01 算法介绍
自主泊车是智能驾驶领域中的一项关键任务。传统的泊车算法通常使用基于规则的方案来实现。因为算法设计复杂,这些方法在复杂泊车场景中的有效性较低。
相比之下,基于神经网络的方法往往比基于规则的方法更加直观和多功能。通过收集大量专家泊车轨迹数据,基于学习的仿人策略方法,可以有效解决泊车任务。
在本文中,我们采用模仿学习来执行从 RGB 图像到路径规划的端到端规划,模仿人类驾驶轨迹。我们提出的端到端方法利用目标查询编码器来融合图像和目标特征,并使用基于 Transformer 的解码器自回归预测未来的航点。
我们在真实世界场景中进行了广泛的实验,结果表明,我们提出的方法在四个不同的真实车库中平均泊车成功率达到了 87.8%。实车实验进一步验证了本文提出方法的可行性和有效性。
输入:1.去完畸变的 RGB 图 2.目标停车位
输出:路径规划

论文精读博客参考链接:https://blog.csdn.net/qq_45933056/article/details/140968352
源代码:https://github.com/qintonguav/ParkingE2E
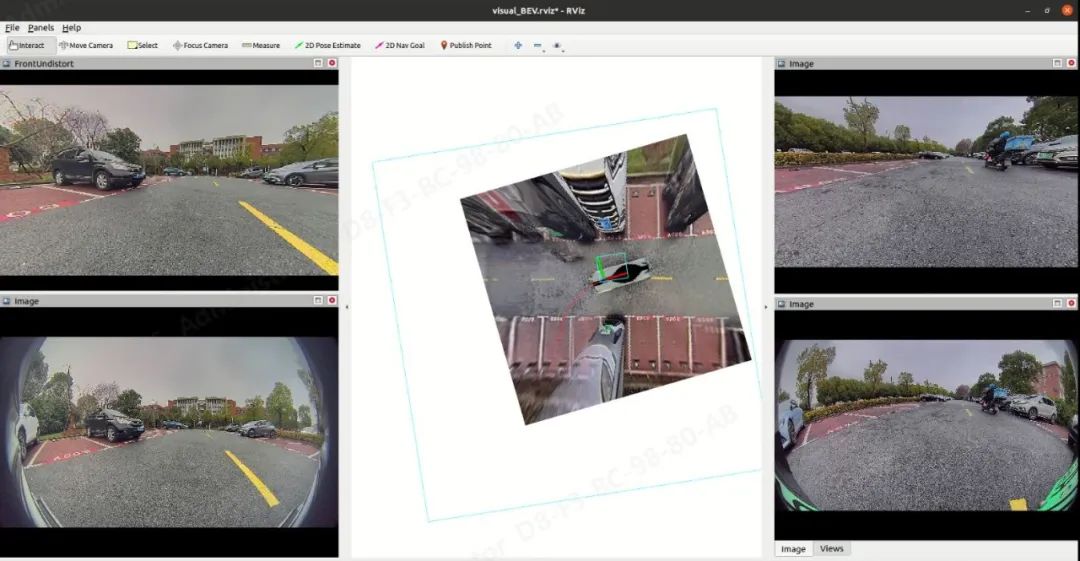
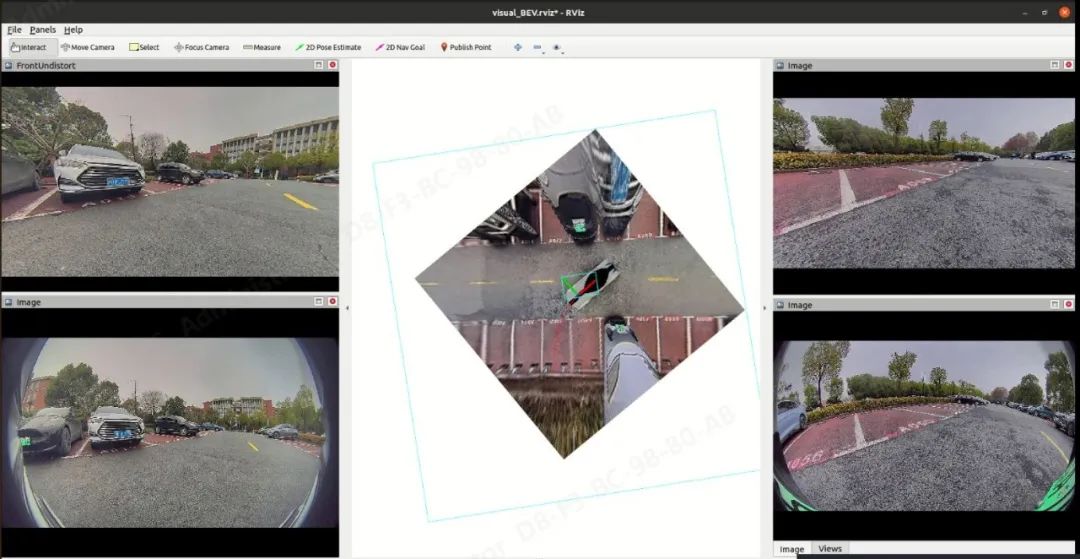
02 算法部署后的 demo 效果展示
03 实现过程
3.1 算法整体架构
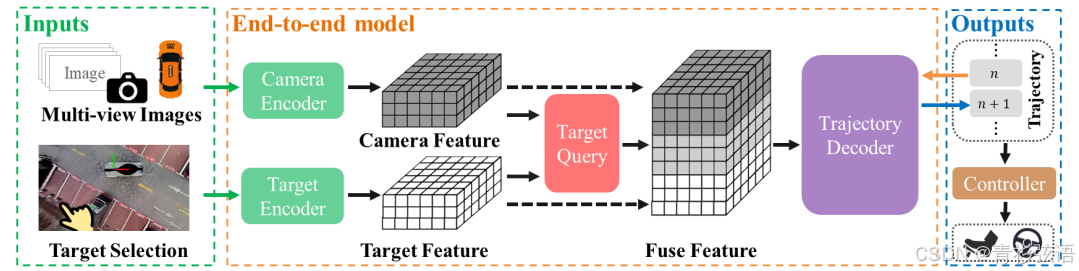
多视角 RGB 图像被处理,图像特征被转换为 BEV(鸟瞰图)表示形式。使用目标停车位生成 BEV 目标特征,通过目标查询将目标特征和图像 BEV 特征融合,然后使用自回归的 Transformer 解码器逐个获得预测的轨迹点。
3.2 训练过程
注:训练数据集是去完畸变的图像,在数据处理时需要对 4 路鱼眼相机进行标定,获取相机内外参,对鱼眼图进行去畸变,去完畸变的图像会被制作成训练集
获取去完畸变的 RGB 图像和目标停车位做为输入:
(去完畸变的 RGB 图像示例)

