零、文章目录
Nginx12-集群高可用
1、Nginx实现服务器集群
(1)单机模式
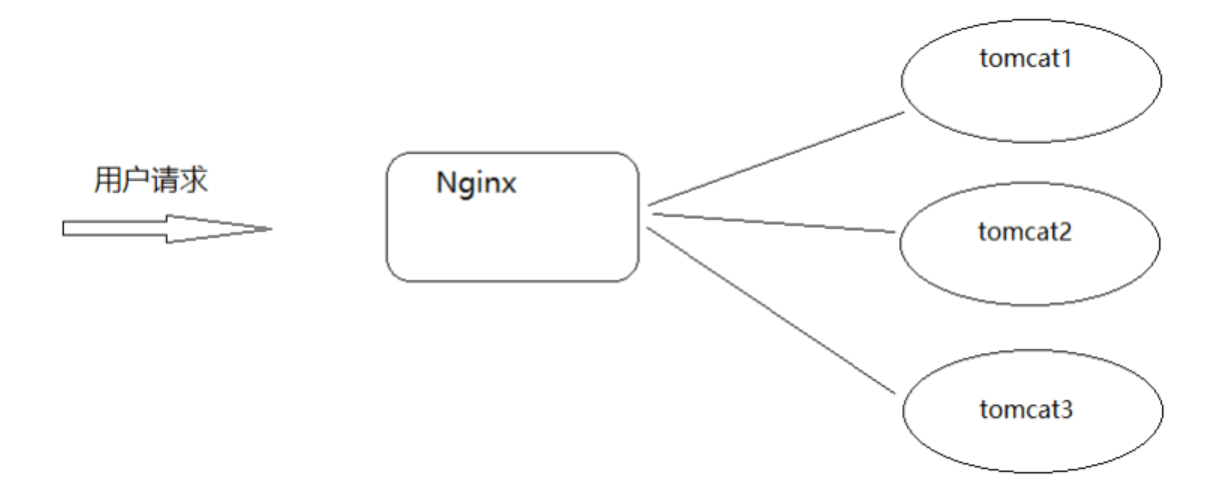
- 在使用Nginx和Tomcat部署项目的时候,我们使用的是一台Nginx服务器和一台Tomcat服务器,架构图如下

(2)集群模式
- 如果Tomcat宕机了,整个系统就无法正常运行,我们可以多搭建几台Tomcat服务器,其中一台宕机了,其他服务器还能继续运行,这也就是我们常说的集群,搭建Tomcat的集群需要用到了Nginx的反向代理和负载均衡知识,架构如下
(3)集群实现
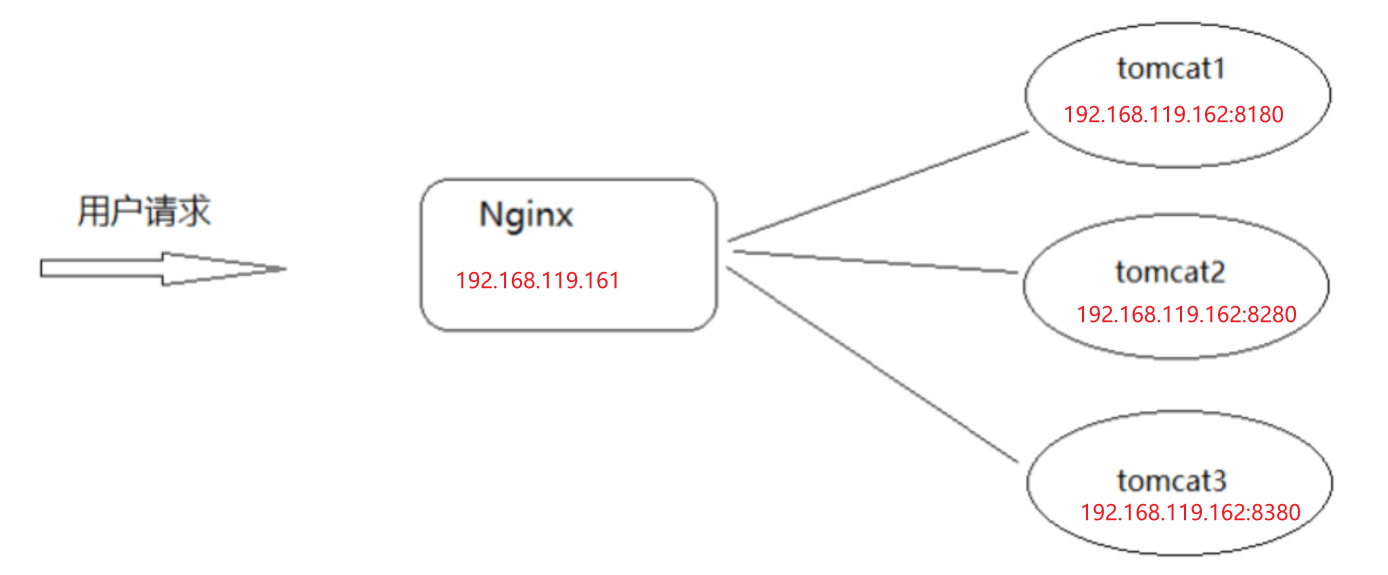
- 准备3台tomcat,使用端口进行区分[实际环境应该是三台服务器]。
cp -r /opt/apache-tomcat-9.0.96 /opt/tomcat01
cp -r /opt/apache-tomcat-9.0.96 /opt/tomcat02
cp -r /opt/apache-tomcat-9.0.96 /opt/tomcat03
- 修改三个 Tocmat 配置文件的端口,修改server.ml,将端口修改分别修改为8180,8280,8380。
vim /opt/tomcat01/conf/server.xml
vim /opt/tomcat02/conf/server.xml
vim /opt/tomcat03/conf/server.xml

- 在Nginx对应的配置文件中添加如下内容
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream webservice{
server 192.168.119.162:8180; # tomcat01
server 192.168.119.162:8280; # tomcat02
server 192.168.119.162:8380; # tomcat03
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://webservice;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
- 启动Tomcat
# 分别开不同窗口启动tomcat
/opt/tomcat01/bin/startup.sh
/opt/tomcat02/bin/startup.sh
/opt/tomcat03/bin/startup.sh
-
测试Tomcat
- 测试地址tomcat01:http://192.168.119.162:8180/
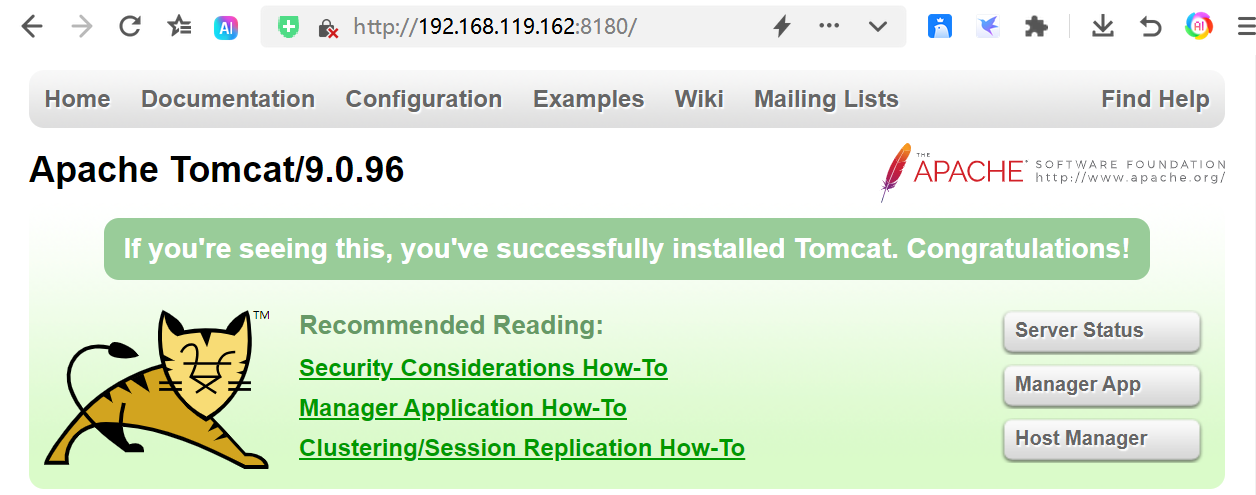
- 测试地址tomcat02:http://192.168.119.162:8280/
- 测试地址tomcat03:http://192.168.119.162:8380/
-
测试Nginx:访问地址http://192.168.119.161/
2、Nginx高可用解决方案
(1)概述
- 完成了上述环境的部署,我们已经解决了Tomcat的高可用性,一台服务器宕机,还有其他两台对外提供服务。
- 但是新问题出现了,上述环境中,如果是Nginx宕机了,那么整套系统都将服务对外提供服务了,所以我们需要两台以上Nginx服务器做集群。但是两台Nginx我们访问哪一台呢?下面我们来解决这个问题。
(2)Keepalived
