文章目录
- 零、复习事前准备
- 一、绪论
- 期末主观题
- 二、数据仓库&OLAP理论
- 数据仓库
- 数据仓库多维建模
- 概念分层(把底层概念映射到更高层、更一般的概念)
- 维度分层
- 数值分层
- 建模方式
- 数据立方体组成
- 星形模型(Star schema)
- 雪花模型(Snowflake schema)
- 事实星座型(Fact constellation schema)
- 对数据立方体的度量(数值函数)
- OLTP与OLAP
- 常见OLAP操作
- 数据湖(不断演进,可扩展的大数据存储、处理、分析的设施)
- 三、数据预处理
- **数据清理**(处理脏数据,使之有用)
- 空缺值处理(提升完整性)
- 一致性检验(提升一致性)
- 离群点处理(提升准确性)
- 基于统计学的离群点检测
- 基于距离的离群点检测
- 基于密度的离群点检测
- 基于模型的离群点检测
- 噪声处理(提升准确性)
- 分箱法(处理有序数据,利用周围的值使之平滑)
- 去重处理(提升冗余性)
- 数据规约(提升冗余性)
- 维度规约(删除不相干的属性/随机变量)
- 主成分分析(PCA,常用于图像压缩)
- 特征选择
- 样本量规约
- 均衡性处理(提升均衡性)
- 数据增强(不增加数据)
- 格式转换(提升标准性)
- 数据变换(提升标准性)
- 可溯源性保证(提升可溯源性)
- 数据集成
- 数据规约&扩充
- 数据转换
- 四、关联规则
- 关联规则模型
- 置信度:反映了这条规则的可信度。
- 支持度:在所有交易集中**A与B同时发生的概率**。
- 项目&项集
- 交易
- 项集的支持度(项集出现的概率)
- 项集的最小支持度&频繁集
- 关联规则
- 关联规则的支持度
- 关联规则置信度
- 强关联规则
- 关联分析算法——Apriori算法
- 潜在频繁项集
- Apriori算法改进
- 基于约束的关联挖掘
- 其他关联规则算法
- 五、分类与回归
- 分类问题(类似softmax)
- 回归问题(用曲线拟合离散点)
- 分类算法
- 决策树
- 构造决策树
- 支持向量机(SVM,两类问题)
- 朴素贝叶斯(有稳定的分类效率,适合增量式训练,常用于文本分类)
- 六、聚类(一种无监督学习)
- 划分聚类:K-means算法
- 层次聚类
- 性能度量
- 外部指标(类似F1指数)
- 内部指标
- 距离计算
- 七、文本挖掘
- 离散型表示方式
- 独热编码(one-hot,某一个维度是1,其他是0的向量)
- 词袋模型(bag of words,BOW)
- 词频-逆文档频率(TF-IDF)
- 分布型/连续型表示方式
- N-gram(基于统计语言模型)
- Word2Vec
- Glove:基于全局词频统计的词表征算法
- ELMO算法:可以根据上下文信息对word embedding 进行调整,解决无法多义词的问题
- 类比评估
- 外部指标:命名实体识别、词义消歧、文本分类等
- 文本预处理(分词)
- 文本摘要
- 信息抽取(关键字抽取)
- 文本分类
- 文本聚类:常用K-Means聚类与层次聚类
- 八、Web挖掘
- PageRank算法(独立与查询,主流方法)
- HITS算法(查询相关)
- 提高网站的权重
- Web数据预处理
- 九、多媒体挖掘
- 十、高级数据挖掘
零、复习事前准备
记得看每一章mooc的ppt重点标注!
一、绪论
数据挖掘:从巨量数据中获取正确的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。
期末主观题
字数不多于8000字,但也不要少于一张A4纸!
教师联系:周三的下午3:40分。

二、数据仓库&OLAP理论
数据仓库

面向主题的(分析特点主题域)、集成的(集成多个数据源)、稳定的(进入仓库后不会改变,历史数据不会被更新)、反映历史数据变化(保留历史数据)的数据集合。用于支持管理决策&信息全局共享。
ETL:从数据库抽取、将数据清洗&转化、加载数据。

数据仓库多维建模
多维数据模型:通过多个维度对数据进行观察与建模,以数据立方体为单位。(将一张表格的多个维度转化为一个n维空间的物体)
数据立方体并非实际物理存储的范式!


