写在前面
🔥我把后端Java面试题做了一个汇总,有兴趣大家可以看看!这里👉
⭐️在无数次的复习巩固中,我逐渐意识到一个问题:面对同样的面试题目,不同的资料来源往往给出了五花八门的解释,这不仅增加了学习的难度,还容易导致概念上的混淆。特别是当这些信息来自不同博主的文章或是视频教程时,它们之间可能存在的差异性使得原本清晰的概念变得模糊不清。更糟糕的是,许多总结性的面试经验谈要么过于繁复难以记忆,要么就是过于简略,对关键知识点一带而过,常常在提及某项技术时,又引出了更多未经解释的相关术语和实例,例如,在讨论ReentrantLock时,经常会提到这是一个可重入锁,并存在公平与非公平两种实现方式,但对于这两种锁机制背后的原理以及使用场景往往语焉不详。
⭐️正是基于这样的困扰与思考,我决定亲自上阵,撰写一份与众不同的面试指南。这份指南不仅仅是对现有资源的简单汇总,更重要的是,它融入了我的个人理解和解读。我力求回归技术书籍本身,以一种层层递进的方式剖析复杂的技术概念,让那些看似枯燥乏味的知识点变得生动起来,并在我的脑海中构建起一套完整的知识体系。我希望通过这种方式,不仅能帮助自己在未来的技术面试中更加从容不迫,也能为同行们提供一份有价值的参考资料,使大家都能在这个过程中有所收获。
消息中间件相关面试题
面试官:消息队列的两种模式?
候选人:(摘自《Java程序员面试笔试宝典》第二版 10.1 节)
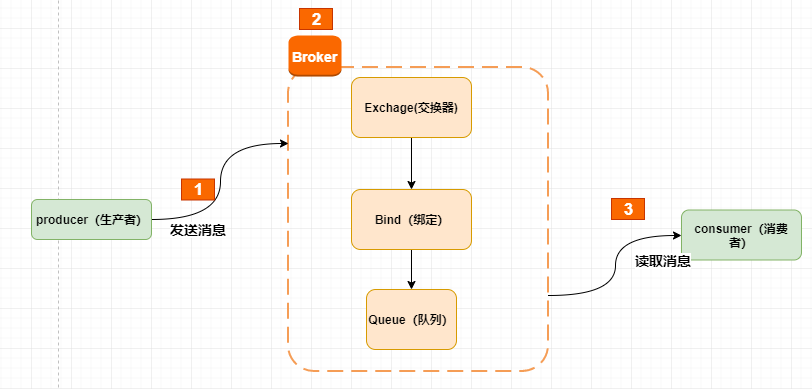
对于消息中间件而言,一般有两种消息投递模式:点对点(P2P,Point-to-Point)模式和发布/订阅(Pub/Sub)模式。
-
点对点模式是基于队列的,一个消息只能被一个消费者消费。当一个消费者消费了队列中的某条数据之后,这条数据就会从队列中删除。

-
发布/订阅模式,生产者生成的数据会被持久化到一个 Topic 中。与点对点消息系统不同的是,消费者可以订阅一个或多个 Topic,消费者可以消费该 Topic 中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立即删除。发布者发送到 Topic 的消息,只有订阅了 Topic 的订阅者才会收到消息。

面试官:RabbitMQ是如何保证消息不丢失
候选人:
RabbitMQ要保证消息的不丢失,主要从三个层面考虑:
-
开启生产者确认机制,确保生产者的消息能到达队列,如果报错可以先记录到日志中,再去修复数据
-
开启持久化功能,确保消息未消费前在队列中不会丢失,其中的交换机、队列、和消息都要做持久化
-
开启消费者确认机制为Auto。当然也需要设置一定的重试次数,我们当时设置了3次,如果重试3次还没有收到消息,就将失败后的消息投递到异常交换机,交由人工处理
面试官:RabbitMQ消息的重复消费问题如何解决的?
