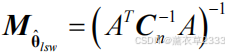文章目录
- 一、项目介绍
- 二、项目实战
- 2.1、搭建环境
- 2.1.1、下载源码
- 2.1.2、下载预训练模型
- 2.1.3、下载训练集
- 2.2、环境配置
- 2.3、模型预测
U-Net是一种用于生物医学图像分割的卷积神经网络架构,最初由Olaf Ronneberger等人于2015年提出。
- 论文: U-Net: Convolutional Networks for Biomedical Image Segmentation
- 作者: Olaf Ronneberger, Philipp Fischer, Thomas Brox
- 会议: MICCAI 2015
- 数据集:使用了ISBI挑战赛中的神经元结构分割和细胞追踪数据集。主要用于评估生物医学图像分割算法的性能。
- 开源代码:原论文并未提供官方的开源代码,但社区中有多个实现版本可供参考。
- nnUNet:生物医学领域
- Segment Anything:强泛化模型(建立了迄今为止最大的分割数据集,有超过1亿个mask。)
一、项目介绍
社区版本:milesial/Pytorch-UNet 是一个基于 PyTorch 的 U-Net 实现项目,专注于语义分割任务。
项目名称:U-Net: Semantic segmentation with PyTorch
主要目的:针对 Kaggle 的Carvana 图像蒙版挑战赛(来自高清图像)在 PyTorch 中定制实现的U-Net 。
Carvana 图像蒙版挑战赛:自动识别图像中的汽车边界
- 概述:由美国二手车零售平台 Carvana 于 2017 年在 Kaggle 上举办的竞赛,最初为提升车辆展示效果而开发,旨在通过前景分割技术从高分辨率图像中提取汽车主体,去除背景。这一挑战推动了高分辨率图像分割技术在自动驾驶和车辆识别等领域的发展。
- 数据集:包含
5088 张汽车照片及其对应的掩码(mask),用于训练和评估图像分割模型,特别是汽车前景与背景的分离。- 代码(多人提交了Notebook格式的开源代码,部分提供了预训练模型)
- 模型(未开源)
- 排行榜(根据Dice得分,
最高Dice=0.99733)

二、项目实战
2.1、搭建环境
2.1.1、下载源码
官方下载地址:milesial/Pytorch-UNet
2.1.2、下载预训练模型
官方提供了两个预训练模型:Pretrained model
unet_carvana_scale0.5_epoch2.pth- 模型说明: 这是在 Carvana 数据集上训练的 U-Net 模型,缩放因子为 0.5。这意味着输入图像的尺寸在训练时被缩小了一半,有助于降低计算复杂性和内存使用。
- 应用场景: 适合于需要快速推理或资源受限的环境,例如移动设备或边缘计算设备。
- 训练细节: 训练通常包括数据增强、交叉熵损失计算和优化,旨在提高模型的分割精度。
unet_carvana_scale1.0_epoch2.pth- 模型说明: 这是相同模型在 Carvana 数据集上的训练,但缩放因子为 1.0,表示输入图像的尺寸与原始图像一致。
- 应用场景: 适合于对图像分割精度要求较高的任务,因为使用原始尺寸可以保留更多的细节信息。
- 训练细节: 该模型可能会有更多的计算需求和内存消耗,但在准确性上通常优于缩放因子为 0.5 的模型。
2.1.3、下载训练集
如果需要自训练模型,可以下载官方数据集:carvana-image-masking-challenge:dataset
2.2、环境配置
Note : Use Python 3.6 or newer
conda install python=3.6
pip install -r requirements.txt
2.3、模型预测
基于预训练模型的Unet【Pytorch版】
该项目具有一定的影响力,由于项目需要,尝试调用其预训练模型。
- 问题:在项目复现过程中,发现
predict.py无法运行且有部分BUG。- 解决:在不改动大框架的前提下,优化了部分内容,最终可以正常执行。
优化内容如下:
(1)get_args():指定路径(预训练模型、输入图像、输出图像)
(2)get_output_filenames()
(3)img = Image.open(filename)替换为img = Image.open(filename).convert('RGB')
备注:由于项目太过简单,优化内容少,建议自己搭建(没有备份优化后项目)。
只需要优化以下两个内容,即可完成项目复现:
- (1)在原项目的基础上,添加蓝色标记内容,用于指定路径。
- (2)使用下述代码替换原文中的 predict.py 文件。