-
Keepalived 软件由 C 编写的,最初是专为 LVS 负载均衡软件设计的,Keepalived 软件主要是通过 VRRP 协议实现高可用功能。
-
VRRP(Virtual Route Redundancy Protocol)协议,翻译过来为虚拟路由冗余协议。
-
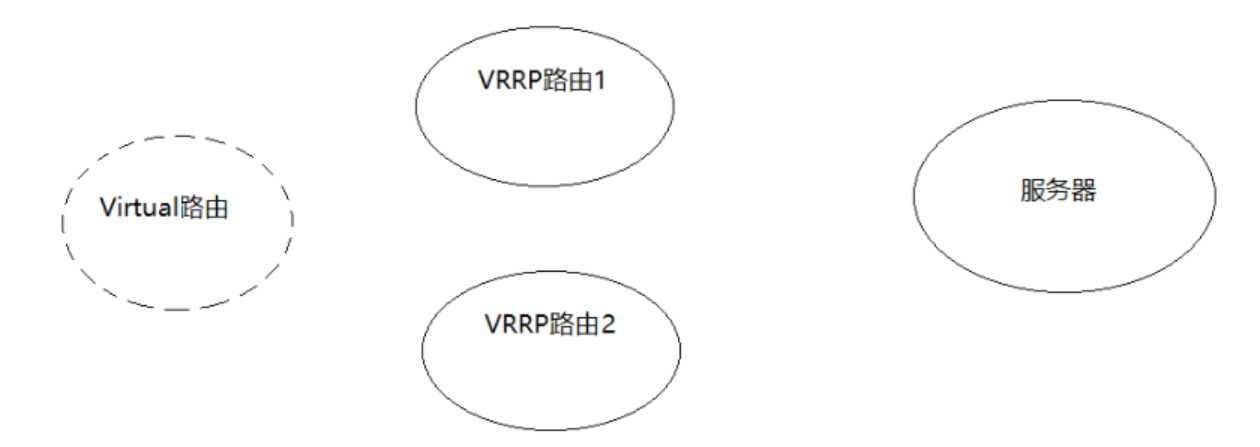
VRRP协议的作用
- 选择协议:VRRP可以把一个虚拟路由器的责任动态分配到局域网上的 VRRP 路由器中的一台。其中的虚拟路由即Virtual路由是由VRRP路由群组创建的一个不真实存在的路由,这个虚拟路由也是有对应的IP地址。而且VRRP路由1和VRRP路由2之间会有竞争选择,通过选择会产生一个Master路由和一个Backup路由。
- 路由容错协议:Master路由和Backup路由之间会有一个心跳检测,Master会定时告知Backup自己的状态,如果在指定的时间内,Backup没有接收到这个通知内容,Backup就会替代Master成为新的Master。Master路由有一个特权就是虚拟路由和后端服务器都是通过Master进行数据传递交互的,而备份节点则会直接丢弃这些请求和数据,不做处理,只是去监听Master的状态
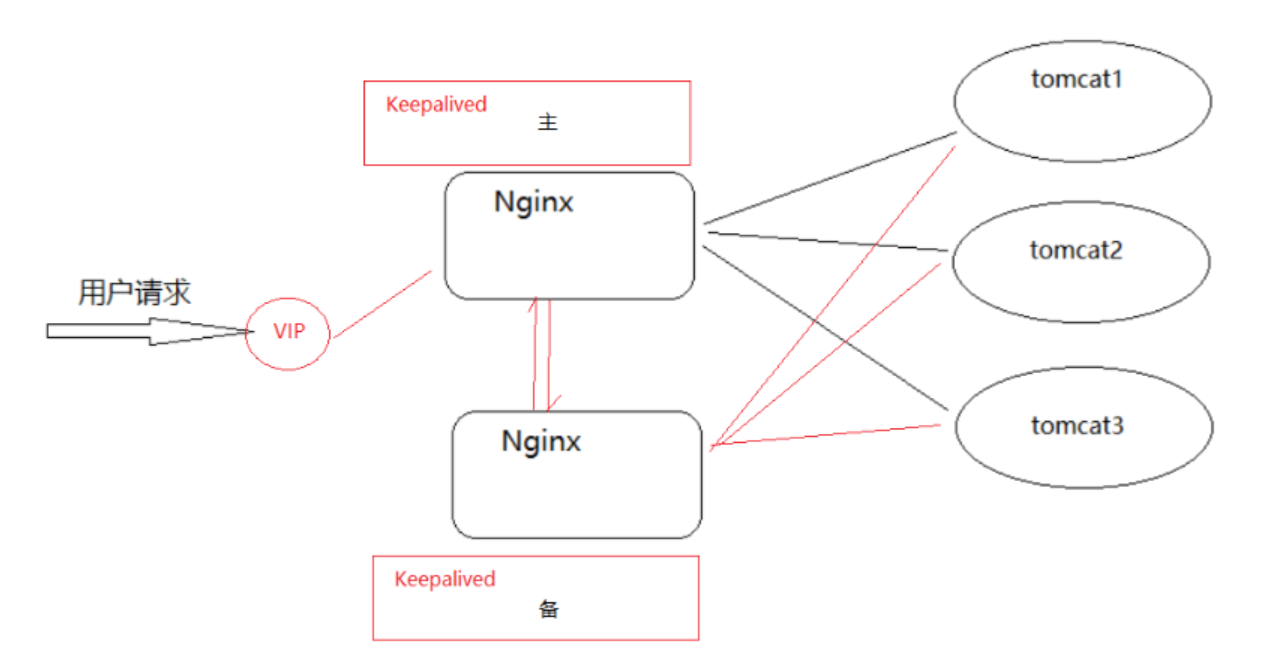
(3)Keepalived+Nginx架构图
- VIP 是虚拟路由,是专门给用户发送请求。一旦用户发送请求到 VIP,VIP 就会发送给 Master(主)的 Nginx,如果 Master(主)Nginx 宕机了,才会发送给 Backup(备份) Nginx 路由。
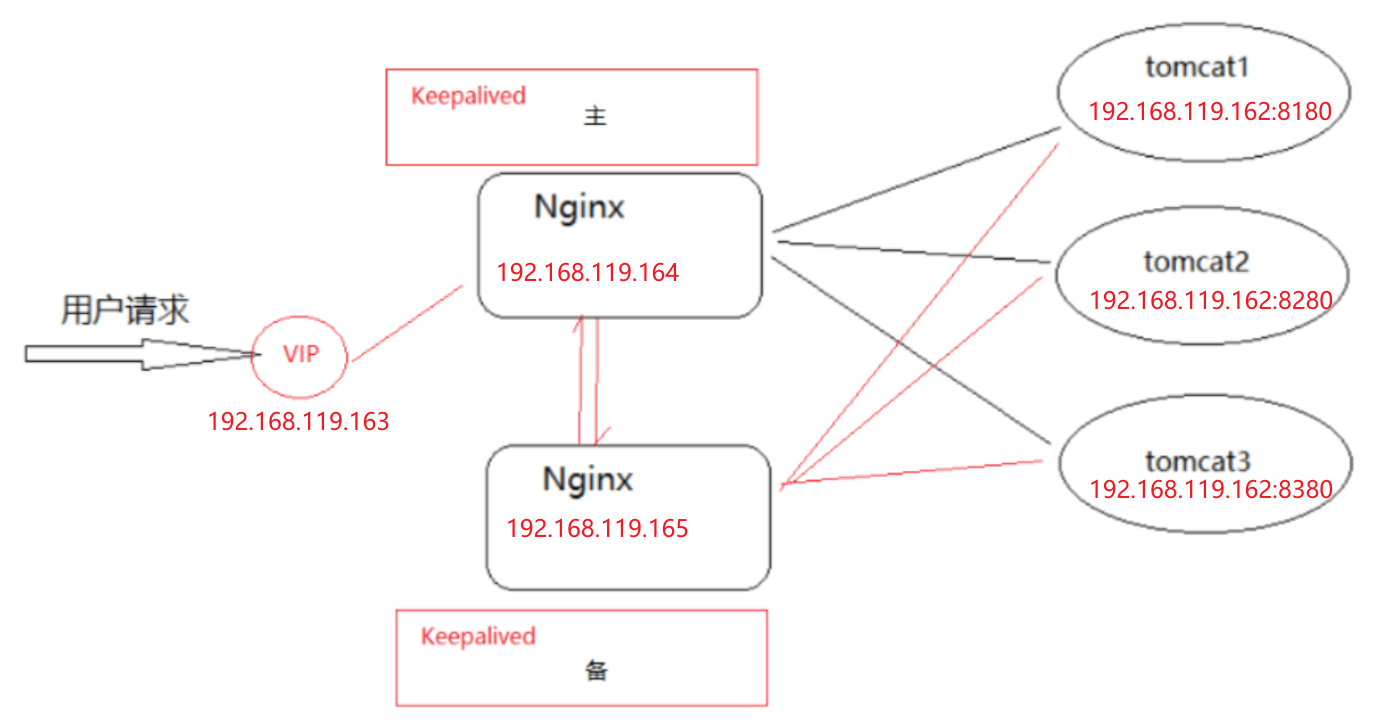
(4)环境搭建
- 环境准备
| IP | 主机名 | 主/从 |
|---|---|---|
| 192.168.119.163 | keepalivedvip | |
| 192.168.119.164(服务器A) | keepalived1 | Master |
| 192.168.119.165(服务器B) | keepalived2 | Backup |
-
Nginx:keepalived1+keepalived2安装,配置保持一致,安装参考Nginx在Linux下安装篇:https://blog.csdn.net/liyou123456789/article/details/142745399
-
keepalived:keepalived1+keepalived2安装
# 创建目录
mkdir /opt/keepalived
cd /opt/keepalived
# 官网地址:https://keepalived.org/
# 官网下载地址:https://keepalived.org/download.html
# 百度网盘地址:https://pan.baidu.com/s/1PHTVk4WhIJ_Pm-c89rY4jQ?pwd=1234
# 上传keepalived-2.0.20.tar.gz文件到/opt/keepalived目录
# 解压文件
tar -zxf keepalived-2.0.20.tar.gz -C /opt/keepalived
# 对 keepalived 进行配置,编译和安装
cd /opt/keepalived/keepalived-2.0.20
./configure --sysconf=/etc --prefix=/usr/local # 安装到 /usr/local 目录下,可修改
