如何批量下载采集淘宝图片?在现代电子商务的背景下,淘宝作为中国最大的在线购物平台之一,承载了数以亿计的商品和信息。对于从事电商运营、市场推广或网络营销的人员而言,采集淘宝图片已经成为日常工作中的重要任务。这不仅是为了丰富商品信息,还能提升店铺的吸引力和竞争力。下载淘宝图片的需求主要源于多个方面。首先,精美的商品图片能够直接影响消费者的购买决策。在众多同类商品中,图片的质量和视觉效果往往是吸引顾客注意的关键。因此,电商运营人员需要定期更新和替换店铺中的商品图片,以保持新鲜感和吸引力。然而,下载淘宝图片并不是一件简单的事情。由于平台的限制,直接右键保存图片往往无法得到高质量的原图,甚至会出现水印问题。因此,很多人选择使用专业的图片下载工具或插件,这些工具能够批量下载商品图片,节省大量时间和精力。此外,掌握一定的网络爬虫技术,能够帮助实现自动化采集,极大提高工作效率。
所以今天小编的目的,就是帮助大家掌握从淘宝中批量下载采集图片这项技能,下面的内容一共涉及3个方法,有的方法直接使用软件下载,有的则需要编写命令或者浏览器插件来完成,赶紧试试看吧。

方法一:使用“星优图片下载助手”软件批量下载采集淘宝图片
步骤1,因为这个方法使用的是一个软件工具,所以还请你将“星优图片下载助手”软件下载到电脑上并安装好。你可以直接通过官网地址进行下载,或者在搜索引擎(如百度)里搜索软件名称后找到靠谱渠道下载。
步骤2,软件左侧下面有一个【淘宝】文字按键,我们需要点击它。
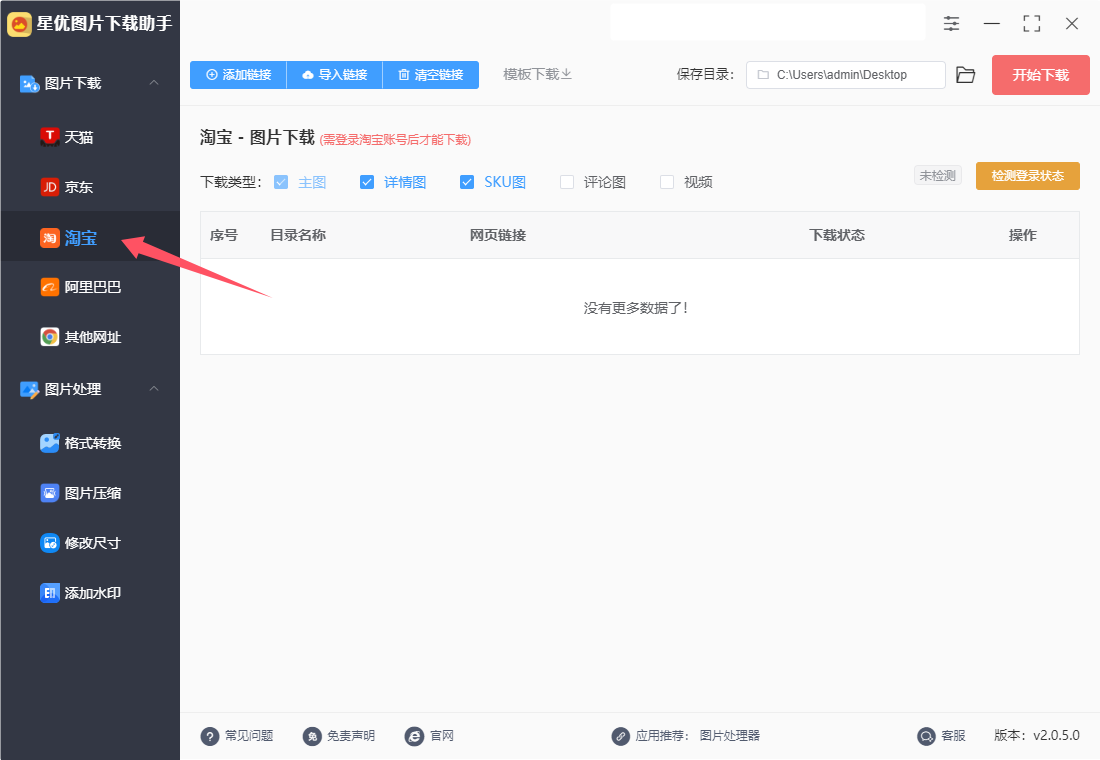
步骤3,接下来就是添加链接的环节,我们需要将淘宝商品链接添加到软件里,两种添加方式:
方式①,点击软件左上角【添加链接】按键后会弹出一个窗口,我们输出链接名称和链接后,点击“确定”按键即可添加成功。
