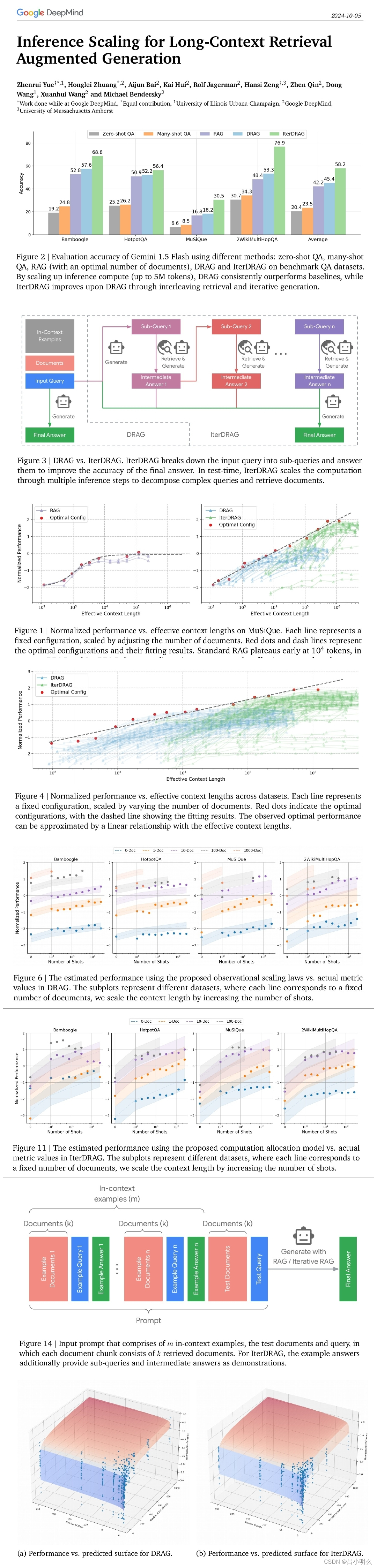
稳定性
在排序算法中,稳定性是一个重要的概念,指的是在排序过程中,如果两个元素的值相等,它们在排序后的相对位置与排序前的相对位置保持不变的特性。
稳定排序与不稳定排序
-
稳定排序:在排序时,相等的元素的相对顺序不会改变。例如,在对一组学生按成绩排序时,如果两个学生的成绩相同,它们在排序后的顺序与原来顺序相同(例如,原来是学生 A 和 B,排序后仍然是 A 和 B)。
-
不稳定排序:在排序时,相等的元素的相对顺序可能会改变。例如,如果两个成绩相同的学生在排序后顺序发生变化,则该排序算法是不稳定的。
稳定性的重要性
稳定性在某些情况下非常重要,特别是当需要多次排序时。例如,如果你首先按姓氏排序,然后按名字排序,稳定排序可以确保在按名字排序时,同一姓氏的人的顺序不会被打乱。
稳定排序算法
- 插入排序:稳定。
- 归并排序:稳定。
- 冒泡排序:稳定。
- 计数排序:稳定。
- 基数排序:稳定。
不稳定排序算法
- 快速排序:通常是不稳定的。
- 选择排序:不稳定。
- 堆排序:不稳定。

名词解释:
- n:数据规模
- k:"桶"的个数
- In-place:占用常数内存,不占用额外内存
- Out-place:占用额外内存
冒泡排序(Bubble Sort)
冒泡排序(Bubble Sort)是一种简单的排序算法,它通过重复比较相邻的元素并交换它们的顺序,直到整个数组有序。
工作原理
- 比较相邻元素:从数组的开始位置开始,比较相邻的两个元素。
- 交换:如果第一个元素大/小于第二个元素(对于升/降序排序),则交换这两个元素。
- 重复:继续向数组的末尾移动,重复步骤 1 和 2,直到最后一个元素。
- 多轮比较:每完成一轮操作,最大/小元素就“冒泡”到数组的末尾。重复这个过程,直到没有需要交换的元素为止。

总轮数
冒泡排序需要进行 n-1 轮比较,其中 n 是待排序数组的元素个数。
每轮比较次数
- 第一轮:比较 n−1 次
- 第二轮:比较 n−2 次
- 第三轮:比较 n−3 次
- ...
