什么是 ShardingSphere
介绍
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
主要功能
一、数据库增强与分布式能力
- 数据分片:ShardingSphere可以将数据库表拆分成多个部分,每个部分称为分片,通过分片实现数据的分布和负载均衡。这能够极大地提升数据库集群的性能和可扩展性,解决单机数据库在存储和计算方面的瓶颈。
- 分布式事务:ShardingSphere提供在独立数据库上的分布式事务功能,基于XA和BASE的混合事务引擎,保证跨数据源的数据一致性,是保障数据库完整、安全的关键技术。
- 数据迁移与扩容:ShardingSphere提供跨数据源的数据迁移能力,并可支持重分片扩展,从而简化数据库迁移或扩容的过程。
二、数据治理与安全性
- 读写分离:基于对SQL语义理解及对底层数据库拓扑感知能力,ShardingSphere提供灵活的读写流量拆分和读流量负载均衡,能够进一步提升数据库系统的读性能。
- 数据加密:ShardingSphere提供完整、透明、安全、低成本的数据加密及脱敏解决方案,确保数据的安全性。
- 影子库:在全链路压测场景下,ShardingSphere支持不同工作负载下的数据隔离,避免测试数据污染生产环境。
三、兼容性与易用性
- 兼容性:ShardingSphere可以兼容所有符合SQL-92标准语法的数据库,包括MySQL、PostgreSQL、SQL Server和Oracle等,用户可根据需求选择最适合的数据库。
- 易用性:ShardingSphere提供了标准化的基于数据库作为存储节点的增量功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。同时,ShardingSphere-JDBC作为轻量级Java框架,在Java的JDBC层提供额外服务,无需额外部署和依赖;ShardingSphere-Proxy则定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。
四、云原生与多云架构支持
ShardingSphere天然支持云原生及多云架构,在构建分布式数据库架构的过程中能够轻松利用云计算的强大功能,实现性能、弹性以及适应力的最大化。
主从复制
原理复习
主从集群有啥好处?
- ①在主机宕机或故障的情况下,从节点能自动升级成主机,从而继续对外提供服务。
- ②提供数据备份的功能,当主节点的数据发生损坏时,从节点中依旧保存着完整数据。
- ③可以实现读写分离,主节点负责处理写请求,从节点处理读请求,进一步提升性能。
- ④可以实现多主多写,数据库系统可以由多个节点组成,共同对外提供读写处理的能力。
同步原理
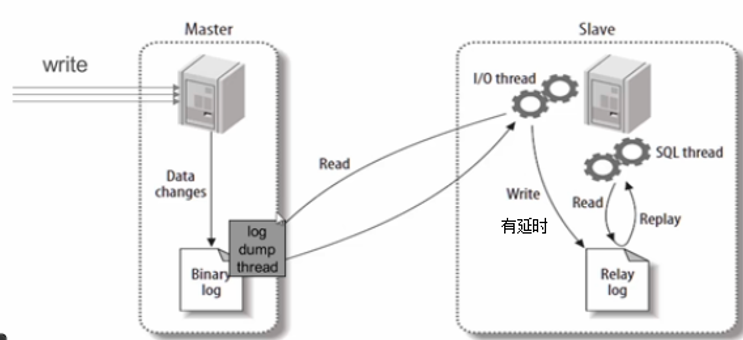
主要采用主推从拉思想
- 写入请求由主节点先执行,写入后记录bin-log二进制日志。
- 主节点的log dump线程监听到bin-log日志变化,通知从节点拉取数据。
- 从节点有专门I/O线程等待主节点通知,收到主机的数据后,写入relay-log中级日志。
- 从节点监听到relay-log日志变更,然后读取解析日志写入自己磁盘。
搭建主从集群,几种架构可选
- 一主一从:做读写分离,适用读大于写
- 双主/多主:各节点间互为主从,各节点都具备读写能力,读写参半
- 多主一从:一个从节点同步多个主节点,适用写大于读。
- 级联复杂:方案一改进,一个节点同步主机数据,适用写大于多。
主从复制的搭建
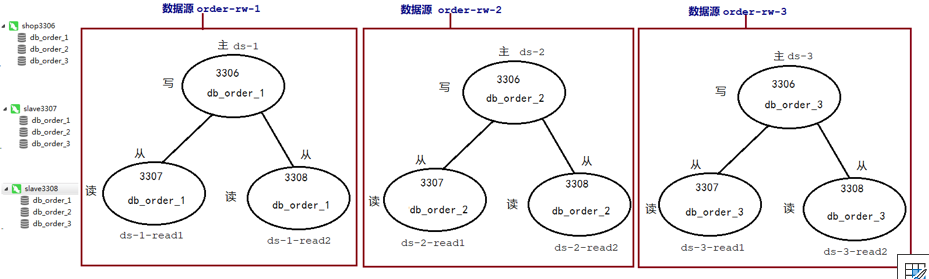
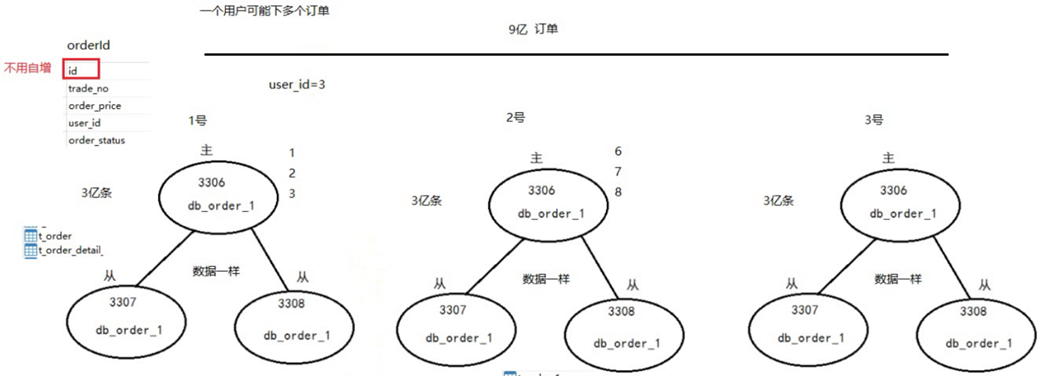
我们搭建主库3306,从库3307、3308。
主库(3306)
- 修改配置:进入容器修改 MySQL 配置文件
my.cnf,启用二进制日志和设置server-id - 授权:进入 MySQL 命令行,授权从库用户。
- 重启容器:使配置生效。
从库(3307 和 3308)
- 修改配置:进入容器,修改
my.cnf配置文件,设置不同的server-id。 - 配置主从复制:进入 MySQL 命令行,设置主库信息并启动复制。
- 重启容器:使配置生效。
一 搭建主节点3306
1.创建容器(可以不做)
docker run -d \
--name=mysql \
--env-file=/usr/local/software/nacos-docker/env/mysql.env \
-p 3306:3306 \
-v /usr/local/software/mysql/3306:/var/lib/mysql \
nacos/nacos-mysql:5.7
2.进入容器
docker exec -it mysql /bin/bash
