1. Spark Streaming
Spark Streaming 是 Apache Spark 的一个组件,用于实时流数据处理。
1.1 核心特点
-
微批处理:
- 将实时数据分割成小批次(micro-batches),每个批次由 Spark 的核心引擎处理。
-
高度容错性:
- 支持将处理的状态和数据保存到 HDFS,具备断点恢复功能。
-
与 Spark 深度集成:
- 支持与 Spark Core、MLlib(机器学习)、SQL 等模块协同工作。
-
多数据源支持:
- 支持 Kafka、Flume、HDFS、Socket 等多种输入源。
1.2 工作流程
- 从数据源读取实时数据流。
- 将数据切分成小批次。
- 使用 Spark 提供的高效分布式计算处理数据。
- 将处理结果输出到目标存储或服务(如 HDFS、数据库、Kafka)。
1.3 应用场景
- 实时日志处理(如用户行为分析)。
- 实时监控和告警(如欺诈检测、网络异常监控)。
- 流式数据 ETL(如数据清洗、聚合)。
2. Spark
Apache Spark 是一个分布式内存计算框架,主要用于大规模数据处理,支持批处理、流处理和图计算。
2.1 核心特点
-
内存优先计算:
- 数据在内存中操作,显著提高了计算速度。
-
统一计算模型:
- 提供批处理(Batch)、流处理(Streaming)、机器学习(MLlib)和图计算(GraphX)功能。
-
丰富的 API:
- 支持多种编程语言(如 Python、Java、Scala)。
- 提供简洁的高阶 API,如 DataFrame 和 Dataset。
-
高扩展性:
- 通过分布式计算架构支持 PB 级别的数据处理。
-
容错性:
- 基于 RDD(弹性分布式数据集)实现数据重算机制。
2.2 核心组件
- Spark Core:处理底层计算任务。
- Spark SQL:用于结构化数据查询。
- Spark Streaming:用于实时流数据处理。
- MLlib:分布式机器学习库。
- GraphX:分布式图计算库。
2.3 应用场景
- 批量数据处理(如大规模日志分析)。
- 实时数据分析(如点击流分析)。
- 机器学习任务(如推荐系统、预测分析)。
- 图数据处理(如社交网络分析)。
3. MapReduce
MapReduce 是一种分布式计算模型,最早由 Google 提出,用于大规模数据的并行处理。
3.1 核心思想
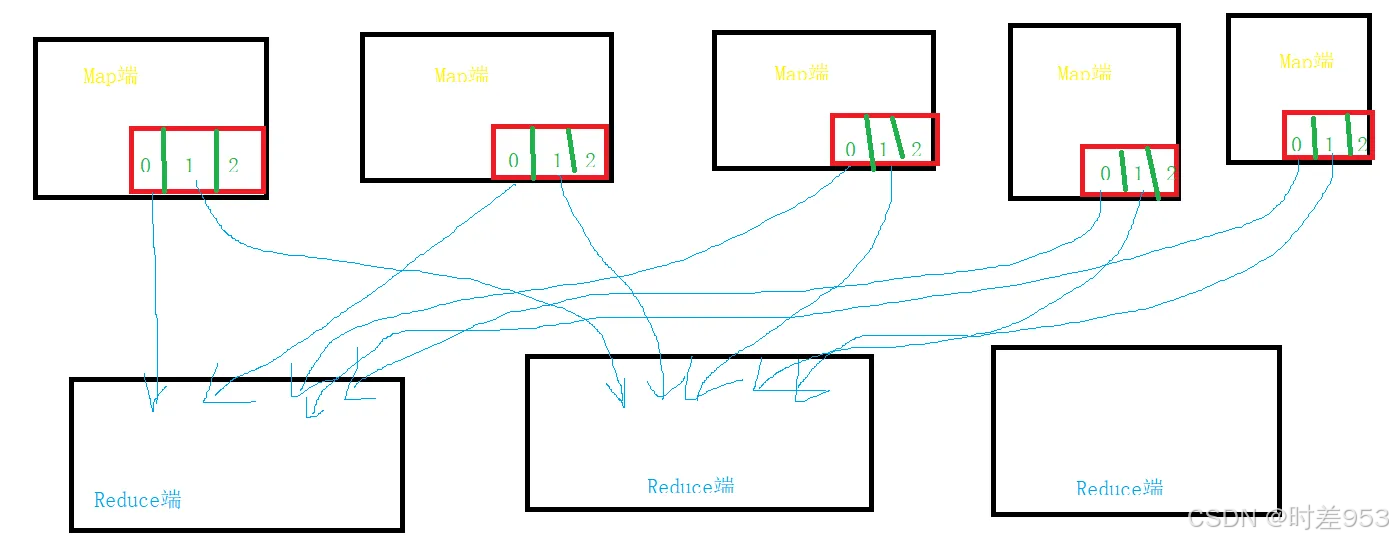
- Map(映射):
- 将数据分成小块,在各节点上并行处理。
- Reduce(归约):
- 将 Map 阶段输出的数据按键值分组并聚合。
3.2 优势
-
可扩展性:
- 支持处理 PB 级别的数据。
-
容错性:
- 通过任务重试机制实现节点故障恢复。
-
适用范围广:
- 支持结构化、非结构化和半结构化数据处理。
3.3 局限性
- 高延迟:
- MapReduce 的处理过程依赖磁盘 I/O,速度较慢。
- 开发复杂:
- 编程模型简单,但需要编写大量代码。
3.4 应用场景
- 批量处理海量数据(如日志文件分析)。
- 数据聚合(如按字段统计)。
4. Impala
Apache Impala 是一个大数据实时交互式查询工具,用于在存储于 HDFS、Kudu 和 HBase 中的数据上执行低延迟查询。
4.1 核心特点
-
交互式查询:
- 提供类似 SQL 的查询接口,支持快速查询。
-
分布式架构:
- 基于 MPP(大规模并行处理)架构,提供高并发性能。
-
与 Hadoop 深度集成:
- 使用 HDFS 和 Hive 元数据,直接查询 Hive 表。
-
高效性:
- 内存计算优化了查询性能,适合实时分析。
4.2 架构
- Impala Daemon(ImpalaD):
- 运行在每个节点上,负责执行查询任务。
- StateStore:
- 管理 ImpalaD 的状态信息。
- Catalog Service:
- 管理元数据。
4.3 应用场景
- 实时 BI(商业智能)查询。
- 大数据平台的 SQL 查询加速。
5. Hive
Apache Hive 是一个基于 Hadoop 的数据仓库工具,提供 SQL 类语言(HiveQL)来操作存储在 HDFS 或其他兼容系统中的数据。
5.1 核心特点
-
SQL 接口:
- 支持复杂查询,通过 HiveQL 操作大数据。
-
批量处理:
- 使用 MapReduce、Tez 或 Spark 作为计算引擎。
-
可扩展性:
- 支持分区和桶(Bucketing)优化查询性能。
-
元数据管理:
- 使用 RDBMS 管理表结构和元数据。
-
数据类型支持:
- 适合结构化和半结构化数据,如 JSON、Parquet。
5.2 应用场景
- 数据清洗和转换。
- 数据仓库分析。
- BI 工具集成(如 Tableau)。
5.3 与 Impala 的对比
| 特性 | Hive | Impala |
|---|---|---|
| 查询延迟 | 高(批处理) | 低(交互式查询) |
| 数据更新支持 | 较差 | 更好,支持增量更新 |
| 计算引擎 | MapReduce、Tez、Spark | 专用的内存计算引擎 |
总结
| 工具 | 核心功能 | 应用场景 |
|---|---|---|
| Spark Streaming | 实时流数据处理 | 实时日志处理、实时监控 |
| Spark | 分布式内存计算框架 | 批处理、实时数据分析、机器学习 |
| MapReduce | 分布式计算模型 | 大规模批处理任务 |
| Impala | 大数据实时查询工具 | 快速交互式 SQL 查询 |
| Hive | 数据仓库工具,基于 SQL 的批处理系统 | 数据清洗、数据仓库分析 |
这些工具在大数据处理的不同环节中各有优势,可以根据业务需求灵活组合使用。