候选人:
如果使用自动确认机制,当消费者在处理消息时,服务宕机了,RabbitMQ 可能仍会将该消息视为已消费并将其从队列中移除。下次消费者重启时,可能会再次接收到同一消息。
解决 RabbitMQ 消息重复消费的问题通常可以采用以下几种策略:
- 幂等性设计:确保消息处理操作是幂等的,即多次处理同一消息不会导致不同的结果。例如,使用唯一标识符来确保相同的操作不会被重复执行。
- 消息去重:在消费消息时,首先检查数据库或缓存中是否已存在该消息的唯一标识。如果存在,说明消息已被处理,直接返回;如果不存在,则处理该消息并记录标识。
- 使用事务:在处理消息时,可以将操作放入事务中,确保操作的原子性。如果事务失败,则不确认消息,允许重新消费。
- 死信队列:将处理失败的消息放入死信队列进行后续处理,这样可以避免直接重试导致的重复消费。
通过这些策略,可以有效地减少和处理 RabbitMQ 消息的重复消费问题。
面试官:RabbitMQ中死信交换机 ? (RabbitMQ延迟队列有了解过嘛)
候选人:
在 RabbitMQ 中,延迟队列通常通过结合死信交换机(DLX)和消息存活时间(TTL)来实现。当消息超过设定的 TTL 还未被消费时,它们会被转发到绑定的死信交换机。在死信交换机上,可以将这些消息路由到其他队列,从而实现延迟消费的效果。
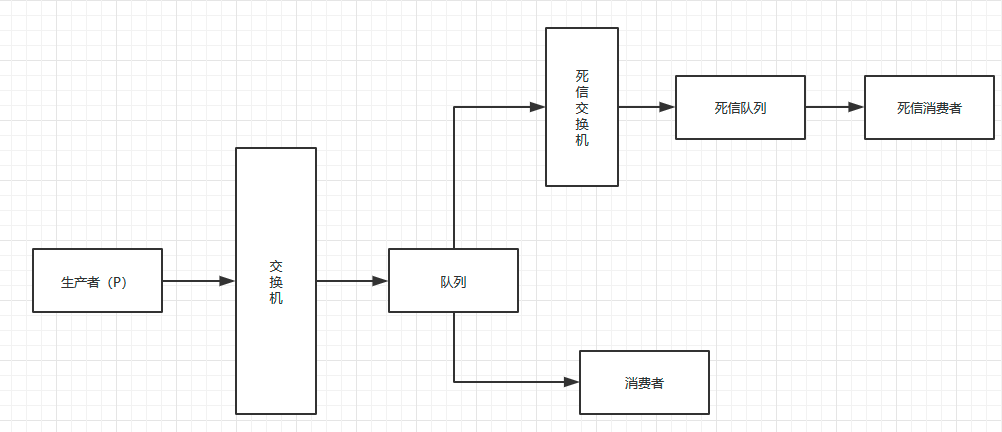
另外,RabbitMQ 还提供了插件来简化这一过程。通过安装死信插件(确保在 pom.xml 中添加 RabbitMQ 的依赖),用户在声明交换机时只需指定为死信交换机,并在发送消息时直接设置超时时间。这种方式省略了一些步骤,使得配置更为便捷,同时也降低了出错的可能性。
面试官:如果有100万消息堆积在MQ , 如何解决 ?
候选人:
当面临消息堆积的问题时,可以采取多种解决方案:
-
提高消费者的消费能力:使用多线程或异步处理来提升单个消费者的处理速度,从而加快消息消费的效率。
-
增加更多消费者:采用工作队列模式,设置多个消费者同时消费同一个队列中的消息,以提高整体消费速度。
-
扩大队列容积:增加队列的堆积上限,以允许更多的消息存储在队列中,避免因短时间内的高流量导致消息丢失。
-
使用惰性队列:通过 RabbitMQ 的惰性队列特性来优化消息存储:
- 直接存储到磁盘:接收到的消息会直接存入磁盘,而不是保存在内存中,减轻内存压力。
- 按需加载:只有当消费者需要消费消息时,消息才会从磁盘中读取并加载到内存中。
- 支持大规模存储:能够支持数百万条消息的存储,适合高并发场景。
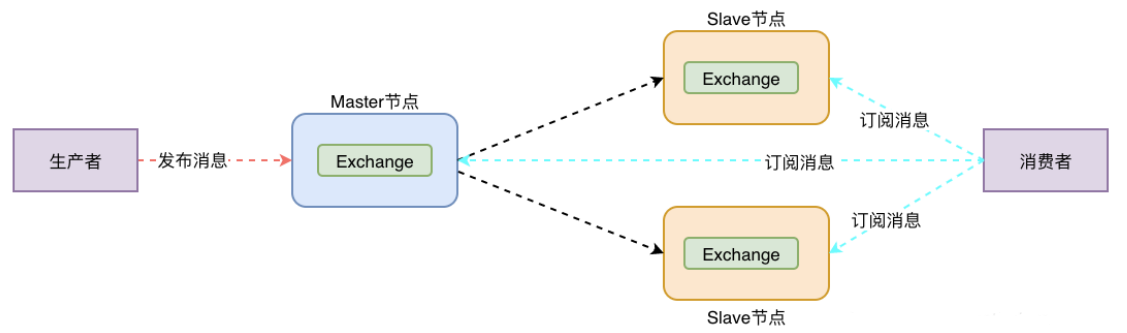
面试官:RabbitMQ 的高可用机制有了解过吗?