概念分层(把底层概念映射到更高层、更一般的概念)
维度分层

数值分层

建模方式
数据立方体组成
维度表:记录了每一个维度及其下对应的类别。
事实表:记录度量值与和维度表关联的码。
星形模型(Star schema)
事实表在中心(有大量数据,没有冗余),周围每个维度连接一个表。

雪花模型(Snowflake schema)
星形模型的变种,部分维度表可以多级进行细化。

事实星座型(Fact constellation schema)
存在多个事实表与维度表相关联。(星型模式的汇集)

对数据立方体的度量(数值函数)
分布类函数:count(),sum(),min(),max()
代数类函数:avg(),min_N(),max_N(),standard_deviation()
整体类函数:rank(),median(),mode()
OLTP与OLAP
OLTP(联机事务处理):传统关系数据库常用,主要是事务处理。
OLAP(联机分析处理):数据仓库常用,支持复杂分析操作,侧重决策支持。

为什么需要可分离的数据仓库而不是DBMS:
1.直接在数据库上进行OLAP查询会大大降低性能。
2.若将并发机制&恢复机制用于OLAP,会危害并行事务运行,从而大大降低OLAP吞吐量。
常见OLAP操作
上卷(Roll up):将某个维度的概念分层通过向上攀升/规约,使得其维度发生改变,(将数据进行“聚集”,维度的类别通常是变少)
eg:cities维度被向上攀升为了countries

下钻(Drill down):上卷的逆操作,从高层的概括细化到底层。(维度的类别通常是变多)
eg:将quarters变为了months。

切片(Slice):在给定的维度中进行选择,“切下”一个截面/做一个投影。
eg:在time维度下是’Q2’的截面。

切块(Dice):通过更多个维度进行的投影/“切块”
eg:在location维度、time维度与item维度三个维度下进行切块。

转轴/旋转(pivot/rotate):通过不同的视角,将3维的立体块变为2维的平面序列。
数据湖(不断演进,可扩展的大数据存储、处理、分析的设施)

湖仓一体:结合了数据湖与数据仓库
集中化数据平台:以数据物理集中化为原则的、中心式单体式架构,其最大特征就是统一的ETL(采集清晰提供),导致集中化管理压力大,数据处理相应变慢,数据延迟影响准确性。
数据网格(去中心化)

数据中台:




三、数据预处理
数据清理(处理脏数据,使之有用)
冗余数据识别&消除,噪点平滑,不一致数据消除等。
空缺值处理(提升完整性)
剔除法(直接去除,适用于样本量大):简单易行,但会导致样本量的损失与统计效果的削弱。
均值插补(用平均值或众数来填充):简单易行,但会产生有偏估计,方差与标准差会变小。
回归插补(处理变量之间的相关关系):更可靠,但容易忽视随机误差。
极大似然估计(适用于任何总体):一致且有效,但并非所有缺失值都可以求得似然估计(似然估计的方程可能难以求解或没有解)
一致性检验(提升一致性)
所有的数据都应从外部条件相同的条件下获取,且具备一致的单位/量纲等衡量单位!
离群点处理(提升准确性)
由于系统误差等因素,往往会产生一些数据变为离群点/异常值,大部分场合需要将这些数据视作噪声而丢弃,也有少部分情况下需要对这些离群点进行研究。
基于统计学的离群点检测
- 简单统计分析:对数据进行描述性统计分析,看看是否有值超出了预期的合理范围。
- 3 σ 3\sigma 3σ探测方法:如果总体为正态总体,则超过 3 σ 3\sigma 3σ的 0.27 0.27% 0.27的数据可以认为是离群点( P ( ∣ X − μ ∣ ≥ 3 σ ) = 0.0027 P(|X-\mu|\geq3\sigma)=0.0027 P(∣X−μ∣≥3σ)=0.0027)
- 作图法:利用散点图/柱状图来直观观察出离群点。
- 四分展布法:计算四分位点。
(1)将所有数据升序排序后四等分,分位点分别为 25 % , 50 % , 75 % 25\%,50\%,75\% 25%,50%,75%。
(2)计算四分展布 d F d_F dF:计算上四分位数 F u F_u Fu( 75 % 75\% 75%)与下四分位数 F l F_l Fl( 25 % 25\% 25%)之差。
(3)得到截断点 F l − 1.5 d F F_l-1.5d_F Fl−1.5dF与 F u + 1.5 d F F_u+1.5d_F Fu+1.5dF。
(4)在上下截断点区间外的数据为离群点。

