STL 算法总览



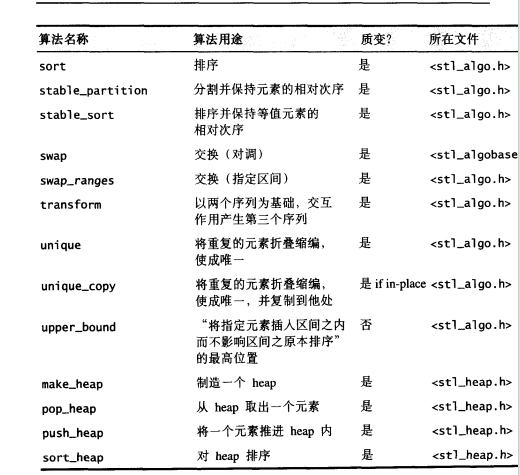
质变算法 mutating algorithms—会改变操作对象之值
所有的 STL算法都作用在由迭代器(first,last)所标示出来的区间上。所谓“质变算法”,是指运算过程中会更改区间内(迭代器所指)的元素内容。诸如拷贝(copy)、互换(swap)、替换(replace)、填写(fill)、删除(remove)、排列组合(permutation)、分割(partition)、随机重排(random shuffling)、排序(sort)等算法,都属此类。
int ia[] ={ 22,30,30,17,33,40,17,23,22,12,20 };
vector<int> iv(ia, ia+sizeof(ia)/sizeof(int));
vector<int>::const_iterator cite1 = iv.begin();
vector<int>::const_iterator cite2 = iv.end();
sort(cite1,cite2);对常迭代器指向的元素进行sort 操作,编译器会报错。
非质变算法(不改变操作对象之值)
所有的STL算法都作用在由迭代器[first,last)所标示出来的区间上。非质变算法”,是指运算过程中不会更改迭代器所指的元素内容。查找(find),匹配(search),计数(count),巡访(for_each),比较,寻找极值(max, min)等算法。
STL 算法的一般形式
所有泛型算法的前两个参数都是一对迭代器(iterators),通常称为 first 和last,用以标示算法的操作区间。STL 习惯采用前闭后开区间表示法。当 first==last时,上述所表现的便是一个空区间。
这个[first,last)区间的必要条件是,必须能够经由累加操作符的反复运用从 first到达 last。编译器本身无法强求这一点。如果这个条件不成立,会导致未可预期的结果。
质变算法(mutating algorithms,6.1.3节)通常提供两个版本:一个是 in-place (就地进行)版,就地改变其操作对象;另一个是 copy(另地进行)版,将操作 对象的内容复制一份副本,然后在副本上进行修改并返回该副本。
不是所有质变算法都有 copy 版,例如 sort()就没有。如果我们希望以这类“无 copy 版本”之质变算法施行于某一段区间元素的副本身上,我们必须自行制作并传递那一份副本。
算法的泛化过程
如何将算法独立于其所处理的数据结构之外,不受数据结构的羁绊,思想层面就不是那么简单了。如何设计一个算法,适用于大多数数据结构呢?只要把操作对象的型别加以抽象化,把操作对象的标示法和区间目标的移动行为抽象化,整个算法也就在一个抽象层面上工作了,整个过程称为算法的泛型化,简称泛化。如写一个find()函数,在 array 中寻找特定值。
int* find(int* arrayHead,int arraySize, int value){
for(int i=0;i<arraySize; ++i)
if(arrayHead[i]==value)break;
return &(arrayHead[i]);
}"最后元素的下一位置"称为 end。返回end以表示"查找无结果"似乎是个可笑的做法。为什么不返回 null? 因为,一如稍后即将见到的,end 指针可以对其他种类的容器带来泛型效果,这是 null 所无法达到的。
int* find(int* begin,int* end,int value){
while(begin != end && *begin != value) ++begin;
return begin;
}这个函数在“前闭后开”区间[begin, end)内(end 指向 array最后元素的下一位置)查找 value,并返回一个指针,指向它所找到的第一个符合条件的元素;如果没有找到,就返回end。
template<typename T>//关键词 typename 也可改为关键词 class
T* find(T* begin,T* end, const T& .value){
//以下用到了 operator!=, operator*, operator++
while(begin != end && *begin != value)++begin;
return begin;
}传统的find函数可能设计为接受原生指针作为参数,用于在数组或其他线性结构中寻找特定元素。然而,这限制了find只能用于那些可以直接用指针遍历的数据结构。
如果我们想要让find函数能够处理更复杂的数据结构,比如链表(链表是自定义的类,不能使用指针递增递减),原生指针不能简单地通过递增(++)来指向下一个元素。
STL引入了迭代器,迭代器是一种行为类似于指针的对象,但它提供了丰富的接口来适应不同的数据结构。在链表中一个迭代器可以设计成当执行递增操作,会移动到链表中的下一个节点。迭代器比喻为"智能指针",迭代器不仅模仿了指针的基本功能(如解引用和递增/递减),还加入了额外的功能。使用迭代器find函数就可以被设计为接受任何类型的迭代器,从而使得这个函数可以用来搜索不同种类的容器,包括但不限于数组,向量(vector)、列表(list)、集合(set)等。
数值算法
accumulate
主要功能是将一个范围内的所有元素累加起来,并返回累加的结果。
template <class InputIterator, class T>
T accumulate(InputIterator first, InputIterator last, T init);
template <class InputIterator, class T, class BinaryOperation>
