知乎:车中草同学(已授权)
链接:https://zhuanlan.zhihu.com/p/987727357
引言
在BERT时代,对于Reranker任务,我们使用encoder-only的BERT为基座,拼接query和doc输入到BERT中去,在使用CLS的向量通过一个MLP,得到得分来做Reranker任务。
在LLM出来之后,一个很自然的想法是,我们能否使用decoder-only的LLM来作为Reranker任务的基座。
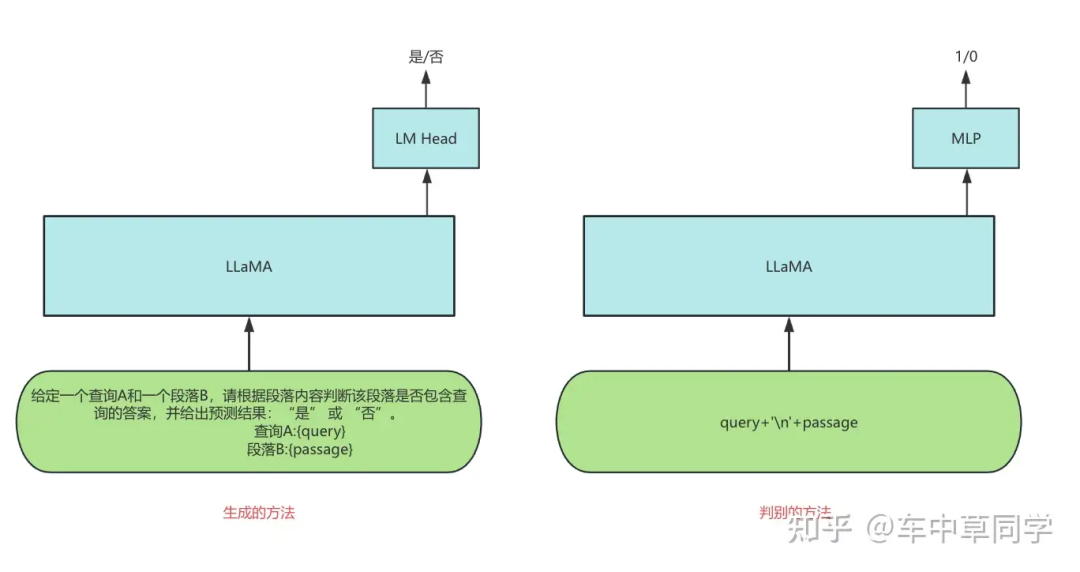
本篇实验报告中,在有监督微调的场景下,如下图所示,笔者探索了以下两种使用LLM做Reranker任务的方法。并且与BERT类模型做比较。
生成的方法:直接用生成的方法去做,输入query和doc,直接让大模型预测相关(是)和不相关(否)。
判别的方法:和传统的BERT一样,在大模型后面增加一个MLP层,来得到score。一般是:让llm的last_hidden_state通过MLP层去得到一个score。
本篇实验报告试图回答这几个问题 ?
在reranker任务上使用llm,是否比bert类模型有优势?
两种使用LLM做Reranker任务的方法,哪种效果最好?
如果LLM做Reranker任务的方法效果比bert好,那么是否可以蒸馏这种信号到bert中?