- 基于分布的单个属性检测
不一致检验:
零假设
H
0
H_0
H0:全体样本数据满足同一个分布模型,
备择假设
H
1
H_1
H1:数据来自其他不同分布的模型,
如果分布检验导致
H
1
H_1
H1被接受,则该点为离群点。
常用格拉布斯/Grubbs检验、Dixon检验、t分布检验。
格拉布斯检验:
- 对于测定的
n
n
n个数据
a
1
a_1
a1~
a
n
a_n
an,先升序排序,
计算平均值 x ‾ \overline{x} x与标准差 s s s。 - 对于某个可疑值 a i a_i ai,计算 G i = ( a i − x ‾ ) s G_i=\frac{(a_i-\overline{x})}{s} Gi=s(ai−x)(此时的 i i i是升序下的排列序号!)
- 将
G
i
G_i
Gi值与格拉布斯表在置信概率为
p
p
p的情况下给出的临界值
G
p
(
n
)
G_p(n)
Gp(n)相比较,若前者更大则为离群点。

基于距离的离群点检测
常用欧氏距离(直线距离)与马氏距离(
D
M
(
x
)
=
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
D_M(x)=\sqrt{(x-\mu)^T\Sigma^{-1}(x-\mu)}
DM(x)=(x−μ)TΣ−1(x−μ),其中
Σ
\Sigma
Σ是协方差矩阵)测定,
当某些点的距离与总体中至少
p
p
p个点的距离大于
d
d
d,则为离群点。

基于密度的离群点检测
当某个点的局部密度显著低于他的大部分近邻时,这个点为离群点。
基于模型的离群点检测
聚类模型中,落在簇之外的就是离散点。
噪声处理(提升准确性)
噪声:随机的错误或方差
分箱法(处理有序数据,利用周围的值使之平滑)
将数据排序,并分成一个个区间范围的“箱”,根据箱子内的值来考虑消除噪声(因此属于局部平滑),通常用平均值/中位数/最值来替换。
箱子的宽度越大,光滑的效果越明显。

去重处理(提升冗余性)
通常选择删除其他重复的数据,或综合所有重复的数据得到整合过的新数据。
数据规约(提升冗余性)
精简数据,使之变小,但依旧可以产生几乎相同的效果。
维度规约(删除不相干的属性/随机变量)
小波变化(DWT):通过加权平均等方式钝化图像,常用于图像处理,计算机视觉相关,数据清理等。

主成分分析(PCA,常用于图像压缩)
降低数据维度,找出
k
k
k个最能代表原本数据的正交维度,称为主成分。
中心化后进行特征值分解,选出
k
k
k个最大的特征向量。


特征选择
特征子集搜索:找到最小的、且最能描述类别的特征组合
评价函数:衡量哪个特征子集的效果最好
穷举法、启发式搜索、随机搜索
启发式搜索:逐步向前选择、逐步向后删除、逐步向前选择&逐步向后删除的结合、决策树归纳
样本量规约
线性回归模型:将散点拟合到一条直线 h θ ( x ) = θ 1 x + θ 0 h_{\theta}(x)=\theta_1x+\theta_0 hθ(x)=θ1x+θ0(最小二乘法)
直方图:分箱法分类后,用频率来表示。(箱的宽度区间与样本个数相似)

聚类:将数据划分为群/簇,簇内的样本性质相似。
直径:两个簇中最远的两个样本的距离
形心距离:簇中每个成员距离簇形心的平均距离
抽样:无放回抽样、放回抽样、簇抽样(分为簇后抽若干个簇)、分层抽样(分层之后在每个层抽样)
数据立方体聚集:即 数据仓库(OLAP相关,见前)
均衡性处理(提升均衡性)
数据增强(不增加数据)
有监督的数据增强:数据变换(如图片镜像翻转,图片色彩变换等)
无监督的数据增强:生成对抗网络(GAN)
格式转换(提升标准性)
把原始数据转化为适合数据挖掘的形式
数据变换(提升标准性)
通过汇总/聚集,让数据形式更适合数据挖掘(光滑、聚集、规范化(Min-Max规范化、Z-score规范化、小数定标规范化)、离散化等)
可溯源性保证(提升可溯源性)
数据获取及其处理过程可溯源
数据集成
结合多个数据源的数据存在一个一致的数据存储中。
数据规约&扩充
在可能获得相同/相似结果的前提下,对数据缩减/扩充。
数据转换
将原始数据转换为适用于数据挖掘的格式。
四、关联规则
反映一个事物与其他事物的相互依存性&关联性,寻找关联规则就是发现数据中的规律。