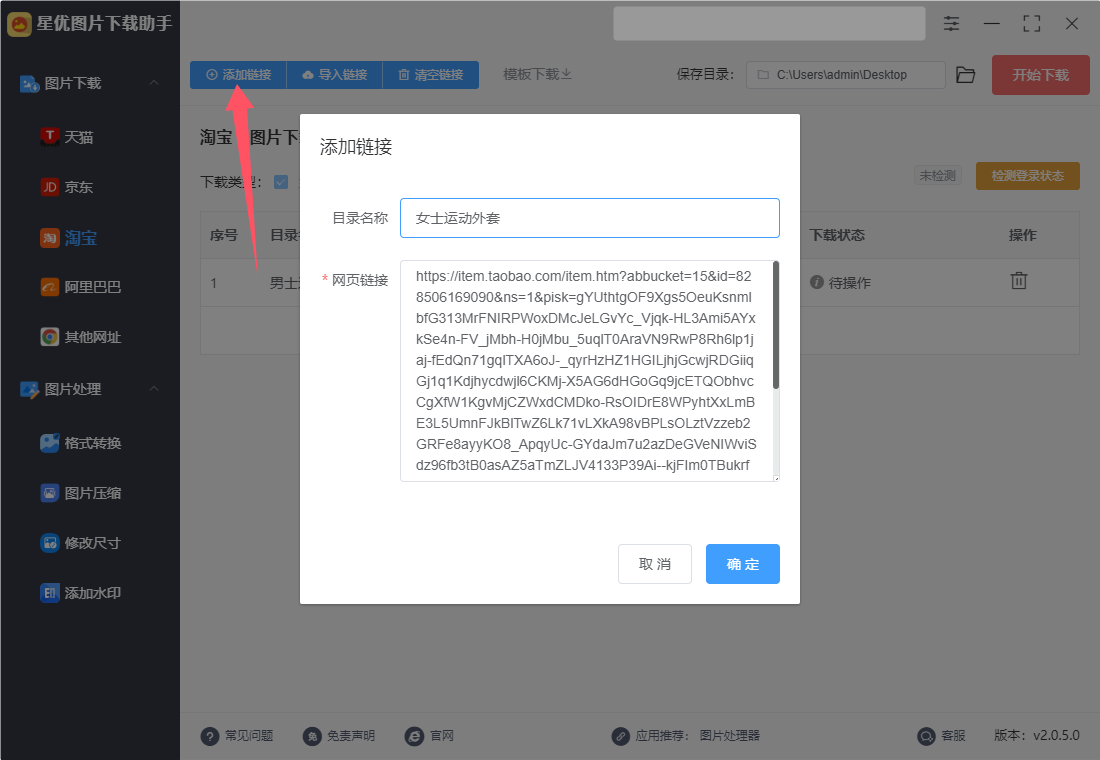
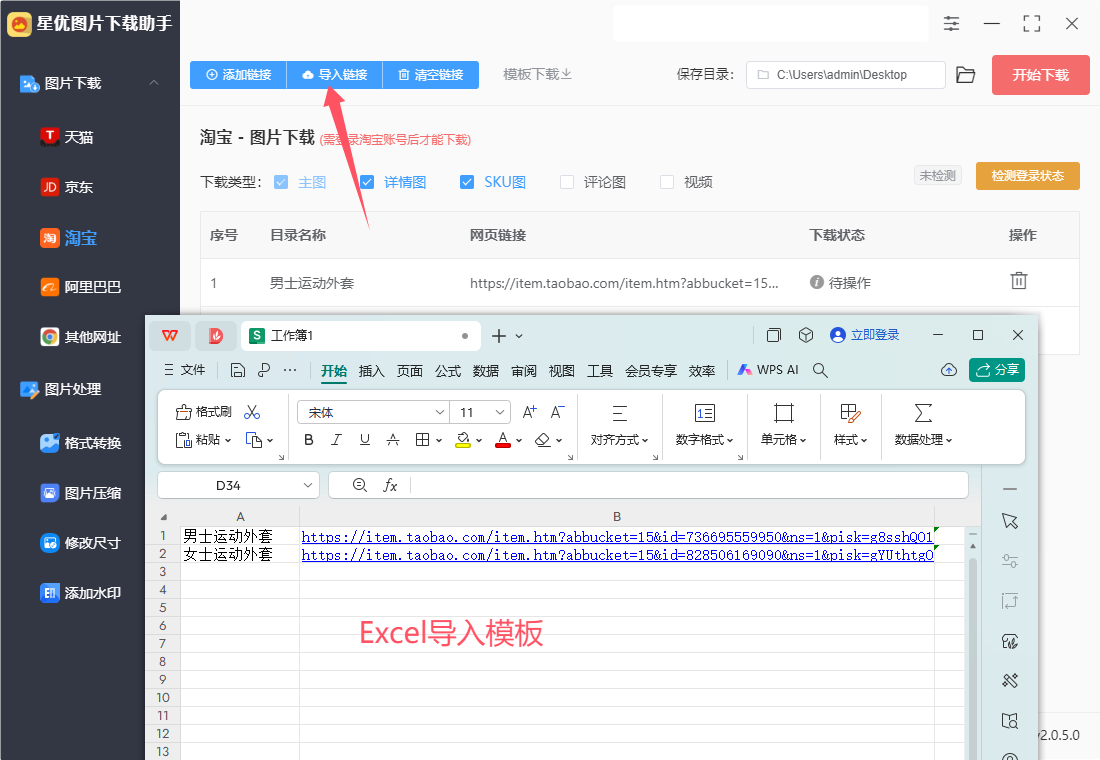
方式②,点击【导入链接】按键实现链接批量添加,导入格式为excel表格,表格第一列填写链接名,第二列填写链接,下图中有模板样式。
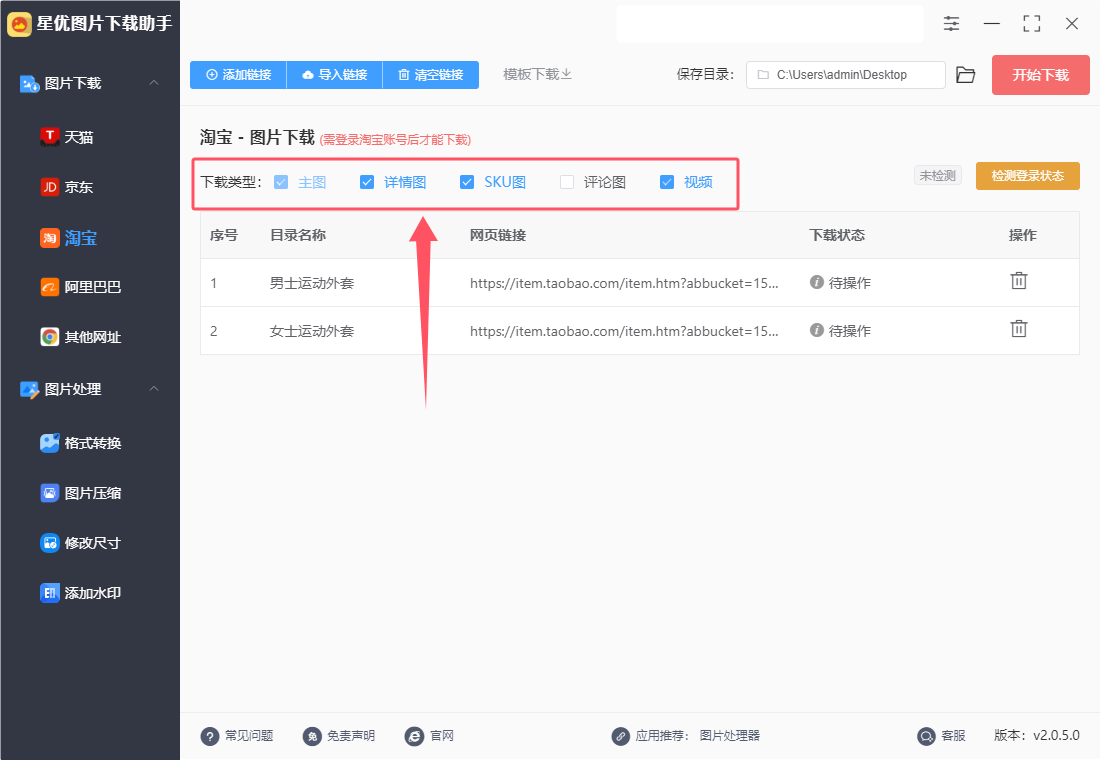
步骤4,随后我们需要设置图片下载类型,一共支持五种,你需要哪种就选择哪种。
步骤5,这一步我们需要在软件里登录淘宝账号,只有登录淘宝账号后才能下载图片,请按下面的顺序进行登录:
①,先点击【检测登录状态】,检测后如果发现未登录,左侧会出现【未登录,点击登录淘宝账号】文字按键,请点击它。
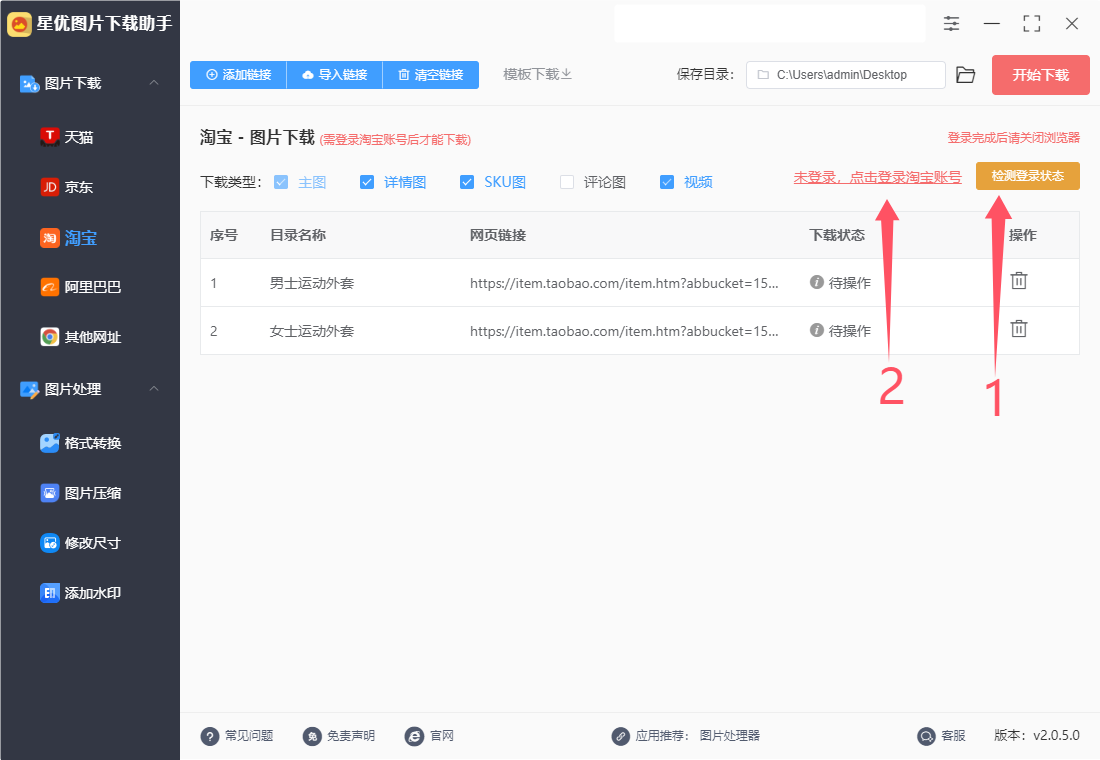
②,此时你会发现软件弹出登录窗口,在这里我们登录自己的淘宝账号(密码登录,验证码登录和扫码登录,选择一种即可),登录完成后关闭软件回到软件界面。
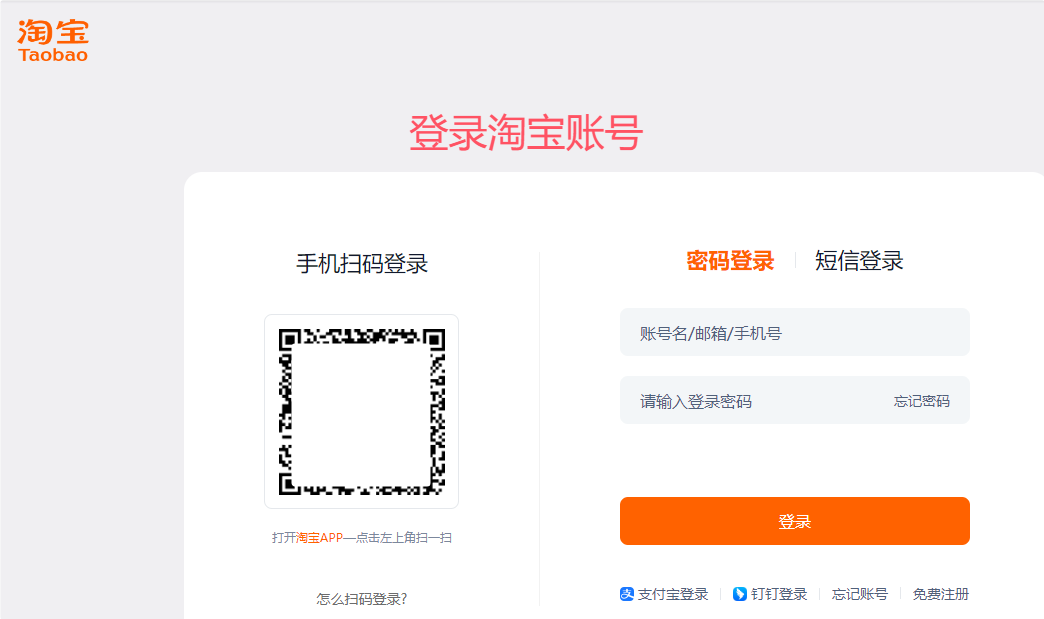
步骤6,登录结束后即可点击【开始下载】按键启动软件,我们只需等待软件下载完成即可。
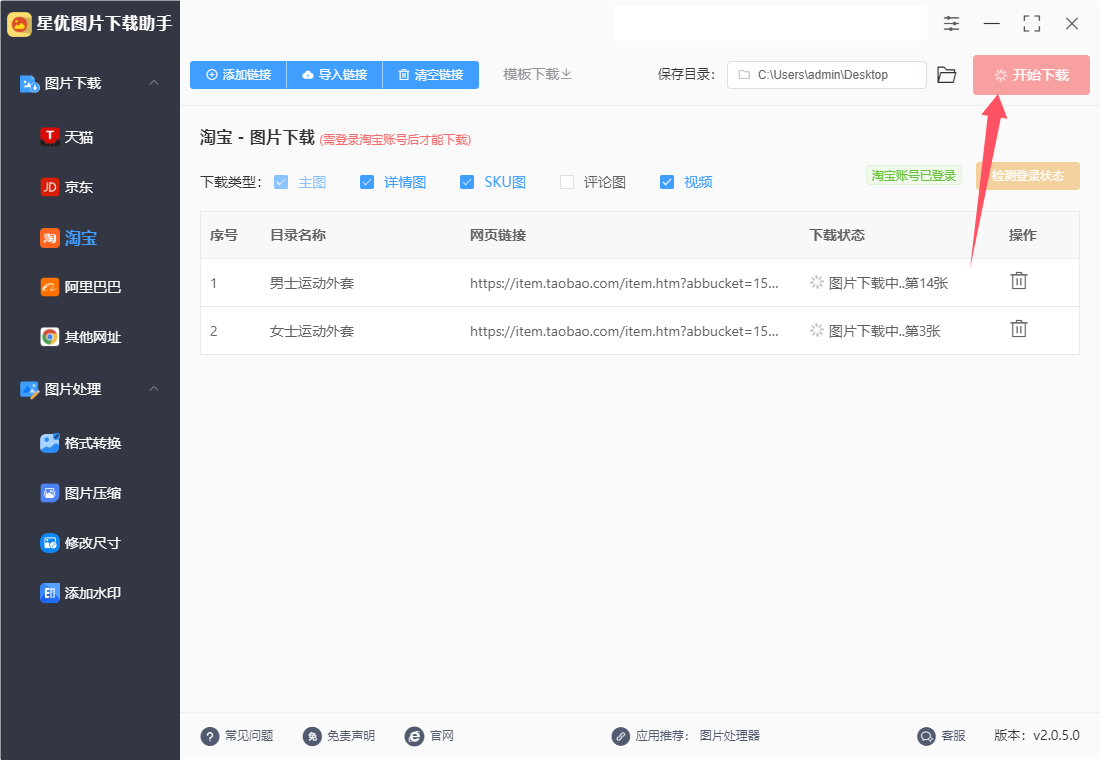
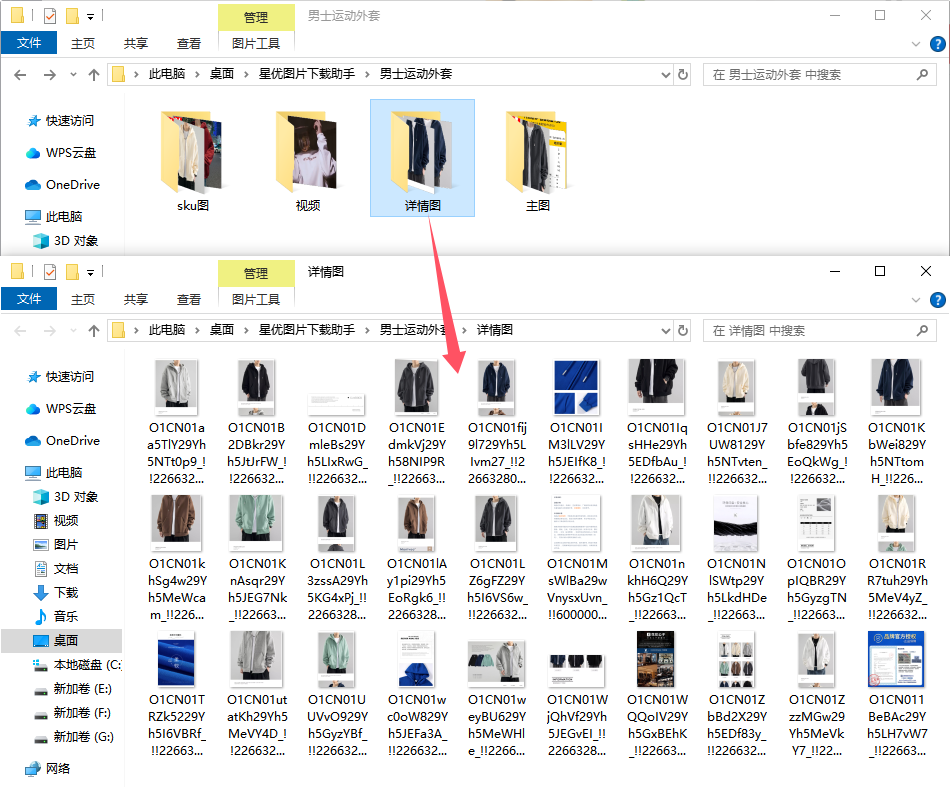
步骤7,下载结束后软件会弹出保存目录,在这里可以看到每个链接生成的文件夹,链接里下载的淘宝图片都保存在对应的文件夹里。
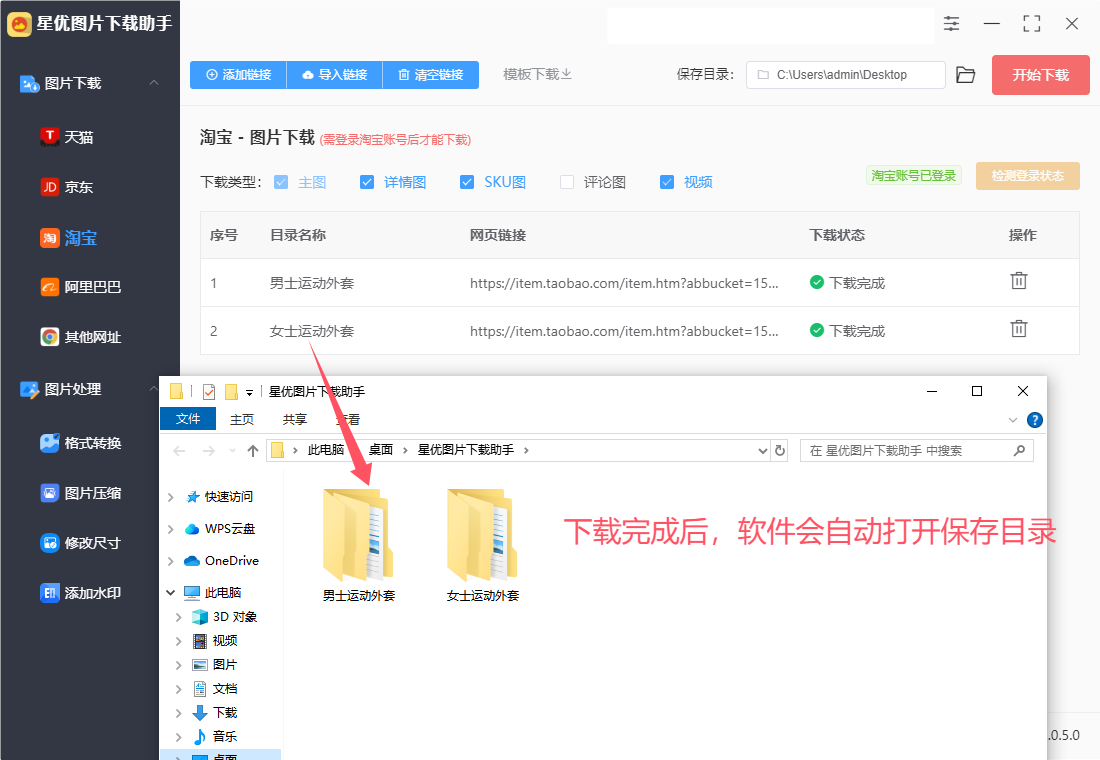
步骤8,打开一个文件夹可以看到,下载的图片都分好了类,不同类别的图片被保存在不同的类别文件夹里,便于后面的使用,这样整个淘宝图片批量下载就完成了