候选人:
使用 RabbitMQ 的集群模式,具体实现为镜像模式集群,可以搭建三台机器:
在镜像队列结构中,采用 “一主多从” 的配置,所有的操作由主节点完成,并同步到镜像节点。这种方式可以确保在主节点出现故障时,镜像节点可以迅速接管,成为新的主节点。
然而,在主节点宕机后,如果镜像节点在数据同步完成之前发生故障,可能会导致数据丢失。
面试官:那出现丢失数据怎么解决呢?
候选人:
在 RabbitMQ 中,我们可以采用 仲裁队列(Quorum Queues) 来解决数据丢失问题。与镜像队列类似,它们都基于主从模式并支持数据同步,但仲裁队列的实现更为先进。
仲裁队列的特点:
-
数据同步:仲裁队列使用 Raft 协议进行主从数据同步,确保数据的一致性和可靠性。
-
强一致性:与镜像队列相比,仲裁队列提供了强一致性保证。所有的消息在被确认之前,必须被大多数节点接收到,从而避免了因网络分区导致的数据不一致。
-
简单易用:仲裁队列的使用非常简单,无需复杂的配置。在声明队列时,只需指定该队列为仲裁队列即可。例如,可以通过设置参数来实现:
Map<String, Object> args = new HashMap<>(); args.put("x-queue-type", "quorum"); channel.queueDeclare("my_quorum_queue", true, false, false, args); -
适用于高负载场景:仲裁队列特别适合需要高可用性和高一致性的应用场景,例如金融系统和电商平台。在这些场景中,确保消息的可靠处理至关重要。
面试官: Kafka 是什么?主要应⽤场景有哪些?
候选人:(摘自《深入理解Kafka核心设计与实践原理》 1.1 节)
Kafka 起初是由 LinkedIn 公司采用 Scala 语言开发的一个多分区、多副本且基于 ZooKeeper协调的分布式消息系统,现已被捐献给 Apache 基金会。目前 Kafka 已经定位为一个分布式流式处理平台,它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用。
Katka 之所以受到越来越多的青睐、与它所“扮演”的三大角色是分不开的:
- 消息系统:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
- 存储系统:Kafka 会把消息持久化到磁盘,有效避免了消息丢失的⻛险。
- 流式处理平台:在消息发布的时候进⾏处理,Kafka 提供了⼀个完整的流式处理类库。
Kafka 主要有两⼤应⽤场景:
- 消息队列 :建⽴实时流数据管道,以可靠地在系统或应⽤程序之间获取数据。
- 数据处理: 构建实时的流数据处理程序来转换或处理数据流。
面试官:Kafka中有哪些组件?