T accumulate(InputIterator first, InputIterator last, T init, BinaryOperation binary_op);adjacent_difference
template <class InputIterator, class OutputIterator>
OutputIterator adjacent_difference(InputIterator first, InputIterator last, OutputIterator result);
template <class InputIterator, class OutputIterator, class BinaryOperation>
OutputIterator adjacent_difference(InputIterator first, InputIterator last, OutputIterator result, BinaryOperation binary_op);
binary_op 是一个二元操作符,它可以是你自定义的函数对象或lambda表达式,用来替代默认的减法操作。
inner_product
template <class InputIterator1, class InputIterator2, class T>
T inner_product(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, T init);
template <class InputIterator1, class InputIterator2, class T,
class BinaryOperation1, class BinaryOperation2>
T inner_product(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, T init,
BinaryOperation1 binary_op1, BinaryOperation2 binary_op2);主要功能是计算两个序列的内积(点积)。内积通常用于向量运算,它是两个向量对应元素相乘后的和。
std::vector<int>vec1={1, 2, 3};
std::vector<int>vec2={4, 5, 6};
//使用默认的乘法和加法操作
int product_sum = std::inner_product(vec1.begin(), vec1.end(), vec2.begin(), 0); // 结果是 1*4 + 2*5 + 3*6 = 32partial_sum
对于输入序列 [a0, a1, a2, ..., an],partial_sum 会生成一个新的序列 [a0, a0 + a1, a0 + a1 + a2, ..., a0 + a1 + ... + an]。
template <class InputIterator,class OutputIterator>
OutputIterator partial_sum(InputIterator first,
InputIterator last, OutputIterator result);
template <class InputIterator,class OutputIterator,class BinaryOperation>
OutputIterator partial_sum(InputIterator first,
InputIterator last, OutputIterator result,BinaryOperation binary_op);fill
将[first,last)内的所有元素改填新值。
template <class ForwardIterator, class T>
void fill(ForwardIterator first,ForwardIterator last, const T& value) //迭代走过整个区间
for(;first!=last; ++first) //设定新值
*first=value;
}fill_n
将[ first,last)内的前n个元素改填新值,返回的迭代器指向被填人的最后一个元素的下一位置。
template <class OutputIterator, class Size, class T>
OutputIterator fil1_n(OutputIterator first, Size n, const T& value){
//经过n个元素,设定新值
for(; n>0; --n,++first) *first = value;
return first;
}lexicographical_compare
以“字典排列方式”对两个序列[first1,last1)和[first2,last2)进行比较。
max
取两个对象中的较大值。有两个版本,版本一使用对象型别T所提供的greater-than操作符来判断大小,版本二使用仿函数 comp来判断大小。
template <class T>
inline const T& max(const T& a, const T& b)
return a < b ? b:a;
}
template <class T,class Compare>
inline const T& max(const T& a, const T& b, Compare comp)(
// 由 comp 决定“大小比较”标准
return comp(a,b)? b:a;
}min
取两个对象中的较小值。有两个版本,版本一使用对象型别 T 所提供的less-than 操作符来判断大小,版本二使用仿函数 comp来判断大小。
template <class T>
inline const T& min(const TE a, const T& b)