3.修改my.cnf
!includedir /etc/mysql/conf.d/
!includedir /etc/mysql/mysql.conf.d/
[mysqld]
log-bin=mysql-bin
server-id=3306
binlog_format=STATEMENT
4.授权
grant replication slave on *.* to 'copy'@'%' identified by 'root';
show master status;
reset master;
5.重启容器
docker cp my.cnf mysql:/etc/mysql/my.cnf
docker restart mysql
二 搭建从节点3307
1.创建容器
docker run -d \
--name=slave3307 \
--env-file=/usr/local/software/nacos-docker/env/mysql.env \
-p 3307:3306 \
-v /usr/local/software/mysql/3307:/var/lib/mysql \
nacos/nacos-mysql:5.7
2.修改配置文件(docker exec -it slave3307 /bin/bash)
!includedir /etc/mysql/conf.d/
!includedir /etc/mysql/mysql.conf.d/
[mysqld]
# 从库在主从集群中的唯一标识
server-id=3307
3.执行命令
docker cp my.cnf slave3307:/etc/mysql/my.cnf
docker restart slave3307
(从这里开始换一台机器)
show slave status;
stop slave;
reset slave;
change master to master_host='10.211.55.6',master_user='copy',
master_port=3306,master_password='root',
master_log_file='mysql-bin.000001',master_log_pos=154;
start slave;
show slave status;
三 搭建从节点3308
1.创建容器
docker run -d \
--name=slave3308 \
--env-file=/usr/local/software/nacos-docker/env/mysql.env \
-p 3308:3306 \
-v /usr/local/software/mysql/3308:/var/lib/mysql \
nacos/nacos-mysql:5.7
2.修改配置文件(docker exec -it slave3308 /bin/bash)
!includedir /etc/mysql/conf.d/
!includedir /etc/mysql/mysql.conf.d/
[mysqld]
server-id=3308
3.执行命令
docker cp my.cnf slave3308:/etc/mysql/my.cnf
docker restart slave3308
show slave status;
stop slave;
reset slave;
change master to master_host='10.211.55.6',master_user='copy',
master_port=3306,master_password='root',
master_log_file='mysql-bin.000001',master_log_pos=154;
start slave;
show slave status
docker logs --tail=1000 slave3309
创建三个数据库
创建3306/3307/3308
db_order_1/db_order_2/db_order_3 最终数据库效果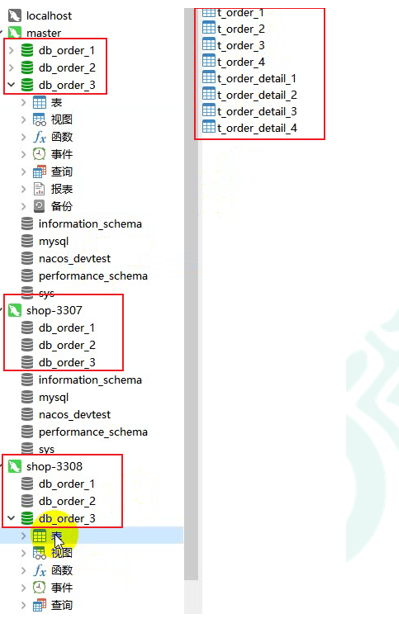
1.1.1. 效果展示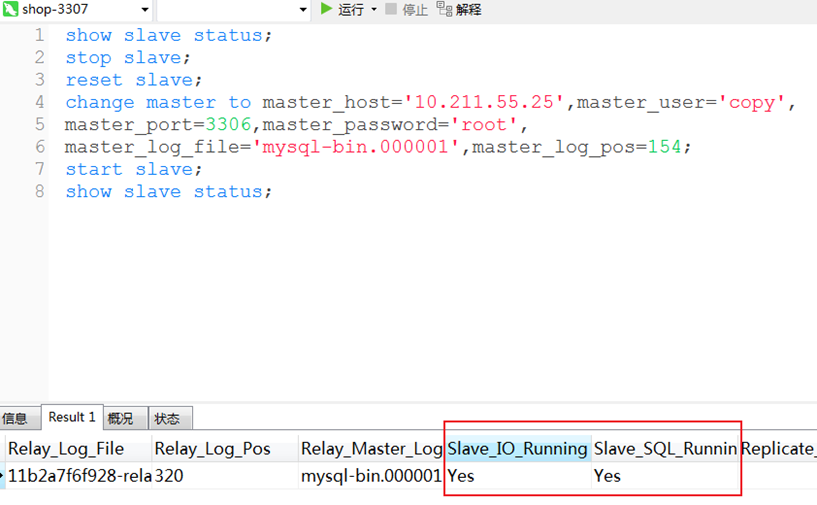
在其中必须要看到Slave_IO_Running、Slave_SQL_Running两个线程的状态都为Yes时,这才意味着主从集群搭建完成。
读写分离(项目中使用)
需求分析
对品牌实现读写分离
官网配置方式
https://shardingsphere.apache.org/document/5.2.1/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/
实现步骤
