2024-10-15,由威斯康星大学麦迪逊分校、微软研究院雷德蒙德等机构联合创建了TemporalBench,它通过大约10K个视频问答对,提供了一个独特的测试平台,用以评估各种时间理解和推理能力,如动作频率、运动幅度、事件顺序等。
一、研究背景:
在多模态视频理解和生成领域,细粒度的时间动态理解至关重要。然而,由于缺乏细粒度的时间标注,现有的视频基准测试大多类似于静态图像基准测试,无法有效评估模型对时间理解的能力。
目前遇到困难和挑战:
1、现有的视频理解基准测试偏向语言先验偏见,忽略了视频内容真正的时间动态。
2、当前的视频基准测试存在单一帧偏见,倾向于空间推理,未能测试模型对时间序列的理解。
3、现有的多模态视频模型(VLMs)在流行的视频问答基准测试中表现优于视频对应模型,但这种优势并不是建立在对视频时间事件真正理解的基础上。
数据集地址:TemporalBench|视频理解数据集|时间理解数据集
二、让我们一起看一下 TemporalBench
TemporalBench是一个基准测试(benchmark),它专门设计来评估多模态视频模型在理解视频中细粒度时间动态方面的能力。这个基准测试包含了大约10K个视频问题-答案对,这些问题-答案对是基于大约2K个高质量人类标注的视频剪辑衍生而来的。通过这些详细的时间动态描述,TemporalBench 提供了一个独特的测试平台,用于评估各种时间理解和推理能力,例如动作频率、运动幅度、事件顺序等。
TemporalBench支持多种视频理解任务,包括视频问答、视频字幕生成、长视频理解等。它提供了详细的视频描述,可以用于评估视频-语言嵌入模型和生成模型。
基准测试:
测试显示,即使是最先进的模型,如GPT-4o,在TemporalBench上的问答准确率仅为38.5%,而人类为67.9%,表明AI模型在时间理解上与人类存在显著差距。
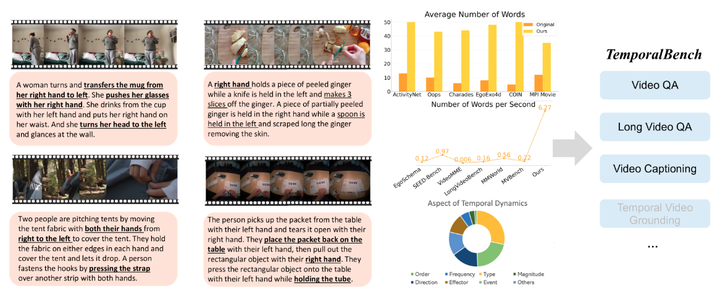
TemporalBench 的任务。TemporalBench 从细粒度的视频描述开始,支持包括视频 QA、视频字幕、长视频理解等多样化的视频理解任务。它与现有基准的不同之处在于每个视频的平均字数(中上)、字密度(中)和各种时间方面的覆盖率(中下)。
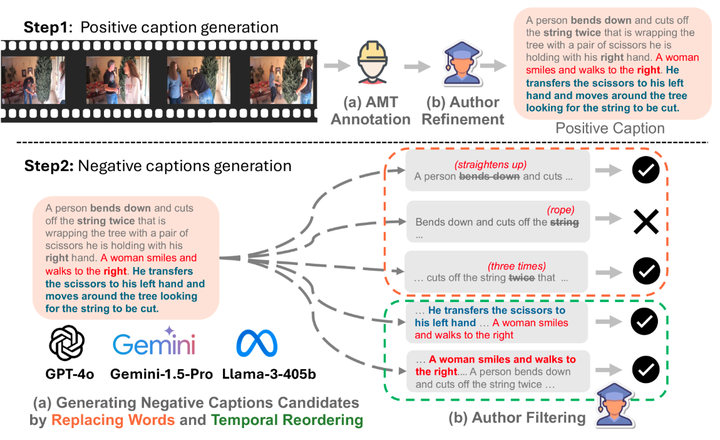
在第 1 步中,我们使用合格的 AMT 注释者为视频收集高质量的字幕,然后对其进行优化。