关联规则模型
规则(形如“如果…那么…”(if…then…)):通过置信度与支持度来衡量规则的好坏。
置信度:反映了这条规则的可信度。
对于规则if A,then B,其置信度
C
o
n
f
i
d
e
n
c
e
(
A
,
B
)
=
P
(
B
∣
A
)
Confidence(A,B)=P(B|A)
Confidence(A,B)=P(B∣A)。

支持度:在所有交易集中A与B同时发生的概率。

项目&项集
令
I
=
{
i
1
,
i
2
,
.
.
.
i
m
}
I=\{i_1,i_2,...i_m\}
I={i1,i2,...im}为
m
m
m个不同项目的集合,每个
i
k
(
k
=
1
,
2
,
.
.
.
,
m
)
i_k(k=1,2,...,m)
ik(k=1,2,...,m)称为一个项目。
集合
I
I
I为项集。其元素个数
m
m
m为项集的长度,也可称其为
m
m
m-项集。

交易
交易
T
T
T是项集
I
I
I上的一个子集,即
T
⊆
I
T\subseteq I
T⊆I,但通常
T
⊂
I
T\subset I
T⊂I。
每一个交易
T
T
T有其唯一标识交易号TID。交易的全体构成了交易集
D
D
D。其交易个数为
∣
D
∣
|D|
∣D∣。

项集的支持度(项集出现的概率)
对于项集
X
⊂
I
X\subset I
X⊂I,其支持度
s
u
p
p
o
r
t
(
X
)
=
c
o
u
n
t
(
X
⊆
T
)
∣
D
∣
support(X)=\frac{count(X\subseteq T)}{|D|}
support(X)=∣D∣count(X⊆T)。
其中
c
o
u
n
t
(
X
⊆
T
)
count(X\subseteq T)
count(X⊆T)指
D
D
D中交易包含X的数量。

项集的最小支持度&频繁集
项集的最小支持度:发现关联规则需要的最小支持阈值
s
u
p
m
i
n
sup_{min}
supmin,大于等于
s
u
p
m
i
n
sup_{min}
supmin的项集称为频繁集。
通常若一个
k
k
k-项集满足
s
u
p
m
i
n
sup_{min}
supmin,则称之为
k
k
k-频繁集,记为
L
k
L_{k}
Lk。
关联规则
即
R
:
X
⇒
Y
R:X\Rightarrow Y
R:X⇒Y
X
⊂
I
,
Y
⊂
I
,
X
∩
Y
=
∅
X\subset I,Y\subset I,X\cap Y=\empty
X⊂I,Y⊂I,X∩Y=∅
eg: R:牛奶
⇒
\Rightarrow
⇒面包
关联规则的支持度
s
u
p
p
o
r
t
(
X
⇒
Y
)
=
c
o
u
n
t
(
X
∪
Y
)
∣
D
∣
support(X\Rightarrow Y)=\frac{count(X\cup Y)}{|D|}
support(X⇒Y)=∣D∣count(X∪Y)(也就是对应项集
{
X
,
Y
}
\{X,Y\}
{X,Y}的支持度)
最小支持度为
s
u
p
m
i
n
sup_{min}
supmin。

上例中,
∣
D
∣
=
4
|D|=4
∣D∣=4,
c
o
u
n
t
(
A
∪
C
)
=
2
count(A\cup C)=2
count(A∪C)=2,故关联规则支持度为
50
%
50\%
50%。
关联规则置信度
c
o
n
f
i
d
e
n
c
e
(
X
⇒
Y
)
=
s
u
p
p
o
r
t
(
X
∪
Y
)
s
u
p
p
o
r
t
(
X
)
confidence(X\Rightarrow Y)=\frac{support(X\cup Y)}{support(X)}
confidence(X⇒Y)=support(X)support(X∪Y)
最小置信度为
c
o
n
f
m
i
n
conf_{min}
confmin。