注意:本篇实验报告所有的代码均在本人维护的RAG-Retrieval仓库中提供,欢迎大家给个star。
https://github.com/NLPJCL/RAG-Retrieval
RAG-Retrieval 提供了全链路的RAG检索微调(train)和推理(infer)代码。
对于微调,支持微调任意开源的RAG检索模型,包括向量(embedding)、迟交互式模型(colbert)、排序模型(bert,llm)。
对于推理,RAG-Retrieval专注于排序(reranker),开发了一个轻量级的python库rag-retrieval,提供统一的方式调用任意不同的RAG排序模型。
对于蒸馏,支持将基于LLM的reranker模型,蒸馏到基于bert的reranker中。
方法
在讲具体的方法前,我们首先回顾下LLM的基座可能比BERT作为基座的好处是:
模型参数一般比较多:一般认为,模型参数量越多,在相同的数据训练下,其能力越强。bert-base一般就110M,约1.15亿参数(0.115b),而开源的LLM比这大的多。(0.5b,1.5b,72b)
预训练阶段见到的数据多:LLM一般比BERT在预训练阶段见过的数据多。并且decoder-only模型从所有的输入信息中学习,而不只是像bert一样,只从mask的部分学习。(15%)。
输入长度更长和多语言支持。
LLM做Reranker基座的两种方式
这里介绍下在有监督场景下,decoder-only的LLM来作为Reranker任务的基座的两种不同的方式。
生成的方法:直接用生成的方法去做,输入promot和query和doc,直接让大模型预测相关(是)和不相关(否)。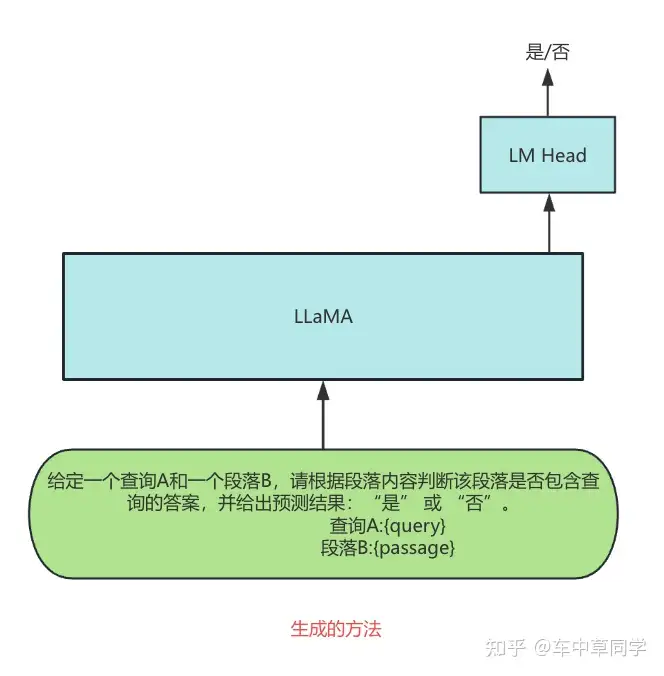
这种方法是把reranker任务当做SFT任务的一种子任务。
LLM本身就有zero-shot的排序能力,直接上,这种方法,可以与LLM在预训练,SFT等阶段积累的能力对齐,充分利用LLM的潜力。
训练的loss:本质上是采用交叉熵loss,原本生成任务是固定的词表(qwen是25w)预测要生成词的概率,而该种方法,还是从词表中预测,不过只有一个词,并且生成的词只可能是:"是"和"否"。
