在 PyTorch 框架中,有一个看似简单的设置可以对模型性能产生重大影响:
pin_memory
。这个设置具体起到了什么作用,为什么需要关注它呢?如果你正在处理大规模数据集、实时推理或复杂的多 GPU 训练任务,将
pin_memory
设为
True
可以提高 CPU 与 GPU 之间的数据传输速度,有可能节省关键的毫秒甚至秒级时间,而这些时间在数据密集型工作流中会不断累积。

你可能会产生疑问:为什么
pin_memory
*如此重要?*其本质在于:
pin_memory
设为
True
时会在 CPU 上分配页面锁定(或称为"固定")的内存,加快了数据向 GPU 的传输速度。本文将深入探讨何时以及为何启用这一设置,帮助你优化 PyTorch 中的内存管理和数据吞吐量。
pin_memory 的作用及其工作原理
在 PyTorch 的
DataLoader
中,
pin_memory=True
不仅仅是一个开关,更是一种工具。当激活时,它会在 CPU 上分配页面锁定的内存。你可能已经熟悉虚拟内存的基本概念,以及将数据传输到 GPU 通常需要复制两次:首先从虚拟内存复制到 CPU 内存,然后再从 CPU 内存复制到 GPU 内存。使用
pin_memory=True
后,数据已被"固定"在 CPU 的 RAM 中,随时准备直接快速传输至 GPU,绕过了不必要的开销。
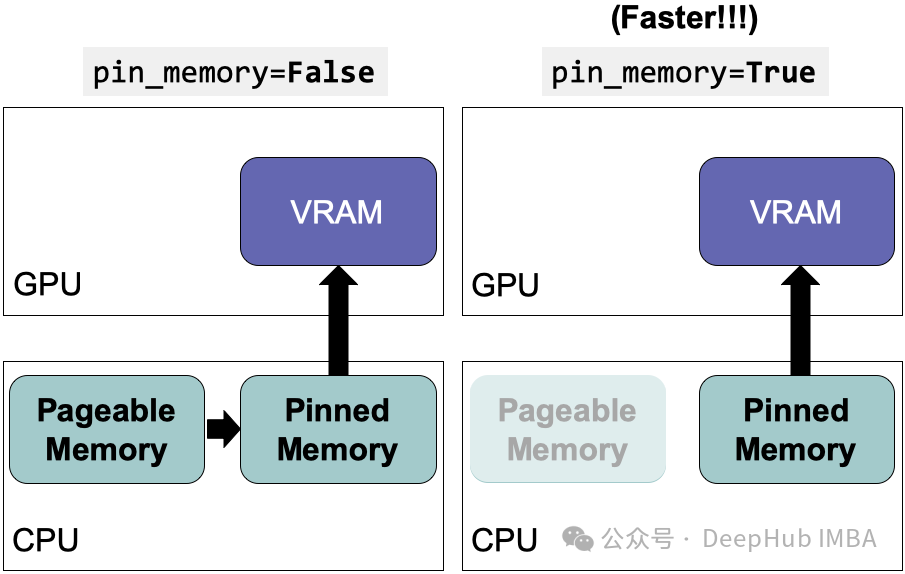
问题的关键在于:页面锁定内存允许以异步、非阻塞的方式将数据传输到 GPU。因此当模型正在处理某个批次时,下一个批次数据已经预加载至 GPU 中,无需等待。这一优势可能看似微小,但它可以显著减少训练时间,尤其是对于数据量巨大的任务。
何时使用pin_memory=True
以下是启用
pin_memory=True
可以在工作流程中产生显著效果的情况。
1、使用高吞吐量数据加载器的 GPU 训练
在基于 GPU 的训练中,特别是在处理大型数据集(如高分辨率图像、视频或音频)时,数据传输的瓶颈会导致效率低下。如果数据处理的速度太慢,GPU 最终会处于等待状态,实际上浪费了处理能力。通过设置
pin_memory=True
,可以减少这种延迟,让 GPU 更快地访问数据,有助于充分利用其算力。
下面是如何在 PyTorch 中使用
pin_memory=True
设置高吞吐量的图像分类代码示例:
importtorch
fromtorch.utils.dataimportDataLoader
fromtorchvisionimportdatasets, transforms
# 定义图像转换
transform=transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
])
# 加载数据集
dataset=datasets.ImageFolder(root='path/to/data', transform=transform)
# 使用 pin_memory=True 的 DataLoader
dataloader=DataLoader(
dataset,
batch_size=64,
shuffle=True,
num_workers=4,
pin_memory=True # 加快数据向 GPU 的传输速度
)
# 数据传输至 GPU
device=torch.device('cuda'iftorch.cuda.is_available() else'cpu')
forbatchindataloader:
images, labels=batch
images=images.to(device, non_blocking=True) # 更快的传输
# 训练循环代码
pin_memory=True
有助于确保数据以最高效的方式移动到 GPU,尤其是当与
.to(device)
中的
non_blocking=True
结合使用时。
2、多 GPU 或分布式训练场景
当使用多 GPU 配置时,无论是通过
torch.nn.DataParallel
还是
torch.distributed
,高效数据传输的重要性都会提高。GPU 需要尽快接收数据,避免等待数据而导致并行化效率低下。使用
pin_memory=True
可以加快跨多个 GPU 的数据传输,提高整体吞吐量。
多 GPU 设置中的
pin_memory
importtorch
fromtorchimportnn
fromtorch.utils.dataimportDataLoader
fromtorchvisionimportdatasets, transforms