通常需要选择支持度与置信度均较高的关联规则!
强关联规则
若
R
:
X
⇒
Y
R:X\Rightarrow Y
R:X⇒Y满足
s
u
p
p
o
r
t
(
X
⇒
Y
)
≥
s
u
p
m
i
n
support(X\Rightarrow Y)\geq sup_{min}
support(X⇒Y)≥supmin且
c
o
n
f
i
d
e
n
c
e
(
X
⇒
Y
)
≥
c
o
n
f
m
i
n
confidence(X\Rightarrow Y)\geq conf_{min}
confidence(X⇒Y)≥confmin,则称其为强关联规则(否则为弱关联规则)。(即置信度与支持度都较高)

关联规则挖掘步骤:找到所有的频繁项集,并由频繁项集产生强关联规则。
关联分析算法——Apriori算法
通过迭代检索出所有的频繁项集,并构造出满足用户最小信任度的规则。
潜在频繁项集
为了避免去计算所有项目集的支持度(因为频繁项集只占很少一部分)
若潜在频繁
k
k
k项集记为
C
k
C_{k}
Ck,频繁
k
k
k项集的集合为
L
k
L_{k}
Lk,
m
m
m个项构成的
k
k
k项集为
C
m
k
C_{m}^k
Cmk,则
L
k
⊆
C
k
⊆
C
m
k
L_{k}\subseteq C_k\subseteq C_m^k
Lk⊆Ck⊆Cmk。
(普通的频繁项集是潜在频繁项集的一部分)
频繁项集的子集也是频繁项集。(因此要通过已知的频繁项集构造更大的项集,即潜在频繁项集,可能会成为频繁k项集的集合。)
非频繁项集的超集一定非频繁。(即包含了它的集合,例如:若
{
D
}
\{D\}
{D}不是频繁项集,则
{
A
,
D
}
,
{
C
,
D
}
\{A,D\},\{C,D\}
{A,D},{C,D}也不是。)
Apriori剪枝原则:如果一个项集不是频繁的,将不产生/测试他的超集。

如图所示,我们可以得到各个商品的支持度与置信度。
当项集大小
k
=
1
k=1
k=1时,我们可以得到支持度分别为50%,75%,75%,25%,75%,因此根据最小支持度得到频繁k项集
L
1
=
{
A
,
B
,
C
,
E
}
L_1=\{A,B,C,E\}
L1={A,B,C,E}。
同理,
k
=
2
k=2
k=2时,可以得到
L
2
=
{
{
A
,
C
}
,
{
B
,
C
}
,
{
B
,
E
}
,
{
C
,
E
}
}
L_2=\{\{A,C\},\{B,C\},\{B,E\},\{C,E\}\}
L2={{A,C},{B,C},{B,E},{C,E}}。支持度分为别50%,50%,75%,50%。
同理,
k
=
3
k=3
k=3时,有
L
3
=
{
{
B
,
C
,
E
}
}
L_3=\{\{B,C,E\}\}
L3={{B,C,E}},支持度为50%。
于是我们得到频繁项集
{
B
,
C
,
E
}
\{B,C,E\}
{B,C,E}。其非空子集有
{
B
}
,
{
C
}
,
{
E
}
,
{
B
,
C
}
,
{
B
,
E
}
,
{
C
,
E
}
\{B\},\{C\},\{E\},\{B,C\},\{B,E\},\{C,E\}
{B},{C},{E},{B,C},{B,E},{C,E},可以发现,满足最小置信度的有:
B
→
C
E
B\rightarrow CE
B→CE,置信度为66.7%。
C
→
B
E
C\rightarrow BE
C→BE,置信度为66.7%。
E
→
B
C
E\rightarrow BC
E→BC,置信度为66.7%。
C
E
→
B
CE\rightarrow B
CE→B,置信度为1。
B
E
→
C
BE\rightarrow C
BE→C,置信度为66.7%。
B
C
→
E
BC\rightarrow E
BC→E,置信度为1。
Apriori算法改进
如果频繁集中包含的项数过多的话,则负载会变得很大(因为最多可能需要I/O操作
2
n
2^n
2n次)。
划分:只扫描数据库两次,第一次划分找出局部频繁,第二次求出全局频繁。
采样:频繁模式(牺牲精度换取有效性)
基于约束的关联挖掘
反单调性:当项集
S
S
S不满足约束时,超集也不满足。
单调性:当项集
S
S
S满足约束时,子集合也满足。
简洁性:不查看事务数据库,项集
S
S
S是否满足约束
C
C
C。
m
i
n
(
S
.
p
r
i
c
e
)
≤
v
min(S.price)\leq v
min(S.price)≤v是简洁的。
s
u
m
(
S
.
p
r
i
c
e
)
≥
v
sum(S.price)\geq v
sum(S.price)≥v不是简洁的。

