文章链接:https://arxiv.org/pdf/2405.15863
代码链接:https://github.com/ivcylc/qa-mdt
Huggingface链接:https://huggingface.co/spaces/jadechoghari/OpenMusic
Demo链接:https://qa-mdt.github.io/ (chatgpt * 30, musiccaps * 30)
亮点直击
-
提出了一种质量感知训练范式,使模型在训练过程中能够感知数据集的质量,从而在音乐性(美学角度)和音频质量方面实现卓越的音乐生成效果。
-
创新性地将masked扩散Transformer引入到音乐信号中,展示了其在建模音乐潜在空间上的独特效果,以及其在质量控制感知方面的卓越能力,从而进一步提升了生成音乐的质量和音乐性。
-
解决了大型音乐数据集中文本与音频低相关性的问题,有效提高了文本对齐度和生成的多样性。
背景
近年来,基于扩散的文本到音乐(TTM)生成方法逐渐受到重视,提供了一种创新的方法,将文本描述合成音乐内容。要在这一生成过程中实现高准确性和多样性,必须依赖大量高质量的数据,包括高保真音频波形和详细的文本描述,但这些通常仅占现有数据集中的一小部分。在开源数据集中,低质量音乐波形、标签错误、弱标签和无标签数据等问题显著阻碍了音乐生成模型的发展。为了解决这些挑战,今天和大家分享一种全新的高质量音乐生成范式,该范式结合了质量感知训练策略,使生成模型能够在训练过程中辨别输入音乐波形的质量。利用音乐信号的独特特性,首先针对TTM任务调整并实现了一个掩码扩散Transformer(MDT)模型,展现出其在质量控制和音乐性增强方面的独特能力。此外,还通过字幕优化数据处理方法解决了TTM中低质量字幕的问题。实验结果表明,在MusicCaps和Song-Describer数据集上取得了当前最先进的(SOTA)性能。
当前音乐生成(音效生成)领域的问题为质量低,具体来说分为三个方面:
-
大部分的开源数据集音质低(FMA,AudioSet,MSD),旋律杂乱
-
音乐性(美学角度)差
-
文本对齐度低,大多数的音频处于少标签,弱标签,错标签。其中, 第1点可以由下图蓝色分布CLAP分数表征,2,3点可以由数据集的平均MOS分布表征(颜色由
 分割)
分割)

创新方法及思路
质量信息注入
解决: 引入质量感知训练策略。采用主观数据集中的MOS分训练出的质量评分模型,在训练过程中注入(伪MOS分)音频质量信息。
两种注入方法:
-
利用 text encoder 对分级后的 low quality, medium quality, high quality 质量文本进行cross attn嵌入 【粗粒度,适配unet架构和transformer类架构】
-
参考U-ViT内 时间信息和label信息的融入方式,以量化(阈值由 决定)后转换为quality embedding, 以token 形式进行控制注入,【细粒度,并且只适配transformer类架构】

