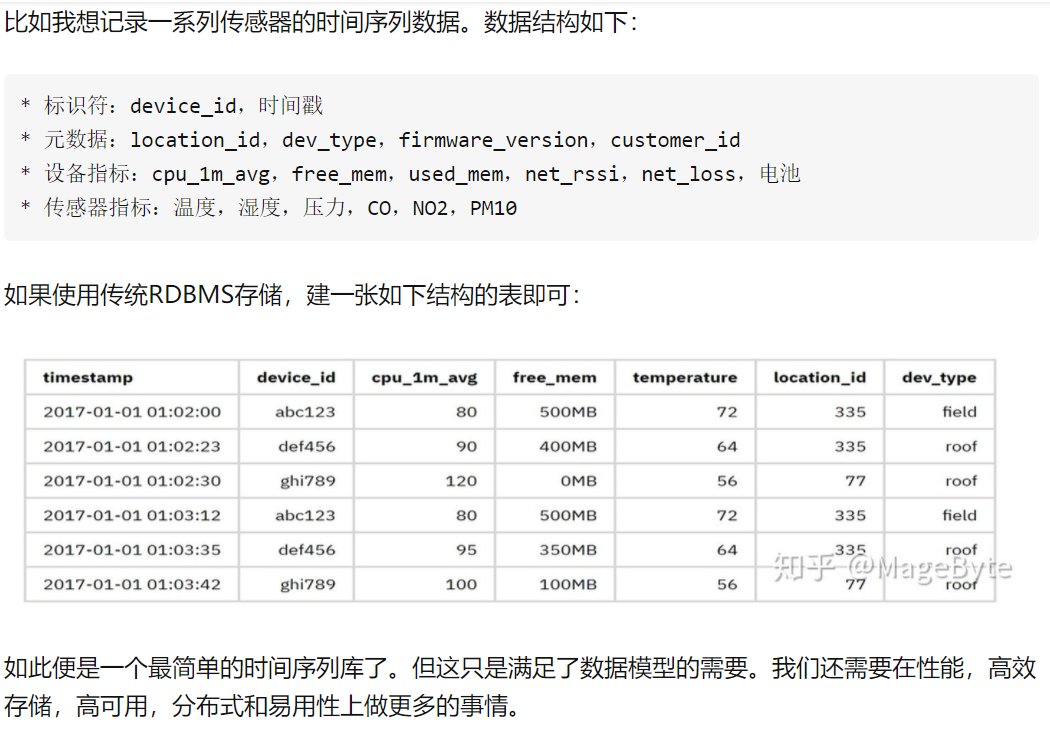
概述
近年来,生成模型在根据文本生成和编辑视频方面受到了广泛关注。然而,由于缺乏合适的数据集,生成人脸视频领域仍然是一个挑战。特别是,生成的视频帧质量较低,与输入文本的相关性较弱。在本文中,我们通过开发 CelebV-Text来解决这些问题,CelebV-Text 是一个根据文本生成人脸视频的大型数据集。这是一个包含文本和视频对的大型高质量数据集。
CelebV-Text 是一个包含 7 万个不同面部视频片段的数据集,每个片段有 20 个文本描述。这些文本描述是通过半自动文本生成技术生成的,包含静态和动态属性的详细信息。与其他数据集相比,该数据集对视频、文本以及文本和视频之间的关系进行了全面的统计分析。大量实验也证明了该数据集的实用性。
设计了包括数据收集、数据注释和半自动文本生成在内的综合数据构建管道,并提出了文本视频生成的新基准。此外,还在一个具有代表性的模型上对其进行了评估,结果显示生成的面部视频与文本之间的关联性得到了改善,时间一致性也有了显著提高。
数据集构建
提出了一种高效的方法,包括数据收集和处理、数据标注和半自动文本生成,用于在高质量人脸上建立大型文本视频数据集。
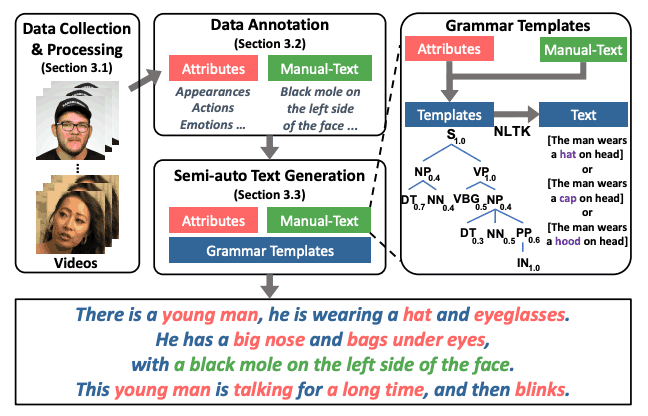
首先,在数据收集方面采用了与 CelebV-HQ 类似的方法。针对人名、片名、视频日志等生成查询,并检索包含动态时间状态变化和丰富面部属性的视频。这些数据是从网上资源下载的,其中不包括低分辨率(<512 x 512)、短视频(<5 秒)和已经包含在 CelebV-HQ 中的视频。
注释也是一个重要的过程,对 CelebV-Text 文本和视频的相关性有重大影响,因此在设计时尤为谨慎。
与图像不同,视频包含随时间发生的变化。然而,大多数人脸视频数据集都侧重于不会随时间变化的静态属性。因此,本文将人脸视频详细分为静态属性(Static)和动态属性(Dynamic)。
作为静态属性,当前的数据集只考虑了外观属性,而 CelebV-Text 不仅包括一般外观,还包括细节外观和光照条件。详细外观包括五个类别:疤痕、痣、雀斑、酒窝和一只眼睛,而光线条件包括六个类别,包括光的色温和亮度。