make && make install
/usr/local/sbin目录下的keepalived:这是系统配置脚本,用来启动和关闭 keepalived
(5)keepalived配置文件
-
配置文件路径/etc/keepalived/keepalived.conf
-
配置文件说明如下
- 第一部分是 global 全局配置
- 第二部分是 vrrp 相关配置:包含四个子模块
- vrrp_script
- vrrp_sync_group
- garp_group
- vrrp_instance
- 第三部分是 LVS 相关配置
-
这里需要修改的是 5、6、8 行代码。
# global全局部分
global_defs {
notification_email { # 通知邮件,当 keepalived 切换 Master 和 Backup 时需要发 email 给具体的邮箱地址
tom@test.com
jerry@test.com
}
notification_email_from test@test.com # 设置发件人的邮箱信息
smtp_server 192.168.119.1 # 指定 smpt 服务地址
smtp_connect_timeout 30 # 指定 smpt 服务连接超时时间
router_id LVS_DEVEL # 运行 keepalived 服务器的一个标识,可以用作发送邮件的主题信息
# 默认是不跳过检查。检查收到的 VRRP 通告中的所有地址可能会比较耗时,设置此命令的意思是,如果通告与接收的上一个通告来自相同的 master 路由器,则不执行检查(跳过检查)
vrrp_skip_check_adv_addr
vrrp_strict # 严格遵守 VRRP 协议
vrrp_garp_interval 0 # 在一个接口发送的两个免费 ARP 之间的延迟。可以精确到毫秒级。默认是 0
vrrp_gna_interval 0 # 在一个网卡上每组消息之间的延迟时间,默认为 0
}
- vrrp_instance 模块内容
- 第 3 行代码是说明当前 Nginx 服务器的角色是 Master 还是 Backup。分别在服务器 A 和 B 进行角色配置。
- 第 5 行代码是 VIP 的 ID,如果使用相同的虚拟路由 VIP,请保持 ID 一致。
- 第 6 行代码是优先级,请让 Master 服务器的优先级大于 Backup 服务器的优先级。如 100 > 90。
- 第 7 行代码是 Master 和 Backup 之间通信的间隔时间,如果无法通信,说明 Master 已经宕机,则切换为 Backup。
- 第 13 行代码是用户访问的虚拟 IP 地址,即 VIP,它会发送给 Nginx 服务器。
vrrp_instance模块中我们修改的是第 3、5、6、7、13 行代码。
# 设置 keepalived 实例的相关信息,VI_1 为 VRRP 实例名称
vrrp_instance VI_1 {
state MASTER # 有两个值可选 MASTER 主,BACKUP 备
interface ens33 # vrrp 实例绑定的接口,用于发送 VRRP 包[当前服务器使用的网卡名称]
virtual_router_id 51 # 指定 VRRP 实例 ID,范围是 0-255
priority 100 # 指定优先级,优先级高的将成为 MASTER