return b< a ? b:a;
}
template <class T,class Compare>
inline const T& min(const T& a,const. T& b,Compare comp){
return comp(b,a)? b:a; // 由 comp 决定“大小比较”标准
}mismatch
用来平行比较两个序列,指出两者之间的第一个不匹配点,返回一对迭代器,分别指向两序列中的不匹配点。

swap
该函用交换(对调)两的 容。
template <class T>
inline void swap(T& a, T& b){
T tmp=a; a=b; b=tmp;
}copy
阅读资料:STL源码剖析——copy函数-CSDN博客(写的比较详细附有源码)
copy函数原型
template<class InputIterator, class OutputIterator>
inline OutputIterator copy(
InputIterator first,
InputIterator last,
OutputIterator result
);
//first last拷贝到result的位置copy算法第一个参数和第二个迭代器是输入迭代器,第三个迭代器是输出迭代器。
copy函数针对不同类型的迭代器采取不同的策略。
对于字符串(const char* 和 const wchar_t*),使用全特化版本直接通过 memmove 复制。
一般的迭代器,使用泛化版本并通过__copy_dispatch结构体根据迭代器类型(类型萃取)选择到合适的实现,这使用函数重载实现。
对于随机访问迭代器(由 std::random_access_iterator_tag 表示),可以利用迭代器的随机访问特性进行优化。在 __copy 的随机访问迭代器版本中,使用 last - first 计算距离,并使用循环来减少迭代器的操作次数,从而提高效率。
(在copy的时候随机迭代器可以计算copy的长度,所以for循环的长度确定,可以使用循环展开进行优化)
阅读材料:CMake中开启编译器代码优化加速_cmakelist 设置编译加速-CSDN博客
对于其他迭代器类别(如输入迭代器、前向迭代器、双向迭代器), 使用通用的 __copy 实现。这些迭代器类别不支持随机访问,因此每次循环都需要显式地递增迭代器。
对于指针迭代器,__copy_dispatch 会检查指针指向的类型是否支持 trivial assignment,如果是,则使用 memmove;否则调用非 trivial 的复制逻辑,逐个元素进行拷贝。
这里涉及到模板全特化和偏特化:
阅读资料: https://harttle.land/2015/10/03/cpp-template.html(这个博客和博主非常强,可以向他学习。以后考虑做一个自己的博客,并多阅读,多参与开源项目扩大自己的影响力)
set相关算法
STL 一共提供了四种与 set(集合)相关的算法,分别是并集(union)、交集(intersection)、差集(difference)、对称差集(symmetric difference)。
heap 算法
make_heap(),pop_heap(),push_heap(),sort_heap()
数据处理相关
adjacent_find
查找范围内相邻且相等的元素对,返回指向第一个这样的元素的迭代器。
template <class ForwardIterator> ForwardIterator
adjacent_find(ForwardIterator first, ForwardIterator last);count
计算范围内等于给定值的元素个数
template <class InputIterator, class T> typename iterator_traits<InputIterator>::difference_type
count(InputIterator first, InputIterator last, const T& value);count_if
计算范围内满足特定条件的元素个数
template <class InputIterator, class Predicate> typename iterator_traits<InputIterator>::difference_type
count_if(InputIterator first, InputIterator last, Predicate pred);find
查找范围内第一个等于给定值的元素
template <class InputIterator, class T> InputIterator
find(InputIterator first, InputIterator last, const T& value);find_if
查找范围内第一个满足特定条件的元素
template <class InputIterator, class Predicate> InputIterator
find_if(InputIterator first, InputIterator last, Predicate pred);find_end
查找一个范围在另一个范围内的最后一次出现位置
template <class ForwardIterator1, class ForwardIterator2> ForwardIterator1
find_end(ForwardIterator1 first1, ForwardIterator1 last1,
ForwardIterator2 first2, ForwardIterator2 last2);find_first_of
查找一个范围在另一个范围内的第一次出现位置。
template <class ForwardIterator1, class ForwardIterator2> ForwardIterator1