此外,还设计了三个动态属性用于塑造:动作、情感和光照方向。动作属性参照 CelebV-HQ 进行了扩展,而情感属性则采用了 Affectnet 的八种情感设置。光照方向有六个类别。与 CelebV-HQ 一样,动态属性也有开始和结束的时间戳。
因此,CelebV 文本注释旨在捕捉视频中的时间变化细节,并提高文本与视频的相关性。
为了优化数据集的质量和成本,CelebV-Text还根据这些属性设计引入了自动和手动注释相结合的方法。
对于可以自动标注的属性,首先对算法进行研究,然后选择准确率至少达到 85% 的算法。光照条件、外观和情感标签都是自动标注的。通过人工修改,进一步提高自动标注的准确性。对于动态和详细的外观属性,则需要人工标注。标注人员会创建自然、恰当的描述。
这种自动标注和人工标注的有效结合,可以高效地建立高质量的数据集。
此外,常见的多模态文本视频数据集使用字幕、手动文本生成和自动文本生成来生成文本。然而,每种方法都有其自身的挑战。字幕很容易获取,但相关性较低,而且噪音较大。手动生成耗时长、成本高且难以扩展。而自动生成虽然更容易扩展,但在生成文本的多样性、复杂性和自然性方面也存在挑战。
为了解决这些问题,本文提出了 "基于模板的半自动文本生成 "方法,它结合了人工和自动方法的优点。在这种方法中,注释器首先为每个属性生成 10 个不同的面部视频描述,并分析它们的语法结构。然后,它使用概率无上下文语法设计自己的模板,从而增加生成文本的多样性。
这些方法能够高效生成自然、多样的文本,并可扩展地构建高质量的文本-视频数据集。
数据集统计分析
本文将 CelebV-Text 与其他领先的面部视频数据集进行了比较,并对视频、文本以及文本与视频之间的关系进行了全面分析。
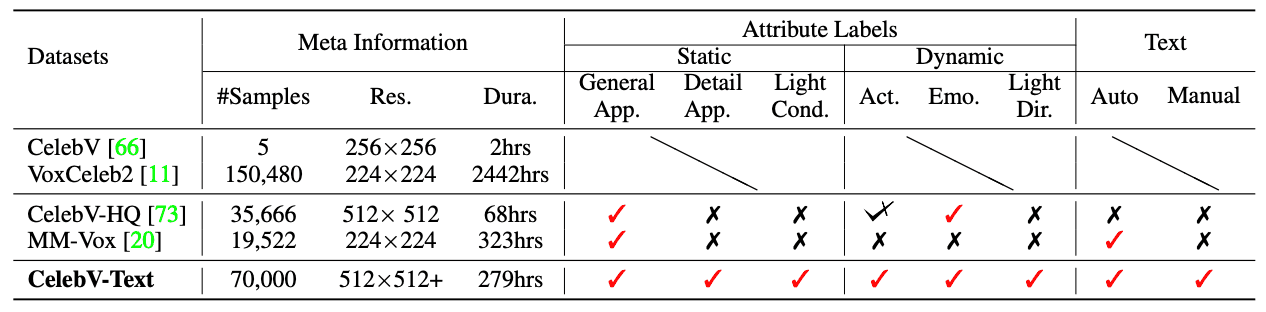
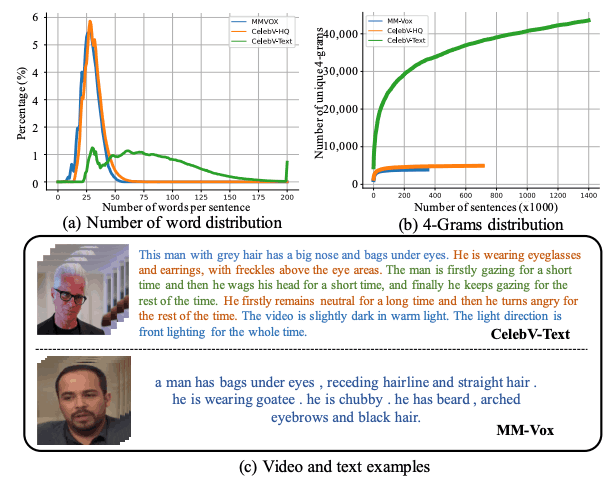
CelebV-Text 包含约 70,000 个视频片段,总播放时间约为 279 小时。每个视频片段都配有 20 个描述性文本,对所有六个属性进行了描述。与其他数据集相比,该数据集的规模更大,分辨率更高。例如,VoxCeleb2 有大量样本,但视频种类(分布)有限,因为它主要由会说话的面孔组成;CelebV-HQ 和 CelebV-Text 样本是通过各种查询收集的,因此种类(分布)更多。其中,CelebV-Text 的视频数据量几乎是其两倍,视频属性更多,相关文本描述也更多。就规模和质量而言,它优于 MM-Vox(现有的唯一人脸文本视频数据集)。