advert_int 1 # 指定发送 VRRP 通告的间隔,单位是秒。这里是心跳检查的时间
authentication { # vrrp 之间通信的认证信息
auth_type PASS # 指定认证方式。PASS 简单密码认证(推荐)
auth_pass 1111 # 指定认证使用的密码,最多 8 位
}
virtual_ipaddress { # 虚拟 IP 地址设置虚拟 IP 地址,供用户访问使用,可设置多个,一行一个
192.168.119.163
}
}
- 服务器A的Keepalived 的具体配置内容如下:
! Configuration File for keepalived
global_defs {
notification_email {
Tom@test.com
}
notification_email_from test@test.com
smtp_server 192.168.119.1
smtp_connect_timeout 30
router_id keepalived1
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.119.163
}
}
...
- 服务器B的Keepalived 的具体配置内容如下:
! Configuration File for keepalived
global_defs {
notification_email {
Tom@test.com
}
notification_email_from Tom@test.com
smtp_server 192.168.119.1
smtp_connect_timeout 30
router_id keepalived2
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.119.163
}
}
(6)测试访问
- 启动keepalived之前,咱们先使用命令
ip a,查看服务器A(MASTER)和服务器B(BACKUP)这两台服务器的IP情况。
# 服务器A
[root@localhost keepalived]# ip a
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:1d:94:ff brd ff:ff:ff:ff:ff:ff
inet 192.168.119.164/24 brd 192.168.119.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::7f3d:1c1c:b384:df37/64 scope link noprefixroute
valid_lft forever preferred_lft forever
# 服务器B
[root@localhost keepalived]# ip a
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:75:69:c4 brd ff:ff:ff:ff:ff:ff
inet 192.168.119.165/24 brd 192.168.119.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::7f3d:1c1c:b384:df37/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::8bc6:fc3c:4e91:dddf/64 scope link noprefixroute