对于之前的例子,如果我们设置普通约束
s
u
m
(
S
.
p
r
i
c
e
<
5
)
sum(S.price<5)
sum(S.price<5),有:

如果设置反单调约束,有:

其中,因为
{
5
}
\{5\}
{5}本身已经不满足,因此不考虑包含
{
5
}
\{5\}
{5}的超集。
其他关联规则算法
FP-growth算法(频率模式增长)
五、分类与回归
分类问题(类似softmax)
函数
f
(
x
)
f(x)
f(x)的值域是有限个离散点。

分类求解方法:
1.寻找每个类的固有特征:适用于一类、多类问题(如图像识别某个特定对象或者多个形象)
2.寻找类之间差异:适用于两类问题(往往用向量机找到两类之间的间隔)
回归问题(用曲线拟合离散点)
函数
f
(
x
)
f(x)
f(x)的值域是整个实数域。

回归问题可以看做是分类问题的推广,是类别数不可数的分类问题。

回归求解方法:插值法、曲线拟合法(最小二乘法(偏差平方和最小),最小
ε
\varepsilon
ε带:偏差最大最小(化为两类问题))

分类算法
决策树、支持向量机(SVM)、K-近邻(KNN)、Logistics回归、朴素贝叶斯、人工神经网络、集成学习
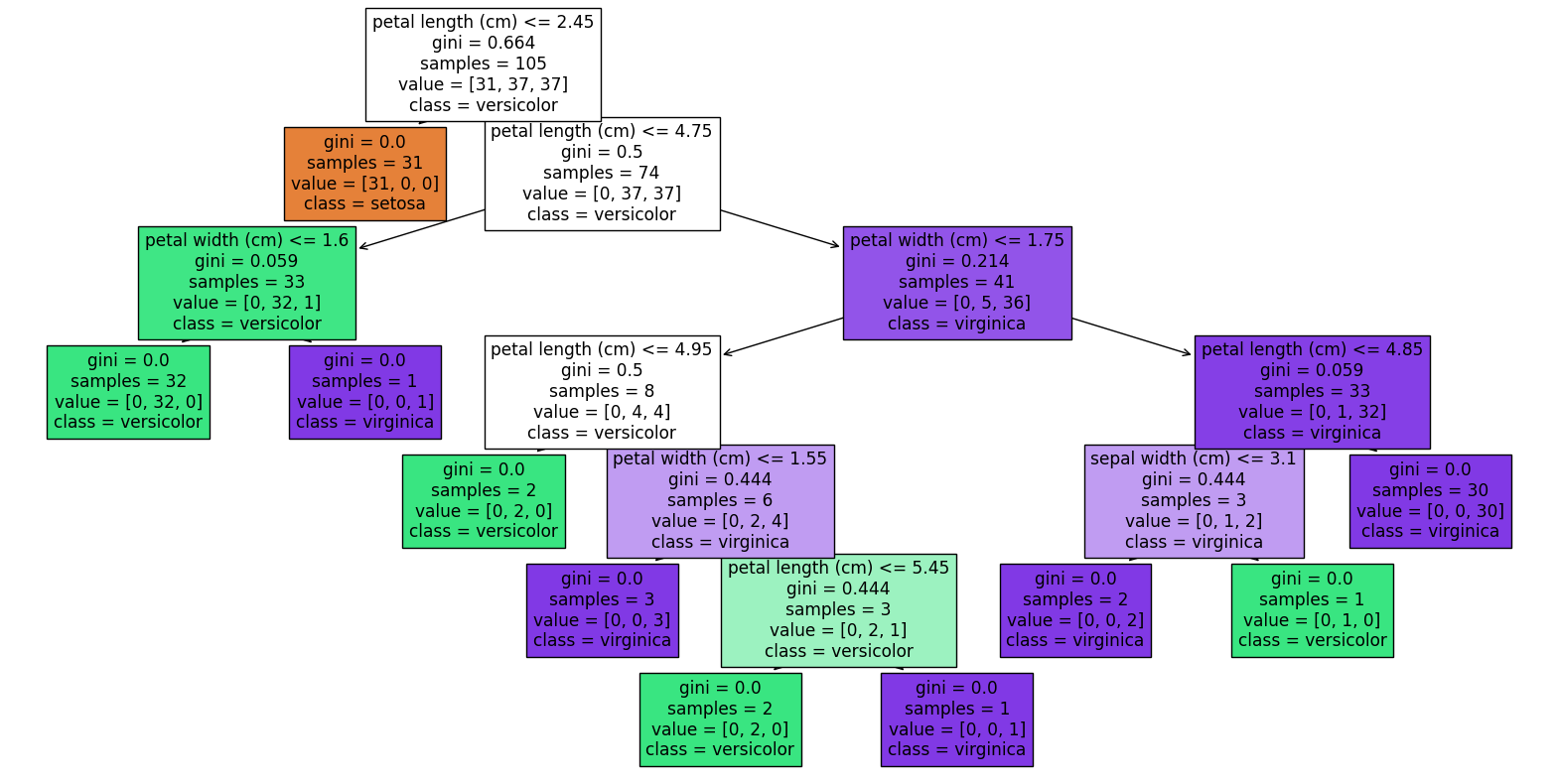
决策树
每个节点表示某个属性,每个分叉路径代表每种可能的属性值。

