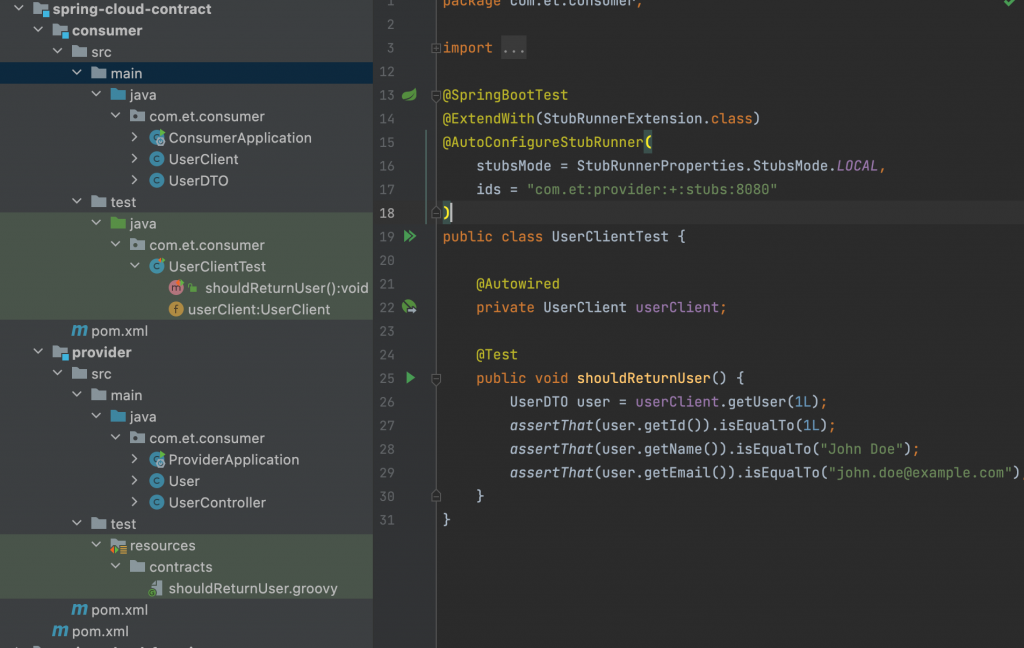
论文解读系列文章目录
文章目录
- 论文解读系列文章目录
- 一、BR(Boutell等人,2004年)将ML任务分解为多个二分类任务,但忽略了标签之间的关联性。为了利用标签之间的关联性,提出了LP(Tsoumakas和Katakis,2006年)、CC(Read等人,2011年)和Seq2Seq(Yang等人,2018年)等方法。为了进一步探索标签之间的关系,最近的研究采用了强化学习方法(Yang等人,2019年)、多任务模式(Tsai和Lee,2020年)和图卷积网络(GCN)模型(Chen等人,2019b年)。给我解释一下
- 二、仔细讲讲标签特定表示
- 三、标签特定表示无法有效捕捉标签之间的顺序和相互依赖关系?
- 四、举个例子
- 五、单模态标签特征提取,举个简单带计算的例子
- 六、为了实现跨模态特征融合,我们使用一个包含三个网络 f v a 2 t ( ⋅ ) f^{va2t}(\cdot) fva2t(⋅)、 f t a 2 v ( ⋅ ) f^{ta2v}(\cdot) fta2v(⋅) 和 f t v 2 a ( ⋅ ) f^{tv2a}(\cdot) ftv2a(⋅) 的两级重构过程(详细分析在附录A中)。为什么这3个网络可以实现重构?
- 七、简练一点
- 八、最后一个Step举个简单的例子
- 九、洗牌有何作用
一、BR(Boutell等人,2004年)将ML任务分解为多个二分类任务,但忽略了标签之间的关联性。为了利用标签之间的关联性,提出了LP(Tsoumakas和Katakis,2006年)、CC(Read等人,2011年)和Seq2Seq(Yang等人,2018年)等方法。为了进一步探索标签之间的关系,最近的研究采用了强化学习方法(Yang等人,2019年)、多任务模式(Tsai和Lee,2020年)和图卷积网络(GCN)模型(Chen等人,2019b年)。给我解释一下
这段话描述了多标签(ML)情感识别任务中不同的方法及其演变过程。具体来说,它讲解了如何处理标签之间的关系,以及如何提高多标签分类模型的性能。下面逐步解释各个方法和背景:
-
BR (Boutell et al., 2004):
- BR 方法(Binary Relevance)是一种简单的多标签分类方法,它将多标签问题分解为多个二分类问题。在这种方法中,每个标签被独立处理,将每个标签的预测看作一个二分类问题(即标签是否存在)。然而,这种方法存在忽略标签之间关联性的问题。也就是说,不同标签之间的潜在相关性和依赖性没有被考虑,可能会导致信息的丢失。
-
LP (Tsoumakas 和 Katakis, 2006) 和 CC (Read et al., 2011):
- 为了解决BR方法中的问题,LP(Label Powerset)方法提出了一种新的方式,它通过将每个标签的组合看作一个类别来处理所有标签的关系。LP通过将标签的所有组合视为一个单独的标签,从而考虑了标签之间的关联性。
- CC(Classical Classifier Chains)方法进一步改进了标签关系的建模。它将多个二分类器串联起来,模型不仅考虑每个标签的特征,还考虑了先前标签的预测结果。这使得每个分类器都能够利用前面分类器的输出信息,从而捕获标签之间的关联性。
-
Seq2Seq (Yang et al., 2018):
- Seq2Seq(Sequence-to-Sequence)方法是通过深度学习方法进一步提高标签关系建模的能力。Seq2Seq模型通常用于处理序列数据,它能够在标签序列中捕捉到更复杂的依赖关系。对于多标签情感识别任务,Seq2Seq模型通过将多个标签视为一个序列来进行建模,从而能够有效捕捉标签之间的顺序和相互依赖关系。
-
进一步探索标签关系的方法:
- 强化学习方法(Yang et al., 2019):近年来,强化学习被引入到多标签任务中,以进一步增强标签之间的关系建模。强化学习通过奖励机制来优化标签的选择和预测过程,从而提高标签关系的捕捉能力。
- 多任务学习(Tsai 和 Lee, 2020):多任务学习方法通过同时处理多个任务来共享学习的信息。通过共同训练多个任务,模型能够更好地理解标签之间的相互关系,从而提高多标签任务的表现。
- GCN(图卷积网络,Chen et al., 2019b):GCN是一种基于图的深度学习方法,它能够在图结构数据上进行操作。在多标签情感识别中,GCN能够通过图结构来捕捉标签之间的依赖关系,能够更好地处理标签之间的复杂相互作用。
-
标签特定表示:
- 在传统的多标签学习中,往往会使用单一的标签表示方法,这可能无法有效捕捉每个标签的独特信息。为了解决这个问题,近年来的研究(例如Chen et al., 2019a, b)提出了标签特定表示,即为每个标签学习一个独特的表示。这种方法能够捕捉每个标签的最相关特征,进而提高模型的判别能力。
