2024-10-10,由浙江大学和阿里巴巴集团联合创建的WORFBENCH,一个用于评估大型语言模型(LLMs)生成工作流能力的基准测试。它包含了一系列的测试和评估协议,用于量化和分析LLMs在处理复杂任务时分解问题和规划执行步骤的能力。WORFBENCH 通过模拟多种应用场景和复杂的图结构工作流,为研究人员提供了一个统一的框架来评估和比较不同LLMs的性能。
一、研究背景:
随着大型语言模型在处理复杂任务方面能力的显著提升,将复杂问题分解为可执行的工作流成为了实现实际部署的关键步骤。然而,现有的工作流评估框架要么只关注整体性能,要么存在场景覆盖有限、工作流结构简单和评估标准宽松等限制。
目前遇到困难和挑战:
1、现有的评估基准大多只关注功能调用任务,忽视了更复杂的工作流结构,如并行性。
2、LLMs在生成工作流时容易受到幻觉和歧义的影响,导致评估缺乏系统性。
3、当前的工作流评估过于依赖GPT-3.5/4,而这些模型本身在复杂任务规划中的表现并不理想。
数据集地址:WORFBENCH|大型语言模型数据集|工作流生成数据集
二、让我们来一起看一下WORFBENCH
WORFBENCH是一个统一的工作流生成基准,包含多方面的应用场景和复杂的图结构工作流,目的全面提升LLMs的工作流生成能力。涵盖了问题解决、功能调用、具身规划和开放性规划等四种复杂的应用场景,包含了18k训练样本、2146个测试样本和723个用于评估泛化能力的保留任务。
整个构建过程包括任务的收集、节点链的构建、工作流图的生成以及严格的质量控制和数据过滤。通过GPT-4生成节点链和工作流图,并通过拓扑排序算法和人工评估来确保数据集的质量。
WORFBENCH提供了一套系统化的评估协议WORFEVAL,使用子序列和子图匹配算法来准确量化LLM代理的工作流生成能力。此外,还支持对不同规模的LLMs进行评估,并可以分析工作流如何增强端到端模型的性能。
基准测试 :
通过在WORFBENCH上的综合评估,研究人员发现即使是GPT-4这样的模型,在图结构化工作流的预测能力上也远远达不到实际要求,性能差距约为15%。此外,通过训练开源模型并评估其在保留任务上的泛化能力,进一步证明了WORFBENCH的有效性和实用性。
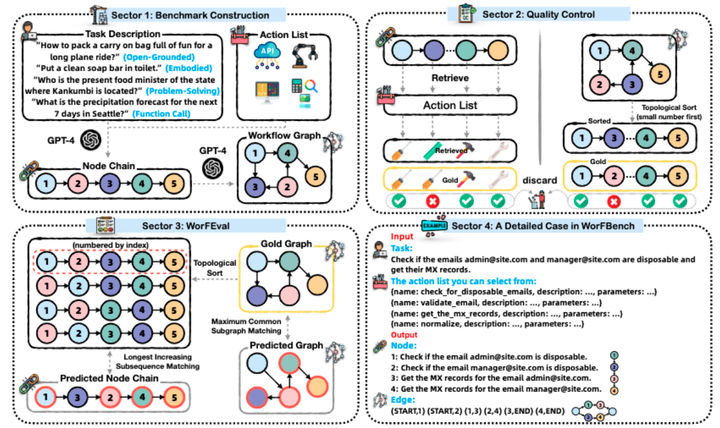
概述框架WORFBENCH:第1 扇区是基准构建,我们首先合成节点链,然后是工 作流图。第二部分是我们的数据过滤过程(§。第3部分描述了WORFEVAL中的算法,以评 估LLM代理的预测工作流。第四部分是我们WORFBENCH的详细数据点。请注意,图中的每个 节点都由其颜色唯一标识。
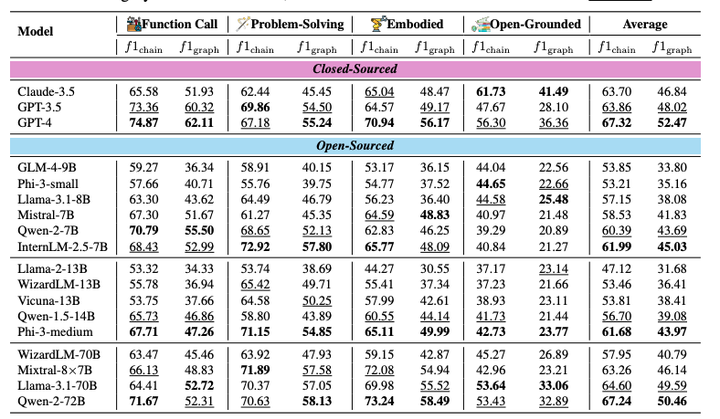
我们使用相同的精心设计指令和两个示例来评估所有模型。我们根据模型是否开源以及它们的规模对模型进行分类。每个类别中的最佳结果用粗体标出,第二好的结果用下划线标出。
三、让我们一起展望 WORFBENCH的应用:
想象一下,你是一个智能家居系统的AI大脑。
你的任务是帮助主人准备一个晚餐。主人家今天回来很多小朋友,所以这个重任就落在了你的肩上。
首先,你得检查一下家里的食材库存。你控制着家里的智能冰箱,查看了里面的蔬菜和肉类,发现冰箱里有新鲜的番茄和牛肉,但是缺少了一些香料和饮料。于是,你生成了一个购物清单,并通过智能家居系统发送给了主人。
主人回来后,根据你的清单采购了所需的物品。现在,你得开始规划晚餐的菜单和烹饪流程了。你决定做一道经典的番茄牛肉意面。你根据冰箱里的食材和主人新买的香料,制定了一个详细的烹饪计划。
烹饪开始了,你首先指导主人把牛肉切成薄片,然后用橄榄油、大蒜和香料腌制。同时,你还控制着智能烤箱预热到合适的温度。牛肉腌制好后,你指导主人将其放入烤箱中烤制。
在牛肉烤制的同时,你也没闲着,开始准备意面和番茄 sauce。你指导主人把意面放入锅中煮熟,同时用智能搅拌机打碎番茄,制作出新鲜的番茄酱。你还控制着智能定时器,确保意面不会煮过头。
最后,当一切准备就绪,你指导主人将烤好的牛肉和热腾腾的番茄酱与意面混合,撒上一些新鲜的芝士,一道美味的番茄牛肉意面就完成了。
在这个过程中,你不仅要处理厨房里的各种智能设备,还要根据实际情况灵活调整计划。比如,当发现烤箱预热不够快时,你得决定是否先准备酱料,或者调整烤箱的温度。这就像是在玩一个实时策略游戏,你得随时做出决策,确保一切都能按时完成。
最后,一盘盘香气扑鼻、味道鲜美、色泽诱人的意面被小吃货们一扫而光。嚷嚷着下次还要来做客。
一个大型语言模型在动态环境中执行动作的能力,它需要理解任务、规划步骤、控制设备,并且能够根据实际情况灵活调整计划。这种能力对于智能家居系统来说是非常有价值的,它可以让家庭生活更加便捷和高效。