# 多 GPU 设置
device=torch.device('cuda'iftorch.cuda.is_available() else'cpu')
# 示例网络和 DataLoader 设置
model=nn.DataParallel(nn.Linear(256*256*3, 10)).to(device)
dataloader=DataLoader(
datasets.ImageFolder('path/to/data', transform=transform),
batch_size=64,
shuffle=True,
num_workers=4,
pin_memory=True # 为跨 GPU 的快速传输启用
)
# 多 GPU 训练循环
forbatchindataloader:
inputs, targets=batch
inputs, targets=inputs.to(device, non_blocking=True), targets.to(device)
outputs=model(inputs)
# 其他训练步骤
当跨多个 GPU 分发数据时,
pin_memory=True
尤其有用。将其与
non_blocking=True
结合,可确保 GPU 数据传输尽可能无缝,减少数据加载成为多 GPU 训练的瓶颈。
3、低延迟场景或实时推理
在延迟至关重要的场景中,例如实时推理或需要快速响应的应用,
pin_memory=True
可以提供额外优势。通过减少将每个批次数据加载到 GPU 的时间,可以最小化延迟并提供更快的推理结果。
importtorch
fromtorchvisionimporttransforms
fromPILimportImage
# 定义实时推理的图像转换
transform=transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor()
])
# 加载图像并固定内存
defload_image(image_path):
image=Image.open(image_path)
image=transform(image).unsqueeze(0)
returnimage.pin_memory() # 为推理显式固定内存
# 实时推理
device=torch.device('cuda'iftorch.cuda.is_available() else'cpu')
model=torch.load('model.pth').to(device).eval()
definfer(image_path):
image=load_image(image_path)
withtorch.no_grad():
image=image.to(device, non_blocking=True)
output=model(image)
returnoutput
# 运行推理
output=infer('path/to/image.jpg')
print("推理结果:", output)
在这个实时推理设置中,
pin_memory=True
允许更平滑、更快速的数据传输,在严格的延迟约束下工作时至关重要。正是这些小优化在每毫秒都很宝贵的应用中能产生显著差异。
何时避免使用 pin_memory=True
pin_memory=True
虽然很有用,但与任何工具一样,它也有局限性。以下是可能需要跳过启用该设置的情况:
1、仅 CPU 训练
如果不使用 GPU,那么
pin_memory=True
对你没有任何作用。固定内存的目的是简化 CPU 和 GPU 之间的数据传输。当只使用 CPU 时,没有必要启用此选项,因为没有数据需要移动到 GPU。
在仅 CPU 设置中,启用
pin_memory=True
只会消耗额外的 RAM 而没有任何好处,这可能导致内存密集型任务的性能下降。因此,对于仅 CPU 的工作流,请保持此设置禁用。
2、数据密集程度低的任务或小型数据集
有时添加
pin_memory=True
可能是多余的。对于加载后很容易放入 GPU 内存的较小数据集,
pin_memory
的好处可以忽略不计。考虑简单的模型、内存需求低或微小数据集的情况,这里的数据传输开销不是主要问题。
比如说一个文本分类任务,其中数据集相对较小。以下代码示例展示了设置
pin_memory=True
如何没有增加价值:
importtorch
fromtorch.utils.dataimportDataLoader, TensorDataset