- 第 i 轮:比较 n−i 次
- 第 n−1 轮:比较 1 次
轮数与总比较次数
在最坏情况下(如逆序排列),总比较次数为:
(n−1)+(n−2)+(n−3)+…+1 =
这个公式是等差数列求和公式的结果。
时间复杂度
- 最坏情况:O(n^2)
- 最好情况:如果数组已经是有序的,冒泡排序只需要进行 n−1 次比较,判断第一轮为有序则终止排序,时间复杂度为 O(n)。
- 平均情况:仍然是 O(n^2)。
空间复杂度
冒泡排序是原地排序算法,空间复杂度为 O(1)。
冒泡排序的稳定性
冒泡排序是一种稳定的排序算法。在冒泡排序中,当相邻的两个元素相等时,算法不会改变它们的相对顺序,因为只有在第一个元素大于第二个元素时才会进行交换。因此,相等元素的相对位置在排序后保持不变。
优缺点
优点
- 简单易懂,易于实现。
- 不需要额外的存储空间(原地排序)。
缺点
- 效率较低,不适合大规模数据排序。
- 时间复杂度高,尤其是在数据量大的情况下。
冒泡排序 C 语言实现
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
// 随机生成数组函数
int* Generate_Random_Array(int n, int min, int max)
{
int f = -1;
if (min < 0)
f = 1;
int* array = (int*)malloc(n * sizeof(int)); // 动态分配内存
if (array == NULL)
exit(-1);
for (int i = 0; i < n; i++)
{
array[i] = min + rand() % (max + f * min + 1);// 生成 min 到 max 之间的随机数
}
return array;
}
// 复制数组函数
int* Copy_Array(int* source, int n)
{
int* copy = (int*)malloc(n * sizeof(int));
if (copy == NULL)
exit(-1);
for (int i = 0; i < n; i++)
{
copy[i] = source[i];
}
return copy;
}
// 排序计时函数
void SortTime(void(*p)(int*, int, int), int* arr, int n, int isAscending)
{
// 记录开始时间
clock_t start = clock();
p(arr, n, isAscending);//调用排序函数
// 记录结束时间
clock_t end = clock();
// 计算并打印排序时间
double time_taken = (double)(end - start) / CLOCKS_PER_SEC;
printf("排序所需时间: %f 秒\n", time_taken);
}
// 打印数组的函数
void print(int* p, int n)
{
for (int i = 0; i < n; ++i) // 遍历数组
{
printf("%d ", p[i]);
}
printf("\n");
}
// 冒泡排序函数最初版
void Bubble_Sort1(int* p, int n, int isAscending)
{
// 外层循环,控制总轮数
for (int i = n - 1; i > 0; --i)
{
// 内层循环,进行相邻元素比较和交换
for (int j = 0; j < i; ++j)
{
// 根据升序或降序规则进行比较
if ((p[j] > p[j + 1] && isAscending) || (p[j] < p[j + 1] && !isAscending))
{
// 交换元素
int tmp = p[j];
p[j] = p[j + 1];
p[j + 1] = tmp;
}
}
}
}
// 冒泡排序函数优化版(增加isSorted标志位,用于判断每轮循环后是否有序,避免已经有序还在排序的情况,减少了比较次数)
void Bubble_Sort2(int* p, int n, int isAscending)
{
// 外层循环,控制总轮数
for (int i = n - 1; i > 0; --i)
{
int isSorted = 1;//重置有序标志
// 内层循环,进行相邻元素比较和交换
for (int j = 0; j < i; ++j)
{
// 根据升序或降序规则进行比较
if ((p[j] > p[j + 1] && isAscending) || (p[j] < p[j + 1] && !isAscending))
{
// 交换元素
int tmp = p[j];
p[j] = p[j + 1];