候选人:(摘自《Java程序员面试笔试宝典》第二版 10.2 节)
Kafka 有很多重要的组件,下面将一一介绍它们的功能以及它们之间的关系。
1)Producer:消息生产者,发布消息到 Kafka 集群的终端或服务。
2)Broker:一个Kafka 结点就是一个 Broker,多个 Broker 可组成一个 Kafka 集群。Broker 用来存储 Topic 的数据。
3)Topic:消息主题,每条发布到 Kafka集群的消息属于的类别,即 Kafka 是面向 Topic 的。
4)Partition:Partition 是Topic 在物理上的分区,一个 Topic 可以分为多个 Partition,每个Partition 是一个有序的不可变的记录序列。分区中的每个记录都分配了一个被称为 offset 的顺序 ID 号,它唯一地标识分区中的每个记录。单一主题中的分区有序,但是无法保证主题中所有的分区有序。
5)Consumer:从 Kafka 集群中消费消息的终端或服务。
6)Consumer Group:每个 Consumer 都属于一个 ConsumeGroup,每条消息只能被 Consumer Group 中的一个Consumer 消费,但可以被多个 Consumer Group消费。
7)Replica:Partition 的副本,用来保障 Partition 的高可用性。
8)Leader:Replica 中的一个角色, Producer 和 Consumer 只跟 Leader 交互。
9)Follower:Replica 中的一个角色,从 Leader 中复制数据。如果 Leader 失效,则从 Follower 中选举出一个新的 Leader。当 Follower 与 Leader 均失效、卡住或者同步太慢,Leader 会把这个Follower 从 ISR 列表中删除,重新创建一个 Follower。
10)Zookeeper:Kafka 通过 Zookeeper 来存储集群的 meta 信息。
Zookeeper在Kafka中的作用:Kafka的各Broken在启动时都要在Zookeeper注册,由Zookeeper统一协调管理。同一个Topic的消息会被分成多个分区并将其分布在多个Broken上,这些分区信息及与Broken的对应关系也是Zookeeper在维护。
11)Offset:Kafka 的存储文件都是按照 offset.kafka 来命名,用 Offset 做名字的好处是方便查找。


面试官:Kafka是如何保证消息不丢失
候选人:
嗯,这个保证机制很多,在发送消息到消费者接收消息,在每个阶段都有可能会丢失消息,所以我们解决的话也是从多个方面考虑:

第一个是生产者发送消息的时候,可以使用异步回调发送,如果消息发送失败,我们可以通过回调获取失败后的消息信息,可以考虑重试或记录日志,后边再做补偿都是可以的。
第二个在broker中消息有可能会丢失,我们可以通过kafka的复制机制来确保消息不丢失,在生产者发送消息的时候,可以设置确认机制,设置参数为all(acks=all)。这样的话,当生产者发送消息到了分区之后,不仅仅只在leader分区保存确认,在follwer分区也会保存确认,只有当所有的副本都保存确认以后才算是成功发送了消息,所以,这样设置就很大程度了保证了消息不会在broker丢失。
当 Producer 向 leader 发送数据时,可以通过
request.required.acks参数来设置数据可靠性的级别。
- acks=0,Producer 不等待来自 Broker 同步完成的确认就继续发送下一条(批)消息。提供最低的延迟但最弱的耐久性保证,因为其没有任何确认机制。acks值为0会得到最大的系统吞吐量。
- acks=1,Producer 在Leader 已成功收到的数据并得到确认后发送下一条消息。等待 Leader 的确认后就返回,而不管 Partition 的 Follower 是否已经完成。
- acks=-1 / all,Producer 在所有 Follower 副本确认接收到数据后才算一次发送完成。此选项提供最好的数据可靠性,只要有一个同步副本存活,Kafka保证信息将不会丢失。
第三个有可能是在消费者端丢失消息,kafka消费消息都是按照offset进行标记消费的,消费者默认是自动按期提交已经消费的偏移量,默认是每隔5s提交一次,如果出现重平衡的情况,可能会重复消费或丢失数据。我们一般都会禁用掉自动提交偏移量,改为手动提交,当消费成功以后再报告给broker消费的位置,这样就可以避免消息丢失和重复消费了。
面试官:Kafka中消息的重复消费问题如何解决的
候选人:
kafka消费消息都是按照offset进行标记消费的,消费者默认是自动按期提交已经消费的偏移量,默认是每隔5s提交一次,如果出现重平衡的情况,可能会重复消费或丢失数据。
解决方法:
-
我们一般都会禁用掉自动提交偏移量,改为手动提交,当消费成功以后再报告给broker消费的位置,这样就可以避免消息丢失和重复消费了
-
