论文地址:https://arxiv.org/abs/2410.10293
github:
研究背景
现有的检索范式存在两个主要问题:一是平铺检索(flat retrieval)对单个检索器造成巨大负担;二是恒定粒度(constant granularity)限制了检索性能的上限。研究难点在于如何平衡检索的有效性和效f率。
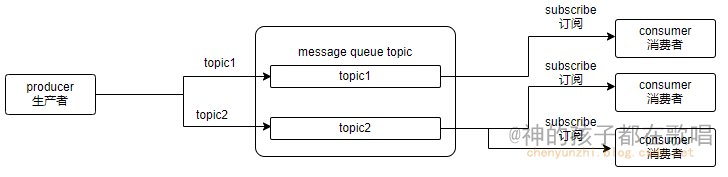
Flat Retrieval: corpus文档切片后大海捞针式检索。
Constant Granularity: 切片粒度一致,比如都按照512token切片
贡献点
- 强调了现有研究中忽略的现实世界RAG系统中的问题,即flat retrieval和constant granularity。
- 提出了一个粗细粒度渐进检索范式FUNNELRAG,用于RAG,满足了节省时间、细粒度、上下文完整性这三个特性。
- 广泛的实验证明了FUNNELRAG可以在减少时间开销的同时,保持或甚至提高现有检索范式的检索性能。
方法
1、渐进式检索(Coarse-to-Fine Progressive Retrieval)
与传统的平面检索不同,渐进式检索通过逐步减少候选规模、细化检索单位粒度和提高检索器能力来平衡有效性和效率。
Progressive Retrieval: 从文档cluster集合->文档->段落,later chunking

Progressive Retrieval具体步骤包括:

- 检索阶段(Retrieval):将文档集D聚类成粗粒度单元(clusters),使用稀疏检索器(如BM25)在这些粗粒度单元上进行检索,找到前K个最相关的粗粒度单元。
聚类方法:
1、排序:对文档集D中的文档按照它们的局部聚类系数进行排序。局部聚类系数是一个衡量文档在其邻居中形成紧密连接程度的指标。这意味着,如果一个文档与很多其他文档都有链接,那么它的局部聚类系数就会很高
2、查找相关聚类:调用一个名为
FIND_RELATED_CLUSTER的函数,输入参数为当前文档d和当前的聚类集合C。这个函数的目的是找到与文档d相关的所有聚类,并将它们作为一个集合R返回。3、合并聚类:我们遍历集合R中的每个相关聚类c,并检查是否可以将它们合并到新聚类c_new中。合并的条件是新聚类c_new的大小(即包含的文档数量)加上要合并的聚类c的大小不超过最大聚类大小S。如果满足条件,我们就将聚类c合并到c_new中,将新聚类c_new添加到聚类集合C中,并从聚类集合C中移除聚类c,
- 预排序阶段(Pre-ranking):使用cross encoder models对检索到的单元(cluster细分到document粒度)进行预排序,缩小候选范围。
- 后排序阶段(Post-ranking):使用list-wise models对细粒度单元(paragraph粒度)进行后排序,进一步提高检索精度。
Later Chunking:早期阶段检索长单元以保留上下文语义,然后在后期阶段将这些长单元分割成细粒度单元以进行更好的检索应用
基于FiD的解码器:后排名器基于FiD(Fusion-in-Decoder)架构,它是一个检索增强的编码器-解码器语言模型。系统使用检索增强的段落来训练FiD,以便学习寻找线索。然后,它获得后排名分数,并将这些段落中得分最高的作为“oracle”段落。
2、蒸馏对齐
对齐Post-ranking和Pre-ranking阶段的模型能力,使用局部到全局(L2G)的蒸馏方式。
(注意Pre-ranking阶段是文档粒度,Post-ranking阶段是paragraph粒度,需要归一化粒度)
STEP1: 找到post-reranking阶段的positive Document
Post-ranking阶段文档粒度score计算如下, 当α = 1时,分数集中在文件中最重要的段落;当α = 0时,分数集中于文档中所有段落的平均重要程度:

STEP 2:确定pre-ranking阶段的postive Document D+和negative Document D-集合
根据这个分数排序找到TOP-K个文档,和命中ground truth的文档取并集为D+集合,D-为之外的集合:

STEP3: preranking模型训练,数据:D+和D-,loss function: pairwise Bayesian Personalized Ranking (BPR)

实验结果
研究问题:
RQ1:渐进式检索与普通检索相比,提升了Answer Recall?
RQ2:QA场景下使用funnelRAG收益?
RQ3:不同的设置如何影响渐进式检索的有效性?
实验配置:
-
Datasets:Natural Question (NQ)、Trivia QA (TQA)
-
Metrics: Answer Recall (Retrieval)、Exact Match (Generation)
-
Retrievers: BM25(retrieval) + bge-reranker-v2-m3(pre-ranker) + FiD(post-ranking) vs bge-large-en-v1.5 (flat retrieval) + bge-reranker-v2-m3(rerank)
-
Generators: Llama3-8B-Instruct、Qwen2-7B-Instruct
实验结果:
RQ1: AR略微提升的情况下,TC降低约40%

RQ2: TOP-K较小的情况,funnelRAG效果较好

RQ3:
a. 不同的cluster大小带来的影响(1K, 2K, 4K, 8K) , 设置最大聚类大小(S)为4K时,FUNNELRAG的性能最佳。设置得太小(如1K)会显著降低性能,而设置为更大的值(如8K)则没有明显增益。
b. 用少量(如4个)representation token进行聚合交叉注意力分数 (FiD) 显著优于不使用rep token的情况;设置少量的rep token(如4个)效果最好,设置过多(如1个)会损害检索性能。
 c. L2G的影响,使用更高值(如0.75)的α进行局部到全局蒸馏通常会带来更好的性能,特别是在排名靠前的位置上有显著改进。即使在排名靠后的位置上,不同α值的改进相对较小,但总体而言,建议在0.5到1.0之间调整α以获得最佳效果。
c. L2G的影响,使用更高值(如0.75)的α进行局部到全局蒸馏通常会带来更好的性能,特别是在排名靠前的位置上有显著改进。即使在排名靠后的位置上,不同α值的改进相对较小,但总体而言,建议在0.5到1.0之间调整α以获得最佳效果。
局限性
●指标,AR主要是检索指标,可能会高估检索信息的有用性,因为它机械地衡量检索信息是否包含答案字符串,即使检索信息没有传达准确的含义。评估RAG的指标仍然是一个开放的研究领域,仍需进一步研究。
● 调参,为了实现负载均衡和提高检索准确性,需要调整一些超参数,例如最大集群大小S,以及每个阶段之间需要仔细协作的数据流量,例如每个阶段检索到的单元数量。
● 兼容性问题,更换检索or生成模型,效果会有影响