方法二:使用Selenium批量下载采集淘宝图片
使用Selenium批量采集淘宝图片是一个比较有效的方法,尤其是当网页内容动态加载时。下面是一个详细的步骤指南,帮助你设置和使用Selenium来采集淘宝图片。
1. 安装环境
首先,确保你的计算机上安装了 Python 和一些必要的库。
安装 Python
如果你还没有安装 Python,请访问 Python官网 下载并安装。
安装 Selenium
打开命令行(Windows 使用 CMD,Mac/Linux 使用终端),然后输入以下命令安装 Selenium:
pip install selenium
安装浏览器驱动
Selenium 需要与浏览器进行交互,因此需要下载对应浏览器的驱动。
Chrome: 下载 ChromeDriver 与 Chrome 浏览器版本匹配的驱动,解压并记下路径。
Firefox: 下载 geckodriver,同样需要与 Firefox 版本匹配。
2. 编写爬虫代码
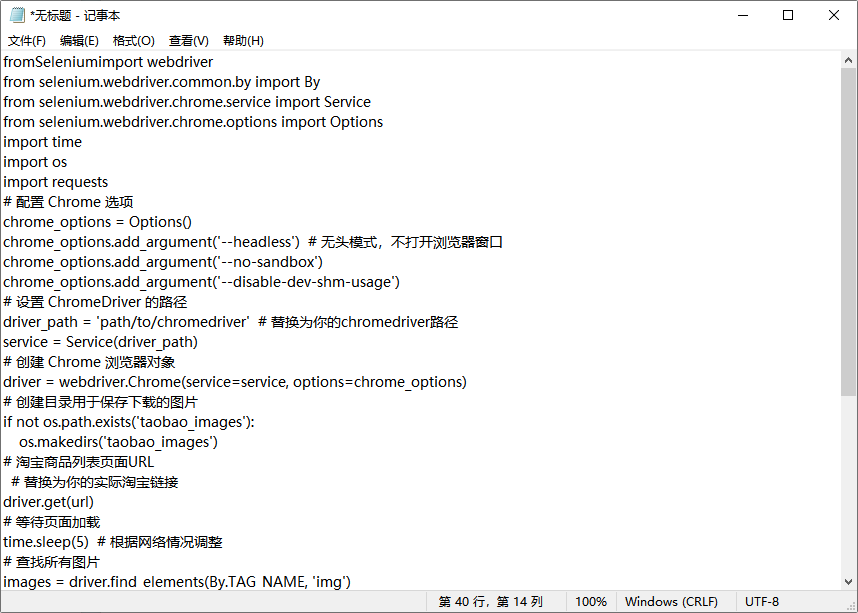
以下是一个使用Selenium的 Python 代码示例,演示如何在淘宝上批量下载图片。
fromSeleniumimport webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import time
import os
import requests
# 配置 Chrome 选项
chrome_options = Options()
chrome_options.add_argument('--headless') # 无头模式,不打开浏览器窗口