p[j + 1] = tmp;
isSorted = 0; //无序标志
}
}
// 如果一轮中没有发生交换,说明数组已经有序,提前退出
if (isSorted)
break;
}
}
// 冒泡排序函数最优版(增加了SortInidex用于记录序列尾部局部有序时最后一次交换的位置,通过赋值给i改变循环的轮数,减少了比较次数)
void Bubble_Sort3(int* p, int n, int isAscending)
{
// 外层循环,控制总轮数
for (int i = n - 1; i > 0; --i)
{
int SortInidex = 0;//该初始值是为数组完全有序时循环提前退出准备的(该值小于等于0时在外层循环判断为false)
// 内层循环,进行相邻元素比较和交换
for (int j = 0; j < i; ++j)
{
// 根据升序或降序规则进行比较
if ((p[j] > p[j + 1] && isAscending) || (p[j] < p[j + 1] && !isAscending))
{
// 交换元素
int tmp = p[j];
p[j] = p[j + 1];
p[j + 1] = tmp;
SortInidex = j + 1;// 记录最后一次交换的位置
}
}
// 更新 i 为最后一次交换的位置,以缩小未排序的范围
// 这意味着在此位置之后的元素已排序
i = SortInidex;
}
}
// 冒泡排序函数改良版鸡尾酒排序
void Cocktail_Sort(int* p, int n, int isAscending)
{
// 交换临时变量
int tmp = 0;
// 无序数列的左边界
int leftBorder = 0;
// 无序数列的右边界
int rightBorder = n - 1;
// 外层循环,控制排序的轮数
for (int i = 0; i < n / 2; i++)
{
// 记录右侧最后一次交换的位置
int lastRightExchange = leftBorder; // 初始值设为左边界
// 奇数轮,从左向右比较和交换
for (int j = leftBorder; j < rightBorder; j++)
{
// 根据升序或降序规则进行比较
if ((p[j] > p[j + 1] && isAscending) || (p[j] < p[j + 1] && !isAscending))
{
// 交换元素
tmp = p[j];
p[j] = p[j + 1];
p[j + 1] = tmp;
// 记录最后一次交换的位置
lastRightExchange = j;
}
}
// 更新右边界为最后一次交换的位置
rightBorder = lastRightExchange;
// 记录左侧最后一次交换的位置
int lastLeftExchange = n; // 初始值设为 n,表示未发生交换
// 偶数轮,从右向左比较和交换
for (int j = rightBorder; j > leftBorder; j--)
{
// 根据升序或降序规则进行比较
if ((p[j] < p[j - 1] && isAscending) || (p[j] > p[j - 1] && !isAscending))
{
// 交换元素
tmp = p[j];
p[j] = p[j - 1];
p[j - 1] = tmp;
// 记录最后一次交换的位置
lastLeftExchange = j;
}
}
// 更新左边界为最后一次交换的位置
leftBorder = lastLeftExchange;
}
}
// 主函数
int main()
{
//排序函数测试
int num = 20;
int* p = Generate_Random_Array(num, -9, 100);
printf("原数组:");
print(p, num);
Bubble_Sort1(p, num, 1);
printf("Bubble_Sort1升序:");
print(p, num);
Bubble_Sort1(p, num, 0);
printf("Bubble_Sort1降序:");
print(p, num);
Bubble_Sort2(p, num, 1);
printf("Bubble_Sort2升序:");
print(p, num);
Bubble_Sort2(p, num, 0);
printf("Bubble_Sort2降序:");
print(p, num);
Bubble_Sort3(p, num, 1);
printf("Bubble_Sort3升序:");
print(p, num);
Bubble_Sort3(p, num, 0);