valid_lft forever preferred_lft forever
- 分别启动两台服务器的keepalived
cd /usr/local/sbin
./keepalived
- 再次通过
ip a查看ip,服务器A(MASTER)多出来一个192.168.119.163,服务器B(BACKUP)和之前一样没变化
# 服务器A
[root@localhost sbin]# ip a
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:1d:94:ff brd ff:ff:ff:ff:ff:ff
inet 192.168.119.164/24 brd 192.168.119.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.119.163/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::7f3d:1c1c:b384:df37/64 scope link noprefixroute
valid_lft forever preferred_lft forever
# 服务器B
[root@localhost sbin]# ip a
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:75:69:c4 brd ff:ff:ff:ff:ff:ff
inet 192.168.119.165/24 brd 192.168.119.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::7f3d:1c1c:b384:df37/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::8bc6:fc3c:4e91:dddf/64 scope link noprefixroute
valid_lft forever preferred_lft forever
- 服务器A(MASTER)关闭keepalived
# 服务器A
[root@localhost sbin]# ps -ef|grep keepalived
root 112299 1 0 20:48 ? 00:00:00 ./keepalived
root 112300 112299 0 20:48 ? 00:00:00 ./keepalived
root 112301 112299 0 20:48 ? 00:00:00 ./keepalived
root 125002 2471 0 21:03 pts/2 00:00:00 grep --color=auto keepalived
[root@localhost sbin]# kill -9 112299
[root@localhost sbin]# ps -ef|grep keepalived
root 125277 2471 0 21:03 pts/2 00:00:00 grep --color=auto keepalived
- 再次通过
ip a查看ip,服务器A(MASTER)的192.168.119.163没有了,转移到了服务器B(BACKUP)上
# 服务器A
[root@localhost sbin]# ip a