构造决策树
选择拥有最高信息增益(
G
a
i
n
Gain
Gain)的属性作为该节点的分裂属性/划分属性。
1.计算
D
D
D中元组的信息熵
I
n
f
o
(
D
)
=
−
∑
i
=
1
m
p
i
l
o
g
2
(
p
i
)
Info(D)=-\sum_{i=1}^{m}p_ilog_2{(p_i)}
Info(D)=−∑i=1mpilog2(pi)。
p
i
p_i
pi表示对应类型发生的概率。
2.用属性
A
A
A将
D
D
D进行划分,有
I
n
f
o
A
(
D
)
=
∑
j
=
1
v
∣
D
j
∣
∣
D
∣
×
I
n
f
o
(
D
j
)
Info_A{(D)}=\sum_{j=1}^v{\frac{|D_j|}{|D|}\times Info(D_j)}
InfoA(D)=∑j=1v∣D∣∣Dj∣×Info(Dj)
3.计算信息增益
G
a
i
n
(
A
)
=
I
n
f
o
(
D
)
−
I
n
f
o
A
(
D
)
Gain(A)=Info(D)-Info_A{(D)}
Gain(A)=Info(D)−InfoA(D)
(4.计算增益率
G
a
i
n
R
a
t
e
(
a
)
=
G
a
i
n
(
A
)
I
n
f
o
A
(
D
)
GainRate(a)=\frac{Gain(A)}{Info_A{(D)}}
GainRate(a)=InfoA(D)Gain(A))
(5.基尼指数:表示数据的不纯度,
G
i
n
i
(
D
)
=
1
−
∑
i
=
1
m
p
i
2
Gini(D)=1-\sum_{i=1}^mp_i^2
Gini(D)=1−∑i=1mpi2,
G
i
n
i
A
(
D
)
=
∑
∣
D
i
∣
∣
D
∣
G
i
n
i
(
D
i
)
Gini_A(D)=\sum\frac{|D_i|}{|D|}Gini(D_i)
GiniA(D)=∑∣D∣∣Di∣Gini(Di),不纯度降低
Δ
G
i
n
i
(
A
)
=
G
i
n
i
(
D
)
−
G
i
n
i
A
(
D
)
\Delta Gini(A)=Gini(D)-Gini_A(D)
ΔGini(A)=Gini(D)−GiniA(D))