为了显示 CelebV-Text 中属性的分布情况,我们将一般外貌、动作和光照方向属性分为几组。面部特征(如双下巴、大鼻子、蛋形脸)约占 45%,基本组约占 25%,胡须类型约占 12%。发型和配饰组分别约占 10%和 8%。在动作属性方面,与头部相关的动作约占 60%,与眼睛相关的动作约占 20%。互动组(如进食)、情绪组(如大笑)和日常组(如睡觉)分别约占 9%、7% 和 4%。就光照方向而言,大部分样本包括正面光照,其余的光照方向分布均匀。
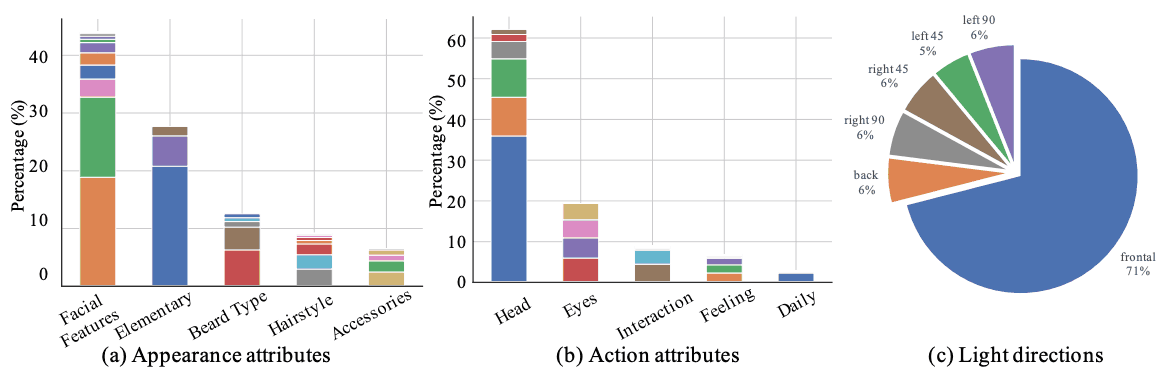
对所收集视频的质量进行了分析,并与 MM-Vox 和 CelebV-HQ 进行了比较,以显示 CelebV-Text 的优越性。BRISQUE 和 VSFA 用于评估图像和视频质量。在所有数据集中,CelebV-Text 和 CelebV-HQ 的图像质量都较高,明显高于 MM-Vox。CelebV-Text 的视频质量同样最高,这可能是由于视频分割方法减少了背景切换时的不连续性。
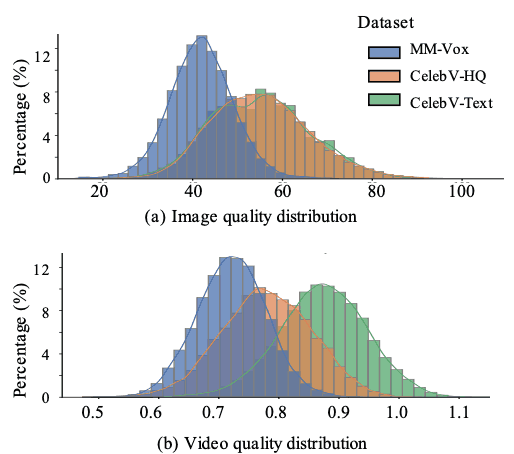
CelebV-Text 文本比 MM-Vox 和 CelebV-HQ文本更长、更详细。平均文本长度分别为 28.39、31.06 和 67.15。全面的注释意味着 CelebV-Text 视频描述包含的字数更多。
对三个数据集的独特语篇(动词、名词、形容词和副词)进行了比较,以考察语言的多样性。CelebV-Text 的属性列表和模板设计全面,因此文本范围更广,涵盖了各种时间静态和动态面部属性。
此外,还考察了 CelebV-Text 与 MM-Vox 相比的文本自然度和复杂度。可以看出,语法结构和同义词替换大大提高了 CelebV-Text 的语言自然度和复杂度。
此外,还在 MM-Vox、CelebV-HQ 和 CelebV-Text 三个数据集上进行了文本-视频检索任务,以定量测试文本和视频的相关性。Recall@K(R@K)、中位数排名 (MdR) 和平均排名 (MnR) 被用作评价指标。请注意,R@K 越高、中位数排名和平均排名越低,表明性能越好。