- 这种方法已经在许多实际应用中取得了成功,比如在情感分析、情感识别等领域,使用标签特定表示可以显著提高模型的精度和鲁棒性。
总结:
这段话总结了多标签情感识别任务中不同的模型和方法,重点在于如何处理和利用标签之间的关联性。早期的BR方法忽略了标签的相关性,而后来的方法如LP、CC、Seq2Seq以及更先进的强化学习、多任务学习和GCN模型则尝试捕捉这些标签之间的关系,从而提升分类性能。此外,标签特定表示方法进一步增强了每个标签的判别力,使得多标签学习在实际任务中取得更好的效果。
二、仔细讲讲标签特定表示
标签特定表示(Label-Specific Representations)是近年来多标签学习中的一个重要发展,特别是在多标签情感识别等任务中,它显著提高了模型的表现。下面我将详细解释这种方法的背景、原理、优势及其应用。
- 传统多标签学习中的问题
在传统的多标签学习中,通常会为所有标签使用一个统一的表示方法。这意味着无论标签的种类或特点如何,所有标签都会共享一个相同的表示方式。这种方法的问题在于:
-
标签差异的忽视:每个标签可能具有不同的特征或重要性,例如,在情感识别任务中,“愤怒”与“快乐”这两个情感标签的特征可能完全不同。统一的标签表示无法有效捕捉每个标签的特性。
-
信息丢失:对于多标签情感识别任务,单一表示方式可能无法包含所有标签的判别性信息,导致模型的精度和泛化能力受到限制。
因此,传统方法在处理复杂的标签间关系时可能出现表现不佳的情况,尤其是在标签本身具有高度异质性的情况下。
- 标签特定表示的提出
为了解决这个问题,标签特定表示的方法应运而生。这个方法的核心思想是为每个标签单独学习一个表示,而不是为所有标签使用统一的表示。具体来说,这种方法通过以下几个步骤来改进模型的表现:
-
为每个标签学习一个独特的表示:通过训练不同的网络或模型部分来为每个标签生成专门的表示。这样,每个标签的特征可以被模型独立学习和捕捉,确保每个标签的独特信息被充分表达。
-
捕捉最相关的特征:标签特定表示能够根据每个标签的特性,学习到与该标签最相关的特征,从而更精确地反映每个标签的特征分布。这对于多标签情感识别任务尤为重要,因为不同情感标签(如愤怒、悲伤、喜悦等)具有截然不同的特征。
- 标签特定表示的优势
标签特定表示方法具有以下几个显著的优势:
-
提高判别能力:由于每个标签都有一个单独的表示,模型可以专注于捕捉该标签的最相关信息,避免了不同标签之间信息的干扰,进而提高了判别能力。尤其是在情感分析等任务中,这种方法能显著提高对细粒度情感标签的区分能力。
-
增强模型的灵活性:标签特定表示使得模型能够灵活地处理不同标签的特征,增加了模型对不同标签的适应性,特别是在标签特性差异较大的情况下,能够更好地学习每个标签的个性化特征。
-
提高精度和鲁棒性:通过为每个标签独立学习最相关的特征,模型可以更加精准地对每个标签进行预测,从而提高整体的精度。此外,标签特定表示增强了模型的鲁棒性,因为每个标签都具有独立的表示,不容易受到其他标签噪声的影响。
- 标签特定表示的应用
标签特定表示已经在多个领域的多标签学习任务中得到了成功应用,特别是在情感分析和情感识别等任务中。以下是一些典型应用:
-
情感分析:在情感分析中,情感标签(如“愤怒”、“悲伤”、“快乐”等)之间可能具有很大的差异。标签特定表示可以为每种情感标签学习独特的表示,从而更好地捕捉各个情感的特征,并提高情感分类的准确性。
-
多标签情感识别:对于同时识别多个情感标签的任务(例如“喜悦”和“悲伤”可能同时出现在同一个文本中),标签特定表示能够帮助模型在多标签情况下分别优化每个标签的特征学习,减少标签间的干扰。
-
文本情感分析中的多任务学习:在多任务学习中,标签特定表示允许每个任务(如情感分类、情感强度预测等)有自己的标签表示,使得模型在多个任务上都能进行有效的特征学习。
-
多模态情感识别:对于多模态情感识别(如结合语音、图像和文本的情感识别任务),标签特定表示可以帮助模型针对每种模态的输入,学习最相关的标签表示,从而更准确地进行情感分类。
- 成功案例
-
Chen et al. (2019) 的研究表明,标签特定表示能够显著提高多标签情感识别的精度,尤其是在情感标签具有高度异质性的情况下。通过引入标签特定表示,模型能够为每个情感标签提取出最具判别性的特征,从而提高情感分类的准确率。
-
Huang et al. (2016) 和 Xiao et al. (2019) 等研究也展示了标签特定表示在情感分析等领域的成功应用,表明这种方法能够有效增强模型的性能和鲁棒性。
- 总结
标签特定表示是一种提高多标签学习中标签判别能力的重要方法。通过为每个标签学习独特的表示,模型能够更好地捕捉每个标签的特征,从而提高多标签情感识别和其他多标签任务的准确性。随着深度学习技术的发展,标签特定表示方法已成为情感分析、情感识别等领域中重要的技术手段,并在多个应用场景中取得了显著的成果。
如果您有更多问题或需要进一步探讨标签特定表示的细节,欢迎继续交流!
三、标签特定表示无法有效捕捉标签之间的顺序和相互依赖关系?
