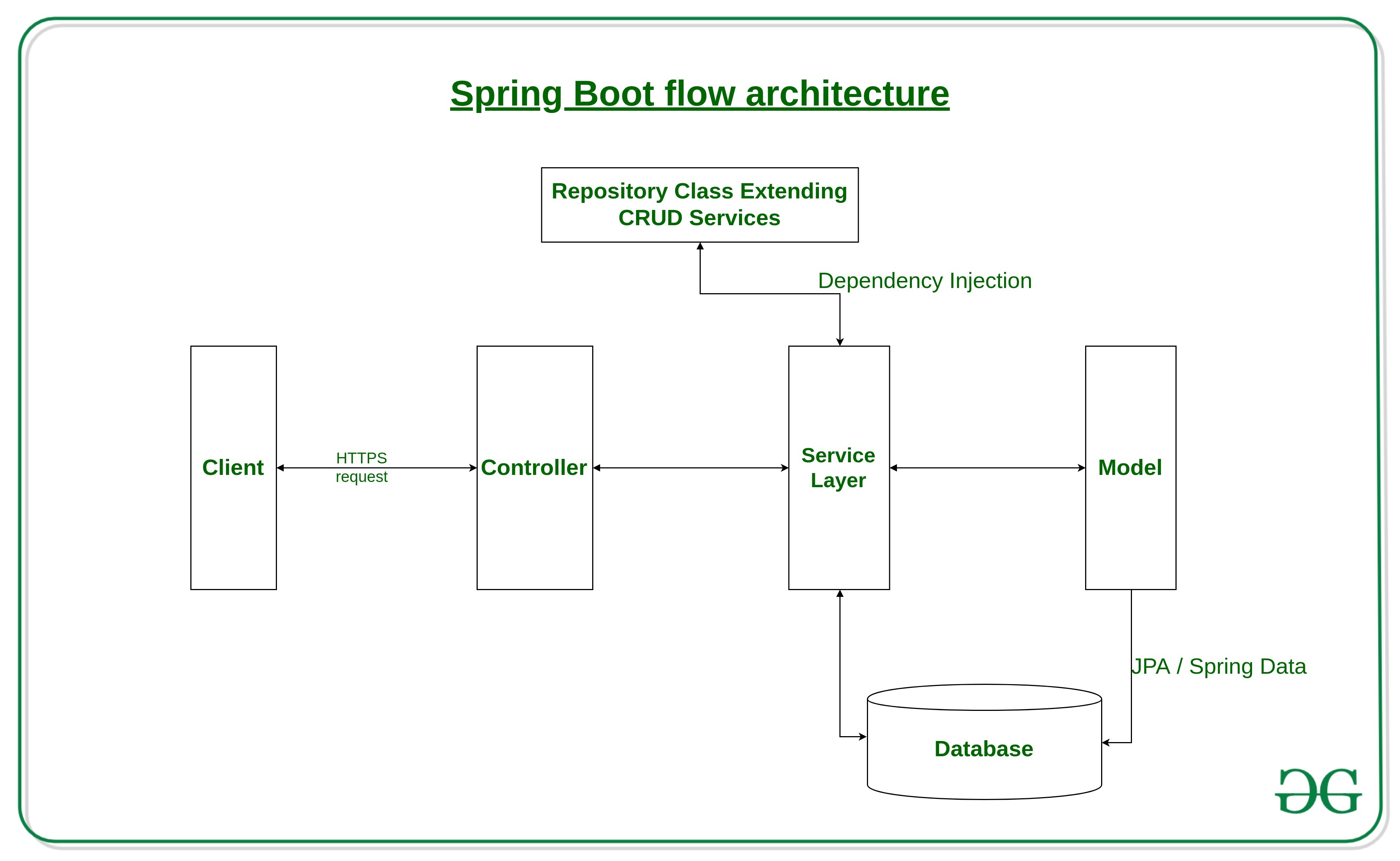
文章目录
- 数据库 基础操作
- 数据库设计的原则
- 数据库设计实例
- 一、需求分析
- 二、数据库设计
- 三、编码应用场景
- 小结
数据库 基础操作
一、数据库连接工具应用
-
SQL Server Management Studio(SSMS)用于连接SQL Server数据库
- 安装与启动
- 首先需要安装SQL Server Management Studio软件。安装完成后,打开软件,在“连接到服务器”对话框中,需要填写服务器名称(可以是本地主机名或者网络中的服务器名称)、身份验证方式(Windows身份验证或SQL Server身份验证)。如果是SQL Server身份验证,还需要输入用户名和密码。
- 连接成功后的操作
- 连接成功后,在对象资源管理器中可以看到数据库实例下的各种对象,如数据库、表、视图、存储过程等。可以展开数据库节点,查看其中的表结构、数据等内容。
- 安装与启动
-
MySQL Workbench用于连接MySQL数据库
- 连接设置
- 启动MySQL Workbench后,在主界面选择“新建连接”。需要填写连接名称(自定义)、主机名(通常是本地为127.0.0.1或远程服务器的IP地址)、端口号(MySQL默认是3306)、用户名和密码。填写完成后,点击“测试连接”按钮,若提示连接成功,则可以保存连接设置。
- 功能使用
- 在连接成功后的界面中,可以通过SQL编辑器编写SQL语句来操作数据库。例如,执行查询、插入、更新和删除操作。还可以使用可视化工具来设计数据库,如创建表、设置表之间的关系等。
- 连接设置
-
Navicat for MySQL(适用于多种数据库)
- 连接配置
- 打开Navicat,点击“连接”按钮,选择要连接的数据库类型(如MySQL)。在弹出的对话框中,填写连接名(自定义)、主机(本地或远程服务器地址)、端口、用户名和密码等信息。
- 优势和功能
- 它支持多种数据库管理系统,如MySQL、Oracle、SQL Server等。Navicat提供了直观的图形界面,方便用户管理数据库对象。例如,可以方便地进行数据库备份和还原操作,还可以通过数据传输功能在不同数据库之间迁移数据。
- 连接配置
二、数据库连接后常用的操作指令
- 数据查询(以SQL为例)
- 基本查询
SELECT * FROM table_name;:这是最基本的查询语句,用于从名为table_name的表中查询所有列的数据。例如,在一个员工信息表employees中,这条语句可以查询出所有员工的全部信息,包括姓名、年龄、职位等。SELECT column1, column2 FROM table_name;:用于查询指定列的数据。比如,SELECT name, age FROM employees;只会查询员工的姓名和年龄两列的数据。
- 条件查询
SELECT * FROM table_name WHERE condition;:condition是查询条件。例如,SELECT * FROM employees WHERE age > 30;会查询出年龄大于30岁的员工信息。- 条件还可以使用逻辑运算符,如
AND、OR。SELECT * FROM employees WHERE age > 30 AND department = 'IT';会查询出年龄大于30岁且在IT部门的员工信息。
- 基本查询
- 数据插入
INSERT INTO table_name (column1, column2,...) VALUES (value1, value2,...);:用于向表中插入新的数据。例如,在employees表中插入一名新员工的信息可以写成INSERT INTO employees (name, age, department) VALUES ('John', 25, 'HR');,这里将姓名为John、年龄为25岁、部门为HR的员工信息插入到表中。