首先,对包含一般外观描述的文本的性能进行了评估:CelebV-HQ 和 CelebV-Text 的结果均优于 MM-Vox,这表明所设计的模板能比 MM-Vox 生成更多相关的视频文本。接下来,我们添加了动态情感变化描述,发现两个数据集的结果相似,表明静态外观属性的注释准确率更高。我们还添加了行为描述,在大多数指标上都取得了最佳性能。
验证数据集的实用性
在此,我们通过根据文本生成面部视频,并使用具有代表性的方法对该任务进行基准测试,从而检验 CelebV-Text 数据集的有效性。
为了证明 CelebV-Text 的静态和动态属性描述的有效性,我们基于最先进的开源方法 MMVID 进行了多项实验,并将其与 CogVideo 进行了比较。
为了首先验证 CelebV-Text 数据集在静态属性方面的有效性,我们根据一般外观、面部细节和光线条件描述生成了视频;使用 CelebV-Text 从头开始训练 MMVID,并生成了三个输入文本,包括每个静态属性的单独描述使用 CelebV-Text 生成视频。然后将生成的文本输入 MMVID 和 CogVideo,并对视频输出进行比较。
一般外观可视化结果如下图(a)所示,CogVideo 根据文本描述生成面部视频,但文本与视频之间的相关性较低,例如 "黑眼圈 "和 “波浪形头发”。另一方面,MMVID 生成的视频包含文本中描述的所有属性,显示出较高的相关性。

我们还根据动态属性(如情绪、动作、光线方向)的变化测试了 CelebV-Text 的有效性。从上图 (b) 可以看出,CogVideo 无法反映输入文本中描述的时间变化(如微笑 -> 旋转)。然而,在 CelebV-Text 文本中训练的 MMVID 能准确模拟动态属性的变化,这证明了数据集的有效性。
请注意,CogVideo 的模型大小约为 MMVID 的 100 倍,并且是在约为 CelebV-Text 75 倍的文本-视频数据集上训练的,但如上图所示,CogVideo 生成的视频样本质量低于仅在 CelebV-Text 上训练的 MMVID 生成的样本质量这表明本文提出的数据集非常有效。