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
# 设置 ChromeDriver 的路径
driver_path = 'path/to/chromedriver' # 替换为你的chromedriver路径
service = Service(driver_path)
# 创建 Chrome 浏览器对象
driver = webdriver.Chrome(service=service, options=chrome_options)
# 创建目录用于保存下载的图片
if not os.path.exists('taobao_images'):
os.makedirs('taobao_images')
# 淘宝商品列表页面URL
# 替换为你的实际淘宝链接
driver.get(url)
# 等待页面加载
time.sleep(5) # 根据网络情况调整
# 查找所有图片
images = driver.find_elements(By.TAG_NAME, 'img')
# 下载图片
for index, img in enumerate(images):
img_url = img.get_attribute('src')
if img_url:
try:
img_data = requests.get(img_url).content
with open(f'taobao_images/image_{index + 1}.jpg', 'wb') as handler:
handler.write(img_data)
print(f"Downloaded: image_{index + 1}.jpg")
except Exception as e:
print(f"Failed to download {img_url}: {e}")
# 关闭浏览器
driver.quit()
3. 运行代码
保存代码:将上述代码保存为 taobao_scraper.py。
修改驱动路径:在代码中替换 driver_path 为你的 ChromeDriver 实际路径,同时将 url 替换为你想要爬取的淘宝页面地址。
运行脚本:在命令行中,导航到代码文件所在的目录并运行:
bash
python taobao_scraper.py
4. 注意事项
反爬机制:淘宝可能会有反爬机制,因此在抓取过程中需要注意请求频率,可以增加 time.sleep() 的时间,避免过于频繁的请求。
登录限制:某些页面可能需要登录才能查看图片,考虑使用Selenium进行登录操作。
法律合规:确保遵守相关法律法规,不要侵犯他人版权。
5. 可能的改进
动态加载处理:如果页面图片是动态加载的,可以使用 WebDriverWait 等待特定元素加载。
更多图片格式:根据实际需要,调整图片的保存格式。
异常处理:加强异常处理机制,以应对网络问题或页面结构变化等。
以上步骤和代码示例将帮助你使用Selenium批量采集淘宝上的图片。
方法三:使用BeautifulSoup批量下载采集淘宝图片
使用BeautifulSoup批量采集下载淘宝图片是一个相对复杂但有效的过程。以下是一个详细的步骤指南,帮助你实现这一目标:
一、准备阶段
安装必要的库
确保你已经安装了Python,并且可以通过pip安装必要的库。
使用pip安装requests和BeautifulSoup4库,以及用于处理JavaScript渲染的selenium库(如果目标页面包含动态加载的内容)。
分析目标页面