- 数据更新
UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;:用于更新表中的数据。例如,UPDATE employees SET age = age + 1 WHERE department = 'IT';会将IT部门所有员工的年龄加1。
- 数据删除
DELETE FROM table_name WHERE condition;:用于删除满足条件的数据。例如,DELETE FROM employees WHERE name = 'John';会删除姓名为John的员工信息。
三、数据库备份要点
- 备份策略规划
- 全量备份
- 全量备份是对整个数据库进行备份,包括所有的数据和对象。这种备份方式恢复起来比较简单,但是备份时间长、占用空间大。一般适用于数据量较小的数据库或者在重要数据变更后进行。例如,对于一个小型的电商网站数据库,在每天凌晨业务量低的时候进行全量备份。
- 增量备份
- 增量备份只备份自上次备份(全量或增量)以来发生变化的数据。它可以减少备份时间和存储空间,但恢复时需要先恢复全量备份,再依次恢复增量备份。适合数据变化频繁且数据量大的数据库。比如,一个大型的金融数据库,在每天进行全量备份后,每隔一段时间(如每小时)进行增量备份。
- 差异备份
- 差异备份是备份自上次全量备份以来发生变化的数据。与增量备份相比,恢复时只需要全量备份和最近一次的差异备份。这种备份方式在备份时间和恢复复杂性上介于全量备份和增量备份之间。
- 全量备份
- 备份工具和方法
- 使用数据库管理系统自带的备份工具
- 例如,SQL Server可以使用备份向导或通过执行
BACKUP DATABASE命令来备份数据库。BACKUP DATABASE database_name TO DISK = 'backup_file_path';语句可以将名为database_name的数据库备份到指定的磁盘路径backup_file_path。 - MySQL可以使用
mysqldump命令进行备份。mysqldump -u username -p database_name > backup_file.sql可以将数据库database_name备份到backup_file.sql文件中,其中-u指定用户名,-p表示需要输入密码。
- 例如,SQL Server可以使用备份向导或通过执行
- 第三方备份工具
- 有些第三方备份工具可以提供更高级的备份功能,如定时备份、备份到云端等。这些工具可以跨数据库平台使用,并且能够更好地管理备份文件,如Veeam Backup & Replication等。
- 使用数据库管理系统自带的备份工具
- 备份验证和恢复测试
- 备份验证
- 备份完成后,需要验证备份文件是否完整和可用。可以通过检查备份文件的大小是否符合预期、尝试部分恢复备份文件中的数据等方法来验证。例如,对于SQL Server备份,可以使用
RESTORE VERIFYONLY命令来检查备份文件的完整性。
- 备份完成后,需要验证备份文件是否完整和可用。可以通过检查备份文件的大小是否符合预期、尝试部分恢复备份文件中的数据等方法来验证。例如,对于SQL Server备份,可以使用
- 恢复测试
- 定期进行恢复测试是确保备份有效的关键。可以在测试环境中模拟灾难恢复场景,使用备份文件恢复数据库,检查数据是否能够正确恢复,包括数据的完整性和一致性。这有助于在真正遇到问题时能够快速有效地恢复数据库。
- 备份验证
数据库设计的原则
-
规范化原则
- 第一范式(1NF)