find_first_of(ForwardIterator1 first1, ForwardIterator1 last1,
ForwardIterator2 first2, ForwardIterator2 last2);for_each
对范围内的每个元素应用一个函数或仿函数。
template <class InputIterator, class Function> Function
for_each(InputIterator first, InputIterator last, Function f);generate
使用生成器填充范围内的元素
template <class ForwardIterator, class Generator> void
generate(ForwardIterator first, ForwardIterator last, Generator gen);generate_n
使用生成器为指定数量的元素赋值
template <class OutputIterator, class Size, class Generator>
OutputIterator
generate_n(OutputIterator first,Size n,Generator gen);remove
移除所有等于给定值的元素,但不调整容器大小。
template <class ForwardIterator, class T> ForwardIterator
remove(ForwardIterator first, ForwardIterator last, const T& value);remove_copy
将不等于给定值的元素复制到另一区间,并移除原区间中等于该值的元素。
template <class InputIterator, class OutputIterator, class T> OutputIterator
remove_copy(InputIterator first, InputIterator last, OutputIterator result,
const T& value);remove_if
根据条件移除元素,但不调整容器大小
template <class ForwardIterator, class Predicate>ForwardIterator
remove_if(ForwardIterator first, ForwardIterator last, Predicate pred);remove_copy_if
根据条件将元素复制到另一区间,并移除原区间中满足条件的元素。
template<class InputIterator, class OutputIterator, class Predicate>
OutputIterator
remove_copy_if(InputIterator first, InputIterator last,
OutputIterator result, Predicate pred);replace
将范围内所有等于旧值的元素替换为新值。
template <class ForwardIterator, class T1, class T2> void
replace(ForwardIterator first, ForwardIterator last,
const T1& old_value, const T2& new_value);replace_copy
将范围内所有等于旧值的元素替换为新值,并复制到另一区间。
template <class InputIterator, class OutputIterator, class T1, class T2>
OutputIterator replace_copy(InputIterator first, InputIterator last,
OutputIterator result, const T1& old_value, const T2& new_value);replace_if
根据条件将元素替换为新值。
template <class ForwardIterator, class Predicate, class T> void
replace_if(ForwardIterator first, ForwardIterator last,
Predicate pred, const T& new_value);replace_copy_if
根据条件将元素替换为新值,并复制到另一区间
template <class InputIterator, class OutputIterator, class Predicate, class T>
OutputIterator replace_copy_if(InputIterator first, InputIterator last,
OutputIterator result, Predicate pred,const T& new_value);reverse
反转范围内的元素顺序
template <class BidirectionalIterator> void
reverse(BidirectionalIterator first, BidirectionalIterator last);reverse_copy
反转并复制范围内的元素到另一区间。
template <class BidirectionalIterator, class OutputIterator> OutputIterator
reverse_copy(BidirectionalIterator first,
BidirectionalIterator last, OutputIterator result);rotate