是的,您提到的问题是 标签特定表示 方法的一项潜在限制。在多标签学习中,标签之间通常存在一定的关系或依赖性,比如某些标签可能是相互关联的或有某种顺序。标签特定表示方法通过为每个标签单独学习特征表示,能够提高每个标签的判别能力,但它并未考虑标签之间的关系,因此可能无法有效捕捉标签之间的顺序性和相互依赖性。下面我们来详细分析这个问题:
- 标签特定表示的原理
标签特定表示的基本思路是为每个标签学习一个独立的表示,捕捉该标签最相关的特征。这对于多标签情感识别等任务非常有效,因为不同标签(如“愤怒”和“快乐”)通常具有不同的特征和表现形式。例如,“愤怒”可能与更高的音量和情绪化的语言相关,而“快乐”则可能与更平和的语调和积极的词汇有关。
标签特定表示通过为每个标签单独训练一个特征表示来提高每个标签的独立判别能力,这对于减少标签之间的干扰、提高精度和鲁棒性非常有帮助。然而,它忽视了标签之间的关系,即标签如何彼此相互影响或依赖。
- 标签间的顺序和相互依赖性
在某些任务中,标签之间可能具有强烈的依赖关系。例如,在情感分析中,可能存在以下情况:
- 标签的顺序性:某些标签可能存在顺序关系。例如,在情感强度分析中,"轻微的愤怒"和"强烈的愤怒"可能是两个不同的标签,具有顺序性。在这种情况下,理解情感的强度(从轻微到强烈)非常重要。
- 标签之间的关联性:某些标签可能在某些上下文中相互依赖。例如,“快乐”和“悲伤”可能在某些情景中不太可能同时出现,而“愤怒”和“焦虑”可能具有较强的共现关系。
- 标签特定表示的局限性
由于标签特定表示只考虑每个标签的独立性,它无法有效地捕捉和利用标签之间的顺序性和相互依赖关系。具体来说:
- 顺序性:标签特定表示方法没有机制去捕捉标签之间的顺序或渐变关系。例如,在情感分析任务中,标签的强度(如“轻微愤怒”到“极度愤怒”)可能对模型预测产生重要影响,但标签特定表示无法明确地反映标签强度的变化趋势。
- 相互依赖关系:标签特定表示方法将每个标签视为独立的实体,忽略了标签之间的共现模式。例如,在情感识别任务中,"快乐"和"悲伤"通常很少同时出现在同一情感状态中,而标签特定表示方法无法捕捉到这种共现或排斥关系。
- 如何改进标签特定表示的局限性?
为了解决标签特定表示方法的这些局限性,学者们提出了多种方法来结合标签间的顺序性和依赖性。以下是一些常见的解决方案:
a. 序列模型(如RNN、LSTM、GRU)
序列模型(如递归神经网络(RNN)、长短期记忆网络(LSTM)和门控循环单元(GRU))通过建模标签之间的顺序依赖来解决这个问题。这些模型能够处理标签的时间或顺序结构,捕捉标签之间的顺序关系和依赖性。
例如,使用LSTM对标签进行建模时,模型不仅能够处理每个标签的特征,还能根据前一个标签的输出动态调整当前标签的预测,这使得它能够捕捉到标签之间的顺序性和依赖关系。
b. 图神经网络(GCN)
图神经网络(GCN)是另一种有效的方法,它可以通过图结构建模标签之间的依赖关系。GCN能够在节点(标签)之间传播信息,捕捉标签之间的相互关系和依赖性。特别是在多标签学习中,GCN可以处理标签之间的复杂交互,从而提高模型对标签关系的理解。
c. 联合标签表示(Joint Label Representation)
一些研究提出了联合标签表示的方法,它试图通过将多个标签的表示结合在一起,来同时学习标签的独特特征和它们之间的关系。通过联合表示,模型不仅可以捕捉每个标签的特征,还能够学习标签之间的关联性。
d. 多任务学习(Multi-task Learning)
多任务学习是一种可以通过共享学习到的表示来捕捉标签依赖关系的方法。在多任务学习中,不同的标签或任务之间共享某些参数或网络层,从而使得模型能够学习到标签之间的潜在依赖关系。
e. 注意力机制(Attention Mechanism)
在多标签学习中,注意力机制可以用来为每个标签分配不同的权重,捕捉标签之间的相关性。通过关注那些对预测最重要的标签,注意力机制能够帮助模型在处理多标签任务时考虑标签之间的依赖。
- 总结
标签特定表示方法在处理多标签学习任务时非常有效,尤其是在每个标签有独特特征时,但它的一个主要局限性是无法捕捉标签之间的顺序性和相互依赖性。为了解决这个问题,近年来的研究采用了序列模型、图神经网络、多任务学习等技术,这些方法能够有效地捕捉标签之间的关系,从而增强模型的表现。
希望这些解释能够帮助您理解标签特定表示的局限性以及如何通过其他方法来弥补这一不足。如果您有更多问题,欢迎随时提问!