判别的方法:和传统的BERT一样,在大模型后面增加一个MLP层,来得到score。一般是:让llm的last_hidden_state通过MLP层去得到一个score。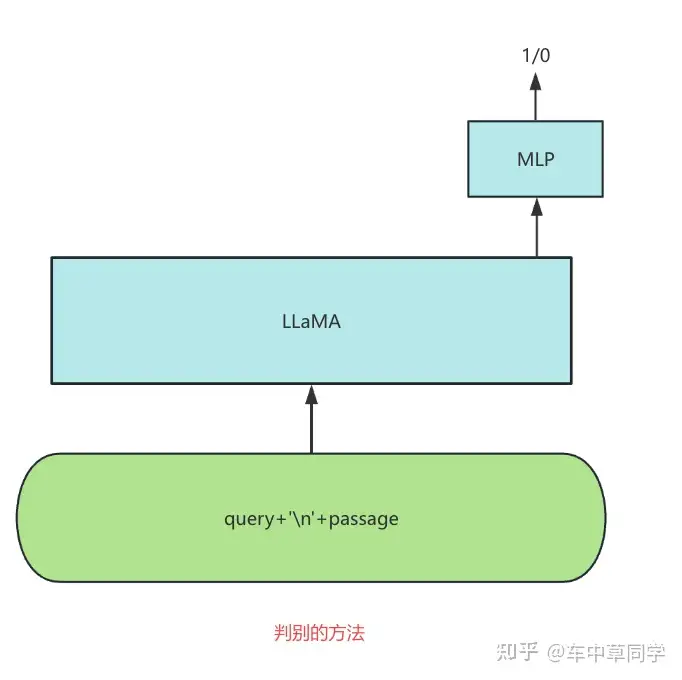
这种方法把reranker任务建模成一个判别任务,只利用LLM的基座,来得到query和passage上下文的表示,再通过一个MLP来做二分类。
对比直接把reranker任务建模成生成任务,这种方法只是将LLM作为编码层,而在解码层,需要完全从零训练一个随机的MLP层,并没有特别和LLM预训练和SFT阶段对齐。
训练的loss:使用BCEWithLogitsLoss loss。
蒸馏到BERT中的方法
我们使用蒸馏logits 的方法,来将大模型的能力蒸馏到bert中来。
构造训练数据:
具体来说,不管我们使用LLM做Reranker任务的,生成方法还是判别方法,都可以得到一个logits。
对于判别方法:因为其用BCEWithLogitsLoss,那么本身其MLP的输出加上一个Sigmoid就是一个0-1之间的score。
对于生成方法:我们取出softmax后的概率值。然后取出"是"的概率,作为query和doc的相关性得分。(预测为1的相关性得分,且在0-1之间)
蒸馏方法:
1.我们将蒸馏任务建模成一个回归任务,用mse loss来学习logits。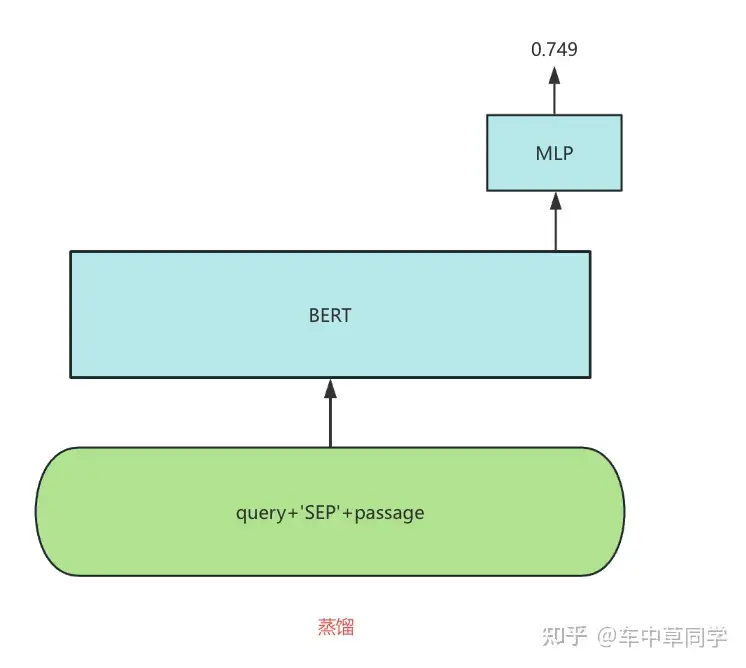
实验
实验设置
训练数据:我们使用T2-Reranking(搜狗和清华开源的搜索引擎段落排序数据集)的训练集共187502个query和对应的正例,并提前挖掘为每个query挖掘了15个难负例。
测试数据:C-MTEB中的T2-Reranking的测试集。
训练细节:
基座模型:对于BERT的基座,我们使用hfl/chinese-roberta-wwm-ext;对于LLM的基座,我们使用Qwen/Qwen2-1.5B-Instruct
实验细节:我们都使用了5e-5的学习率,并且设置batch_size为96,采用BCE loss来训练模型,共训练了2个epoch。
训练框架:
对于LLM做reranker任务:
对于生成方法:本篇文章使用LLaMA-Factory。
https://github.com/NLPJCL/LLaMA-Factory
对于判别方法:本篇文章使用RAG-Retrieval。
https://github.com/NLPJCL/RAG-Retrieval
训练代码:
https://github.com/NLPJCL/RAG-Retrieval/tree/master/rag_retrieval/train/reranker
对于蒸馏:把LLM做reranker任务的能力蒸馏到bert中,文章使用RAG-Retrieval。
https://github.com/NLPJCL/RAG-Retrieval
构造训练数据:
https://github.com/NLPJCL/RAG-Retrieval/tree/master/examples/distill_llm_to_bert
训练蒸馏模型:
https://github.com/NLPJCL/RAG-Retrieval/tree/master/rag_retrieval/train/reranker
实验结果
在实验中,我们首先在reranker数据较少或者难负例较少的情况下做了一些实验。
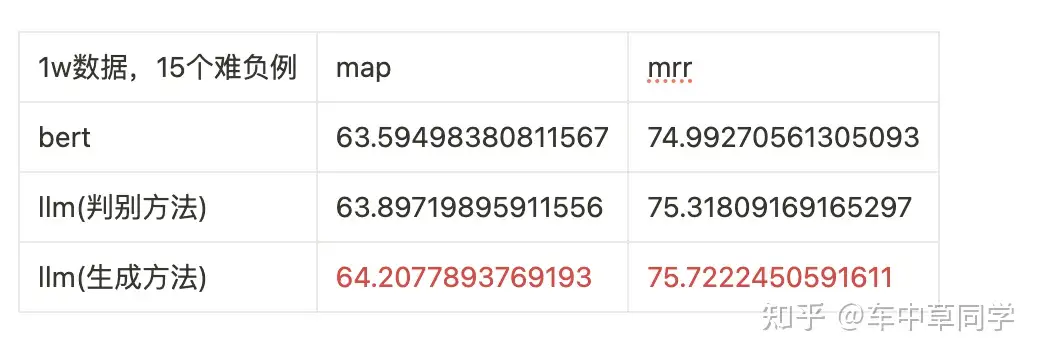
我们使用T2-Reranking 187502训练集中的1w个训练数据,每个训练数据带有15个难负例。
 实验结论:
实验结论:
可以看出,在数据量较少的情况下,两个基于llm的方法都比bert的方法效果好。
其中llm(生成方法)效果最好,在相同的数据情况下,其比bert的方法的map高了0.62,其比llm(判别)方法的map高了0.30。
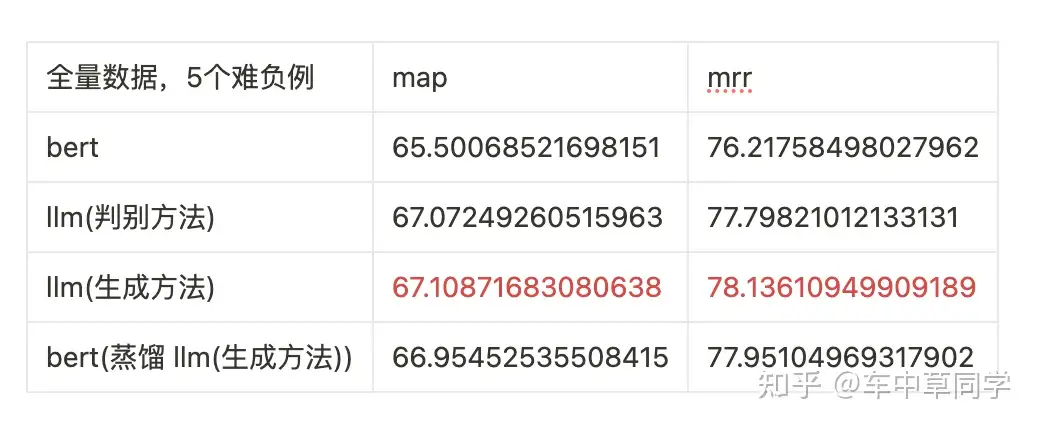
我们使用全量的T2-Reranking 187502训练集,但只使用了5个难负例。
 实验结论:
实验结论:
可以看出,在难负例较少的情况下,bert的结果相比两个基于llm的结果较差,map只有65.50。这说明bert模型的泛化性不如两个基于llm的方法。
