学习视频:b站链接
项目链接
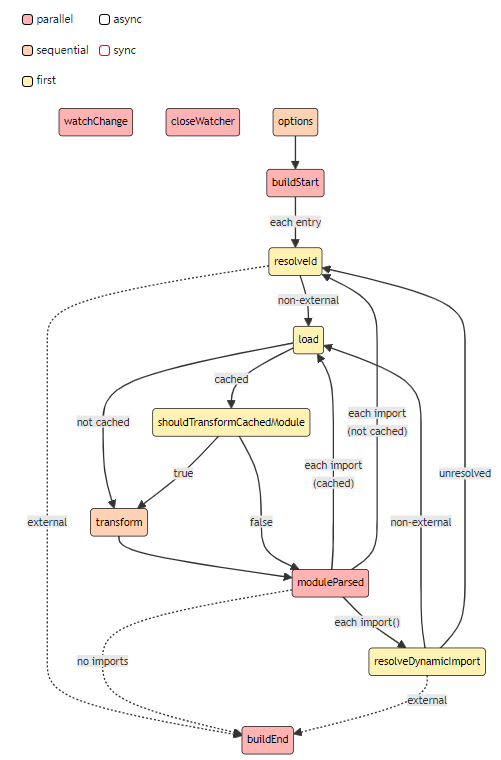
GraphRAG 的基本概念
-
Document(文档):系统中的输入文档。这些文档要么代表CSV中的单独行,要么代表单独的txt文件。
-
TextUnit(文本块):要分析的文本块。这些块的大小、重量以及它们是否遵守任何数据边界可以在下面配置。一个常见的用例是设置
CHUNK_BY_COLUMNS为 id,以便文档和TextUnits之间存在一对多关系,而不是多对多关系。 -
Entity(实体):从TextUnit中提取的实体。这些实体代表人物、地点、事件或您提供的其他实体模型。
-
Relationship(关系):两个实体之间的关系。这些关系由协变量生成。
-
Covariate(协变量):提取的声明信息,其中包含可能受时间限制的实体的陈述。
-
Claim(声明):代表具有评估状态和时间限制的积极事实陈述,以协变量(Covariates)的称呼在各处使用。
-
Community Report(社区报告):一旦生成实体,我们就对它们执行层次社区检测,并为该层次结构中的每个社区生成报告。
-
Node(节点):包含已被聚集的实体和文档的呈现图形视图的布局信息。
总体流程:

文档转换为 TextUnits
说明:
- 概念 -> 追溯原文
- 文档和文本单元之间存在严格的一对多关系

切换技巧:
- 切换大小 chunk size: 1200 token
- 较大的块会导致输出保真度较低,参考文本意义较小;使用较大的块可以大大缩短处理时间。
图表:
- 图表显示不同
chunk size和gleanings的数量对实体引用检测的影响。 - 600 token、1200 token、2400 token 的 chunk size 对比。

图提取
功能:
分析每个文本单元并提取图形基元:实体、关系和声明
实体和关系提取:
- 使用 LLM 从原始文本中提取实体和关系,包含具有名称、类型和描述的实体列表,以及具有源、目标和描述的关系列表。
实体和关系摘要:
- 通过 LLM 为每个实体和关系提供简短的摘要描述。
Claim Extraction & Emission:
- 声明代表具有评估状态和时间限制的积极事实陈述,以协变量(Covariates)的称呼在各处使用。

图增强(构建社区)
社区检测:
- 使用分层莱顿算法生成实体社区的层次结构,此方法将对我们的图应用递归社区聚类,直到达到社区规模阈值。
- 这将使我们能够了解图的社区结构,并提供一种在不同粒度级别上导航和总结图的方法。
图嵌入:
- 使用 Node2Vec 算法生成图的向量表示。
- 这将使我们能够理解图的隐式结构,并提供额外的向量空间,以便在查询阶段搜索相关概念。

社区总结
功能:
基于社区数据并为每个社区生成报告,这让我们可以从多个粒度点对图表有一个高层次的了解。例如,如果社区 A 是顶级社区,我们将获得有关整个图表的报告。如果社区是较低级别的,我们将获得有关地集群的报告。
生成社区报告:
使用 LLM 生成每个社区的摘要,引用社区子结构中的关键实体、关系和声明。
总结社区报告:
每个社区报告都会通过 LLM 进行总结,以供速记使用。
社区嵌入:
通过生成社区报告、社区报告摘要和社区报告标题的文本嵌入来生成我们的社区的向量表示。

文档处理
链接到 TextUnits:
将每个文档链接到第一阶段创建的文本单元,了解哪些文档与哪些文本单元相关。
文档嵌入:
文档切片的平均嵌入来生成文档的向量表示,能够理解文档之间的隐式关系。

local查询

Local 查询流程
流程描述:
- 用户查询(User Query):用户输入查询,进入流程的起点。
- 提取实体(Extracted Entities):从用户查询中提取出实体,包括实体描述和嵌入信息。
- 候选文本单元(Candidate Text Units):通过实体和文本单元的映射,生成候选文本单元。
- 候选社区报告(Candidate Community Reports):通过实体和社区报告的映射,生成候选社区报告。
- 候选实体(Candidate Entities):通过实体-实体关系映射,生成候选实体。
- 候选关系(Candidate Relationships):通过实体-实体关系映射,生成候选关系。
- 候选协变量(Candidate Covariates):通过实体-协变量映射,生成候选协变量。
排序和过滤:
每个候选单元经过排序与过滤(Ranking + Filtering),并输出优先级结果,包括:
- 优先级文本单元(Prioritized Text Units)
- 优先级社区报告(Prioritized Community Reports)
- 优先级实体(Prioritized Entities)
- 优先级关系(Prioritized Relationships)
- 优先级协变量(Prioritized Covariates)
响应(Response):
最终将所有优先级结果汇总,并生成响应(Response),提供给用户。
会话历史(Conversation History):
会话历史用来记录并辅助当前查询的处理,确保连续性和上下文的完整性。
Global查询流程
Global 查询流程
流程描述:
- 用户查询(User Query):用户输入查询,作为流程的起点。
- 会话历史(Conversation History):通过会话历史确保查询的上下文完整性。
- 社区报告批次(Shuffled Community Report Batch):将用户查询分配给不同的社区报告批次进行处理。每个批次会被洗牌处理,以确保多样性。
- Batch 1:第一批社区报告
- Batch 2:第二批社区报告
- Batch N:第N批社区报告
- 中间响应评分(Rated Intermediate Responses, RIR):每个社区报告批次会生成中间响应,并对其进行评分。
- 排序与过滤(Ranking + Filtering):对中间响应的评分结果进行排序与过滤,保留最佳结果。
- 聚合中间响应(Aggregated Intermediate Responses):将所有评分较高的中间响应聚合在一起,作为最终输出。
- 最终响应(Response):将聚合的结果返回给用户,作为最终的查询响应。