printf("Bubble_Sort3降序:");
print(p, num);
Cocktail_Sort(p, num, 1);
printf("Cocktail_Sort升序:");
print(p, num);
Cocktail_Sort(p, num, 0);
printf("Cocktail_Sort降序:");
print(p, num);
//排序时间测试
int n = 20000;
printf("\n\n排序时间测试,排序个数:%d\n", n);
int* arr = Generate_Random_Array(n, -100, 100000);
int* arr1 = Copy_Array(arr, n);
int* arr2 = Copy_Array(arr, n);
int* arr3 = Copy_Array(arr, n);
int* arr4 = Copy_Array(arr, n);
printf("Bubble_Sort1");
SortTime(Bubble_Sort1, arr1, n, 1);
printf("Bubble_Sort2");
SortTime(Bubble_Sort2, arr2, n, 1);
printf("Bubble_Sort3");
SortTime(Bubble_Sort3, arr3, n, 1);
printf("Cocktail_Sort");
SortTime(Cocktail_Sort, arr4, n, 1);
// 释放动态分配的内存
free(arr);
free(arr1);
free(arr2);
free(arr3);
free(arr4);
return 0;
}鸡尾酒排序 (Cocktail Sort)

-
基本原理:
- 鸡尾酒排序是冒泡排序的变种,采用双向遍历方法。
- 它在每一轮中先从左到右排序,然后再从右到左排序。
-
遍历方向:
- 具有双向遍历:第一部分是从左到右,第二部分是从右到左,这样可以在每一轮中同时将最小和最大元素移动到各自的边界。
-
效率:
- 在最坏和平均情况下的时间复杂度也是 O(n²),但由于双向遍历,它在某些情况下可能会比简单的冒泡排序更快,尤其是在数据已经部分有序的情况下。
总结
- 遍历方向:冒泡排序单向遍历,而鸡尾酒排序双向遍历。
- 性能:鸡尾酒排序在某些情况下比冒泡排序更高效,尤其是在处理部分有序的列表时。
- 实现复杂性:鸡尾酒排序的实现略复杂,因为需要处理两个方向的遍历。
选择排序 (Selection Sort)
选择排序是一种简单的排序算法,它通过不断选择未排序部分中的最小(或最大)元素,并将其放到已排序部分的末尾,最终实现整个数组的排序。
工作原理
- 选择最小/大元素:从未排序的部分中找到最小/大元素。
- 交换:将找到的最小/大元素与未排序部分的第一个元素交换。
- 更新边界:已排序部分的边界向右移动一位,未排序部分的大小减小。
- 重复:继续对未排序部分重复上述步骤,直到没有未排序的元素。

总轮数
选择排序需要进行 n-1 轮比较,其中 n 是待排序数组的元素个数。
每轮比较次数
- 第一轮:比较 n−1 次
- 第二轮:比较 n−2 次
- 第三轮:比较 n−3 次
- ...
- 第 i 轮:比较 n−i 次
- 第 n−1 轮:比较 1 次
轮数与总比较次数
选择排序的总比较次数为:
(n−1)+(n−2)+(n−3)+…+1 =
这个公式是等差数列求和公式的结果。
时间复杂度
- 最坏情况:O(n²)
- 最好情况:O(n²)(选择排序不受初始数据顺序影响,始终进行相同的比较次数)
- 平均情况:O(n²)
空间复杂度
选择排序是原地排序算法,空间复杂度为 O(1)。
选择排序的稳定性
选择排序是一种不稳定的排序算法。在选择最小元素的过程中,相等元素的相对顺序可能会改变,因为最小元素的交换可能会导致相等元素的顺序发生变化。
优缺点
优点
- 实现简单,易于理解。
- 不需要额外的存储空间(原地排序)。
缺点
- 效率较低,不适合大规模数据排序。
- 时间复杂度较高,尤其是在数据量大的情况下。
选择与冒泡比较与交换次数
- 选择排序:
- 每一轮都会进行 n-1 次比较,但只进行一次交换(如果需要交换的话)。因此,选择排序的交换次数相对较少。
- 冒泡排序:
- 每一轮都需要进行多次交换,尤其是在逆序排列的情况下,交换次数会显著增加。
实际性能
- 选择排序通常比冒泡排序稍快,尤其是在交换操作较昂贵的情况下,因为选择排序每轮只进行一次交换。
- 冒泡排序在已经部分有序的情况下表现较好(可以提前终止),但在大多数情况下仍然较慢。
总结
在一般情况下,选择排序的效率通常会优于冒泡排序,尤其是在需要减少交换次数时。然而,在大规模数据排序时,这两种算法都不是最佳选择,更高效的排序算法(如快速排序、归并排序或堆排序)更为适合。