循环移动范围内的元素
template <class ForwardIterator> void
rotate(ForwardIterator first,ForwardIterator middle,ForwardIterator last);rotate_copy
循环移动并复制范围内的元素到另一区间。
template <class ForwardIterator, class OutputIterator> OutputIterator rotate_copy(ForwardIterator first, ForwardIterator middle, ForwardIterator last, OutputIterator result);search
查找一个范围在另一个范围内的第一次出现位置
template <class ForwardIterator1, class ForwardIterator2>
ForwardIterator1
search(ForwardIterator1 first1, ForwardIterator1 last1,
ForwardIterator2 first2, ForwardIterator2 last2);search_n
查找连续出现给定次数的值。
template <class ForwardIterator, class Size, class T>
ForwardIterator
search_n(ForwardIterator first, ForwardIterator last,
Size count, const T& value);swap_ranges
交换两个相同长度区间的元素。
template <class ForwardIterator1, class ForwardIterator2>
ForwardIterator2
swap_ranges(ForwardIterator1 first1,ForwardIterator1 last1,
ForwardIterator2 first2);transform
对范围内的每个元素应用一元操作。
template <class InputIterator, class OutputIterator, class UnaryOperation>
OutputIterator
transform(InputIterator first1,InputIterator last1,
OutputIterator result,UnaryOperation op);对两个范围内的元素应用二元操作,并将结果存储在输出迭代器所指向的位置。
template <class InputIterator1, class InputIterator2, class OutputIterator,
class BinaryOperation>
OutputIterator
transform(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, OutputIterator result,
BinaryOperation binary_op);max_element
找出范围内最大元素的位置
template <class ForwardIterator> ForwardIterator
max_element(ForwardIterator first, ForwardIterator last);min_element
找出范围内最小元素的位置
template <class ForwardIterator> ForwardIterator
min_element(ForwardIterator first, ForwardIterator last);includes
检查一个已排序的序列是否包含另一个已排序序列的所有元素。
template <class InputIterator1, class InputIterator2> bool
includes(InputIterator1 first1,InputIterator1 last1,
InputIterator2 first2,InputIterator2 last2);merge
合并两个已排序的序列到一个有序序列
template <class InputIterator1, class InputIterator2, class OutputIterator>
OutputIterator
merge(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2,InputIterator2 last2,OutputIterator result);partition
重新排列范围内的元素,使得满足条件的元素位于不满足条件的元素之前。
template <class BidirectionalIterator, class Predicate>
BidirectionalIterator partition
(BidirectionalIterator first, BidirectionalIterator last,
Predicate pred);unique
移除相邻重复元素,但不调整容器大小
template <class ForwardIterator> ForwardIterator
unique(ForwardIterator first, ForwardIterator last);unique_copy
移除相邻重复元素,并将唯一元素复制到另一区间。
template<class InputIterator,class OutputIterator>OutputIterator
unique_copy(InputIterator first,InputIterator last,