两个基于llm的结果相差不大,其中llm(生成方法)效果最好,其比bert的方法的map高了1.61。
蒸馏:在相同数据的前提下,通过将llm(生成方法)蒸馏到bert中来,其效果达到了66.95,比单纯训练bert模型的map高了1.45。
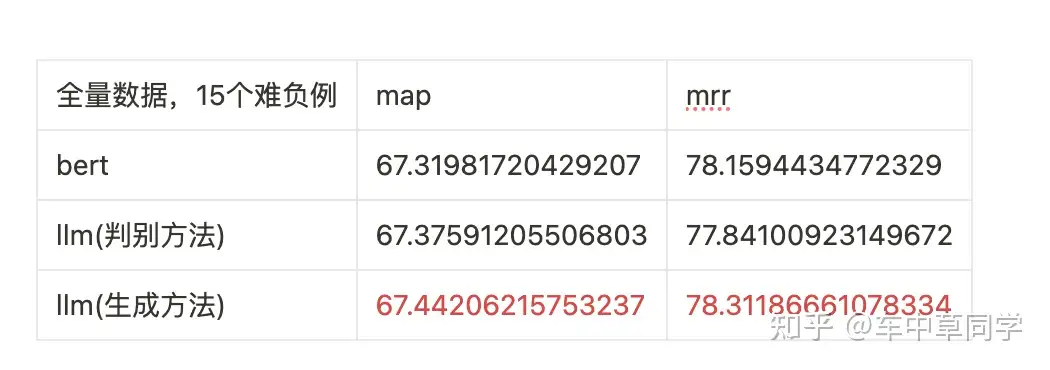
在最终,全量的T2-Reranking 187502训练集,同时使用了15个难负例。
 实验结论:
实验结论:
可以看出,在全量数据,15个难负例的情况下,bert的结果和两个基于llm的方法结果相差不大。
其中其中llm(生成方法)效果最好,其比bert的方法的map高了0.13,比llm(判别方法)高0.06了。
总结
最后,我们来回答下开头的三个提问:
在reranker任务上使用llm,是否比bert类模型有优势?
在训练数据量较少或者难负例较少的情况下,两者llm的方法相比bert都有较大的优势。但在数据充足(训练数据足够,难负例足够)的情况下,这种优势会被减弱。两种使用LLM做Reranker任务的方法,哪种效果最好?
llm(判别方法)和llm(生成方法)没有较大的差距,但始终是llm(生成方法)效果更好一点,可能是因为其更好的和llm在训练过程中的训练目标对齐了。如果LLM做Reranker任务的方法效果比bert好,那么是否可以蒸馏这种信号到bert中?
在数据量较少或者难负例较少的情况下,在相同的训练数据下,通过先训练llm(生成方法),再蒸馏到bert中,这样可以兼顾效果和效率。对于效果,蒸馏后的bert模型,可以比单纯只训练bert的map高了1.45,和训练llm(生成方法)只差了0.16。
最佳实践建议
我们建议:
如果您的数据较为充足(且没有利用大模型的两个特性的需求:输入更长,多语言支持),那么可以直接训练bert模型来做reranker任务,那么其可以在效果不错的前提下兼顾高效推理。
如果您的数据较少或者需要输入更长,多语言支持,那么请优先选择已llm为基座的两种方法,且优先选择llm(生成)的方法。如果您考虑推理效率,那么可以再将其蒸馏到BERT中去。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