目标停车位坐标示例:
{
"x": 83.93134781878057,
"y": -7.080006849257972,
"z": -7.404438257656194,
"yaw": 20.95510451530132
}
- 使用 EfficientNet 从 RGB 图像中提取特征;
- 将预测的深度分布 ddep 与图像特征 Fimg 相乘,以获得具有深度信息的图像特征;
- 将图像特征投影到 BEV 体素网格(特征的大小为 200×200,对应实际空间范围 x∈[−10m, 10m], y∈[−10m, 10m],分辨率为 0.1 米)中,生成相机特征 Fcam。
BEV 视图示例:

- 使用深度 CNN 神经网络提取目标停车位特征 Ftarget
- 在 BEV 空间,将相机特征 Fcam 和目标停车位特征 Ftarget 进行融合,获取融合特征 Ffuse
- 使用 Transformer 解码器以自回归方式预测轨迹点
预测的轨迹序列示例:
[[-0.17014217376708984, -0.010008811950683594], [-0.3298116556863353, -0.011956165423615472], [-0.4854376561367579, -0.02052420170634236], [-0.6337416331734281, -0.03509474854381417], [-0.774850889165686, -0.05409092178920946], [-0.9106318371186677, -0.07662342910150008], [-1.0429499912911764, -0.10220288211346742], [-1.1730293341546085, -0.130403150090076], [-1.3014671109093938, -0.16081194272771432], [-1.4284175031869575, -0.19315076247807056], [-1.5537739117230407, -0.22739195648381574], [-1.6773593831451739, -0.2637573983721455], [-1.7991250198403412, -0.3025803813592571], [-1.9192866870681176, -0.34410827406410627], [-2.0383187092132995, -0.3883681895794497], [-2.1567872059422366, -0.43518302389208097], [-2.275088086162824, -0.4843281463722012], [-2.393198715763861, -0.5357188397161318], [-2.5105481374226417, -0.5894858888356189], [-2.6260817537118184, -0.6458681996255287], [-2.7385546018760474, -0.7049937228225489], [-2.84701611529502, -0.7667346960596122], [-2.9513409844272736, -0.8308041149223722], [-3.0525702187102848, -0.8970783878192974], [-3.1528531887709175, -0.9658913604113011], [-3.25493913830157, -1.0379629359384206], [-3.3612681922638727, -1.1139021444876271], [-3.4725675825974993, -1.193842039192509], [-3.58588491431963, -1.2783030155644421], [-3.69307804107666, -1.3711423873901367]]
实现过程图标表示:

3.3 推理过程
- 在 RViz 界面软件中使用“2D-Nav-Goal”来选择目标停车位
目标停车位停车轨迹示例:
position:
x: -6.49
y: -5.82
z: 0.0
orientation:
x: 0.0
y: 0.0
z: 0.0
w: 1.0目标停车位停车轨迹示例:position:x: -6.49y: -5.82z: 0.0orientation:x: 0.0y: 0.0z: 0.0w: 1.0
- 获取起始位姿,将以起始点为原点的世界坐标转化为车辆坐标
起始轨迹位姿示例:
position:
x: -0.16161775150943924
y: 0.018056780251669124
z: 0.006380920023400627
orientation:
x: -0.0002508110368611588
y: 0.0008039258947159855
z: 0.010172557118261405
w: 0.9999479035823092
- 组合数据输入到 transformer 进行推理,预测轨迹序列
预测的轨迹序列示例:
[[-0.17014217376708984, -0.010008811950683594], [-0.3298116556863353, -0.011956165423615472], [-0.4854376561367579, -0.02052420170634236], [-0.6337416331734281, -0.03509474854381417], [-0.774850889165686, -0.05409092178920946], [-0.9106318371186677, -0.07662342910150008], [-1.0429499912911764, -0.10220288211346742], [-1.1730293341546085, -0.130403150090076], [-1.3014671109093938, -0.16081194272771432], [-1.4284175031869575, -0.19315076247807056], [-1.5537739117230407, -0.22739195648381574], [-1.6773593831451739, -0.2637573983721455], [-1.7991250198403412, -0.3025803813592571], [-1.9192866870681176, -0.34410827406410627], [-2.0383187092132995, -0.3883681895794497], [-2.1567872059422366, -0.43518302389208097], [-2.275088086162824, -0.4843281463722012], [-2.393198715763861, -0.5357188397161318], [-2.5105481374226417, -0.5894858888356189], [-2.6260817537118184, -0.6458681996255287], [-2.7385546018760474, -0.7049937228225489], [-2.84701611529502, -0.7667346960596122], [-2.9513409844272736, -0.8308041149223722], [-3.0525702187102848, -0.8970783878192974], [-3.1528531887709175, -0.9658913604113011], [-3.25493913830157, -1.0379629359384206], [-3.3612681922638727, -1.1139021444876271], [-3.4725675825974993, -1.193842039192509], [-3.58588491431963, -1.2783030155644421], [-3.69307804107666, -1.3711423873901367]]
- 将预测的轨迹序列发布到 rviz 进行可视化

04 评估指标
端到端实车评估:在实车实验中,我们使用以下指标来评估端到端停车性能。
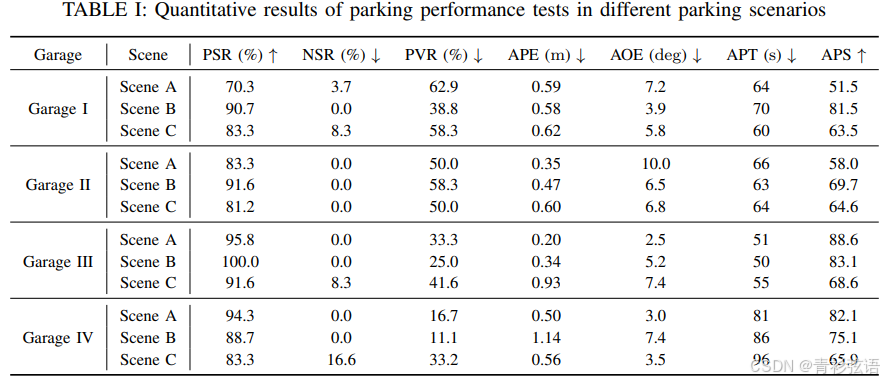
关键词解释:
PSR:停车成功率
NSR:无车位率
PVR:停车违规率
APE:平均位置误差
AOE:平均方向误差
APS:平均停车得分
APT:平均停车时间
05 局限性
- 由于数据规模和场景多样性的限制,我们的方法对移动目标的适应性较差
- 训练过程需要专家轨迹
.(img-7orUMtby-1731052248424)]
关键词解释:
PSR:停车成功率
NSR:无车位率
PVR:停车违规率
APE:平均位置误差
AOE:平均方向误差
APS:平均停车得分
APT:平均停车时间
05 局限性
- 由于数据规模和场景多样性的限制,我们的方法对移动目标的适应性较差
- 训练过程需要专家轨迹
- 与传统的基于规则的停车方法相比仍有差距