- 要求数据库表的每一列都是不可分割的原子数据项。例如,在一个员工信息表中,不能将员工的姓名和联系方式放在同一列中,而应该分别用“姓名”列和“联系方式”列来表示。这样可以保证数据的清晰性和准确性,便于后续的查询、更新等操作。
- 第二范式(2NF)
- 在满足第一范式的基础上,要求非主属性完全依赖于主键。例如,在一个订单明细表中,主键是“订单编号”和“商品编号”的组合,“商品单价”和“商品数量”等属性完全依赖于这个主键。如果“商品单价”只依赖于“商品编号”,而不依赖于“订单编号”,就不符合第二范式,可能会导致数据冗余和更新异常。
- 第三范式(3NF)
- 在满足第二范式的基础上,要求非主属性不传递依赖于主键。例如,在一个部门员工表中,“部门名称”通过“部门编号”与“员工编号”(主键)相关联,如果“员工工资”直接依赖于“员工编号”,而不是通过“部门名称”等其他非主属性传递依赖,就满足第三范式。遵循第三范式可以进一步减少数据冗余,提高数据的一致性。
- 第一范式(1NF)
-
完整性原则
- 实体完整性
- 通过主键来保证实体的完整性。主键是表中用于唯一标识每条记录的列或列组合,不能为空且必须唯一。例如,在用户表中,用户编号作为主键,每条用户记录都有唯一的用户编号,这样可以确保用户实体的完整性,避免出现重复或无法区分的用户记录。
- 参照完整性
- 主要通过外键来实现。外键是一个表中的列,它引用了另一个表中的主键。例如,在订单表中有一个“用户编号”列作为外键,它引用了用户表中的“用户编号”主键。这就保证了订单记录中的用户必须是用户表中已经存在的用户,防止出现无效的关联。
- 用户定义完整性
- 根据具体的业务规则来定义数据的完整性。例如,在商品表中,规定商品价格不能为负数,这就是一种用户定义完整性。可以通过在数据库中设置检查约束(如在SQL中使用CHECK约束)来实现这种完整性要求,确保数据符合业务规则。
- 实体完整性
-
一致性原则
- 数据一致性维护
- 在数据库的多个表之间或者同一表的不同记录之间,数据应该保持一致。例如,在一个库存管理系统中,商品销售后,商品表中的库存数量和销售记录表中的销售数量应该是相互匹配的,不能出现库存数量已经减少,但销售记录没有更新,或者反之的情况。这可以通过使用事务来实现,在一个事务中包含对相关表的所有更新操作,确保这些操作要么全部成功,要么全部失败。
- 并发控制保证一致性
- 在多用户并发访问数据库时,要保证数据的一致性。例如,在银行系统中,多个用户同时对同一个账户进行操作(如转账、取款等),需要采用合适的并发控制机制,如锁机制(行锁、表锁等)或乐观并发控制(通过版本号等方式),以防止数据冲突和不一致的情况。
- 数据一致性维护
-
安全性原则
- 用户权限管理
- 根据用户的角色和职责,授予不同的权限。例如,在一个企业资源规划(ERP)系统中,普通员工可能只有查看和修改自己相关数据的权限,而部门经理可以查看和管理本部门所有员工的数据,系统管理员则可以对整个系统的数据进行全面管理。通过在数据库中设置用户权限(如在SQL Server中使用GRANT和REVOKE语句),可以确保数据的安全性,防止未经授权的访问和操作。
- 数据加密
- 对于敏感数据,如用户密码、银行卡信息等,进行加密处理。可以采用哈希函数(如MD5、SHA - 256等)对密码进行加密存储,在验证用户密码时,比较加密后的密码。对于需要保密的其他数据,可以使用对称加密(如AES)或非对称加密(如RSA)算法进行加密,确保数据在存储和传输过程中的安全性。
- 用户权限管理
-
性能优化原则
- 合理的表结构设计
- 避免设计过于复杂或冗余的表结构。例如,尽量减少大表中的列数,对于经常一起查询的列可以放在一个表中,而对于不经常使用的列可以考虑分离出来,以提高查询性能。同时,要注意表之间的关联关系,避免过多的关联导致复杂的查询和性能下降。
- 索引策略