a. 编排数据库
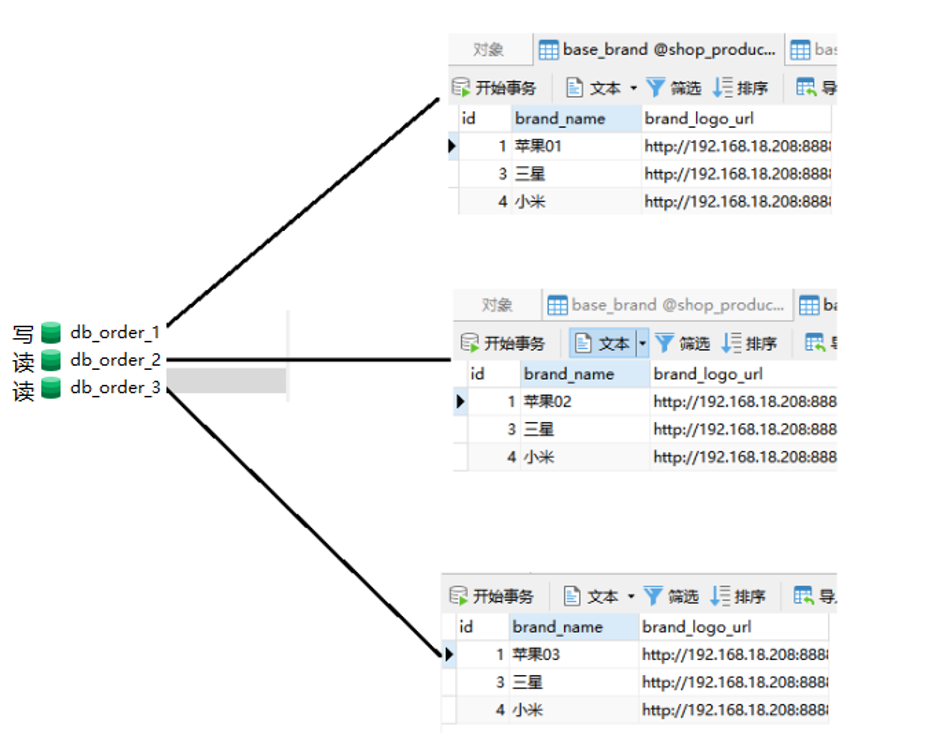
b.添加依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>${shardingsphere.version}</version>
</dependency>
a. 利用逆向工程生成代码
b. 配置文件
https://shardingsphere.apache.org/document/5.2.1/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/
shardingsphere:
mode:
type: Standalone
repository:
type: JDBC
datasource:
names: write-node,read-node1,read-node2
write-node:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://192.168.121.128:3306/db_order_1?characterEncoding=utf-8&useSSL=false
username: root
password: root
read-node1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://192.168.121.128:3306/db_order_2?characterEncoding=utf-8&useSSL=false
username: root
password: root
read-node2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://192.168.121.128:3306/db_order_3?characterEncoding=utf-8&useSSL=false
username: root
password: root
rules:
readwrite-splitting:
data-sources:
#读写分离多个数据源逻辑名称
readwrite-node:
static-strategy:
write-data-source-name: write-node
read-data-source-names:
- read-node1
- read-node2
load-balancer-name: read-lb
load-balancers:
read-lb:
type: ROUND_ROBIN
#打印SQL语句
props:
sql-show: true
出现的问题
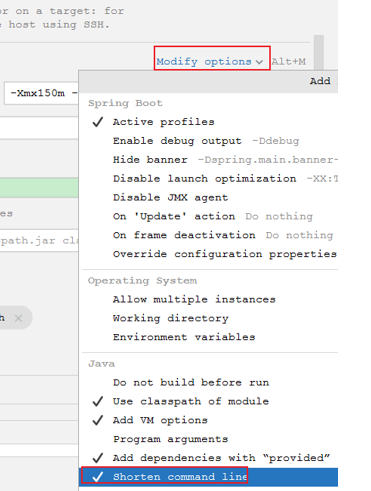
问题描述
启动时:

Command line is too long. Shorten command
解决方案
效果验证
读
127.0.0.1:8504/api/sharding/getAllBrand
读数据是从db_order_2和db_order_3中读


写
写数据往db_order_1中写

单表分库分表
规则分析
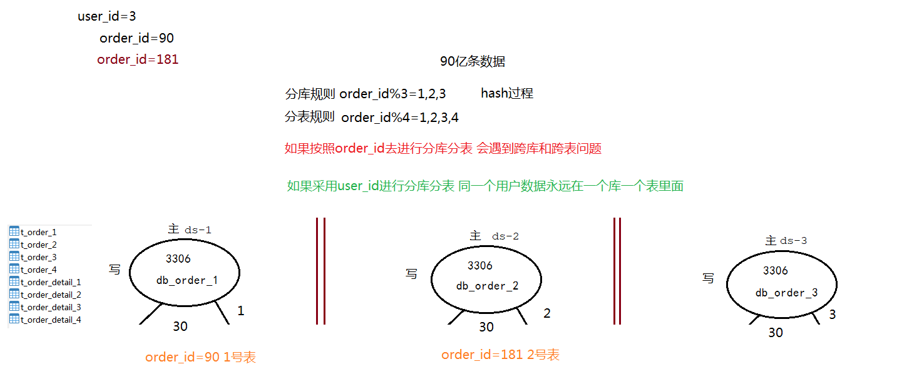 分库 order_id%3=1,2,3
分库 order_id%3=1,2,3
分表order_id%4=1,2,3,4
如果按照order_id分库分表,会遇到跨库问题
采用规则方式
采用user_id进行分库分表,同一个用户的数据会放到同一个库同一张表里面
分库 user_id%3=1,2,3
分表 user_id%4=1,2,3,4
10%3=1+1=2
10%4=2+1=3
具体步骤
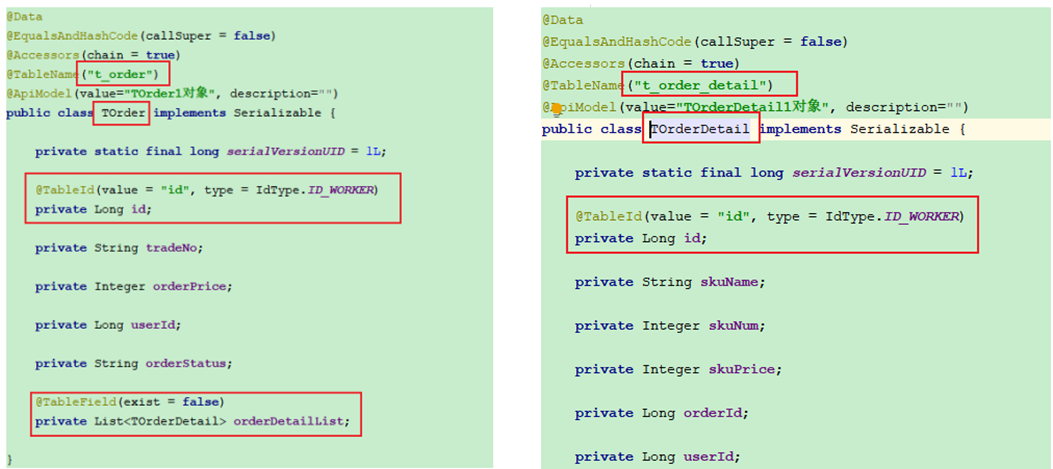
a.修改实体类
select * from db_order_{变量}.t_order_{变量}
a.修改yml文件
https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/sharding/
shardingsphere:
datasource:
names: ds-1,ds-2,ds-3
ds-1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3306/db_order_1?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3306/db_order_2?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-3:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3306/db_order_3?characterEncoding=utf-8&useSSL=false
