文章目录
- 单词搜索
- 思路一
- 思路二
单词搜索
给定一个
m x n二维字符网格board和一个字符串单词word。如果word存在于网格中,返回true;否则,返回false。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
图一:

图二:

图三:

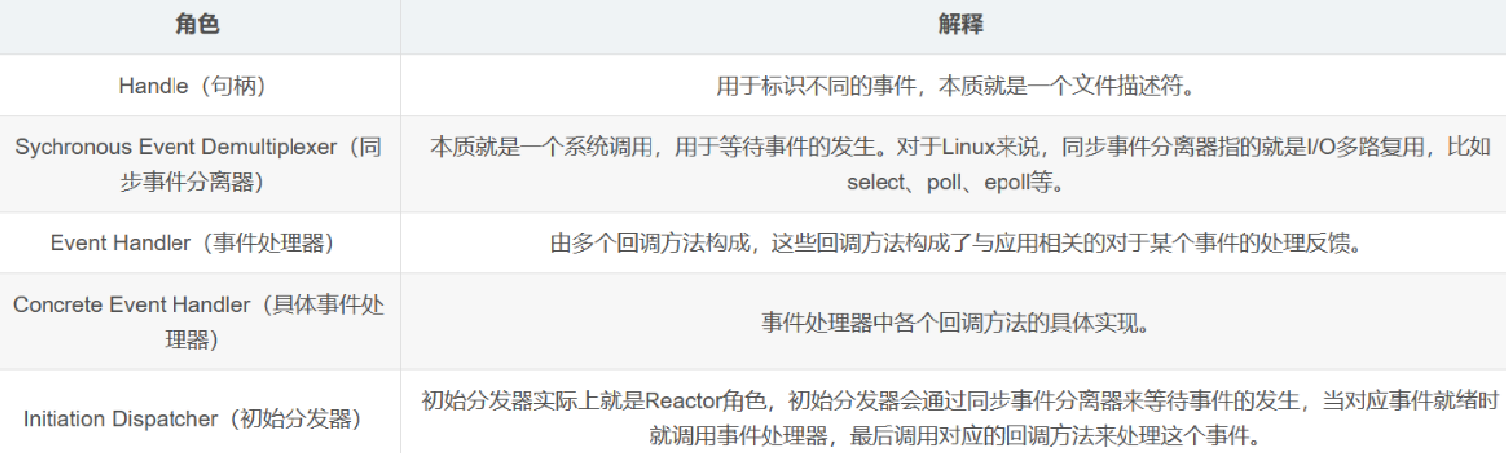
示例 1:图一
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true
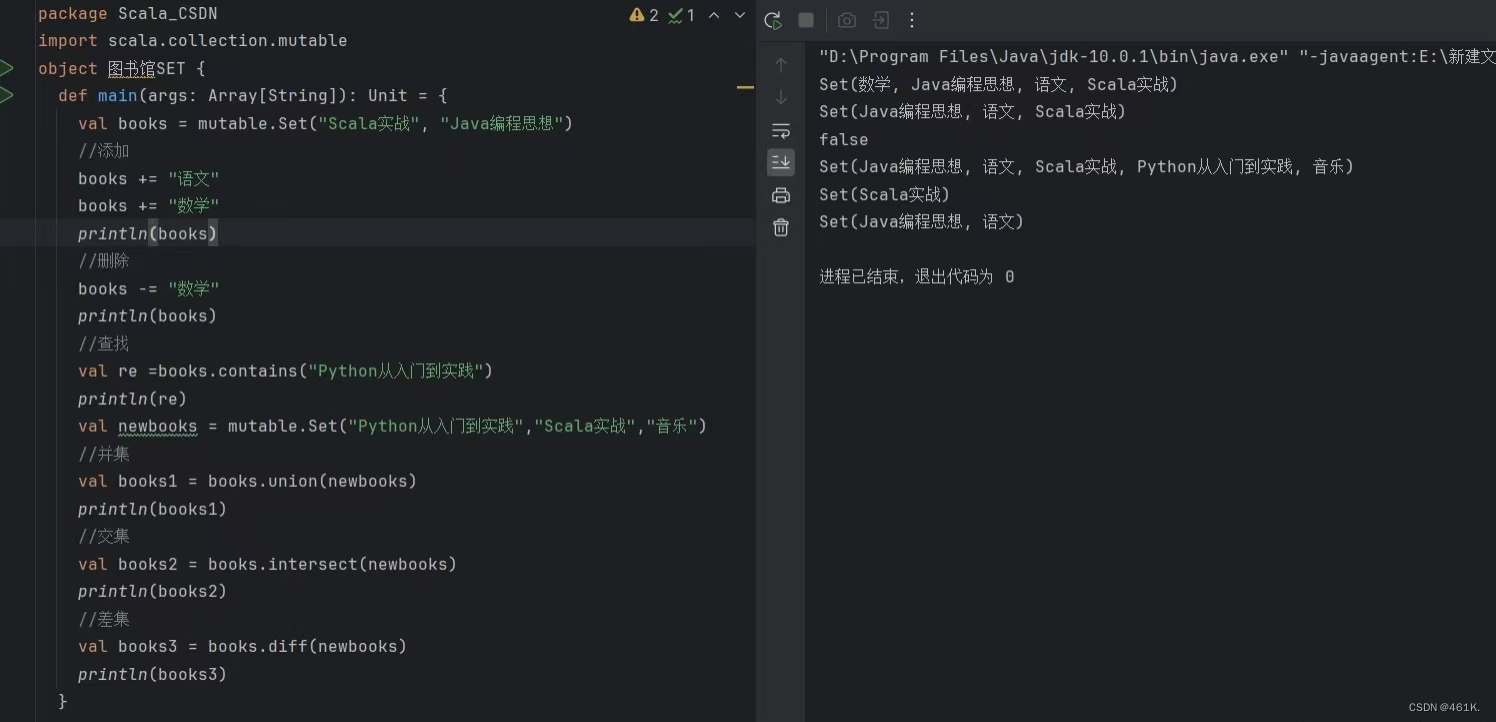
示例 2:图二
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE"
输出:true
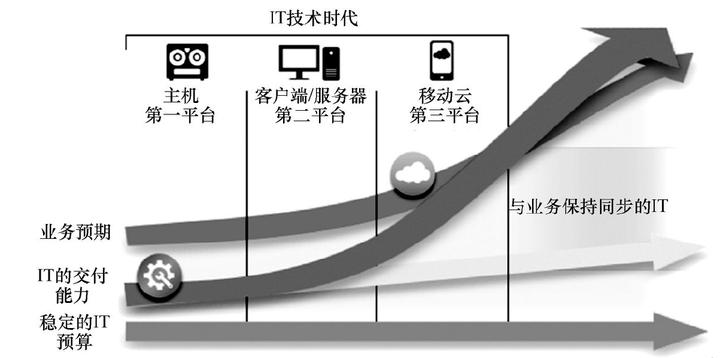
示例 3:图三
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB"
输出:false
思路一
function exist(board, word) {
const rows = board.length;
const cols = board[0].length;
const visited = Array.from({ length: rows }, () => Array(cols).fill(false));
function dfs(row, col, index) {
if (index === word.length) return true;
if (row < 0 || row >= rows || col < 0 || col >= cols || visited[row][col] || board[row][col] !== word[index]) {
return false;
}
visited[row][col] = true;
const found = dfs(row + 1, col, index + 1) || dfs(row - 1, col, index + 1) ||
dfs(row, col + 1, index + 1) || dfs(row, col - 1, index + 1);
visited[row][col] = false;
return found;
}
for (let row = 0; row < rows; row++) {
for (let col = 0; col < cols; col++) {
if (board[row][col] === word[0] && dfs(row, col, 0)) {
return true;
}
}
}
return false;
}
讲解
这道题目可以通过深度优先搜索(DFS)结合回溯(Backtracking)来解决。基本思路是在网格中的每个可能的起点开始,尝试沿着四个方向(上、下、左、右)进行深度优先搜索,看是否能找到与目标单词匹配的路径。如果在任何起点找到了匹配的路径,我们就返回true,否则返回false。
- 初始化:创建一个标志矩阵visited来记录哪些单元格已经被访问过。
- 递归函数:定义一个递归函数dfs,它接受以下参数:
○ 当前的行row和列col,
○ 目标单词word,
○ 当前匹配的单词位置index,