- 合理使用索引可以提高查询速度。对于经常用于查询条件的列(如用户表中的用户名、商品表中的商品名称等),可以创建索引。但要注意避免过度索引,因为索引会增加数据插入、更新和删除的开销。例如,在一个日志表中,如果数据是频繁插入的,而且很少查询,就不适合创建大量索引。
- 存储过程和视图的有效利用
- 存储过程是预编译的SQL代码块,可以提高执行效率,并且可以封装复杂的业务逻辑。例如,在一个复杂的报表系统中,通过编写存储过程来生成报表数据,可以减少网络传输和数据库服务器的负担。视图是基于一个或多个表的虚拟表,可以简化复杂的查询。例如,通过创建一个包含多个表连接的视图,可以方便用户查询组合后的信息,而不需要每次都编写复杂的联合查询语句。
- 合理的表结构设计
数据库设计实例
以下是一个简单的图书馆管理系统数据库设计实例:
一、需求分析
图书馆管理系统需要处理图书信息、读者信息、借阅记录等。主要功能包括图书查询与借阅、读者注册与管理、借阅归还操作等。
二、数据库设计
-
图书表(books)
- book_id(主键):图书编号,例如“B001”,用于唯一标识每本图书。
- title:图书标题,如“《数据库系统概论》”。
- author:作者姓名,“王珊,萨师煊”。
- publisher:出版社,“高等教育出版社”。
- isbn:国际标准书号,如“978 - 7 - 04 - 022301 - 7”。
- quantity:馆藏数量,代表图书馆拥有的该图书的副本数量。
- available_quantity:可借阅数量,初始值等于 quantity,随着借阅和归还操作而变化。
-
读者表(readers)
- reader_id(主键):读者编号,如“R001”。
- name:读者姓名,“张三”。
- contact_info:联系方式,可以是手机号码或电子邮箱。
- address:读者地址。
- registered_date:注册日期,记录读者在图书馆注册的时间。
-
借阅记录表(borrowings)
- borrowing_id(主键):借阅记录编号,如“BR001”。
- reader_id:外键,关联读者表中的 reader_id,表明是哪位读者借阅。
- book_id:外键,关联图书表中的 book_id,表明借阅的是哪本图书。
- borrow_date:借阅日期,记录图书被借出的时间。
- due_date:应归还日期,根据图书馆规定设置的归还期限。
- return_date:归还日期,初始值为 NULL,在读者归还图书时更新。
三、编码应用场景
- 图书查询功能(基于 SQL 查询)
- 按标题查询:
- 当用户在图书馆系统的搜索框中输入图书标题的关键词,如“数据库”,系统执行以下 SQL 查询:
- 按标题查询:
SELECT * FROM books WHERE title LIKE '%数据库%';
- 这将返回所有标题中包含“数据库”的图书信息,包括图书编号、作者等,然后在用户界面显示查询结果。
- 按作者查询:
- 若用户输入作者姓名“王珊”,查询语句为:
- 按作者查询:
SELECT * FROM books WHERE author LIKE '%王珊%';
- 用于查找王珊所著的图书信息。
- 读者注册功能(基于 SQL 插入)
- 当新读者在图书馆注册时,系统收集读者信息(姓名、联系方式、地址等),然后执行以下 SQL 插入语句:
INSERT INTO readers (reader_id, name, contact_info, address, registered_date)
VALUES ('R010', '李四', 'lisi@example.com', 'XX 街 XX 号', CURDATE());
- 这里假设新读者编号为“R010”,使用
CURDATE()函数获取当前日期作为注册日期,将新读者信息插入到读者表中。