四、举个例子
好的,下面我们通过一个简单的例子,结合情感分析任务中的标签“愤怒”和“快乐”,演示为什么单一标签表示无法有效捕捉到不同标签的判别特征。
任务背景:
假设我们有一个简单的情感分析任务,需要根据文本来判断情感标签。我们用情感特征向量来表示每个情感标签的特征。对于“愤怒”和“快乐”这两个标签,它们的特征存在较大的差异。
假设的特征表示:
-
愤怒的情感特征可能包含:
- 尖锐的语气(高负向情绪)
- 负面词汇(如“愤怒”、“生气”)
- 快速语速(时间特征)
假设我们用一个3维的向量表示这些特征,向量表示为:
F anger = [ 1 , 0.9 , 0.8 ] \mathbf{F_{\text{anger}}} = [1, 0.9, 0.8] Fanger=[1,0.9,0.8]
其中,1代表情感的强度(愤怒强烈),0.9和0.8分别代表负面情绪词汇的强度和语速。 -
快乐的情感特征可能包含:
- 积极的语气(高正向情绪)
- 正面词汇(如“开心”、“高兴”)
- 语调的上扬(语音特征)
快乐的向量可以表示为:
F happy = [ 0.3 , 0.7 , 0.9 ] \mathbf{F_{\text{happy}}} = [0.3, 0.7, 0.9] Fhappy=[0.3,0.7,0.9]
这里,0.3代表情感强度(相对于愤怒较弱),0.7和0.9代表正面情绪词汇和语调上扬的特征。
问题分析:使用单一标签表示
如果我们使用一个单一标签表示方法(例如使用一个共享的表示来处理所有标签),我们可能会把“愤怒”和“快乐”这两个标签混淆。为了简化,我们可以将这两个标签的特征合并成一个统一的表示:
-
单一表示方法:将这两个标签的特征向量拼接或平均化,得到一个“通用”的情感表示。
如果我们对这两个标签的特征取平均,可以得到:
F average = F anger + F happy 2 \mathbf{F_{\text{average}}} = \frac{\mathbf{F_{\text{anger}}} + \mathbf{F_{\text{happy}}}}{2} Faverage=2Fanger+Fhappy
计算结果:
F average = [ 1 , 0.9 , 0.8 ] + [ 0.3 , 0.7 , 0.9 ] 2 = [ 0.65 , 0.8 , 0.85 ] \mathbf{F_{\text{average}}} = \frac{[1, 0.9, 0.8] + [0.3, 0.7, 0.9]}{2} = [0.65, 0.8, 0.85] Faverage=2[1,0.9,0.8]+[0.3,0.7,0.9]=[0.65,0.8,0.85]这个结果是一个单一表示,它试图为所有情感标签(包括愤怒和快乐)提供一个共享的特征表示。但是,如下问题可能发生:
-
特征丢失:通过简单地对愤怒和快乐的特征进行平均化,我们丧失了两者之间的显著差异。例如,愤怒的情感强度较大,而快乐的情感强度较小。通过平均化后,我们无法精确地捕捉这两者之间的差异。
-
信息混合:愤怒和快乐的特征并不完全兼容。愤怒的特征如负面情绪和快速语速与快乐的特征(正面情绪和语调上扬)是对立的。通过单一表示,这些信息混合在一起,可能导致情感分析模型无法准确区分这两个标签。
单一标签表示的问题:
-
模糊分类边界:由于“愤怒”和“快乐”有很大的特征差异,单一标签表示无法有效处理这种差异。上述的平均特征向量([0.65, 0.8, 0.85])可能无法精确表示任何一个具体标签。
-
无法捕捉独特判别特征:每个情感标签的独特特征(如愤怒的语气尖锐、负面情绪,快乐的正面词汇、语调上扬)在单一表示中被混合,导致模型无法学到这些判别性强的特征。
改进方法:标签特定表示
为了解决上述问题,可以采用标签特定表示的方法。每个标签会有一个独特的表示,而不是共享一个通用表示。对于“愤怒”和“快乐”,我们为每个标签学习独立的特征表示,这样可以确保模型能够充分捕捉每个标签的独特信息,而不混淆它们之间的差异。
- 愤怒的标签表示: F anger = [ 1 , 0.9 , 0.8 ] \mathbf{F_{\text{anger}}} = [1, 0.9, 0.8] Fanger=[1,0.9,0.8]
- 快乐的标签表示: F happy = [ 0.3 , 0.7 , 0.9 ] \mathbf{F_{\text{happy}}} = [0.3, 0.7, 0.9] Fhappy=[0.3,0.7,0.9]
总结
单一标签表示方法将所有标签的特征融合为一个统一的表示,无法有效捕捉每个标签的独特特征,尤其是在标签之间具有明显差异时。为了提高分类性能,标签特定表示方法通过为每个标签学习独立的表示,能够保留标签间的差异,进而提高模型的判别能力。
通过上述的简单计算示例,我们可以看到标签特定表示的重要性,尤其是在情感分析任务中,不同情感标签具有不同的判别性特征,因此需要独立的表示来更好地捕捉每个标签的特征。
五、单模态标签特征提取,举个简单带计算的例子
在这个例子中,我们使用的是基于Transformer的提取器和多标签注意力机制来处理多模态情感识别任务。下面我将通过一个简单的例子来演示如何计算标签特定的表示,并在此过程中进行一些基础的计算。
任务背景
我们有多个模态(例如文本、音频、图像等),对于每个模态,首先通过Transformer编码器将原始特征序列转换为高级嵌入序列。然后,对于每个情感标签,使用标签特定的注意力机制来从每个模态的嵌入序列中提取最相关的信息。
步骤 1:Transformer编码器
首先,对于某个模态
m
m
m(例如文本模态),我们有一个输入特征序列
X
m
∈
R
n
m
×
d
m
X^m \in \mathbb{R}^{n_m \times d_m}
Xm∈Rnm×dm,其中
n
m
n_m
nm 是序列的长度(例如,句子的词数),
d
m
d_m
dm 是每个词的特征维度(例如词嵌入的维度)。
通过Transformer编码器,将该输入映射到一个高级嵌入序列 H m ∈ R n m × d H^m \in \mathbb{R}^{n_m \times d} Hm∈Rnm×d,其中 d d d 是嵌入的维度。
假设:
- 模态 m m m的输入特征序列 X m X^m Xm 具有长度 n m = 4 n_m=4 nm=4 和每个特征维度 d m = 3 d_m=3 dm=3。
- 经过Transformer编码器后,我们得到了嵌入序列 H m H^m Hm,其维度为 n m × d = 4 × 2 n_m \times d = 4 \times 2 nm×d=4×2(即每个词的嵌入维度为2)。
步骤 2:计算标签特定的表示(标签注意力)
对于每个情感标签
j
j
j,我们需要通过标签特定的注意力机制来计算该标签在每个模态下的嵌入表示。这里我们使用注意力机制来加权每个位置的嵌入。
假设:
-
我们有两个情感标签:标签1(“愤怒”)和标签2(“快乐”)。
-
模态 m m m 的嵌入序列 H m H^m Hm 是:
H m = [ 0.5 0.7 0.2 0.4 0.3 0.6 0.1 0.2 ] H^m = \begin{bmatrix} 0.5 & 0.7 \\ 0.2 & 0.4 \\ 0.3 & 0.6 \\ 0.1 & 0.2 \end{bmatrix} Hm= 0.50.20.30.10.70.40.60.2
每一行表示一个位置的嵌入(例如,句子中的每个词)。 -
标签特定的注意力参数:对于每个标签,我们有对应的注意力参数 w j m ∈ R d w_j^m \in \mathbb{R}^{d} wjm∈Rd,这里我们假设标签1的注意力参数为:
w 1 m = [ 0.6 0.8 ] w_1^m = \begin{bmatrix} 0.6 \\ 0.8 \end{bmatrix} w1m=[0.60.8]
对于标签2:
w 2 m = [ 0.3 0.4 ] w_2^m = \begin{bmatrix} 0.3 \\ 0.4 \end{bmatrix} w2m=[0.30.4]
计算步骤:
-
计算注意力权重 α i j m \alpha_{ij}^m αijm:对于每个位置 i i i 和标签 j j j,我们需要计算注意力权重 α i j m \alpha_{ij}^m αijm。根据公式:
α i j m = exp ( w j m T h i m ) ∑ i = 1 n m exp ( w j m T h i m ) \alpha_{ij}^m = \frac{\exp({w_{j}^{m}}^\mathsf{T} h_{i}^{m})}{\sum_{i=1}^{n_m} \exp({w_{j}^{m}}^\mathsf{T} h_{i}^{m})} αijm=∑i=1nmexp(wjmThim)exp(wjmThim)先计算每个位置的注意力分数。
-
对于标签1(“愤怒”):
- 第1个位置的注意力分数: ω 1 = 0.6 × 0.5 + 0.8 × 0.7 = 0.3 + 0.56 = 0.86 \omega_1 = 0.6 \times 0.5 + 0.8 \times 0.7 = 0.3 + 0.56 = 0.86 ω1=0.6×0.5+0.8×0.7=0.3+0.56=0.86
- 第2个位置的注意力分数: ω 2 = 0.6 × 0.2 + 0.8 × 0.4 = 0.12 + 0.32 = 0.44 \omega_2 = 0.6 \times 0.2 + 0.8 \times 0.4 = 0.12 + 0.32 = 0.44 ω2=0.6×0.2+0.8×0.4=0.12+0.32=0.44
- 第3个位置的注意力分数: ω 3 = 0.6 × 0.3 + 0.8 × 0.6 = 0.18 + 0.48 = 0.66 \omega_3 = 0.6 \times 0.3 + 0.8 \times 0.6 = 0.18 + 0.48 = 0.66 ω3=0.6×0.3+0.8×0.6=0.18+0.48=0.66
- 第4个位置的注意力分数: ω 4 = 0.6 × 0.1 + 0.8 × 0.2 = 0.06 + 0.16 = 0.22 \omega_4 = 0.6 \times 0.1 + 0.8 \times 0.2 = 0.06 + 0.16 = 0.22 ω4=0.6×0.1+0.8×0.2=0.06+0.16=0.22
将这些分数带入到软最大化函数中(softmax)计算权重 α i j m \alpha_{ij}^m αijm:
α 1 m = exp ( 0.86 ) exp ( 0.86 ) + exp ( 0.44 ) + exp ( 0.66 ) + exp ( 0.22 ) ≈ 0.328 \alpha_1^m = \frac{\exp(0.86)}{\exp(0.86) + \exp(0.44) + \exp(0.66) + \exp(0.22)} \approx 0.328 α1m=exp(0.86)+exp(0.44)+exp(0.66)+exp(0.22)exp(0.86)≈0.328
α 2 m = exp ( 0.44 ) exp ( 0.86 ) + exp ( 0.44 ) + exp ( 0.66 ) + exp ( 0.22 ) ≈ 0.181 \alpha_2^m = \frac{\exp(0.44)}{\exp(0.86) + \exp(0.44) + \exp(0.66) + \exp(0.22)} \approx 0.181 α2m=exp(0.86)+exp(0.44)+exp(0.66)+exp(0.22)exp(0.44)≈0.181
α 3 m = exp ( 0.66 ) exp ( 0.86 ) + exp ( 0.44 ) + exp ( 0.66 ) + exp ( 0.22 ) ≈ 0.261 \alpha_3^m = \frac{\exp(0.66)}{\exp(0.86) + \exp(0.44) + \exp(0.66) + \exp(0.22)} \approx 0.261 α3m=exp(0.86)+exp(0.44)+exp(0.66)+exp(0.22)exp(0.66)≈0.261
α 4 m = exp ( 0.22 ) exp ( 0.86 ) + exp ( 0.44 ) + exp ( 0.66 ) + exp ( 0.22 ) ≈ 0.107 \alpha_4^m = \frac{\exp(0.22)}{\exp(0.86) + \exp(0.44) + \exp(0.66) + \exp(0.22)} \approx 0.107 α4m=exp(0.86)+exp(0.44)+exp(0.66)+exp(0.22)exp(0.22)≈0.107
-
-
计算标签表示 u j m u_j^m ujm:标签1的表示是每个位置嵌入的加权和:
u 1 m = ∑ i = 1 n m α i j m h i m u_1^m = \sum_{i=1}^{n_m} \alpha_{ij}^m h_i^m u1m=∑i=1nmαijmhim
代入具体数值:
u 1 m = 0.328 × [ 0.5 0.7 ] + 0.181 × [ 0.2 0.4 ] + 0.261 × [ 0.3 0.6 ] + 0.107 × [ 0.1 0.2 ] u_1^m = 0.328 \times \begin{bmatrix} 0.5 \\ 0.7 \end{bmatrix} + 0.181 \times \begin{bmatrix} 0.2 \\ 0.4 \end{bmatrix} + 0.261 \times \begin{bmatrix} 0.3 \\ 0.6 \end{bmatrix} + 0.107 \times \begin{bmatrix} 0.1 \\ 0.2 \end{bmatrix} u1m=0.328×[0.50.7]+0.181×[0.20.4]+0.261×[0.30.6]+0.107×[0.10.2]
计算得到:
u 1 m = [ 0.5 0.7 ] × 0.328 + [ 0.2 0.4 ] × 0.181 + [ 0.3 0.6 ] × 0.261 + [ 0.1 0.2 ] × 0.107 u_1^m = \begin{bmatrix} 0.5 \\ 0.7 \end{bmatrix} \times 0.328 + \begin{bmatrix} 0.2 \\ 0.4 \end{bmatrix} \times 0.181 + \begin{bmatrix} 0.3 \\ 0.6 \end{bmatrix} \times 0.261 + \begin{bmatrix} 0.1 \\ 0.2 \end{bmatrix} \times 0.107 u1m=[0.50.7]×0.328+[0.20.4]×0.181+[0.30.6]×0.261+[0.10.2]×0.107
u 1 m = [ 0.164 0.2296 ] + [ 0.0362 0.0724 ] + [ 0.0783 0.1566 ] + [ 0.0107 0.0214 ] u_1^m = \begin{bmatrix} 0.164 \\ 0.2296 \end{bmatrix} + \begin{bmatrix} 0.0362 \\ 0.0724 \end{bmatrix} + \begin{bmatrix} 0.0783 \\ 0.1566 \end{bmatrix} + \begin{bmatrix} 0.0107 \\ 0.0214 \end{bmatrix} u1m=[0.1640.2296]+[0.03620.0724]+[0.07830.1566]+[0.01070.0214]
u 1 m = [ 0.2892 0.4800 ] u_1^m = \begin{bmatrix} 0.2892 \\ 0.4800 \end{bmatrix} u1m=[0.28920.4800]
这就是标签1(愤怒) 的标签特定表示。
总结
通过这个简单的计算例子,我们演示了如何通过Transformer编码器生成嵌入,并使用标签特定的注意力机制计算每个标签的表示。通过这种方法,模型能够根据每个标签的特性对不同位置的嵌入进行加权,从而生成最具判别性的标签表示。这种方法有效地捕捉了标签之间的差异,并能够根据标签的需要聚焦在最相关的特征上。
六、为了实现跨模态特征融合,我们使用一个包含三个网络 f v a 2 t ( ⋅ ) f^{va2t}(\cdot) fva2t(⋅)、 f t a 2 v ( ⋅ ) f^{ta2v}(\cdot) fta2v(⋅) 和 f t v 2 a ( ⋅ ) f^{tv2a}(\cdot) ftv2a(⋅) 的两级重构过程(详细分析在附录A中)。为什么这3个网络可以实现重构?