文本到视频生成技术发展迅速,MM-Vox 是人脸视频生成的唯一基准。在本文中,我们扩展了这一基准,并使用 MM-Vox、CelebV-HQ 和 CelebV-Text 三个数据集建立了一个新基准。这样就能全面评估从文本生成人脸视频任务的性能。我们选择了 TFGAN 和 MMVID 这两种方法进行性能评估,它们基于以下指标
- FVD:时间一致性评估。
- FID: 评估每个帧的质量。
- CLIPSIM:评估文本和生成视频的相关性。
在定量评估中使用了具有静态和动态属性的变体文本,以验证基线方法。结果显示 MMVID 优于 TFGAN,如下表所示。同时还发现,当输入文本包含时间状态变化时,MMVID 生成的视频质量会降低。

下图显示了在不同数据集上训练出 MMVID 的视频样本。可以看出,这些视频帧的尺寸为 128 x 128 像素,在时间上保持一致,而且质量很高。但也可以看出,MMVID 有时无法完全再现输入文本中描述的属性。

总结
本文提出的 CelebV-Text 是一个具有静态和动态属性的大型面部文字视频数据集。该数据集包含 70,000 个视频片段,每个片段包含 20 个描述静态和动态元素的独立文本。通过大量的统计分析和实验,证明了 CelebV-Text 的优越性和有效性。
论文还指出,未来计划包括进一步扩大 CelebV-Text 的规模和多样性。预计 CelebV-Text 还将应用于基于 CelebV-Text 的新任务,如视频人脸的细粒度控制、一般预学习模型在人脸领域的适配,以及文本驱动的 3D 识别人脸视频生成。
注:
论文地址:https://arxiv.org/pdf/2303.14717
源码地址:https://github.com/celebv-text/CelebV-Text.git






![CSP/信奥赛C++刷题训练:经典例题 - 栈(2):洛谷P1981 :[NOIP2013 普及组] 表达式求值](https://i-blog.csdnimg.cn/direct/f89c03d1fa7140cd87a41e8cead94e91.png#pic_center)







![[ Linux 命令基础 7 ] Linux 命令详解-磁盘管理相关命令](https://i-blog.csdnimg.cn/direct/7d6662bba48d47388d63ee52225e8016.png)