在第 2 步中,我们利用现有的 LLMs 来生成负面字幕,方法是替换选定的单词并重新排序操作序列,然后再自行过滤它们。
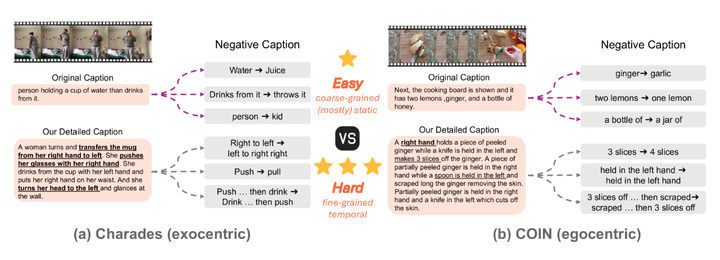
从 TemporalBench 中的原始字幕和我们的详细字幕生成的负面字幕的比较。对于细粒度的细节,底片更加困难且以时间为中心。
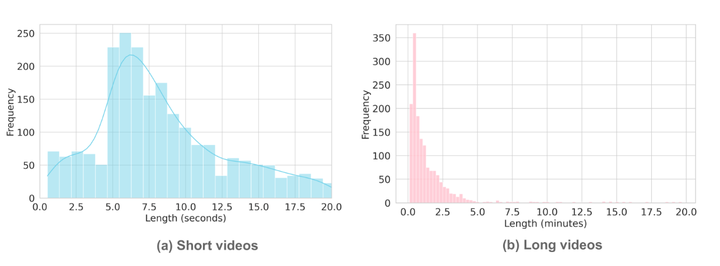
TemporalBench 中 (a) 短视频剪辑和 (b) 长视频的视频长度分布。

多选 QA 的插图,其中包含 (a) 原始字幕和 (b) 启发式指导的否定字幕。橙色块表示从正选项(绿色框)更改的内容。
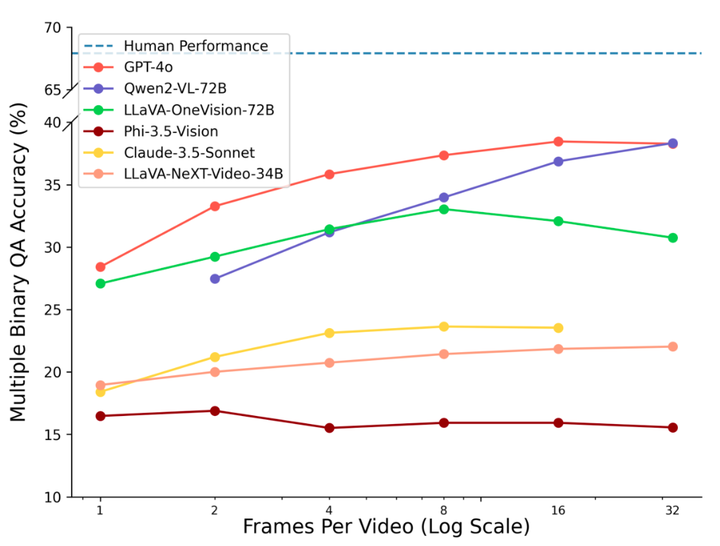
在不同帧的 TemporalBench 上建模性能。
三、让我们一起展望TemporalBench的应用:
比如,我是一名足球教练,正在分析上周的重要比赛,特别是那个决定比赛胜负的关键时刻——一个精彩的进球。我想知道这个进球是怎么发生的,球员们的动作是如何配合的,以及防守方是在哪里出现了失误。
这个进球发生在比赛的第75分钟。当时,我的球队在对方半场获得了一个角球机会。
动作分析:
-
角球开出:首先,我看到底角球是由7号球员开出的。他站在角旗区,抬头观察了一下禁区内的情况,然后起脚将球传向了禁区中央。
-
空中争顶:球飞向禁区中央时,我的球队的中锋9号球员和对方两名中卫同时起跳争顶。这个动作非常关键,因为9号球员的起跳时机和高度都把握得非常好,他成功地将球顶向了球门的方向。
-
射门:这时,我的球队的前锋11号球员出现在了正确的位置。他观察到9号球员的头球后,迅速调整自己的位置,用一脚凌空抽射将球打进了对方球门。
现在,我使用一个通过了TemporalBench基准测试的系统
就可以分析这个进球过程,它能够提供详细的时间线和动作描述。
这个系统能够识别和记录以下关键信息:
1、7号球员在第75分钟30秒时开出角球。
2、9号球员在第75分钟32秒时成功争顶,将球顶向了球门方向。
3、11号球员在第75分钟33秒时完成射门,球进了。
这些信息不仅能帮我理解进球的整个过程,还能分析出球员们的动作是如何精确配合的。比如,7号球员的传球时机,9号球员的头球力度和方向,以及11号球员的射门时机。
它不仅能帮我理解比赛的关键时刻,还能分析球员们的动作是如何精确配合的。这种细粒度的时间动态理解,对于教练来说,绝对是分析比赛、提高球队表现的有力工具。