结论:质量感知策略允许了在推理阶段以高质量文本和质量token进行引导,从而生成显著高于训练集平均质量的音频。
以类似解耦的方式在训练中感知音频的质量(类似TTS中分离出音色训练),从而更好地促进了模型的训练(大幅降低FAD,KL,并提升IS,REL,CLAP等指标)。
我们还发现,粗粒度文本控制和细粒度token控制相结合,更有助于模型训练中解耦,感知,并控制更高质量音频的生成,从而解决训练数据集影响的问题
质量感知型 masked扩散Transformer
解决:从音乐性建模角度,我们发现 U-ViT/DiT 类架构对频谱隐空间建模也具有图像上表达的scale ability,并能更好建模谐波,音色等方面(反应在主观评分)
优化:
-
对频谱切片而言,此类结构的收敛速度慢。消融数据集中,20w步时依然不能很好控制收敛,推测来源于时域/频域相关性弱。故在预训练阶段加入掩码,加速训练速度和频谱关联性。微调阶段以高质量数据进一步强化模型(5W步就有收敛迹象)。
-
相比于U-Net,transformer based架构对text encoder的质量信息感知能力增强,并且U-ViT 式 token 质量融入策略显著有效进一步提升质量并降低客观指标
-
图像中切块未考虑 overlap,探究了overlap策略在合成中的作用(大幅降低FAD,但在主观听感上有trade off)
优化音乐标注描述
解决:首次在音乐生成领域使用预训练标注模型(LP-Musiccaps)进行大规模标注优化:
-
考虑到标注模型的不充分训练导致错标,以CLAP文本-音频分数+阈值筛选低分数据
-
考虑到原始标注中有些词(例如说American,R&B等标注器不一定能标注出的词)。使用CLAP分数过滤出生成的与原始的文本相似度低低数据,利用语言模型 融合原始标注中有用信息。
实验
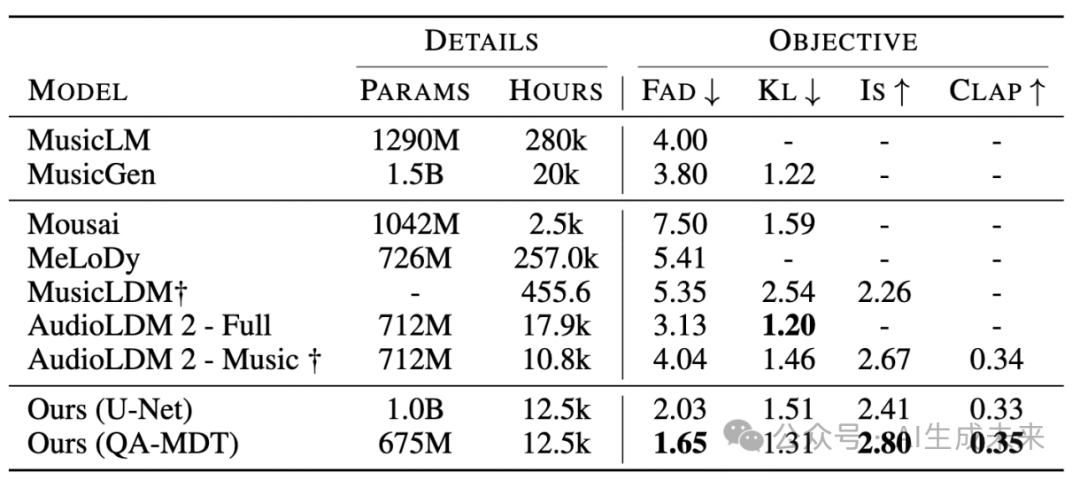
总体对比与,对比U-net架构和transformer based架构
对比overlap策略和patch size

质量感知消融
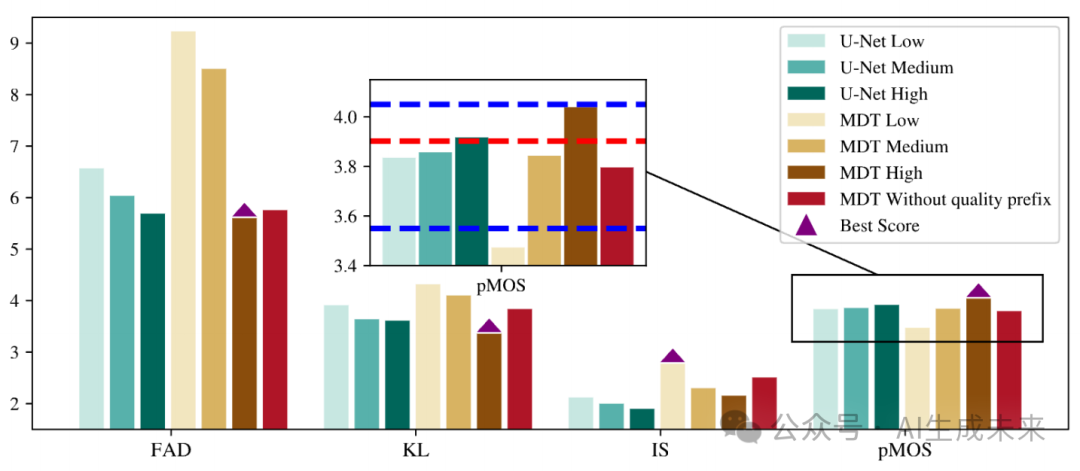
此图证明了相比于无质量感知,大幅提升了生成质量和客观指标。并且,MDT(我们的架构)比 U-Net 在文本质量控制感知上的独特优势(生成质量更高,总体客观指标更好)

左图展示了 token as control 的准确感知控制生成能力,生成的高质量数据(黄色区域)显著高于训练集MOS分。
右图展示了文本质量控制和token质量控制的结合效果与单纯token和文本控制的对比。

主观评测结果
-
PO:产品运营
-
PMP:专业音乐制作人
-
VE:视频编辑人
-
BEGINNERS:不懂音乐的小白
各个人的评分下,均有优势。
结论与展望
本研究识别出大规模音频质量不均和文本标注未对齐所带来的挑战,这些挑战阻碍了基于扩散的文本到音乐(TTM)生成的发展。通过采用基于p-MOS的新型质量感知学习方法,以及以masked扩散Transformer作为扩散过程的主干,在音乐生成中实现了更高的生成质量和音乐性。
参考文献
[1] QA-MDT: Quality-aware Masked Diffusion Transformer for Enhanced Music Generation