1. 牛客大厂笔试真题SQLW6:统计所有课程参加培训人次
1.1 题目:
描述
某公司员工培训信息数据如下:
员工培训信息表cultivate_tb(info_id-信息id,staff_id-员工id,course-培训课程),如下所示:
注:该公司共开设了三门课程,员工可自愿原则性培训0-3项,每项课程每人可培训1次。

问题:请统计该公司所有课程参加培训人次?
示例数据结果如下:
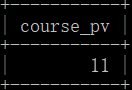
解释:course1课程共有员工1、3、4、7共4名员工培训;
course2课程共有员工1、2、4、7共4名员工培训;
course3课程共有员工3、4、5共3名员工培训;
示例1
输入:
drop table if exists `staff_tb` ;
CREATE TABLE `staff_tb` (
`staff_id` int(11) NOT NULL,
`staff_name` varchar(16) NOT NULL,
`staff_gender` char(8) NOT NULL,
`post` varchar(11) NOT NULL,
`department` varchar(16) NOT NULL,
PRIMARY KEY (`staff_id`));
INSERT INTO staff_tb VALUES(1,'Angus','male','Financial','dep1');
INSERT INTO staff_tb VALUES(2,'Cathy','female','Director','dep1');
INSERT INTO staff_tb VALUES(3,'Aldis','female','Director','dep2');
INSERT INTO staff_tb VALUES(4,'Lawson','male','Engineer','dep1');
INSERT INTO staff_tb VALUES(5,'Carl','male','Engineer','dep2');
INSERT INTO staff_tb VALUES(6,'Ben','male','Engineer','dep1');
INSERT INTO staff_tb VALUES(7,'Rose','female','Financial','dep2');
drop table if exists `cultivate_tb` ;
CREATE TABLE `cultivate_tb` (
`info_id` int(11) NOT NULL,
`staff_id` int(11) NOT NULL,
`course` varchar(32) NULL,
PRIMARY KEY (`info_id`));
INSERT INTO cultivate_tb VALUES(101,1,'course1,course2');
INSERT INTO cultivate_tb VALUES(102,2,'course2');
INSERT INTO cultivate_tb VALUES(103,3,'course1,course3');
INSERT INTO cultivate_tb VALUES(104,4,'course1,course2,course3');
INSERT INTO cultivate_tb VALUES(105,5,'course3');
INSERT INTO cultivate_tb VALUES(106,6,NULL);
INSERT INTO cultivate_tb VALUES(107,7,'course1,course2');
复制输出:
staff_nums
111.2 思路:
注意到字符串长度即可。
1.3 题解 :
with tep1 as (
-- 抓住本质,直接判断字符串长度就行
select case length(course) when 7 then 1
when 15 then 2
else 3
end cnt
from cultivate_tb
where course is not null
)
select sum(cnt) staff_nums
from tep12. 牛客大厂笔试真题SQLW7:查询培训指定课程的员工信息
2.1 题目:
描述
某公司员工信息数据及员工培训信息数据如下:
员工信息表staff_tb(staff_id-员工id,staff_name-员工姓名,staff_gender-员工性别,post-员工岗位类别,department-员工所在部门),如下所示:
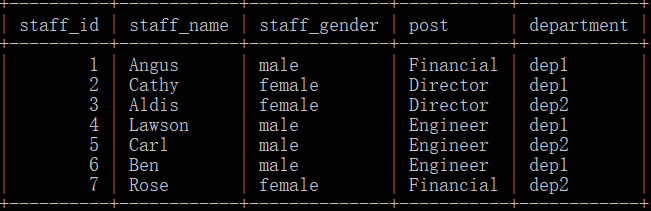
员工培训信息表cultivate_tb(info_id-信息id,staff_id-员工id,course-培训课程),如下所示:
注:该公司共开设了三门课程,员工可自愿原则性培训0-3项;
问题:请查询培训课程course3的员工信息?
