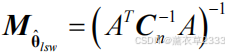词嵌入方法(Word Embedding)
Word Embedding是NLP中的一种技术,通过将单词映射到一个空间向量来表示每个单词
✨️常见的词嵌入方法:
-
🌟Word2Vec:由谷歌提出的方法,分为CBOW(continuous Bag of Words)和Skip-gram两种模型。
-
🌟Glove:斯坦福大学提出的基于统计的词嵌入方法。
-
🌟FastText:由Facebook提出的方法,不仅考虑了单词,还考虑了字符。
-
🌟ELMo(Embeddings from Language Models):基于双向LSTM。
-
🌟BERT:谷歌提出的基于transformers的词嵌入方法。
Word2Vec
-
CBOW:通过预测上下文(周围的单词)来训练模型。
-
Skip-gram:通过给定一个词,来预测这个单词的上下文。
-
优点:简单高效,能够捕捉语义关系和特征。
-
缺点:无法处理多义词,每个单词只有一个向量表示。

# 训练Word2Vec模型
model = Word2Vec(sentences=data, vector_size=100, window=5, min_count=1, workers=4, sg=1)
# 保存模型
model.save("word2vec.model")-
vector_size=100:指定词向量的维度为 100。这意味着每个词将被表示为一个 100 维的向量。 -
window=5:指定上下文窗口的大小为 5。这意味着在训练过程中,每个词会考虑其前后各 5 个词作为上下文。 -
min_count=1:指定词的最小出现次数。只有出现次数大于或等于min_count的词才会被包含在模型中。这里设置为 1,表示所有词都会被包含。 -
workers=4:指定用于训练的并行工作线程数。这里设置为 4,表示使用 4 个线程进行训练。 -
sg=1:指定训练算法。sg=1表示使用 Skip-gram 算法,sg=0表示使用 CBOW(Continuous Bag of Words)算法。
♨️执行完上面的代码后,本地生成了 3 个文件:
-
word2vec.model:主模型文件,包含了模型的参数、词汇表等信息。不仅存储了模型的架构信息,还包括了词汇频率、模型训练状态等。
-
word2vec.model.wv.vectors.npy:这个文件存储了模型中所有词汇的词向量。
-
word2vec.model.syn1neg.npy:这个文件存储的是训练过程中使用的负采样权重。
Glove
-
基于全局统计的模型,通过矩阵分解的方法训练词向量,在Word2Vec的基础上进一步优化,以更好地捕捉词语之间的语义关系
-
优点:利用全局实现矩阵,更好地捕捉全局统计信息
-
缺点:离线训练,无法动态更新词向量。
✨️FastText
-
扩展了Word2Vec的思路,考虑了词内的字符n-gram(“apple” 和“apples”)。
-
优点:能处理未登录词问题(训练时未出现,测试时出现了的单词),对拼写错误和变形更加友好。
-
缺点:训练时间和存储压力大。
-
未登录词的嵌入向量是通过对其所有子词 n-gram 的嵌入向量进行平均或求和得到的
import fasttext
model1 = fasttext.train_unsupervised('data/fil9')
model = fasttext.load_model("data/fil9.bin")
# 获取对应词向量
model.get_word_vector("the")✨️ELMo
-
ELMo在传统静态word embedding方法(Word2Vec, GloVe)的基础上提升了很多, 但是依然存在缺陷, 有很大的改进余地
-
缺点在于特征提取器的选择上, ELMo使用了双向双层LSTM, 而不是现在横扫千军的Transformer, 在特征提取能力上是要弱一些
-
ELMo选用双向拼接的方式进行特征融合, 这种方法不如BERT一体化的双向提取特征好

🔎ELMo分三个主要模块:
-
最底层黄色标记的Embedding模块.
-
中间层蓝色标记的两部分双层LSTM模块.
-
最上层绿色标记的词向量表征模块.
ELMo最底层的词嵌入采用CNN对字符级进行编码, 本质就是获得一个静态的词嵌入向量作为网络的底层输入
ELMo模型是个根据当前上下文对word embedding动态调整的语言模型
🫧BERT
-
基于Transformer架构,通过Mask任务和双向编码器实现词嵌入。
-
性能先进,捕捉了丰富的上下文信息。
通过预训练, 加上Fine-tunning, 在11项NLP任务上取得最优结果,BERT的根基源于Transformer, 相比传统RNN更加高效, 可以并行化处理同时能捕捉长距离的语义和结构依赖,BERT采用了Transformer架构中的Encoder模块, 不仅仅获得了真正意义上的bidirectional context, 而且为后续微调任务留出了足够的调整空间。
🫧BERT的MLM任务中为什么采用了80%, 10%, 10%的策略?
-
首先, 如果所有参与训练的token被100%的[MASK], 那么在fine-tunning的时候所有单词都是已知的, 不存在[MASK], 那么模型就只能根据其他token的信息和语序结构来预测当前词, 而无法利用到这个词本身的信息, 因为它们从未出现在训练过程中, 等于模型从未接触到它们的信息, 等于整个语义空间损失了部分信息. 采用80%的概率下应用[MASK], 既可以让模型去学着预测这些单词, 又以20%的概率保留了语义信息展示给模型.
-
保留下来的信息如果全部使用原始token, 那么模型在预训练的时候可能会偷懒, 直接照抄当前token信息. 采用10%概率下random token来随机替换当前token, 会让模型不能去死记硬背当前的token, 而去尽力学习单词周边的语义表达和远距离的信息依赖, 尝试建模完整的语言信息.
-
最后再以10%的概率保留原始的token, 意义就是保留语言本来的面貌, 让信息不至于完全被遮掩, 使得模型可以"看清"真实的语言面貌
🥇BERT预训练模型所接收的最大sequence长度是512,对于长文本(文本长度超过512的句子), 就需要特殊的方式来构造训练样本. 核心就是如何进行截断:
-
head-only方式: 只保留长文本头部信息的截断方式, 具体为保存前510个token (要留两个位置给[CLS]和[SEP]).
-
tail-only方式: 只保留长文本尾部信息的截断方式, 具体为保存最后510个token (要留两个位置给[CLS]和[SEP]).
-
head+only方式: 选择前128个token和最后382个token (文本总长度在800以内), 或者前256个token和最后254个token (文本总长度大于800)