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:1d:94:ff brd ff:ff:ff:ff:ff:ff
inet 192.168.119.164/24 brd 192.168.119.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::7f3d:1c1c:b384:df37/64 scope link noprefixroute
valid_lft forever preferred_lft forever
# 服务器B
[root@localhost sbin]# ip a
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:75:69:c4 brd ff:ff:ff:ff:ff:ff
inet 192.168.119.165/24 brd 192.168.119.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.119.163/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::7f3d:1c1c:b384:df37/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::8bc6:fc3c:4e91:dddf/64 scope link noprefixroute
valid_lft forever preferred_lft forever
- 通过上述的测试,我们会发现,虚拟IP(VIP)会在MASTER节点上,当MASTER节点上的keepalived出问题以后,因为BACKUP无法收到MASTER发出的VRRP状态通过信息,就会直接升为MASTER。VIP也会"漂移"到新的MASTER。
- 我们把服务器A的keepalived再次启动下,由于它的优先级高于服务器B的,所有它会再次成为MASTER,VIP也会"漂移"回去。
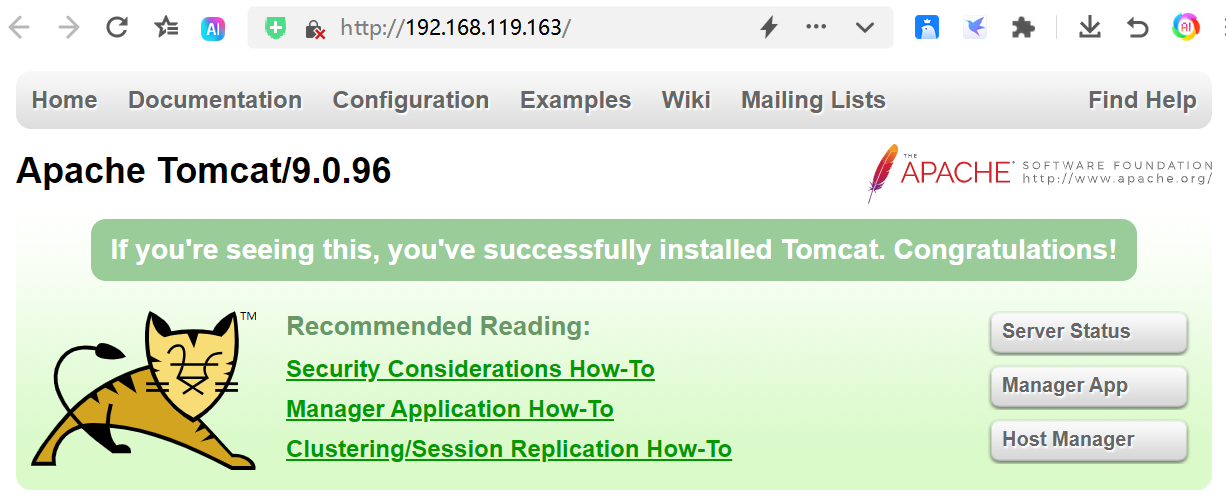
- 我们现在访问虚拟服务器http://192.168.119.163/,页面显示成功
(7)vrrp_script
- keepalived只能做到对网络故障和keepalived本身的监控,即当出现网络故障或者keepalived本身出现问题时,进行自动切换。
- 但是这些还不够,我们还需要监控keepalived所在服务器上的其他业务,比如Nginx,如果Nginx出现异常了,仅仅keepalived保持正常,是无法完成系统的正常工作的,因此需要根据业务进程的运行状态决定是否需要进行主备切换,这个时候,我们可以通过编写脚本对业务进程进行检测监控。
- 需要在keepalived配置文件中添加对应的配置内容
vrrp_script 脚本名称
{
script "脚本位置"
interval 3 #执行时间间隔
weight -20 #动态调整vrrp_instance的优先级
}
-
实现步骤
- 在服务器A,编写脚本,这里的脚本名是
ck_nginx.sh,位置在/etc/keepalived路径下。- ps 命令用于显示当前进程 (process) 的状态。
- -C(command):指定命令的所有进程。
- –no-header:排除标题。