OutputIterator result);lower_bound和upper_bound
lower_bound 返回的是“不小于”给定值的第一个位置。
upper_bound 返回的是“大于”给定值的第一个位置。
例如,在一个包含 {1, 2, 4, 4, 6, 7} 的有序数组中,对于值 4:
lower_bound 将返回指向第一个 4 的迭代器。
upper_bound 将返回指向第一个大于 4 的元素(即 6)的迭代器。
如果你想要找到等于给定值的所有元素的范围,你可以结合使用 lower_bound 和 upper_bound 来获取这个范围。比如上面的例子中,[lower_bound, upper_bound) 将给出所有 4 的范围。
random_shuffle
将(first,last)的元素次序随机重排
partial_sort/partial_sort_copy
- 首先,
partial_sort使用make_heap()将区间[first, middle)构造成一个最大堆(max-heap)。 - 筛选较小元素:然后,它遍历
[middle, last)中的每一个元素,将其与堆顶元素进行比较。如果新元素小于堆顶元素,则替换堆顶元素,并重新调整堆的结构以保持最大堆的性质。 - 堆排序:遍历结束后,
[first, middle)中已经包含了最小的N个元素,但顺序并未完全排序,因此最后调用sort_heap()对该区间进行排序,使其按升序排列。
[first, last),partial_sort 会将这个序列中的前 N 个最小元素放入 [first, middle) 中,其中 middle 是一个指向序列中间位置的迭代器,通常定义为 first + N。排序后,[first, middle) 中的元素是按升序排列的最小元素,而 [middle, last) 中的元素则不保证有序。
std::vector<int> data = {7, 3, 5, 8, 1, 9, 2, 6, 4, 0};
int N = 5;
//希望找到并排序前5个最小的元素
//使用 partial_sort 将前 N 个最小的元素排好序
std::partial_sort(data.begin(), data.begin() + N, data.end());sort
快速排序(Quick Sort)
sort()的主要部分是基于快速排序的。快速排序是一种分治的排序算法,通过选择一个基准元素,然后将数据分区使得所有小于基准的元素放在它的左边,大于基准的元素放在它的右边。对于每一个分区,它递归地进行排序,直到所有元素都被排序完成。
插入排序(Insertion Sort)
- 当递归排序的分区规模较小(通常在 STL 的实现中,这个阈值为 16 或更小)时,为了避免递归调用的开销,
sort()会切换到插入排序。 - 插入排序在小规模数据上性能优异,因为它的比较和交换操作相对较少,特别是在数据接近有序的情况下。
堆排序(Heap Sort):
- 如果在执行快速排序时递归深度过大,导致效率下降(例如,数据接近有序的情况可能导致快速排序的最坏情况发生),
sort()会自动切换到堆排序。 - 堆排序是一种时间复杂度为 O(n log n) 的算法,可以有效避免快速排序在最坏情况下的退化问题。它使用堆结构来排序数据,确保算法在最坏情况下仍然能保持较好的性能。
为什么要求 RandomAccessIterator
STL sort() 算法要求容器提供 RandomAccessIterator(随机访问迭代器),原因如下:
- 快速排序和堆排序都需要频繁访问数据,并且会对数据进行大量的索引操作。随机访问迭代器能够在常数时间内访问任意位置的元素。
- 如果迭代器不支持随机访问(如双向迭代器或前向迭代器),则每次访问元素时都可能需要线性时间,这会极大降低排序的效率。
不适用 sort() 的情况
- 关联容器(Associative Containers):
- 像
set,map这类关联容器,底层是红黑树(RB-tree)实现,元素在插入时就会被自动排序,因此不需要使用sort()算法。
- 像
- 序列容器:
- 对于
vector和deque,它们支持随机访问迭代器,因此可以使用sort()算法。 - 对于
list和slist,它们的迭代器分别是双向迭代器(BidirectionalIterator)和单向迭代器(ForwardIterator),不支持随机访问。对于这种情况,应使用它们的成员函数sort(),这些函数针对容器的特点进行了优化。
- 对于
SGI STL 的sort()算法实现是一个混合排序算法,主要基于快速排序,并结合了堆排序和插入排序。这种排序算法被称 Introsort,它根据不同的情况自动选择最合适的排序算法,从而在性能和稳定性之间取得平衡。
下面是对这个sort()实现细节的解析:
1. sort()函数入口
template <class RandomAccessIterator>
inline void sort(RandomAccessIterator first, RandomAccessIterator last) {
if(first!=last){
introsort_loop(first, last, value_type(first), lg(last - first) * 2);
final_insertion_sort(first, last);
}
}sort() 通过调用 introsort_loop() 函数执行主要的排序逻辑。
lg(last - first) * 2计算出最大允许的递归层数。lg()计算的是二进制对数的值(即log2),并乘以 2,这是控制分割深度的手段,以防止快速排序出现性能退化的情况。
final_insertion_sort()用于在排序完成后对较小规模的元素进行最终的插入排序。
2. lg()函数