- 测试结果:使用官方提供的预训练模型,测试效果极差(没有过度探讨内部细节,但核查代码后确定定义的 UNet 模型没有问题)
- 原因分析:提供的预训练模型中有
epoch2字样,若为真,则模型确实不可能收敛(感兴趣可以尝试自训练,并增加epoch训练周期)

import argparse
import logging
import os
import numpy as np
import torch
import torch.nn.functional as F
from PIL import Image
from torchvision import transforms
from utils.data_loading import BasicDataset
from unet import UNet
from utils.utils import plot_img_and_mask
def predict_img(net,
full_img,
device,
scale_factor=1,
out_threshold=0.5):
net.eval()
img = torch.from_numpy(BasicDataset.preprocess(None, full_img, scale_factor, is_mask=False))
img = img.unsqueeze(0)
img = img.to(device=device, dtype=torch.float32)
with torch.no_grad():
output = net(img).cpu()
output = F.interpolate(output, (full_img.size[1], full_img.size[0]), mode='bilinear')
if net.n_classes > 1:
mask = output.argmax(dim=1)
else:
mask = torch.sigmoid(output) > out_threshold
return mask[0].long().squeeze().numpy()
def get_args():
parser = argparse.ArgumentParser(description='Predict masks from input images')
parser.add_argument('--model', '-m', type=str, default='./data/checkpoints/unet_carvana_scale1.0_epoch2.pth', help='Specify the file in which the model is stored')
parser.add_argument('--input', '-i', type=str, default='./data/predict_data/input/t1.png', help='Filenames of input images')
parser.add_argument('--output', '-o', type=str, default='./data/predict_data/output/t1.png', help='Filenames of output images')
parser.add_argument('--viz', '-v', action='store_true', help='Visualize the images as they are processed')
parser.add_argument('--no-save', '-n', action='store_true', help='Do not save the output masks')
parser.add_argument('--mask-threshold', '-t', type=float, default=0.5, help='Minimum probability value to consider a mask pixel white')
parser.add_argument('--scale', '-s', type=float, default=0.5, help='Scale factor for the input images')
parser.add_argument('--bilinear', action='store_true', default=False, help='Use bilinear upsampling')
parser.add_argument('--classes', '-c', type=int, default=2, help='Number of classes')
return parser.parse_args()
def get_output_filenames(args):
def _generate_name(fn):
return f'{os.path.splitext(fn)[0]}_OUT.png'
# return args.output or list(map(_generate_name, args.input))
return [args.output] if args.output else list(map(_generate_name, args.input))
def mask_to_image(mask: np.ndarray, mask_values):
if isinstance(mask_values[0], list):
out = np.zeros((mask.shape[-2], mask.shape[-1], len(mask_values[0])), dtype=np.uint8)
elif mask_values == [0, 1]:
out = np.zeros((mask.shape[-2], mask.shape[-1]), dtype=bool)
else:
out = np.zeros((mask.shape[-2], mask.shape[-1]), dtype=np.uint8)
if mask.ndim == 3:
mask = np.argmax(mask, axis=0)
for i, v in enumerate(mask_values):
out[mask == i] = v
return Image.fromarray(out)
if __name__ == '__main__':
args = get_args()
logging.basicConfig(level=logging.INFO, format='%(levelname)s: %(message)s')
in_files = [args.input] if isinstance(args.input, str) else args.input
out_files = get_output_filenames(args)
net = UNet(n_channels=3, n_classes=args.classes, bilinear=args.bilinear)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
logging.info(f'Loading model {args.model}')
logging.info(f'Using device {device}')
net.to(device=device)
state_dict = torch.load(args.model, map_location=device)
mask_values = state_dict.pop('mask_values', [0, 1])
net.load_state_dict(state_dict)
logging.info('Model loaded!')
for i, filename in enumerate(in_files):
logging.info(f'Predicting image {filename} ...')
# img = Image.open(filename)
img = Image.open(filename).convert('RGB')
mask = predict_img(net=net,
full_img=img,
scale_factor=args.scale,
out_threshold=args.mask_threshold,
device=device)
if not args.no_save:
out_filename = out_files[i]
result = mask_to_image(mask, mask_values)
result.save(out_filename)
logging.info(f'Mask saved to {out_filename}')
if args.viz:
logging.info(f'Visualizing results for image {filename}, close to continue...')
plot_img_and_mask(img, mask)