username: root
password: root
rules:
sharding:
#配置分库算法
default-database-strategy:
standard:
sharding-algorithm-name: sharding-db-by-user-id
sharding-column: user_id
#具体算法如何做
sharding-algorithms:
#具体分库算法如何实现
sharding-db-by-user-id:
type: INLINE
props:
#ds-1,ds-2,ds-3
algorithm-expression: ds-$->{user_id%3+1}
#具体分表算法如何实现
sharding-table-order-by-user-id:
type: INLINE
props:
#t_order_1,t_order_2,t_order_3,t_order_4
algorithm-expression: t_order_$->{user_id%4+1}
#真实SQL如何实现的
tables:
t_order:
actual-data-nodes: ds-$->{1..3}.t_order_$->{1..4}
#表的分表策略
table-strategy:
standard:
sharding-algorithm-name: sharding-table-order-by-user-id
sharding-column: user_id
#打印SQL语句
props:
sql-show: true
编写保存订单分库分表测试

//1.保存订单利用分库分表
@GetMapping("test01/{loopNum}")
public void test01(@PathVariable Integer loopNum){
for (int i = 0; i <loopNum; i++) {
TOrder tOrder = new TOrder();
tOrder.setOrderPrice(99);
String uuid = UUID.randomUUID().toString();
tOrder.setTradeNo(uuid);
tOrder.setOrderStatus("未支付");
//设置分库分表字段
int userId = new Random().nextInt(20);
tOrder.setUserId(Long.parseLong(userId+""));
System.out.println("用户id"+userId);
order1Service.save(tOrder);
}
}
两张表实现保存分库分表
配置文件
TRUNCATE TABLE t_order_1;
TRUNCATE TABLE t_order_2;
TRUNCATE TABLE t_order_3;
TRUNCATE TABLE t_order_4;
TRUNCATE TABLE t_order_detail_1;
TRUNCATE TABLE t_order_detail_2;
TRUNCATE TABLE t_order_detail_3;
TRUNCATE TABLE t_order_detail_4;
shardingsphere:
datasource:
names: ds-1,ds-2,ds-3
ds-1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3306/db_order_1?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3306/db_order_2?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-3:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3306/db_order_3?characterEncoding=utf-8&useSSL=false
username: root
password: root
rules:
sharding:
#配置分库算法
default-database-strategy:
standard:
sharding-algorithm-name: sharding-db-by-user-id
sharding-column: user_id
#具体算法如何做
sharding-algorithms:
#具体分库算法如何实现
sharding-db-by-user-id:
type: INLINE