template <class Size>
inline Size __lg(Size n) {
Size k;
for (k = 0; n > 1; n >>= 1) ++k;
return k;
}lg()函数计算一个整数n 的二进制对数。它返回 n 的对数 k,其中2^k ≤ n。
这是为了限制快速排序的最大递归深度,避免出现最坏情况的 O(n²) 时间复杂度。
3. introsort_loop()函数
template <class RandomAccessIterator, class T, class Size>
void introsort_loop(RandomAccessIterator first, RandomAccessIterator last, T*, Size depth_limit) {
const int stl_threshold = 16; // 定义阈值常量,16 个元素以下使用插入排序
while (last - first > stl_threshold) { // 如果元素个数大于阈值,继续快速排序
if (depth_limit == 0) { // 分割深度用尽时,改用堆排序
partial_sort(first, last, last); // 堆排序处理剩下的元素
return;
}
--depth_limit; // 递归深度减一
// median-of-3 partition:选择三个元素的中位数作为基准
RandomAccessIterator cut = unguarded_partition(
first, last, T(median(*first, *(first + (last - first) / 2), *(last - 1)))
);
// 对右半部分递归排序
introsort_loop(cut, last, value_type(first), depth_limit);
// 现在回到 while 循环,准备对左半部分递归排序
last = cut;
}
}快速排序阶段
当前区间的元素个数大于一个预设阈值(stl_threshold=16),它会继续进行快速排序。使用 median-of-3 partition(三数取中法)来选择枢轴元素,以避免出现最坏情况(即所有元素几乎相同或完全有序)。median-of-3选择first、middle和 last - 1这三个元素的中位数作为枢轴元素,能较好地避免性能退化。
递归深度限制
depth_limit用于限制快速排序的递归深度。它的初始值是 lg(n) * 2,每次递归时递减。如果递归深度达到 depth_limit == 0,快速排序的递归过深,算法会改用堆排序(Heap Sort)来避免快速排序最坏情况下的性能退化。
final_insertion_sort() 函数
template <class RandomAccessIterator>
void final_insertion_sort(RandomAccessIterator first, RandomAccessIterator last) {
if (last - first > stl_threshold) {
insertion_sort(first, first + stl_threshold);
unguarded_insertion_sort(first + stl_threshold, last);
} else {
insertion_sort(first, last);
}
}final_insertion_sort()在快速排序阶段完成后用于处理剩下的较小区间(通常小于16 个元素)。当区间较小时,插入排序的效率较高。
Introsort算法:SGI STL 的 sort() 实现采用的是 Introsort 算法,它在处理大规模数据时结合了快速排序的高效性、堆排序的稳定性以及插入排序在小规模数据时的优势。
递归深度控制:通过depth_limit限制快速排序的递归深度,防止性能退化为 O(n²),一旦递归过深,会自动切换到堆排序来保证 O(n log n) 的最坏情况性能。
混合排序:它根据数据的规模和当前的排序状态选择最合适的排序策略,既能保证效率,又能避免最坏情况的出现。
这种实现方式使得STL sort()能够高效处理不同规模和特性的输入数据,并提供稳定的O(nlogn)性能。inplace_merge 的作用是将两个相邻的、有序的序列合并成一个有序的序列。例如,假设有两个有序序列 [1, 3, 5] 和 [2, 4, 6],它们排列在一起形成 [1, 3, 5, 2, 4, 6]。inplace_merge 可以将它们合并成 [1, 2, 3, 4, 5, 6]。
inplace_merge(应用于有序区间)
inplace_merge 使用了一个辅助缓冲区来提高效率。当缓冲区不足时,它会采用递归分治的策略。
初始化和检查
算法首先会检查两个序列是否为空,如果其中任何一个为空,则不需要任何操作。
if(first==middle||middle==last)return;这一步判断两个区间是否为空,若是,则直接返回,无需合并。inplace_merge 调用辅助函数 inplace_merge_aux 来处理合并过程:
inplace_merge_aux(first, middle, last, value_type(first), distance_type(first));辅助函数根据序列长度和缓冲区的大小,选择不同的合并策略。
在inplace_merge_aux中,如果缓冲区的大小足够容纳其中一个序列,它会将其中一个序列拷贝到缓冲区中,然后用简单的合并算法完成整个合并过程:
if (len1 <= len2 && len1 <= buffer_size) {
Pointer end_buffer = copy(first, middle, buffer);