双向选择排序(Bidirectional Selection Sort)
双向选择排序是一种改进的选择排序,它在每一轮中同时选择未排序部分的最小和最大元素。这种方法可以减少排序所需的总轮数。
双向选择排序其基本思想是同时在未排序部分找到最小和最大元素,并将它们放置到已排序部分的两端。
基本思想
-
分区:
- 将数组分为已排序部分和未排序部分。初始时,已排序部分为空,未排序部分为整个数组。
-
同时选择:
- 在未排序部分中同时寻找最小值和最大值。
- 找到后,将最小值放到未排序部分的起始位置(已排序部分的末尾),最大值放到未排序部分的末尾。
具体过程
假设我们有一个数组 arr = {5, 3, 8, 6, 2},我们想要进行升序排序:
-
第一次选择:
- 在未排序部分
{5, 3, 8, 6, 2}中找到最小值2和最大值8。 - 将
2放到数组的开头,将8放到数组的末尾。 - 结果:
{2, 3, 6, 5, 8}(已排序部分为{2},未排序部分为{3, 6, 5})。
- 在未排序部分
-
第二次选择:
- 在未排序部分
{3, 6, 5}中找到最小值3和最大值6。 - 将
3放到已排序部分的末尾(即当前最小位置),将6放到数组的末尾。 - 结果:
{2, 3, 5, 6, 8}(已排序部分为{2, 3},未排序部分为空)。
- 在未排序部分
优点
- 减少比较次数:双向选择排序每轮同时找出未排序部分的最小和最大元素,相比标准选择排序减少了比较和交换的次数。
- 适用于小规模数据:尽管其时间复杂度仍为 O(n²),但在小规模数据排序时表现良好。
缺点
- 对大规模数据效率低:由于时间复杂度较高,双向选择排序不适合用于大数据集的排序。
- 相等元素的顺序可能改变:双向选择排序是一个不稳定的排序算法。相同元素的相对顺序可能会因为交换而发生变化,这在某些应用场景下可能是不可接受的。
#include "All_Sort.h"
// 选择排序函数
void Selection_Sort(int* arr, int n, int isAscending)
{
for (int i = 0; i < n - 1; i++)
{
// 假设当前元素是最小/大值
int Index = i;
for (int j = i + 1; j < n; j++)
{
if (arr[j] < arr[Index] && isAscending || arr[j] > arr[Index] && !isAscending)
Index = j;// 更新最小/大值的索引
}
// 交换当前元素与最小/大值
if (Index != i)
{
int temp = arr[i];
arr[i] = arr[Index];
arr[Index] = temp;
}
}
}
// 双向选择排序函数
void Bidirectional_Selection_Sort(int* arr, int n, int isAscending)
{
for (int i = 0; i < n / 2; i++)
{
int minIndex = i;
int maxIndex = i;
for (int j = i + 1; j < n - i; j++)
{
if (arr[j] < arr[minIndex] && !isAscending || arr[j] > arr[minIndex] && isAscending)
minIndex = j;
if (arr[j] > arr[maxIndex] && !isAscending || arr[j] < arr[maxIndex] && isAscending)
maxIndex = j;
}
// 交换最小/大元素
if (minIndex != i)
{
int temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
// 交换最大/小元素(注意 maxIndex 的位置可能已变)
if (maxIndex == i)
maxIndex = minIndex; // 如果最小/大元素在 maxIndex 位置,要更新 maxIndex
if (maxIndex != n - 1 - i)
{
int temp = arr[n - 1 - i];
arr[n - 1 - i] = arr[maxIndex];
arr[maxIndex] = temp;
}
}
}以下是关键的代码段:
// 交换最大/小元素(注意 maxIndex 的位置可能已变)
if (maxIndex == i)
maxIndex = minIndex; // 如果最小/大元素在 maxIndex 位置,要更新 maxIndex
逻辑分析
-
初始假设:
- 假设当前元素
i是未排序部分的最小值。 - 假设
maxIndex也是当前未排序部分的最大值。
- 假设当前元素
-