- 图书借阅功能(基于 SQL 插入和更新)
- 当读者借阅图书时,系统首先检查图书的可借阅数量是否大于 0。假设读者“R001”借阅图书“B001”,执行以下操作:
- 查询图书“B001”的可借阅数量:
- 当读者借阅图书时,系统首先检查图书的可借阅数量是否大于 0。假设读者“R001”借阅图书“B001”,执行以下操作:
SELECT available_quantity FROM books WHERE book_id = 'B001';
- 如果可借阅数量大于 0,则执行以下两条 SQL 语句:
- 插入借阅记录:
INSERT INTO borrowings (borrowing_id, reader_id, book_id, borrow_date, due_date)
VALUES ('BR010', 'R001', 'B001', CURDATE(), DATE_ADD(CURDATE(), INTERVAL 14 DAY));
- 更新图书的可借阅数量:
UPDATE books SET available_quantity = available_quantity - 1
WHERE book_id = 'B001';
- 这里
DATE_ADD(CURDATE(), INTERVAL 14 DAY)表示设置应归还日期为当前日期加 14 天。
- 图书归还功能(基于 SQL 更新)
- 当读者归还图书时,假设读者“R001”归还图书“B001”,系统执行以下 SQL 更新语句:
UPDATE borrowings SET return_date = CURDATE()
WHERE reader_id = 'R001' AND book_id = 'B001' AND return_date IS NULL;
UPDATE books SET available_quantity = available_quantity + 1
WHERE book_id = 'B001';
- 第一条语句更新借阅记录表中的归还日期,第二条语句增加图书的可借阅数量。
小结
-
注意事项
- 需求分析阶段
- 全面了解业务流程:与相关业务人员充分沟通,确保理解所有的数据处理场景。例如,对于一个电商系统,要清楚从商品上架、用户下单、支付、发货到售后的全流程数据需求。
- 明确数据范围和边界:确定哪些数据需要存储在数据库中,避免存储不必要的数据导致资源浪费。同时,要考虑数据的时效性,如是否需要存储历史数据以及存储多久。
- 概念设计阶段
- 合理抽象实体和关系:准确地将现实世界中的对象抽象为实体,定义清晰的实体间关系(一对一、一对多、多对多)。例如,在学校管理系统中,一个学生可以选多门课程(多对多关系),需要通过选课表来正确体现这种关系。
- 考虑未来扩展性:预留一定的灵活性,以便在业务扩展或变化时能够方便地添加新的实体、属性或关系。比如,在设计产品数据库时,为产品可能新增的属性预留一些通用的扩展字段。
- 逻辑设计阶段
- 遵循规范化原则:尽量将数据库设计到第三范式(3NF)或更高范式,以减少数据冗余和更新异常。例如,在员工部门信息表中,将部门信息单独建表,通过外键关联员工表,避免员工记录中重复存储部门信息。
- 选择合适的数据类型:根据数据的实际性质和范围选择恰当的数据类型。例如,对于年龄字段,使用整数类型而不是字符串类型;对于可能很长的文本描述,选择合适的文本类型(如TEXT)。
- 物理设计阶段
- 考虑存储引擎和索引策略:根据数据库的读写特点选择合适的存储引擎。对于经常查询的列创建索引,但要注意避免过度索引。例如,对于日志表这种写入频繁但查询相对较少的表,要谨慎使用索引,以免影响写入性能。
- 数据分区(如果适用):对于大数据量的数据库,考虑数据分区策略,如按时间、地域等分区,以提高查询效率和管理便利性。比如,在大型的销售数据仓库中,按季度分区存储销售数据。