merge(buffer, end_buffer, middle, last, first);
}else if(len2 <= buffer_size) {
Pointer end_buffer = copy(middle, last, buffer);
merge_backward(first, middle, buffer, end_buffer, last);
}- Case 1: 如果缓冲区足够容纳序列一,则将序列一复制到缓冲区中,之后将缓冲区中的数据与序列二进行合并。
- Case 2: 如果缓冲区足够容纳序列二,则将序列二复制到缓冲区中,之后将序列一与缓冲区中的数据合并。
当缓冲区不足以容纳任何一个序列时,inplace_merge 采用递归分治的策略。它将较长的序列一分为两半,然后递归调用自己来继续处理。
BidirectionalIterator first_cut = first;
BidirectionalIterator second_cut = middle;
Distance len11 = 0;
Distance len22 = 0;
// 序列二较长if (len2 > len1) {
len22 = len2 / 2;
advance(second_cut, len22);
first_cut = upper_bound(first, middle, *second_cut);
distance(first, first_cut, len11);
}算法根据较长的序列找到分割点,然后对分割后的两部分递归地调用 merge_adaptive。
在找到分割点后,算法会调用 rotate_adaptive 将两个部分旋转合并。这使得下一个递归调用可以在原地继续合并操作。
BidirectionalIterator new_middle = rotate_adaptive(first_cut, middle, second_cut, len1 - len11, len22, buffer, buffer_size);
rotate_adaptive 是 rotate 的一种优化版本,它会尝试使用缓冲区,如果缓冲区不够大,则直接调用 rotate。
( 这个地方看不懂 )
nth_elem ent
nth_element是找到一个第 n 大元素,并且重新排列序列,使得这个元素在正确的位置上,同时满足以下条件:
- 左侧子区间:所有元素都小于或等于这个“第 n 大”元素。
- 右侧子区间:所有元素都大于或等于这个“第 n 大”元素。
- 次序无关:它不会保证两个子区间内部的元素顺序,这与
sort或partial_sort不同。
这使得 nth_element 更像是一个改进版的 partition,而不是 sort。
假设有一个序列:{22, 30, 30, 17, 33, 40, 17, 23, 22, 12, 20}
执行以下操作:
nth_element(iv.begin(), iv.begin() + 5, iv.end());
目标是将序列重新排列,使得第 5 个位置上的元素(即索引 5)是这个序列排序后应该在的位置。算法执行完成后,结果可能是:
{20, 12, 22, 17, 17, 22, 23, 30, 30, 33, 40}
iv[5] 上的元素是 22,并且它与完全排序后的序列中同一位置上的元素值相同。然而,左侧和右侧部分的元素顺序并没有完全排序,只保证满足“左侧所有元素小于等于 22,右侧所有元素大于等于 22”。
nth_element 的实现思路借鉴了快速排序中的分区算法(partitioning),采用了median-of-3 partitioning 技术。具体来说:
- Median-of-3 partitioning:算法从序列的开头、中间和结尾选取三个元素,计算它们的中值(即三者中居中的那个值),并将该中值作为“枢轴(pivot)”。
- 分割序列:以枢轴为中心,将序列分为左(小于枢轴)和右(大于枢轴)两部分。
- 递归分治:判断
nth元素在左侧还是右侧,并递归地对相关部分继续执行相同操作,直到序列长度小于或等于 3。 - 插入排序:当序列长度减小到 3 或以下时,使用插入排序(insertion sort)完成排序,因为对于小规模的数据,插入排序更加高效。这种方法的效率高于完全排序,因为它只对涉及的部分进行重新排列。
merge sort
可以使用inplace_merge来实现merge sort
template <class BidirectionalIter>
void mergesort(BidirectionalIter first, BidirectionalIter last) {
// 计算序列长度
typename iterator_traits<BidirectionalIter>::difference_type n = distance(first, last);
// 如果序列长度为 0 或 1,则序列已经有序,无需进一步操作
if (n <= 1)
return;
// 找到序列的中点,将序列对半分割
BidirectionalIter mid = first + n / 2
// 对左半部分递归进行归并排序
mergesort(first, mid);
// 对右半部分递归进行归并排序
mergesort(mid, last);
// 将两个已经排序的子序列合并成一个有序序列
inplace_merge(first, mid, last);
}归并排序和快速排序的时间复杂度都是 O(NlogN),但是它们的性能在实际应用中会有所不同:
- 空间复杂度:归并排序通常需要额外的内存空间来存储合并过程中的中间结果,而快速排序可以在原地进行,不需要额外的存储。这使得快速排序在内存管理上更有优势。
- 数据移动成本:由于归并排序需要将元素复制到临时缓冲区中,这会增加数据移动的成本。而快速排序由于在原地进行,因此数据移动较少。