要理解为什么这三个网络 f v a 2 t ( ⋅ ) f^{va2t}(\cdot) fva2t(⋅)、 f t a 2 v ( ⋅ ) f^{ta2v}(\cdot) fta2v(⋅) 和 f t v 2 a ( ⋅ ) f^{tv2a}(\cdot) ftv2a(⋅) 可以实现跨模态特征融合,我们需要从跨模态学习和重构的角度来分析它们的作用和如何通过这些网络进行信息的互相映射与重构。
- 跨模态特征融合的挑战
在跨模态学习中,通常有多种模态数据(例如视觉、文本、音频等),每种模态的特征表示可能具有不同的维度、分布和表达方式。为了有效地融合这些模态信息,必须考虑如何将它们映射到一个共享的潜在空间,或者如何在不同模态之间进行信息的转换和互相补充。
一个直接的思路是通过重构(reconstruction)过程,将一种模态的信息通过特定的网络映射回其他模态,从而实现模态间的相互转换和信息融合。
- 三个网络的作用
这三个网络, f v a 2 t ( ⋅ ) f^{va2t}(\cdot) fva2t(⋅)、 f t a 2 v ( ⋅ ) f^{ta2v}(\cdot) fta2v(⋅) 和 f t v 2 a ( ⋅ ) f^{tv2a}(\cdot) ftv2a(⋅),每个网络负责从一种模态映射到另一种模态,即实现模态间的重构。具体来说:
-
f v a 2 t ( ⋅ ) f^{va2t}(\cdot) fva2t(⋅):这个网络负责将视觉模态(例如图像或视频)到文本模态的转换。通过该网络,视觉信息可以被映射到文本特征空间,类似于将图像的特征转换为可以理解的文本信息,或者将图像描述转化为文本。
-
f t a 2 v ( ⋅ ) f^{ta2v}(\cdot) fta2v(⋅):这个网络负责将文本模态到视觉模态的转换。通过该网络,文本信息(例如,描述一幅图片的文字)可以被映射回到视觉模态,这可以用来生成图像的特征表示或与图像相关的内容。
-
f t v 2 a ( ⋅ ) f^{tv2a}(\cdot) ftv2a(⋅):这个网络负责将文本模态到音频模态的转换。它能够把文本数据转化为音频特征,或从文本中生成与之相关的语音特征(例如,通过TTS模型生成语音)。
- 为什么可以实现重构
这三个网络之所以能够实现跨模态特征的重构,基于以下几个关键原因:
a. 映射与相互转换
每个网络都承担了一个“映射”的任务:即将一个模态的特征映射到另一个模态的特征空间。通过训练这些网络,我们能够学习到如何将一个模态的信息表示转化为另一模态的等效表示。这个过程类似于数据从一个模态到另一个模态的转换过程。例如,通过
f
v
a
2
t
(
⋅
)
f^{va2t}(\cdot)
fva2t(⋅),我们可以将图像中的视觉特征转换为文本描述,从而实现视觉信息到文本信息的转换。
b. 共享潜在空间的学习
在多模态学习中,通常会学习一个共享的潜在空间。在这个潜在空间中,不同模态的特征可以被统一表示,从而使得模型能够跨模态地理解和融合信息。通过这三个网络,我们实际上是将不同模态的信息映射到同一个潜在空间中,使得模型可以在这个共享空间中对不同模态进行融合。
- 重构的本质就是通过学习这种映射关系来使得输入数据在转换之后仍然保持相对一致的表示,这样就可以通过重构损失来训练模型,优化这些转换网络的效果。
c. 自监督学习的应用
这三个网络在跨模态学习中也常常与自监督学习相结合。例如,模型可能会根据一种模态的输入(如图像)生成其他模态的输出(如文本描述),并通过计算原始输入与重构输出之间的损失来训练模型。这种方式利用了模态之间的相关性和一致性,确保网络能够学会如何从一个模态的特征恢复或重构其他模态的特征。
d. 互补信息的融合
每个模态提供的信息都是互补的。通过这些重构网络的相互作用,模型可以在不同模态之间进行信息传递和融合。例如,图像和文本通常携带不同类型的信息,但它们之间的关系紧密(例如,“描述图像”或“根据描述生成图像”)。通过这三个网络,模型能够在视觉和语言之间建立起这种关联,甚至在不同模态之间生成有用的补充信息(例如从视觉生成文本,或从文本生成图像)。
- 简单的计算示例
假设我们有一个包含图像和文本数据的任务,目标是通过图像生成文本描述。我们可以通过以下步骤实现这一过程:
-
图像编码:首先,使用一个视觉编码器(例如CNN)将图像 X v X_v Xv转换为视觉特征向量 v ∈ R d v v \in \mathbb{R}^{d_v} v∈Rdv。
-
图像到文本的映射:然后,使用网络 f v a 2 t ( ⋅ ) f^{va2t}(\cdot) fva2t(⋅)将视觉特征 v v v 转换为文本描述特征向量 t ∈ R d t t \in \mathbb{R}^{d_t} t∈Rdt:
t = f v a 2 t ( v ) t = f^{va2t}(v) t=fva2t(v)
该过程可以通过自注意力机制或其他神经网络方法实现,使得图像中的视觉信息能够被映射到文本描述。 -
重构过程:通过生成的文本特征 ( t ),可以进一步用语言模型生成与图像相关的文本描述,从而实现图像到文本的转换。
-
损失计算与优化:通过计算生成的文本描述与真实文本标签之间的差异(例如使用交叉熵损失),并反向传播优化整个模型。
总结
这三个网络通过相互转换和映射不同模态的数据,能够实现跨模态特征的融合和重构。每个网络在其对应的模态之间进行映射,帮助模型学习如何通过不同模态的数据转换来实现信息的共享和融合。通过这些重构过程,模型能够学习到跨模态之间的深层关系,并能够进行有效的多模态融合。
