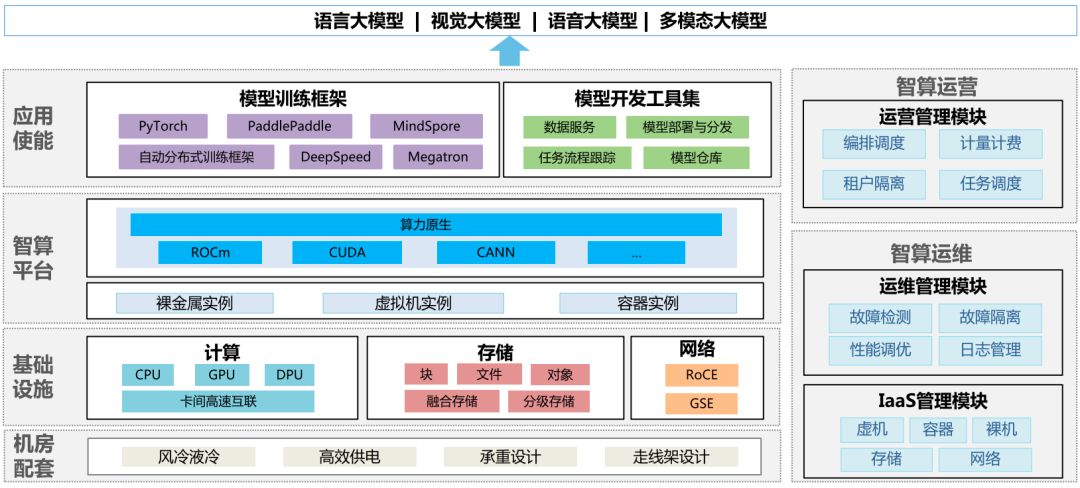
1.定位爬取位置内容:
# -*- coding: utf-8 -*-
import requests
import time
import re
# 请求的 URL 和头信息
url = 'https://bbs.itheima.com/forum-425-1.html'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36',
}
# 发起请求并等待 5 秒
response = requests.get(url, headers=headers)
time.sleep(5)
print(response.text)
# 使用正则表达式提取文章标题,发布时间,文章作者
# 文章标题:(关于Django项目《美多商城》的全部流程(下)--从购物车到部署)</a>]</em> <a href="http://bbs.itheima.com/thread-426625-1-1.html" onclick="atarget(this)" class="s xst">关于Django项目《美多商城》的全部流程(下)--从购物车到部署</a>
# 发布时间:(2018-10-28)<a href="http://bbs.itheima.com/home.php?mod=space&uid=468765" c="1"><span style="margin-left: 0;">python_shenshou</span></a><span style="margin-left: 5px;">@ 2018-10-28</span><span style="margin-left: 18px;padding-left: 16px;background: url(/template/gfquan/src/replygf.jpg) no-repeat 0 0;">
# 文章作者: (python_shenshou)<a href="http://bbs.itheima.com/home.php?mod=space&uid=468765" c="1"><span style="margin-left: 0;">python_shenshou</span></a><span style="margin-left: 5px;">@ 2018-10-28</span>
2.正则匹配提取出需要的内容:
import requests
import re
# 请求的 URL 和头信息
url = 'https://bbs.itheima.com/forum-425-1.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36',
}
# 发起请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
# 使用正则表达式提取文章标题
titles = re.findall(r'class="s xst">([^<]+)</a>', response.text)
# 提取发布时间和作者
details = re.findall(r'<span style="margin-left: 0;">([^<]+)</span></a><span style="margin-left: 5px;">@ ([^<]+)</span>', response.text)
authors = [detail[0] for detail in details]
dates = [detail[1] for detail in details]
# 输出提取的结果
for title, date, author in zip(titles, dates, authors):
print(f"文章标题: {title}")
print(f"发布时间: {date}")
print(f"文章作者: {author}")
print('-' * 40)
else:
print("访问失败", response.status_code)3.定位翻页进行多页爬取:
import requests
import re
def fetch_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36',
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
# 使用正则表达式提取文章标题
titles = re.findall(r'class="s xst">([^<]+)</a>', response.text)
# 提取发布时间和作者
details = re.findall(
r'<span style="margin-left: 0;">([^<]+)</span></a><span style="margin-left: 5px;">@ ([^<]+)</span>',
response.text)
authors = [detail[0] for detail in details]
dates = [detail[1] for detail in details]
# 输出提取的结果
for title, date, author in zip(titles, dates, authors):
print(f"文章标题: {title}")
print(f"发布时间: {date}")
print(f"文章作者: {author}")
print('-' * 40)
# 使用正则表达式提取下一页的链接
next_page_link = re.search(r'下一页', response.text)
if next_page_link:
return next_page_link.group(1) # 返回完整的链接
else:
return None
else:
print("访问失败", response.status_code)
return None
# 初始页面
current_url = 'https://bbs.itheima.com/forum-425-1.html'
# 循环遍历每一页,直到没有下一页
while current_url:
print(f"正在爬取: {current_url}")
next_url = fetch_page(current_url)
current_url = next_url
4.最后爬取结果:

需要注意的地方:其中运用到的正则方法为([^<]+),另一种的正则方法为(.*?),建议第一种,效率更高,但是处理不了'<'字符情况,根据实际情况操作。