props:
#ds-1,ds-2,ds-3
algorithm-expression: ds-$->{user_id%3+1}
#具体分表算法如何实现
sharding-table-order-by-user-id:
type: INLINE
props:
#t_order_1,t_order_2,t_order_3,t_order_4
algorithm-expression: t_order_$->{user_id%4+1}
sharding-table-detail-by-user-id:
type: INLINE
props:
#t_order_detail_1,t_order_detail_2,t_order_detail_3,t_order_detail_4
algorithm-expression: t_order_detail_$->{user_id%4+1}
#真实SQL如何实现的
tables:
t_order:
actual-data-nodes: ds-$->{1..3}.t_order_$->{1..4}
#表的分表策略
table-strategy:
standard:
sharding-algorithm-name: sharding-table-order-by-user-id
sharding-column: user_id
t_order_detail:
actual-data-nodes: ds-$->{1..3}.t_order_detail_$->{1..4}
#表的分表策略
table-strategy:
standard:
sharding-algorithm-name: sharding-table-detail-by-user-id
sharding-column: user_id
binding-tables:
- t_order,t_order_detail
#打印SQL语句
props:
sql-show: true
代码
//2.保存订单与订单详情分库分表
@GetMapping("test02/{userId}")
public void saveOrderInfo(@PathVariable Long userId){
TOrder tOrder = new TOrder();
tOrder.setTradeNo("enjoy6288");
tOrder.setOrderPrice(9900);
tOrder.setUserId(userId);//ds-1,table_4
order1Service.save(tOrder);
TOrderDetail iphone13 = new TOrderDetail();
iphone13.setOrderId(tOrder.getId());
iphone13.setSkuName("Iphone13");
iphone13.setSkuNum(1);
iphone13.setSkuPrice(6000);
iphone13.setUserId(userId);
detail1Service.save(iphone13);
TOrderDetail sanxin = new TOrderDetail();
sanxin.setOrderId(tOrder.getId());
sanxin.setSkuName("三星");
sanxin.setSkuNum(2);
sanxin.setSkuPrice(3900);
sanxin.setUserId(userId); //要进行分片计算
detail1Service.save(sanxin);
System.out.println("执行完成");
效果
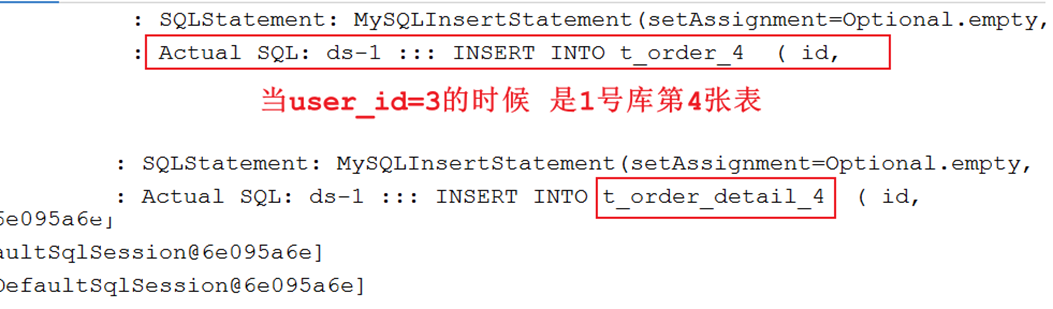
两张表实现分库分表查询
Controller(待)
//3.查询订单与订单详情
@GetMapping("test03/{userId}")
public void test03(@PathVariable Long userId){
List<TOrder> orderList=order1Mapper.queryOrderAndDetail(userId,null);
//根据订单的id查询订单(全库查询) 没有使用分片的键 速度相当慢
//List<TOrder> orderList=order1Mapper.queryOrderAndDetail(null,1624253671124619266L);
System.out.println(orderList);
}
配置文件
shardingsphere:
datasource:
#真实物理数据库数据源的名称
names: ds-1,ds-2,ds-3