# 小数据集示例
data=torch.randn(100, 10) # 100 个样本, 10 个特征
labels=torch.randint(0, 2, (100,))
# 数据集和 DataLoader 设置
dataset=TensorDataset(data, labels)
dataloader=DataLoader(dataset, batch_size=10, shuffle=True, pin_memory=True)
# 简单的基于 CPU 的模型
model=torch.nn.Linear(10, 2)
# 在 CPU 上的训练循环
device=torch.device('cpu')
forbatch_data, batch_labelsindataloader:
batch_data, batch_labels=batch_data.to(device), batch_labels.to(device)
# 前向传递
outputs=model(batch_data)
# 执行其他训练步骤
由于整个数据集很小,在这里使用
pin_memory=True
没有真正的影响。事实上,它可能会稍微增加内存使用量而没有任何实质性的好处。
3、内存有限的系统
如果在内存有限的机器上工作,启用
pin_memory=True
可能会增加不必要的压力。固定内存时,数据会保留在物理 内存中,这可能很快导致内存受限系统上的瓶颈。内存耗尽可能会减慢整个进程,甚至导致崩溃。
提示:对于 8GB 或更少内存的系统,通常最好保持
pin_memory=False
,除非正在使用受益于此优化的非常高吞吐量模型。(但是对于8GB 的内存,进行大规模训练也没有什么意义,对吧)
代码比较: pin_memory=True和False
为了看到
pin_memory
的实际影响,我们进行一个比较。使用
torch.utils.benchmark
测量
pin_memory=True
和
pin_memory=False
时的数据传输速度,切实地展示性能上的差异。
importtorch
fromtorch.utils.dataimportDataLoader, TensorDataset
importtorch.utils.benchmarkasbenchmark
# 用于基准测试的大型数据集
data=torch.randn(10000, 256)
labels=torch.randint(0, 10, (10000,))
dataset=TensorDataset(data, labels)
# 使用 pin_memory=True 和 pin_memory=False 进行基准测试
defbenchmark_loader(pin_memory):
dataloader=DataLoader(dataset, batch_size=128, pin_memory=pin_memory)
device=torch.device('cuda')
defload_batch():
forbatch_data, _indataloader:
batch_data=batch_data.to(device, non_blocking=True)
returnbenchmark.Timer(stmt="load_batch()", globals={"load_batch": load_batch}).timeit(10)
# 结果
time_with_pin_memory=benchmark_loader(pin_memory=True)
time_without_pin_memory=benchmark_loader(pin_memory=False)
print(f"使用 pin_memory=True 的时间: {time_with_pin_memory}")
print(f"使用 pin_memory=False 的时间: {time_without_pin_memory}")
在这段代码中,
benchmark.Timer
用于测量性能差异。当数据量很大时,很可能会观察到
pin_memory=True
加快了数据传输时间。将这些结果可视化(或简单地将其作为打印值查看)可以清楚地证明使用固定内存对性能的影响。
如果你想测试你的训练流程是否需要pin_memory 设置,可以运行上面的代码,结果就一目了然了。
pin_memory=True 的影响
对于致力于优化数据处理的开发者而言,使用 PyTorch 内置分析工具测量
pin_memory=True
的效果非常有价值。这可以提供数据加载与 GPU 计算所花费时间的详细信息,帮助准确定位瓶颈,并量化使用固定内存节省的时间。