○ 二维字符网格board。- 基本结束条件:如果index等于word的长度,意味着我们已经找到了一个匹配的路径,返回true。
- 边界检查:如果row或col超出了board的范围,或者当前单元格已经被访问过,或者board[row][col]不等于word[index],返回false。
- 标记访问:在进入递归之前,标记当前单元格为已访问。
- 回溯过程:尝试在四个方向(上、下、左、右)上递归调用dfs函数。
- 回溯:在退出递归之前,将当前单元格的状态恢复为未访问。
- 开始搜索:对于board中的每个单元格,如果它与word的第一个字符匹配,调用dfs函数。
- 返回结果:如果在任何时候dfs函数返回true,立即返回true;否则,在所有单元格都搜索完毕后返回false。
思路二
var exist = function(board, word) {
const m = board.length;
const n = board[0].length;
function dfs(x, y, index) {
if (index === word.length) return true; // 找到单词
if (x < 0 || x >= m || y < 0 || y >= n || board[x][y] !== word[index]) return false; // 越界或不匹配
const temp = board[x][y];
board[x][y] = '#'; // 标记为已访问
const found = dfs(x + 1, y, index + 1) || // 下
dfs(x - 1, y, index + 1) || // 上
dfs(x, y + 1, index + 1) || // 右
dfs(x, y - 1, index + 1); // 左
board[x][y] = temp; // 恢复状态
return found;
}
for (let i = 0; i < m; i++) {
for (let j = 0; j < n; j++) {
if (dfs(i, j, 0)) return true; // 从每个单元格开始搜索
}
}
return false;
};
讲解
这段代码实现了一个深度优先搜索(DFS)算法,用于在一个二维字符网格中查找给定的单词。以下是对代码的逐行解析:首先,定义了一个函数 exist,接收一个二维字符数组 board 和一个字符串 word。接着,获取网格的行数 m 和列数 n。
在 exist 函数内部,定义了一个递归函数 dfs,它接受当前坐标 (x, y) 和当前要匹配的单词字符的索引 index。该函数首先检查是否已经匹配到单词的末尾,如果是,则返回 true。接着,检查当前坐标是否越界或当前字符是否与单词中的对应字符不匹配,如果是,则返回 false。
然后,保存当前字符并将其标记为已访问(用 ‘#’ 替代),以避免重复访问。接下来,通过递归调用 dfs 函数,向下、上、右、左四个方向继续搜索下一个字符。如果在任何方向上找到单词,则 found 为 true。
在递归返回后,恢复当前字符的状态,以便后续的搜索使用,并返回 found 的值。
最后,使用两层循环遍历网格中的每个字符,从每个字符开始调用 dfs 函数,如果找到单词,立即返回 true。如果遍历完所有字符都没有找到单词,则返回 false。
这段代码通过深度优先搜索的方式,逐步探索每个可能的路径,并在找到匹配时返回成功。通过标记已访问的字符,避免了重复访问的问题。