ds-1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://10.211.55.25:3306/db_order_1?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://10.211.55.25:3306/db_order_2?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-3:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://10.211.55.25:3306/db_order_3?characterEncoding=utf-8&useSSL=false
username: root
password: root
#分库分表的策略
rules:
sharding:
#配置一个分库算法
default-database-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: sharding-db-by-user-id
#配置一个具体的分表分表算法
sharding-algorithms:
#分库具体算法
sharding-db-by-user-id:
type: INLINE
props:
#ds-1,ds-2,ds-3
algorithm-expression: ds-$->{user_id%3+1}
#分表的具体算法
sharding-table-order-by-user-id:
type: INLINE
props:
#t_order_1,t_order_2,t_order_3,t_order_4
algorithm-expression: t_order_$->{user_id%4+1}
sharding-table-detail-by-user-id:
type: INLINE
props:
#t_order_detail_1,t_order_detail_2,t_order_detail_3,t_order_detail_4
algorithm-expression: t_order_detail_$->{user_id%4+1}
#真实SQL语句查询
tables:
t_order:
actual-data-nodes: ds-$->{1..3}.t_order_$->{1..4}
#表的分表策略
table-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: sharding-table-order-by-user-id
t_order_detail:
actual-data-nodes: ds-$->{1..3}.t_order_detail_$->{1..4}
#表的分表策略
table-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: sharding-table-detail-by-user-id
出现的问题
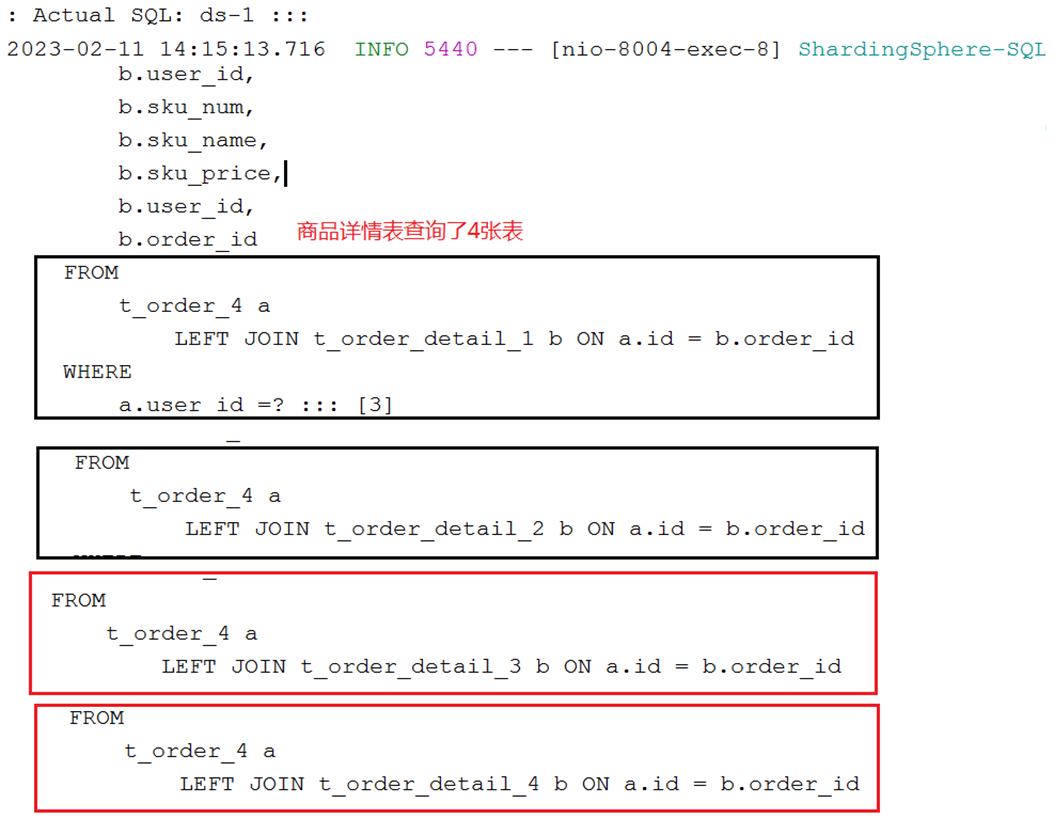
解决方案
对商品详情表也添加一个user_id的字段
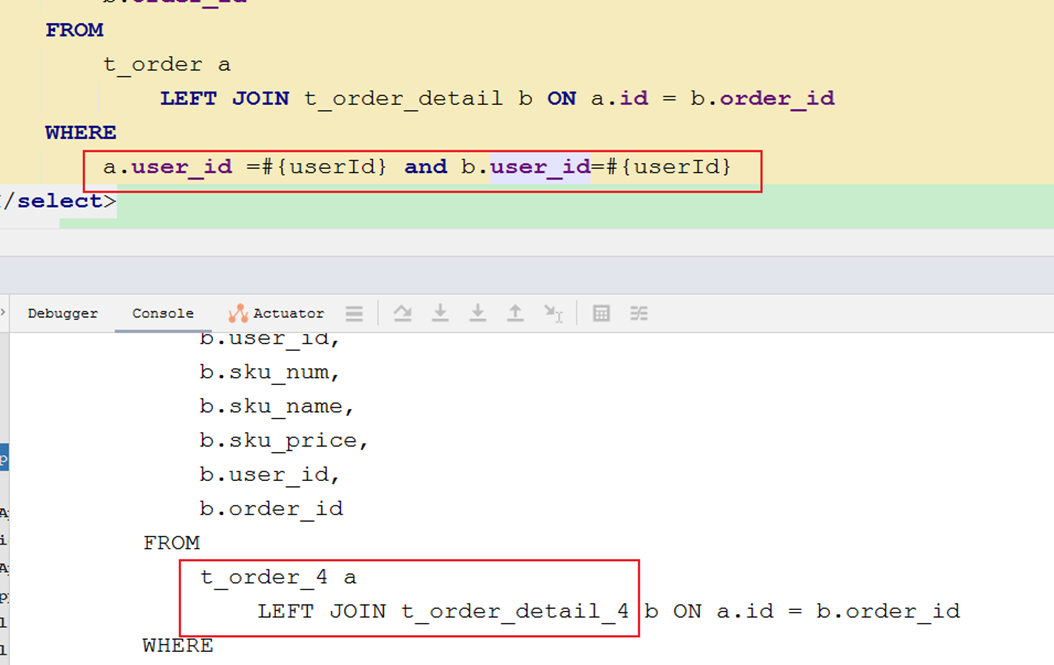 对两张表进行绑定
对两张表进行绑定
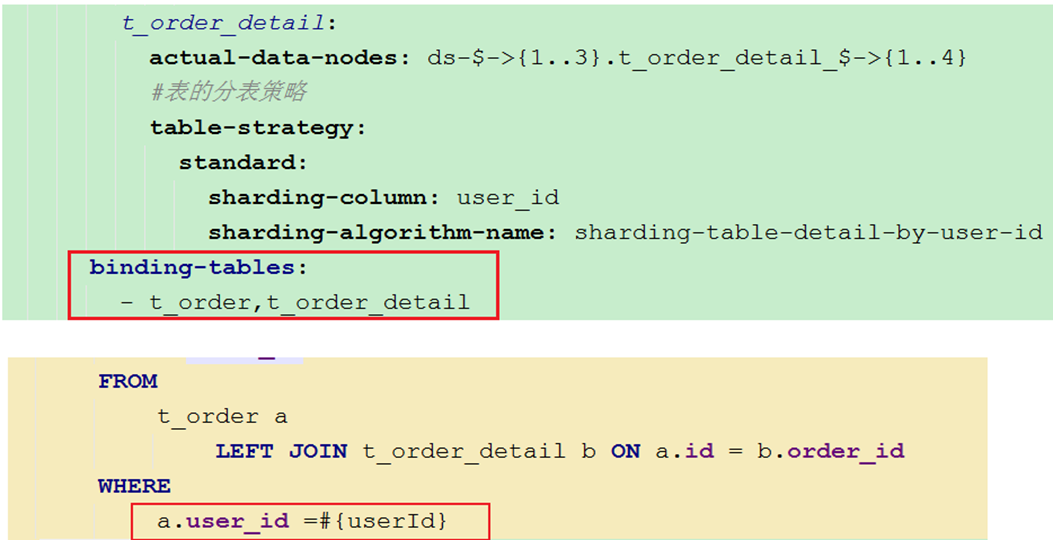
mapper代码
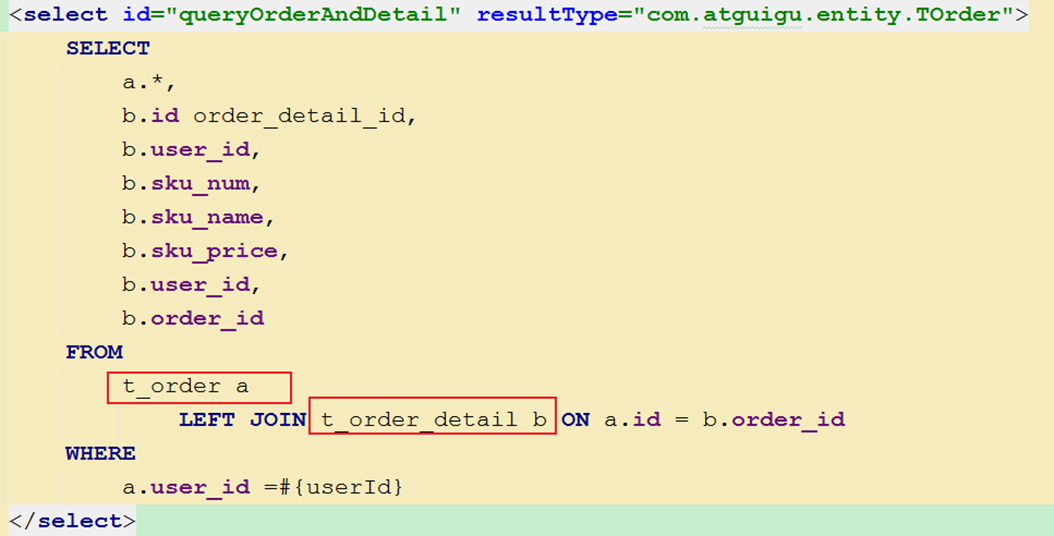
<resultMap id="orderMap" type="com.atguigu.entity.TOrder" autoMapping="true">
<id property="id" column="id"></id>
<collection property="orderDetailList" ofType="com.atguigu.entity.TOrderDetail" autoMapping="true">
<id property="id" column="order_detail_id"></id>
</collection>
</resultMap>
<select id="queryOrderAndDetail" resultMap="orderMap">
SELECT
a.*,
b.id order_detail_id,
b.user_id,
b.sku_num,
b.sku_name,
b.sku_price,
b.user_id,
b.order_id
FROM
t_order a
LEFT JOIN t_order_detail b ON a.id = b.order_id
<where>
<if test="userId!=null">