确定你想要爬取图片的淘宝页面,如商品详情页、店铺首页或搜索结果页。
使用浏览器的开发者工具查看网页的HTML源代码,特别注意图片标签(如<img>标签的src属性)和可能包含图片链接的JavaScript代码。
二、编写爬虫代码
导入必要的库
import requests
from bs4 import BeautifulSoup
fromSeleniumimport webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import os
import time
设置请求头
为了防止被淘宝的反爬机制识别为爬虫,设置合理的请求头,包括User-Agent等。
发送请求并获取响应
如果目标页面不包含动态加载的内容,可以直接使用requests库发送HTTP请求并获取响应内容。
如果目标页面包含动态加载的内容,则需要使用selenium库模拟浏览器行为,等待页面加载完成后再获取响应内容。
解析HTML内容
使用BeautifulSoup解析响应内容,提取出图片链接。
下载并保存图片
遍历提取出的图片链接,使用requests库的get方法下载图片。
将下载的图片保存到本地磁盘,可以根据需要设置保存路径和文件名。
三、处理特殊情况
登录验证
如果淘宝要求登录才能访问某些页面,你需要使用selenium模拟登录过程。
动态加载内容
如果图片是通过JavaScript动态加载的,requests可能无法直接获取到。此时,可以使用selenium来模拟浏览器行为,等待图片加载完成后再提取链接。
反爬机制
淘宝有强大的反爬机制,可能会限制访问频率、验证码验证等。你需要根据实际情况调整爬虫策略,如设置合理的请求间隔时间、使用代理IP等。
异常处理