#!/bin/bash # 使用 ps 命令查询 nginx 进程数,并通过 wc -l 统计行数 num=$(ps -C nginx --no-header | wc -l) # 查询 Nginx 的进程数 # 检查 Nginx 的进程数是否等于 0 if [ "$num" -eq 0 ]; then echo "Nginx process is not running. Attempting to stop keepalived." # 尝试杀死所有 keepalived 进程 killall keepalived # 检查 killall 命令是否执行成功 if [ $? -eq 0 ]; then echo "Successfully stopped keepalived." else echo "Failed to stop keepalived. Please check permissions or if keepalived is running." fi else echo "Nginx is running with $num processes." fi- 为脚本文件设置权限
chmod 755 /etc/keepalived/ck_nginx.sh- 配置文件添加vrrp_script,下面的vrrp_instance中加上track_script
vrrp_script ck_nginx { script "/etc/keepalived/ck_nginx.sh" # 执行脚本的位置 interval 2 # 执行脚本的周期,秒为单位 weight -20 # 权重的计算方式 } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 10 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.200.111 } track_script { ck_nginx } }- 配置文件修改完成后重新启动keepalived,把nginx关闭,再看keepalived,已经自动关闭
[root@localhost keepalived]# cd /usr/local/sbin [root@localhost sbin]# ps -ef|grep nginx root 88865 1 0 21:47 ? 00:00:00 nginx: master process nginx nobody 88866 88865 0 21:47 ? 00:00:00 nginx: worker process root 88907 2085 0 21:47 pts/0 00:00:00 grep --color=auto nginx [root@localhost sbin]# ps -ef|grep keepalived root 86830 1 0 21:45 ? 00:00:00 ./keepalived root 86831 86830 0 21:45 ? 00:00:00 ./keepalived root 86832 86830 0 21:45 ? 00:00:00 ./keepalived root 89054 2085 0 21:47 pts/0 00:00:00 grep --color=auto keepalived [root@localhost sbin]# kill -9 86830 [root@localhost sbin]# ps -ef|grep keepalived root 89378 2085 0 21:47 pts/0 00:00:00 grep --color=auto keepalived [root@localhost sbin]# ./keepalived [root@localhost sbin]# ps -ef|grep keepalived root 89465 1 0 21:48 ? 