a.user_id = #{userId}
</if>
<if test="orderId!=null">
a.id = #{orderId}
</if>
</where>
</select>
根据订单id查询订单信息
mapper代码
<resultMap id="orderMap" type="com.atguigu.entity.TOrder" autoMapping="true">
<id property="id" column="id"></id>
<collection property="orderDetailList" ofType="com.atguigu.entity.TOrderDetail" autoMapping="true">
<id property="id" column="order_detail_id"></id>
</collection>
</resultMap>
<select id="queryOrderAndDetail" resultMap="orderMap">
SELECT
a.*,
b.id order_detail_id,
b.user_id,
b.sku_num,
b.sku_name,
b.sku_price,
b.user_id,
b.order_id
FROM
t_order a
LEFT JOIN t_order_detail b ON a.id = b.order_id
<where>
<if test="userId!=null">
a.user_id = #{userId}
</if>
<if test="orderId!=null">
a.id = #{orderId}
</if>
</where>
</select>
出现的问题
全库查询-----没有使用分片的键速度相当慢
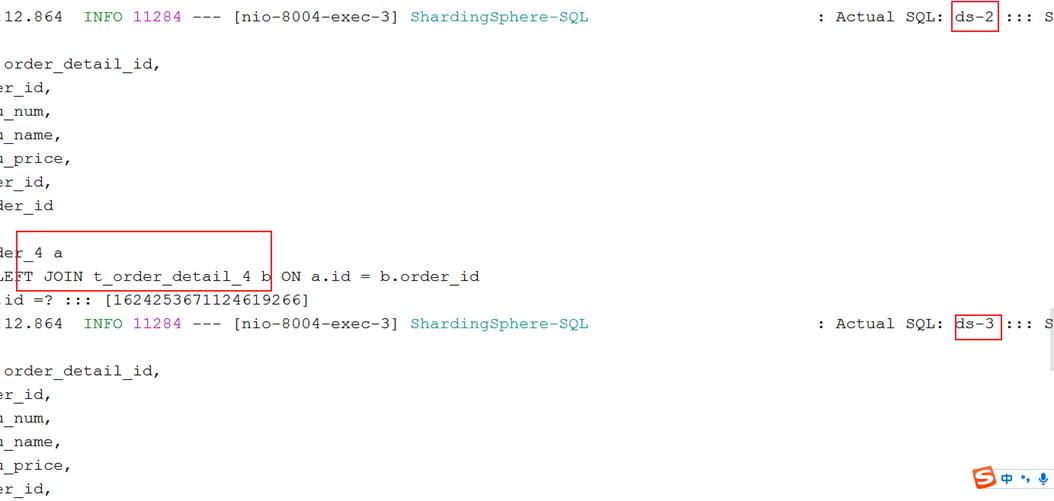
读写分离+主从复制+分库分表
查Controller
//3.查询订单与订单详情
@GetMapping("test03/{userId}")
public void test03(@PathVariable Long userId){
List<TOrder> orderList=order1Mapper.queryOrderAndDetail(userId,null);
//根据订单的id查询订单(全库查询) 没有使用分片的键 速度相当慢
//List<TOrder> orderList=order1Mapper.queryOrderAndDetail(null,1624253671124619266L);
System.out.println(orderList);
}

写数据

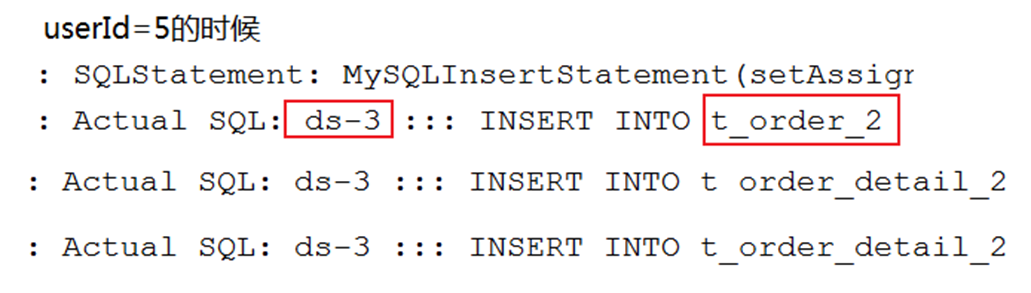
配置文件
shardingsphere:
datasource:
names: ds-1,ds-1-read1,ds-1-read2,ds-2,ds-2-read1,ds-2-read2,ds-3,ds-3-read1,ds-3-read2
#一号组
ds-1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3306/db_order_1?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-1-read1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3307/db_order_1?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-1-read2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3308/db_order_1?characterEncoding=utf-8&useSSL=false
username: root
password: root
#二号组
ds-2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3306/db_order_2?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-2-read1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3307/db_order_2?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-2-read2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3308/db_order_2?characterEncoding=utf-8&useSSL=false