在编写爬虫代码时,要充分考虑可能出现的异常情况,如网络问题、请求超时、数据解析错误等,并编写相应的异常处理代码。
四、示例代码
以下是一个简化的示例代码框架,用于展示如何使用BeautifulSoup和selenium库来爬取淘宝图片(注意:由于淘宝的反爬机制,此代码可能需要根据实际情况进行调整和完善):
# 省略了部分导入库和设置请求头的代码...
def download_images(url):
# 使用selenium模拟浏览器行为
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式
options.add_argument('--disable-gpu')
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.get(url)
# 等待页面加载完成(根据需要调整等待时间)
time.sleep(5)
# 获取页面源代码
page_source = driver.page_source
# 使用BeautifulSoup解析源代码
soup = BeautifulSoup(page_source, 'html.parser')
# 提取图片链接(根据实际情况调整提取方式)
images = soup.find_all('img')
img_urls = [img['src'] for img in images if 'http' in img['src']] # 只提取包含http的图片链接
# 下载并保存图片
for img_url in img_urls:
response = requests.get(img_url)
if response.status_code == 200:
img_name = os.path.join('downloaded_images', os.path.basename(img_url)) # 设置保存路径和文件名
with open(img_name, 'wb') as f:
f.write(response.content)
else:
print(f"Failed to download {img_url}")
# 关闭浏览器
driver.quit()
# 示例URL(需要替换为实际的目标URL)
download_images(url)
五、注意事项
遵守法律法规:在爬取淘宝图片时,务必遵守相关法律法规和淘宝的使用协议,不得用于商业用途或侵犯他人权益。
尊重网站规则:不要过度频繁地访问淘宝服务器,以免对网站的正常运行造成影响。
调整策略:由于淘宝的反爬机制不断更新和完善,你可能需要不断调整爬虫策略以适应新的情况。
在采集过程中,需要注意法律和道德问题。淘宝上的图片通常受到版权保护,未经授权的使用可能导致侵权。因此,在使用这些图片时,运营人员应该遵循相关法律法规,确保所使用的图片是经过合法授权的。此外,与供应商或品牌方沟通,获取正式的图片资源,也是一个不错的选择。最后,采集淘宝图片不仅仅是为了满足工作需求,更是提升个人和团队专业水平的重要环节。通过不断尝试不同的采集方式和技巧,运营人员可以提高自身的工作效率,增强市场竞争力。在这个信息化和数字化高度发展的时代,掌握有效的图片采集技能将为职业发展提供更多的机会和空间。总之,下载和采集淘宝图片是电商工作中不可或缺的一部分。通过不断学习和应用新的工具与方法,能够更好地服务于商品推广和市场营销,助力个人和团队在竞争激烈的电商环境中取得成功。关于“如何批量下载采集淘宝图片?”的方法就全部介绍完毕了,如果你对这项技能感兴趣,就一定要试一试哦。