以下是如何使用
torch.autograd.profiler.profile
分析数据传输时间,跟踪加载和传输数据所花费的时间:
importtorch
fromtorch.utils.dataimportDataLoader, TensorDataset
fromtorch.autogradimportprofiler
# 示例数据集
data=torch.randn(10000, 256)
labels=torch.randint(0, 10, (10000,))
dataset=TensorDataset(data, labels)
dataloader=DataLoader(dataset, batch_size=128, pin_memory=True)
# 使用 pin_memory=True 分析数据传输
device=torch.device('cuda')
defload_and_transfer():
forbatch_data, _indataloader:
batch_data=batch_data.to(device, non_blocking=True)
withprofiler.profile(record_shapes=True) asprof:
load_and_transfer()
# 显示分析结果
print(prof.key_averages().table(sort_by="cpu_time_total", row_limit=10))
在上述示例中,
prof.key_averages().table()
显示了每个操作所花费时间的摘要,包括数据加载和传输到 GPU。这种细分有助于了解
pin_memory=True
是否通过减少 CPU 开销和加快传输时间提供了切实的改进。
DataLoader 中使用 pin_memory 的最佳实践
设置
pin_memory=True
可以提高性能,但将其与适当的
num_workers
设置和
.to(device)
中的
non_blocking=True
结合使用,可以将性能提升到新的水平。以下是如何在数据管线中充分利用
pin_memory
:
1、结合
pin_memory
和
num_workers
需要注意的是:
DataLoader
中的
num_workers
设置控制加载批次数据的子进程数量。使用多个 worker 可以加速数据加载,当与
pin_memory=True
结合使用时,可以最大化数据吞吐量。但是如果
num_workers
设置过高,可能会与内存或 CPU 资源竞争,适得其反。
为了找到合适的平衡,需要尝试不同的
num_workers
值。通常将其设置为 CPU 内核数是一个不错的经验法则,但始终需要分析以找到最佳设置。
2、使用**
non_blocking=True
进行异步数据传输
如果希望从数据处理中榨取每一丝速度,可以考虑将
pin_memory=True
与
.to(device)
中的
non_blocking=True
结合使用。将数据传输到 GPU 时,
non_blocking=True
允许传输异步进行。这样模型可以开始处理数据,而无需等待整个批次传输完成,在 I/O 密集型工作流中可以带来性能提升。
总结
在数据密集型、GPU 加速的训练领域,即使是小的优化也能产生显著的性能提升。以下是何时以及如何使用
pin_memory=True
的快速回顾:
- 高吞吐量 GPU 训练:处理大型数据集时,启用
pin_memory=True,因为它可以加速数据从 CPU 到 GPU 的传输。 - 多 GPU 或分布式训练:在需要高效数据传输的多 GPU 设置中,此设置尤其有益。
- 低延迟或实时应用:当最小化延迟至关重要时,
pin_memory=True与non_blocking=True相结合可以优化管线。
尝试
num_workers
的不同值,同时测试
pin_memory
和
non_blocking
设置,并使用分析工具衡量它们对数据传输速度的影响。
虽然
pin_memory=True
很有价值,但 PyTorch 还提供了其他值得探索的内存相关设置和技术,例如多进程中的内存固定或使用
torch.cuda.memory_allocated()
进行监控。
通过使用pin_memory可以尽可能高效地进行数据传输,为 PyTorch 模型提供性能提升,充分利用 GPU 资源。
https://avoid.overfit.cn/post/cfbf700dc65741009372cf73ad53af36


