username: root
password: root
#三号组
ds-3:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3306/db_order_3?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-3-read1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3307/db_order_3?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-3-read2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.121.128:3308/db_order_3?characterEncoding=utf-8&useSSL=false
username: root
password: root
#配置读写分离策略
rules:
readwrite-splitting:
data-sources:
#读写分离多个数据源逻辑名称
order-rw-1:
static-strategy:
write-data-source-name: ds-1
read-data-source-names: ds-1-read1,ds-1-read2
loadBalancerName: read-lb
order-rw-2:
static-strategy:
write-data-source-name: ds-2
read-data-source-names: ds-2-read1,ds-2-read2
loadBalancerName: read-lb
order-rw-3:
static-strategy:
write-data-source-name: ds-3
read-data-source-names: ds-3-read1,ds-3-read2
loadBalancerName: read-lb
loadBalancers:
read-lb:
type: ROUND_ROBIN
sharding:
#配置分库算法
default-database-strategy:
standard:
sharding-algorithm-name: sharding-db-by-user-id
sharding-column: user_id
#具体算法如何做
sharding-algorithms:
#具体分库算法如何实现
sharding-db-by-user-id:
type: INLINE
props:
#ds-1,ds-2,ds-3
algorithm-expression: order-rw-$->{user_id%3+1}
#具体分表算法如何实现
sharding-table-order-by-user-id:
type: INLINE
props:
#t_order_1,t_order_2,t_order_3,t_order_4
algorithm-expression: t_order_$->{user_id%4+1}
sharding-table-detail-by-user-id:
type: INLINE
props:
#t_order_detail_1,t_order_detail_2,t_order_detail_3,t_order_detail_4
algorithm-expression: t_order_detail_$->{user_id%4+1}
#真实SQL如何实现的
tables:
t_order:
actual-data-nodes: order-rw-$->{1..3}.t_order_$->{1..4}
#表的分表策略
table-strategy:
standard:
sharding-algorithm-name: sharding-table-order-by-user-id
sharding-column: user_id
t_order_detail:
actual-data-nodes: order-rw-$->{1..3}.t_order_detail_$->{1..4}
#表的分表策略
table-strategy:
standard:
sharding-algorithm-name: sharding-table-detail-by-user-id
sharding-column: user_id
binding-tables:
- t_order,t_order_detail
#打印SQL语句
props:
sql-show: true