为了消息的幂等性,我们也可以设置PID和序列号来进行区分,或者是加锁,数据库的锁,或者是redis分布式锁,都能解决幂等的问题。但是Kafka的幂等只能保证单个生产者会话(session)中单分区的幂等,不能保证topic的幂等。
面试官:Kafka是如何保证消费的顺序性
候选人:
kafka默认存储和消费消息,是不能保证顺序性的,因为一个主题(topic)数据可能存储在不同的分区中,每个分区都有一个按照顺序的存储的偏移量,如果消费者关联了多个分区不能保证顺序性。Kafka 只能为我们保证Partition(分区) 中的消息有序,⽽不能保证 Topic(主题) 中的 Partition(分区) 的有序。
如果有这样的需求的话,我们是可以解决的,把消息都存储同一个分区下就行了,有两种方式都可以进行设置:
- 第一个是发送消息时指定分区号。
- 第二个是发送消息时按照相同的业务设置相同的key。因为默认情况下分区也是通过key的hashcode值来选择分区的,hash值如果一样的话,分区肯定也是一样的。
面试官:Kafka的高可用机制有了解过嘛
候选人:
嗯,主要是有两个层面,第一个是集群,第二个是提供了多副本机制。
kafka集群指的是由多个broker实例组成,即使某一台宕机,也不耽误其他broker继续对外提供服务。
多副本机制是可以保证kafka的高可用的,一个主题有多个分区,每个分区有多个副本,有一个leader,其余的是follower,副本存储在不同的broker中;所有的分区副本的内容是都是相同的,如果leader发生故障时,会自动将其中一个follower提升为leader,保证了系统的容错性、高可用性
拓展:(摘自《深入理解Kafka核心设计与实践原理》 1.1 节)
AR = ISR + OSR
分区中的所有副本统称为AR(Assigned Replicas)。所有与leader 副本保持一定程度同步的副本(包括leader 副本在内)组成ISR(In-Sync Replicas),ISR 集合是 AR 集合中的一个子集。消息会先发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步,同步期间内 follower 副本相对于 leader 副本而言会有一定程度的滞后。前面所说的“一定程度的同步”是指可忍受的滞后范围,这个范围可以通过参数进行配置。与 leader 副本同步滞后过多的副本(不包括leader 副本)组成OSR(Out-of-SyncReplicas),由此可见,AR=ISR+OSR。在正常情况下,所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即 AR=ISR,OSR 集合为空。
面试官:解释一下复制机制中的ISR(多副本机制)
候选人:
在Kafka中,ISR是指一组与Leader副本同步的Follower副本。只有在ISR中的副本才能保证数据的安全和一致性。在每个分区中,存在一个Leader和多个Follower副本。只有Leader副本负责处理所有的写入和读取请求,而Follower只负责与Leader副本的消息同步。
-
数据一致性:只有当所有ISR中的副本都确认接收到消息后,Leader才会将该消息视为已提交,这样可以防止数据丢失。
-
故障恢复:在Leader发生故障时,ISR中的副本可以被选举为新的Leader,确保系统的高可用性。
面试官:Kafka数据清理机制了解过嘛
候选人:
Kafka中topic的数据存储在分区上,分区如果文件过大会分段存储segment
每个分段都在磁盘上以 索引(xxxx.index)和日志文件(xxxx.log) 的形式存储,这样分段的好处是,第一能够减少单个文件内容的大小,查找数据方便,第二方便kafka进行日志清理。
在kafka中提供了两个日志的清理策略(删除和压缩):
第一,根据消息的保留时间,当消息保存的时间超过了指定的时间,就会触发清理,默认是168小时(7天)
第二是根据topic存储的数据大小,当topic所占的日志文件大小大于一定的阈值,则开始删除最久的消息。这个默认是关闭的
这两个策略都可以通过kafka的broker中的配置文件进行设置。
面试官:Kafka中实现高性能的设计有了解过嘛
候选人:
Kafka 高性能,是多方面协同的结果,包括宏观架构、分布式存储、ISR 数据同步、以及高效的利用磁盘、操作系统特性等。主要体现有这么几点:
-
消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
-
顺序读写:磁盘顺序读写,提升读写效率
-
页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问,减少磁盘I/O操作
-
零拷贝:减少内核和用户模式直接的上下文切换及数据拷贝
-
分批发送:将消息打包批量发送,减少网络开销







![C++ [项目] 愤怒的小鸟](https://i-blog.csdnimg.cn/direct/df0e9a84f3764e938d542ea622325491.png)