注:只要培训的课程中包含course3课程就计入结果
要求输出:员工id、姓名,按照员工id升序排序;
示例数据结果如下:

解释:有员工3、4、5培训了course3课程,故结果如上
示例1
输入:
drop table if exists `staff_tb` ;
CREATE TABLE `staff_tb` (
`staff_id` int(11) NOT NULL,
`staff_name` varchar(16) NOT NULL,
`staff_gender` char(8) NOT NULL,
`post` varchar(11) NOT NULL,
`department` varchar(16) NOT NULL,
PRIMARY KEY (`staff_id`));
INSERT INTO staff_tb VALUES(1,'Angus','male','Financial','dep1');
INSERT INTO staff_tb VALUES(2,'Cathy','female','Director','dep1');
INSERT INTO staff_tb VALUES(3,'Aldis','female','Director','dep2');
INSERT INTO staff_tb VALUES(4,'Lawson','male','Engineer','dep1');
INSERT INTO staff_tb VALUES(5,'Carl','male','Engineer','dep2');
INSERT INTO staff_tb VALUES(6,'Ben','male','Engineer','dep1');
INSERT INTO staff_tb VALUES(7,'Rose','female','Financial','dep2');
drop table if exists `cultivate_tb` ;
CREATE TABLE `cultivate_tb` (
`info_id` int(11) NOT NULL,
`staff_id` int(11) NOT NULL,
`course` varchar(32) NULL,
PRIMARY KEY (`info_id`));
INSERT INTO cultivate_tb VALUES(101,1,'course1,course2');
INSERT INTO cultivate_tb VALUES(102,2,'course2');
INSERT INTO cultivate_tb VALUES(103,3,'course1,course3');
INSERT INTO cultivate_tb VALUES(104,4,'course1,course2,course3');
INSERT INTO cultivate_tb VALUES(105,5,'course3');
INSERT INTO cultivate_tb VALUES(106,6,NULL);
INSERT INTO cultivate_tb VALUES(107,7,'course1,course2');
复制输出:
staff_id|staff_name
3|Aldis
4|Lawson
5|Carl2.2 思路:
如果course字段的值存在3 的话,就替换掉3.然后与原来记录比较。发生变化的就是存在3 的记录。
2.3 题解:
with
tep1 as (
-- 如果course字段存在3,则将3替换为其数字
select
staff_id,
replace (course, '3', '0') replace_cou
from
cultivate_tb
where
course is not null
),
tep2 as (
-- 自连接,如果id相同的记录的course却不相同,则即含有3
select
t1.staff_id
from
tep1 t1
join cultivate_tb t2 on t1.staff_id = t2.staff_id
and replace_cou <> course
)
-- 然后再表内连接即可
select t1.staff_id, staff_name
from tep2 t1
join staff_tb t2
on t1.staff_id = t2.staff_id3. 牛客大厂笔试真题SQLW8:推荐内容准确的用户平均评分
3.1 题目:
描述
某产品2022年2月8日系统推荐内容给部分用户的数据,以及用户信息和对推荐内容的评分交叉表部分数据如下:
推荐内容表recommend_tb(rec_id-推荐信息id,rec_info_l-推荐信息标签,rec_use-推荐目标用户id,rec_time-推荐时间),如下所示:
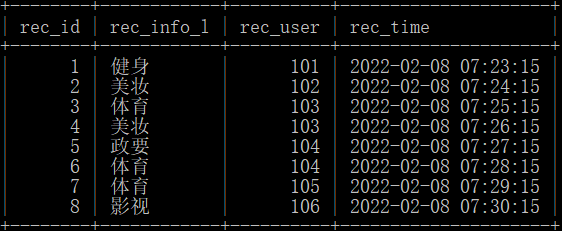
用户信息及评分交叉表user_action_tb(user_id-用户id,hobby_l-用户喜好标签,score-综合评分),如下所示:
注:该表score为对所有推荐给该用户的内容的综合评分,在计算用户平均评分切勿将推荐次数作为分母

问题:请统计推荐内容准确的用户平均评分?(结果保留3位小数)
注:(1)准确定义:推荐的内容标签与用户喜好标签一致;如推荐多次给同一用户,有一次及以上准确就归为准确。
示例数据结果如下:
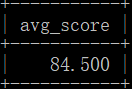
解释:一共推荐8条内容,其中推荐给101、103、105、106四位用户的内容准确,
四位用户的评分分别是88、78、90、82,故平均评分=(88+78+90+82)/4=84.500
示例1
输入:
drop table if exists `recommend_tb` ;
CREATE TABLE `recommend_tb` (
`rec_id` int(11) NOT NULL,
`rec_info_l` varchar(8) NOT NULL,
`rec_user` int(11) NOT NULL,
`rec_time` datetime NOT NULL,
PRIMARY KEY (`rec_id`));