- 安全设计方面
- 用户权限管理:为不同用户角色定义明确的权限,限制用户对数据的访问和操作范围。例如,在企业资源规划(ERP)系统中,普通员工只能查看和修改自己相关的数据,而管理员可以访问和修改所有数据。
- 数据加密:对敏感数据进行加密,如用户密码、银行卡信息等。采用合适的加密算法,如哈希函数用于密码存储,对称或非对称加密算法用于其他敏感数据。
- 性能优化方面
- 优化查询语句:编写高效的SQL查询语句,避免复杂的嵌套查询和子查询,尽量使用连接(JOIN)来代替子查询。例如,在关联多个表查询数据时,使用合适的连接方式(INNER JOIN、LEFT JOIN等)。
- 合理使用存储过程和视图:存储过程可以封装复杂的业务逻辑,提高执行效率;视图可以简化复杂的查询。例如,在报表系统中,通过存储过程生成报表数据,通过视图提供给用户简洁的查询接口。
- 备份和恢复策略
- 制定合理的备份计划:包括备份的频率(如全量备份的周期、增量备份的间隔)、备份的存储位置(本地磁盘、外部存储设备、云端)等。例如,对于重要的生产数据库,每天进行全量备份,每小时进行增量备份,并将备份存储在异地的存储设备上。
- 定期进行恢复测试:确保备份数据在需要时能够成功恢复,并且数据的完整性和一致性得到保证。
- 需求分析阶段
-
经常出现问题的点
- 数据冗余和更新异常
- 问题表现:由于数据库设计不符合规范化原则,可能导致数据在多个地方重复存储。例如,在一个订单商品表中,如果把商品的所有信息(如名称、价格、描述)都存储在每条订单商品记录中,当商品信息需要更新时,就需要在多个地方修改,容易出现更新不一致的情况。
- 解决方法:按照规范化规则对数据库进行重新设计,将数据合理地分布到不同的表中,通过外键关联来减少数据冗余。
- 数据完整性问题
- 问题表现:包括实体完整性(如主键重复或为空)、参照完整性(外键引用不存在的主键)和用户定义完整性(如违反业务规则的数据,如价格为负数)。例如,在插入一条订单记录时,关联的用户编号在用户表中不存在,导致数据不一致。
- 解决方法:在数据库中设置合适的约束条件,如主键约束、外键约束、检查约束等。在代码层面,在进行数据插入和更新操作时,进行数据合法性检查。
- 性能瓶颈
- 问题表现:随着数据量的增加和并发访问的增多,数据库性能下降。可能是由于查询效率低下(如缺少必要的索引、查询语句复杂)、存储引擎选择不当或者没有合理的缓存策略。例如,在一个没有索引的大型数据表中进行频繁的搜索操作,会导致查询速度非常慢。
- 解决方法:分析性能瓶颈所在,优化查询语句,合理创建索引,选择适合业务场景的存储引擎,考虑使用缓存技术(如Redis缓存)来减轻数据库的压力。
- 并发控制问题
- 问题表现:在多用户同时访问和修改数据时,可能出现数据冲突、死锁等情况。例如,两个用户同时对同一个账户进行转账操作,如果没有合适的并发控制机制,可能导致账户余额计算错误。
- 解决方法:采用合适的并发控制策略,如使用数据库的锁机制(行锁、表锁)或乐观并发控制(通过版本号等方式)来保证数据的一致性。
- 安全漏洞
- 问题表现:包括未经授权的访问、数据泄露等。例如,用户密码以明文形式存储,容易被窃取;权限管理不当,导致用户可以访问和操作不应访问的数据。
- 解决方法:加强用户权限管理,对敏感数据进行加密,定期进行安全审计,及时发现和修复安全漏洞。
- 数据迁移和兼容性问题
- 问题表现:在系统升级、更换数据库或整合其他系统数据时,可能出现数据格式不兼容、数据丢失或转换错误等问题。例如,将旧数据库中的数据迁移到新数据库时,由于数据类型或表结构的差异,导致部分数据无法正确迁移。
- 解决方法:在迁移前进行详细的数据评估和转换规划,编写数据迁移脚本,在迁移后进行数据验证和测试,确保数据的完整性和兼容性。
- 数据冗余和更新异常