找到最小和最大元素:
- 在内部循环中,你会遍历未排序部分的所有元素,更新
minIndex和maxIndex的值,以找到未排序部分的最小值和最大值。
- 在内部循环中,你会遍历未排序部分的所有元素,更新
-
交换:
- 在完成查找后,你会交换最小元素(指向
minIndex)到当前的i位置。 - 但是,如果当前的
i是最大值的位置(即maxIndex == i),那么在交换最小值后,最大值的位置可能会发生变化。
- 在完成查找后,你会交换最小元素(指向
更新 maxIndex
- 为什么要更新
maxIndex:- 当最小值被放到
i位置时,原本在i位置的元素(即最大值)现在位于未排序部分的其他位置。这时,maxIndex指向的可能是一个不再是最大值的位置。 - 因此,我们需要将
maxIndex更新为minIndex的位置,以确保在后续的交换中,我们能正确交换最大值。
- 当最小值被放到
示例
假设我们有一个数组 arr = {5, 3, 8, 6, 2},我们想要进行升序排序。
迭代过程
第一次迭代(i = 0)
-
初始状态:
minIndex = 0(指向5)maxIndex = 0(指向5)
-
内部循环(查找最小值和最大值):
- j = 1:
arr[1] = 3→minIndex更新为1(3 是当前最小值) - j = 2:
arr[2] = 8→maxIndex更新为2(8 是当前最大值) - j = 3:
arr[3] = 6→maxIndex仍为2(8 仍然是最大值) - j = 4:
arr[4] = 2→minIndex更新为4(2 是当前最小值)
- j = 1:
-
找到的最小和最大:
- 最小值
2(索引4),最大值8(索引2)。
- 最小值
-
交换最小值:
- 将
2交换到位置0: - 结果数组变为
{2, 3, 8, 6, 5}。
- 将
-
更新
maxIndex:- 当前最大值
8的原始位置是2,但现在数组的结构已经改变。 - 由于最小值在位置
0被交换,原本在0位置的5现在在未排序部分的其他位置。 - 由于
maxIndex仍然指向2,我们需要检查这个索引是否仍然是最大值。 - 由于
maxIndex没有指向i(即maxIndex仍然是2),我们继续。
- 当前最大值
-
交换最大值:
- 将
8(最大值)交换到未排序部分的末尾(即位置4): - 结果数组变为
{2, 3, 5, 6, 8}。
- 将
为什么要更新 maxIndex
在某些情况下,如果最小值在 maxIndex 位置(例如如果初始数组为 {8, 3, 5, 6, 2}),而我们在交换最小值后,最大值的位置可能会被改变:
-
假设数组为
{8, 3, 5, 6, 2}:- 初始时,
minIndex = 4(指向2),maxIndex = 0(指向8)。 - 在交换后,数组变为
{2, 3, 5, 6, 8}。 - 因为
maxIndex仍然指向0(原始最大值的位置),而8被交换到了末尾。
- 初始时,
-
更新
maxIndex:- 由于
minIndex是4(当前最小值的索引)与maxIndex是0(当前最大值的索引) 交换了,所有需要更新maxIndex为minIndex的位置(因为8已经不在原来的位置)。
- 由于
总结
更新 maxIndex 是为了确保在后续的交换中,我们能正确交换最大值。通过这个例子,可以看到在交换最小值后,原本的最大值位置可能会发生变化,因此需要根据新的数组状态进行更新,以确保最大值的正确处理。
堆排序(Heap Sort)
堆排序(Heap Sort)是一种基于堆数据结构的排序算法,通过构建最大堆(或最小堆)来实现排序。其主要思想是利用堆的特性来进行排序。堆是一种特殊的完全二叉树,其中每个节点的值都大于或等于(最大堆)或小于或等于(最小堆)其子节点的值。
基本原理
堆排序的基本步骤如下:
-
构建最大/小堆:
- 将待排序的数组构建成一个最大/小堆。最大/小堆的性质是每个父节点的值大/小于或等于其子节点的值。这样,根节点就是最大/小值。
-
排序过程:
- 将根节点(最大/小值)与数组的最后一个元素交换,然后将堆的大小减 1。
- 重新调整堆,使其保持最大堆的性质。
- 重复以上步骤,直到堆的大小为 1。

时间复杂度
- 堆排序的时间复杂度为 O(n log n),其中 n 是待排序的元素数量。
- 空间复杂度为 O(1),因为堆排序是原地排序。
堆排序的稳定性
堆排序是一种不稳定的排序算法。在排序过程中,可能会改变相等元素的相对位置,因为堆的调整过程依赖于树的结构。
优缺点
优点
- 高效:在大多数情况下,堆排序的时间复杂度为 O(n log n),适合大规模数据排序。
- 原地排序:不需要额外的存储空间,空间复杂度为 O(1)。
缺点
- 不稳定:相等元素的相对顺序可能会被改变。
- 实现相对复杂:相比于简单的排序算法(如冒泡排序),堆排序的实现相对复杂。