INSERT INTO recommend_tb VALUES(1,'健身',101,'2022-02-08 07:23:15');
INSERT INTO recommend_tb VALUES(2,'美妆',102,'2022-02-08 07:24:15');
INSERT INTO recommend_tb VALUES(3,'体育',103,'2022-02-08 07:25:15');
INSERT INTO recommend_tb VALUES(4,'美妆',103,'2022-02-08 07:26:15');
INSERT INTO recommend_tb VALUES(5,'政要',104,'2022-02-08 07:27:15');
INSERT INTO recommend_tb VALUES(6,'体育',104,'2022-02-08 07:28:15');
INSERT INTO recommend_tb VALUES(7,'体育',105,'2022-02-08 07:29:15');
INSERT INTO recommend_tb VALUES(8,'影视',106,'2022-02-08 07:30:15');
drop table if exists `user_action_tb` ;
CREATE TABLE `user_action_tb` (
`user_id` int(11) NOT NULL,
`hobby_l` varchar(8) NOT NULL,
`score` int(11) NOT NULL,
PRIMARY KEY (`user_id`));
INSERT INTO user_action_tb VALUES(101,'健身',88);
INSERT INTO user_action_tb VALUES(102,'影视',81);
INSERT INTO user_action_tb VALUES(103,'美妆',78);
INSERT INTO user_action_tb VALUES(104,'健身',68);
INSERT INTO user_action_tb VALUES(105,'体育',90);
INSERT INTO user_action_tb VALUES(106,'影视',82);
复制输出:
84.5003.2 思路:
注意到需要distinct这种情况。
3.3 题解:
with tep1 as (
-- 啥啊,咋还出现了一样的记录,非要distinct去重一下。
select distinct score
from recommend_tb t1
join user_action_tb t2
on t1.rec_info_l = t2.hobby_l
and
t1.rec_user = t2.user_id
)
select round(avg(score), 3)
from tep14. 附赠力扣hard题601:体育馆的人流量
4.1 题目:
表:Stadium
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | visit_date | date | | people | int | +---------------+---------+ visit_date 是该表中具有唯一值的列。 每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people) 每天只有一行记录,日期随着 id 的增加而增加
编写解决方案找出每行的人数大于或等于 100 且 id 连续的三行或更多行记录。
返回按 visit_date 升序排列 的结果表。
查询结果格式如下所示。
示例 1:
输入:
Stadium 表:
+------+------------+-----------+
| id | visit_date | people |
+------+------------+-----------+
| 1 | 2017-01-01 | 10 |
| 2 | 2017-01-02 | 109 |
| 3 | 2017-01-03 | 150 |
| 4 | 2017-01-04 | 99 |
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-09 | 188 |
+------+------------+-----------+
输出:
+------+------------+-----------+
| id | visit_date | people |
+------+------------+-----------+
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-09 | 188 |
+------+------------+-----------+
解释:
id 为 5、6、7、8 的四行 id 连续,并且每行都有 >= 100 的人数记录。
请注意,即使第 7 行和第 8 行的 visit_date 不是连续的,输出也应当包含第 8 行,因为我们只需要考虑 id 连续的记录。
不输出 id 为 2 和 3 的行,因为至少需要三条 id 连续的记录。4.2 思路:
公式:遇到连续几行的问题 => 直接使用自连接+between and + group by + having => 直接梭哈。
4.3 题解:
with tep1 as (
select t1.id id1, t1.id+1 id2, t1.id+2 id3
from Stadium t1
join Stadium t2
on (t2.id - t1.id) between 0 and 2
and t2.people >= 100
group by t1.id
having count(*) = 3
), tep2 as (
select id1 id
from tep1
union
select id2 id
from tep1
union
select id3 id
from tep1
)
select t1.id, visit_date, people
from tep2 t1
join Stadium t2
on t1.id = t2.id
order by visit_date