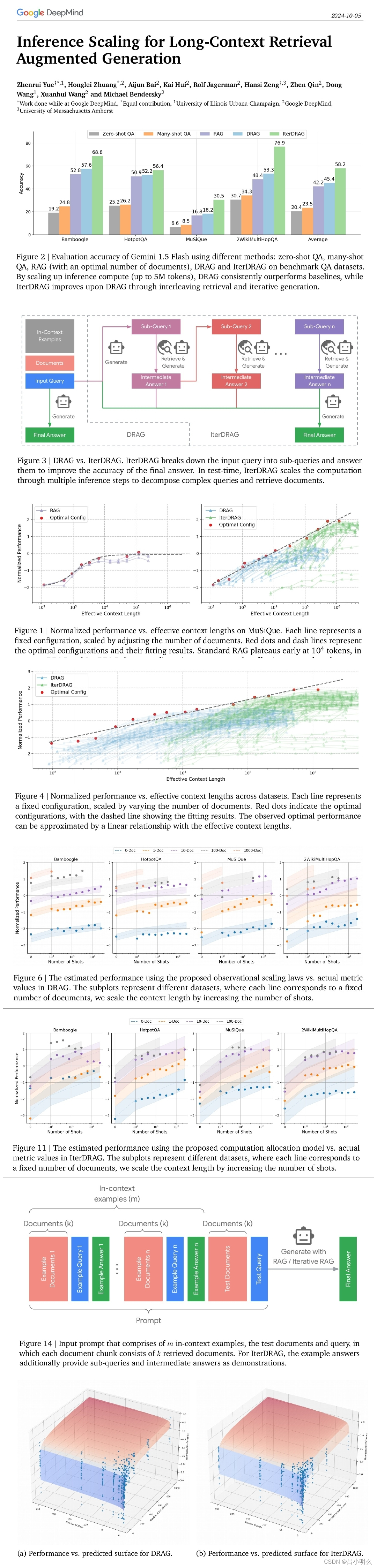
推理计算的扩展释放了长文本大语言模型(LLM)在各种环境中的潜力。对于知识密集型任务,增加的计算量通常被分配用于纳入更多外部知识。然而,如果不能有效利用这些知识,仅仅扩展上下文并不总能提高性能。
Google DeepMind 团队研究了检索增强生成(RAG)的推理扩展,探索了除单纯增加知识量之外的其他策略。
他们重点关注两种推理扩展策略:上下文学习和迭代提示。这些策略为扩展测试时间计算(例如,通过增加检索文档或生成步骤)提供了额外的灵活性,从而验证了 LLM 有效获取和利用上下文信息的两方面问题:
(1)在优化配置的情况下,RAG 的性能如何从推理计算的扩展中获益?
(2)通过对 RAG 性能和推理参数之间的关系建模,能否预测给定预算下的最佳测试时间计算分配?
观察结果表明,在优化分配的情况下,推理计算量的增加会导致 RAG 性能的近乎线性提升,他们将这种关系描述为 RAG 的推理 scaling laws。
在此基础上。他们进一步开发了计算分配模型,预测了各种计算约束条件下的最佳推理参数,并与实验结果非常吻合。通过应用这些最佳配置,证明与标准 RAG 相比,长文本 LLM 的推理计算扩展可实现高达 58.9% 的增益。
对于知识密集型任务场景,如针对复杂疾病诊疗过程中的复杂的多学科会诊、复杂平台型临床试验时的动态方案设计与调整等场景,不论得益于之前长上下文对于llm的基础,还是rag技术的快速发展,又或是cot下的step by step system2慢思考,对人类现有知识进行密集融合与多步骤下test-time scaling law也许在未来是一个非常有效的技术路径,我想未来随着技术的发展与应用场景的逐渐成熟,至少在某些任务场景下其带来的结果回报相比于reasoning的支出应该是能够达到平衡。
甚至也许在未来依托于完备的技术框架、模型达到足够敏锐且鲁棒的泛化能力下,使得模型不再局限于概念空间的思考、推理、探索与反馈,而能够真正像人类一样消耗更低能量面对外部真实世界环境中的各类复杂问题与任务,实现更少样本的高效学习,即更大尺度下的evolution-time scaling law,也许这也是当下李飞飞的“空间智能”所期待的下一个智能涌现的窗口期吧。
而我想这离不开人们对未来AI技术在模型网络结构、优化算法、跨学科融合借鉴等的进一步探索与创新。