七、简练一点
这三个网络 f v a 2 t ( ⋅ ) f^{va2t}(\cdot) fva2t(⋅)、 f t a 2 v ( ⋅ ) f^{ta2v}(\cdot) fta2v(⋅) 和 f t v 2 a ( ⋅ ) f^{tv2a}(\cdot) ftv2a(⋅) 可以实现重构,主要是通过跨模态映射和特征转换来实现信息的融合和重建。每个网络负责将一种模态的特征映射到另一模态的特征空间,从而实现模态间的互相转换。
- f v a 2 t ( ⋅ ) f^{va2t}(\cdot) fva2t(⋅):将视觉模态的特征(如图像)映射到文本模态。
- f t a 2 v ( ⋅ ) f^{ta2v}(\cdot) fta2v(⋅):将文本模态的特征映射到视觉模态。
- f t v 2 a ( ⋅ ) f^{tv2a}(\cdot) ftv2a(⋅):将文本模态的特征映射到音频模态。
这种重构过程通过自监督学习或生成模型进行训练,网络通过将一个模态的特征重构成其他模态的特征,确保模态间信息的共享与融合,从而实现跨模态特征的有效整合。
八、最后一个Step举个简单的例子
好的,下面我通过一个简单的例子,来帮助理解这个 跨模态特征融合 的过程,特别是涉及到 样本洗牌 和 模态洗牌(Sample-wise Shuffle 和 Modality-wise Shuffle)。
假设情景
我们有三种模态的数据:
- 文本模态:例如,“愤怒”和“快乐”的情感描述。
- 视觉模态:例如,图像中展现的情绪(“愤怒”面部表情和“快乐”面部表情)。
- 音频模态:例如,语音中的情绪表达(“愤怒”的语气和“快乐”的语调)。
我们希望通过跨模态特征融合来增强情感识别的表现。
步骤 1:堆叠模态特征
假设我们有 3个样本(即 ( B = 3 ))和 3个模态(文本、视觉、音频),每个模态的特征是一个长度为2的向量。将这些模态的特征堆叠在一起,得到一个矩阵 ( V ):
V
=
[
文本特征
视觉特征
音频特征
[
0.5
,
0.7
]
[
0.8
,
0.6
]
[
0.2
,
0.4
]
[
0.4
,
0.6
]
[
0.9
,
0.7
]
[
0.3
,
0.5
]
[
0.3
,
0.5
]
[
0.7
,
0.9
]
[
0.1
,
0.3
]
]
V = \begin{bmatrix} \text{文本特征} & \text{视觉特征} & \text{音频特征} \\ [0.5, 0.7] & [0.8, 0.6] & [0.2, 0.4] \\ [0.4, 0.6] & [0.9, 0.7] & [0.3, 0.5] \\ [0.3, 0.5] & [0.7, 0.9] & [0.1, 0.3] \\ \end{bmatrix}
V=
文本特征[0.5,0.7][0.4,0.6][0.3,0.5]视觉特征[0.8,0.6][0.9,0.7][0.7,0.9]音频特征[0.2,0.4][0.3,0.5][0.1,0.3]
这里,每个模态有2维的特征表示,合起来就是
3
×
3
×
2
3 \times 3 \times 2
3×3×2 的矩阵。
步骤 2:样本洗牌(SWS)
对每个模态,我们执行 样本洗牌(Sample-wise Shuffle)。具体来说,洗牌的目的是随机打乱样本的顺序,但保持模态之间的顺序。假设我们洗牌后得到新的样本顺序。
- 原始矩阵 ( V ) 中第一个样本是:[0.5, 0.7](文本),[0.8, 0.6](视觉),[0.2, 0.4](音频)。
- 假设新的顺序是:[0.4, 0.6](文本),[0.7, 0.9](视觉),[0.1, 0.3](音频)。
结果是,样本洗牌后的矩阵 ( \tilde{V} ) 变成了:
V
~
=
[
[
0.4
,
0.6
]
[
0.9
,
0.7
]
[
0.3
,
0.5
]
[
0.5
,
0.7
]
[
0.8
,
0.6
]
[
0.2
,
0.4
]
[
0.3
,
0.5
]
[
0.7
,
0.9
]
[
0.1
,
0.3
]
]
\tilde{V} = \begin{bmatrix} [0.4, 0.6] & [0.9, 0.7] & [0.3, 0.5] \\ [0.5, 0.7] & [0.8, 0.6] & [0.2, 0.4] \\ [0.3, 0.5] & [0.7, 0.9] & [0.1, 0.3] \\ \end{bmatrix}
V~=
[0.4,0.6][0.5,0.7][0.3,0.5][0.9,0.7][0.8,0.6][0.7,0.9][0.3,0.5][0.2,0.4][0.1,0.3]
步骤 3:模态洗牌(MWS)
然后,我们对每个样本执行 模态洗牌(Modality-wise Shuffle)。模态洗牌意味着我们在每个样本中,随机打乱模态的顺序。假设模态的顺序也被打乱,新的顺序可能是:视觉,音频,文本。
例如,在样本1中,原始的模态顺序是文本-视觉-音频(即 [0.4, 0.6], [0.9, 0.7], [0.3, 0.5])。经过模态洗牌后,这些模态的顺序变成了:视觉、音频、文本(即 [0.9, 0.7], [0.3, 0.5], [0.4, 0.6])。
结果是,模态洗牌后的矩阵
V
^
\hat{V}
V^ 变成了:
V
^
=
[
[
0.9
,
0.7
]
[
0.3
,
0.5
]
[
0.4
,
0.6
]
[
0.8
,
0.6
]
[
0.2
,
0.4
]
[
0.5
,
0.7
]
[
0.7
,
0.9
]
[
0.1
,
0.3
]
[
0.3
,
0.5
]
]
\hat{V} = \begin{bmatrix} [0.9, 0.7] & [0.3, 0.5] & [0.4, 0.6] \\ [0.8, 0.6] & [0.2, 0.4] & [0.5, 0.7] \\ [0.7, 0.9] & [0.1, 0.3] & [0.3, 0.5] \\ \end{bmatrix}
V^=
[0.9,0.7][0.8,0.6][0.7,0.9][0.3,0.5][0.2,0.4][0.1,0.3][0.4,0.6][0.5,0.7][0.3,0.5]
步骤 4:连接特征
接下来,我们将洗牌后的特征矩阵
V
V
V 和
V
^
\hat{V}
V^ 按标签维度连接起来。具体地,原始矩阵
V
V
V 中每个模态和每个样本的特征被连接到
q
m
i
q_m^i
qmi,而洗牌后的矩阵
V
^
\hat{V}
V^ 中的特征被连接到
q
^
m
i
\hat{q}_m^i
q^mi。
通过这种连接,模型就能够将每个样本和每个模态的信息结合在一起,从而在特征层面进行跨模态的融合。
步骤 5:微调分类器
通过这两个过程生成的特征(
Q
Q
Q 和
Q
^
\hat{Q}
Q^),模型可以进一步微调分类器(如使用交叉熵损失函数)来进行情感预测或其他多模态任务。具体来说,通过计算损失函数来优化模型,模型能够学习如何在多模态数据中找到最相关的信息。
总结
这个过程通过两个洗牌步骤(样本洗牌和模态洗牌)来增强多模态特征的融合。样本洗牌通过随机打乱样本的顺序,模态洗牌通过随机打乱模态的顺序,从而丰富了标签的共现关系,并提高了特征的鲁棒性。最终,这些洗牌后的特征被用于训练模型,提高了跨模态信息融合的效果。
九、洗牌有何作用
在机器学习中,洗牌(Shuffle) 是一种常见的数据处理操作,它在跨模态学习和多模态学习中尤为重要,特别是在处理多模态数据时,洗牌有以下几个主要作用:
-
增强模型的鲁棒性
通过对样本和模态进行随机洗牌,可以让模型在训练过程中看到不同的模态组合和样本组合,这样可以防止模型在训练时对某种特定的模态或样本顺序产生过拟合。通过洗牌,模型可以在训练时更好地适应不同的输入顺序,提高对新数据的泛化能力。 -
打破数据之间的依赖关系
在许多数据集中,数据的顺序可能包含某些偏差(例如时间顺序或先后关系)。通过洗牌,模型可以避免学习到这种不必要的顺序依赖性,从而强迫模型仅仅依赖于数据本身的特征,而不是数据的排列顺序。特别是对于跨模态的学习,洗牌操作可以打破模态之间的潜在依赖,使得模型更加全面地学习不同模态之间的特征。 -
丰富标签的共现关系
在多标签学习中,每个样本可以有多个标签。洗牌操作尤其在标签洗牌中起着关键作用,通过随机改变标签与样本的组合顺序,可以丰富标签之间的共现关系。这有助于模型学习标签之间的相互关系(例如,某些标签经常共同出现,而有些标签则可能彼此排斥)。通过洗牌,标签之间的关系不再是固定的,而是动态变化的,从而提高了模型的表现。 -
提高跨模态融合的多样性
在跨模态学习中,洗牌操作可以帮助模型混合不同模态的信息,让模型在训练时接触到多种模态的随机组合。这样,不同模态(如图像、文本、音频等)之间的互补信息可以得到有效融合。洗牌后,每个样本的特征来自不同模态,模型可以学习到这些模态之间的非线性关联,而不是单独依赖某一个模态。 -
防止过拟合
洗牌是避免过拟合的有效方法之一。如果在训练过程中样本顺序保持固定,模型可能会对数据的顺序产生过度依赖,从而导致过拟合。通过洗牌,样本顺序被打乱,模型无法依赖样本的顺序进行决策,从而减少了过拟合的风险。 -
多样化样本和模态的组合
在某些模型中,洗牌操作不仅仅是对样本进行洗牌,还包括对模态的洗牌。例如,在多模态学习中,模态洗牌可以让模型在每个样本中随机选择不同的模态特征进行训练。这样,模型可以在不同模态组合下学习特征,从而提高对模态间复杂关系的理解。 -
增加训练数据的多样性
通过洗牌,训练集的样本和特征组合变得更加多样化,这相当于增加了训练数据的多样性。这对于增强模型的鲁棒性、减少对特定样本或模态组合的依赖非常重要,尤其是在数据量有限的情况下,洗牌有助于模拟更丰富的训练环境。
总结
洗牌操作通过随机化样本和模态的顺序,可以:
- 增强模型的鲁棒性。
- 打破顺序依赖,避免过拟合。
- 丰富标签的共现关系,帮助模型学习标签间的关系。
- 提高跨模态融合的多样性。
- 增加数据的多样性,有助于提高模型的泛化能力。
洗牌是一种简单但有效的技术,尤其在跨模态学习和多标签任务中,通过增加样本和模态的随机性,帮助模型更好地捕捉数据的多样性和复杂性。




![[Docker#8] 容器配置 | Mysql | Redis | C++ | 资源控制 | 命令对比](https://img-blog.csdnimg.cn/img_convert/e355315bf2279c1428ceebd01a1edf6f.png)





![[产品管理-76]:延续是创新与颠覆式创新的比较](https://i-blog.csdnimg.cn/direct/5bc61d739e2b44a2a070b19b46bc71e1.png)