00:00:00 ./keepalived root 89466 89465 0 21:48 ? 00:00:00 ./keepalived root 89467 89465 0 21:48 ? 00:00:00 ./keepalived root 89543 2085 0 21:48 pts/0 00:00:00 grep --color=auto keepalived [root@localhost sbin]# nginx -s stop [root@localhost sbin]# ps -ef|grep keepalived root 89819 2085 0 21:48 pts/0 00:00:00 grep --color=auto keepalived- MASTER转移到服务器B
# 服务器A [root@localhost sbin]# ip a 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:1d:94:ff brd ff:ff:ff:ff:ff:ff inet 192.168.119.164/24 brd 192.168.119.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet6 fe80::7f3d:1c1c:b384:df37/64 scope link noprefixroute valid_lft forever preferred_lft forever # 服务器B [root@localhost keepalived]# ip a 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:75:69:c4 brd ff:ff:ff:ff:ff:ff inet 192.168.119.165/24 brd 192.168.119.255 scope global noprefixroute ens33 valid_lft forever preferred_lft forever inet 192.168.119.163/32 scope global ens33 valid_lft forever preferred_lft forever inet6 fe80::7f3d:1c1c:b384:df37/64 scope link tentative noprefixroute dadfailed valid_lft forever preferred_lft forever inet6 fe80::8bc6:fc3c:4e91:dddf/64 scope link noprefixroute valid_lft forever preferred_lft forever- 如果效果没有出来,可以使用
tail -f /var/log/messages查看日志信息,找对应的错误信息进行调试
- 在服务器A,编写脚本,这里的脚本名是





![[PHP]Undefined index错误只针对数组](https://i-blog.csdnimg.cn/direct/71d1ed2906c6465f90d6ceb7dd09b5f2.png)