以上图为例,计算六个维度哪一个信息增益最大。
1.首先计算根节点的信息熵,17条记录里8个好瓜,9个坏瓜。故
E
n
t
(
D
)
=
−
∑
k
=
1
2
p
k
l
o
g
2
p
k
=
−
(
8
17
l
o
g
2
8
17
+
9
17
l
o
g
2
8
17
)
=
0.998
Ent(D)=-\sum_{k=1}^{2}p_klog_2p_k=-(\frac{8}{17}log_2\frac{8}{17}+\frac{9}{17}log_2\frac{8}{17})=0.998
Ent(D)=−∑k=12pklog2pk=−(178log2178+179log2178)=0.998
2.我们以属性“色泽”为例,有三个取值{青绿、乌黑、浅白},得到
E
n
t
(
D
1
)
=
−
(
3
6
l
o
g
2
3
6
+
3
6
l
o
g
2
3
6
)
=
1.000
Ent(D^1)=-(\frac{3}{6}log_2\frac{3}{6}+\frac{3}{6}log_2\frac{3}{6})=1.000
Ent(D1)=−(63log263+63log263)=1.000(青绿里面3个好瓜3个坏瓜,下同)
E
n
t
(
D
2
)
=
−
(
4
6
l
o
g
2
4
6
+
2
6
l
o
g
2
2
6
)
=
0.918
Ent(D^2)=-(\frac{4}{6}log_2\frac{4}{6}+\frac{2}{6}log_2\frac{2}{6})=0.918
Ent(D2)=−(64log264+62log262)=0.918
E
n
t
(
D
3
)
=
−
(
1
5
l
o
g
2
1
5
+
4
5
l
o
g
2
4
5
)
=
0.722
Ent(D^3)=-(\frac{1}{5}log_2\frac{1}{5}+\frac{4}{5}log_2\frac{4}{5})=0.722
Ent(D3)=−(51log251+54log254)=0.722
于是得到属性“色泽”的信息增益
G
a
i
n
(
D
,
色泽
)
=
0.998
−
(
6
17
×
1.000
+
5
17
×
0.918
+
5
17
×
0.722
)
=
0.109
Gain(D,色泽)=0.998-(\frac{6}{17}\times1.000+\frac{5}{17}\times0.918+\frac{5}{17}\times0.722)=0.109
Gain(D,色泽)=0.998−(176×1.000+175×0.918+175×0.722)=0.109
同理得到
G
a
i
n
(
D
,
根蒂
)
=
0.143
,
G
a
i
n
(
D
,
敲声
)
=
0.141
,
G
a
i
n
(
D
,
纹理
)
=
0.381
,
G
a
i
n
(
D
,
脐部
)
=
0.289
,
G
a
i
n
(
D
,
触感
)
=
0.006
Gain(D,根蒂)=0.143,Gain(D,敲声)=0.141,Gain(D,纹理)=0.381,Gain(D,脐部)=0.289,Gain(D,触感)=0.006
Gain(D,根蒂)=0.143,Gain(D,敲声)=0.141,Gain(D,纹理)=0.381,Gain(D,脐部)=0.289,Gain(D,触感)=0.006。
因此属于“纹理”的信息增益最大,将被选为划分属性。

支持向量机(SVM,两类问题)
通常,数据是线性不可分的,所以我们需要要通过核函数,让平面维度的数据增加一维变为立体的,然后用一个超平面将二者分开。


朴素贝叶斯(有稳定的分类效率,适合增量式训练,常用于文本分类)
贝叶斯公式:
P
(
L
i
∣
A
)
=
P
(
A
∣
L
i
)
×
P
(
L
i
)
P
(
A
)
P(L_i|A)=\frac{P(A|L_i)\times P(L_i)}{P(A)}
P(Li∣A)=P(A)P(A∣Li)×P(Li)

拉普拉斯平滑:为了解决在连乘的时候遇到未出现的值,导致连乘结果变为0,令此时的
P
(
J
j
∣
Y
=
C
k
)
=
m
k
j
+
λ
m
k
+
O
j
λ
P(J_j|Y=C_k)=\frac{m_{kj}+\lambda}{m_k+O_j\lambda}
P(Jj∣Y=Ck)=mk+Ojλmkj+λ,其中
λ
>
0
\lambda>0
λ>0,往往
λ
=
1
\lambda=1
λ=1。
O
j
O_j
Oj为
j
j
j对应的特征个数。
对于正态分布,
P
(
X
j
=
F
j
∣
Y
=
C
k
)
=
1
2
π
σ
k
2
e
x
p
(
−
(
F
j
−
μ
k
)
2
2
σ
k
2
)
P(X_j=F_j|Y=C_k)=\frac{1}{\sqrt{2\pi\sigma_k^2}}exp(-\frac{(F_j-\mu_k)^2}{2\sigma_k^2})
P(Xj=Fj∣Y=Ck)=2πσk21exp(−2σk2(Fj−μk)2)。
六、聚类(一种无监督学习)
将数据集划分为若干组或簇,使得同一类的数据对象之间有较高的相似度。

划分聚类:K-means算法
(标记若干个类别中心后,数据划分到距离最近的中心)
对于输入样本
S
=
x
1
,
x
2
,
.
.
.
x
m
S=x_1,x_2,...x_m
S=x1,x2,...xm:
1.选择初始的
k
k
k个类别中心
μ
1
,
μ
2
,
.
.
.
μ
k
\mu_1,\mu_2,...\mu_k
μ1,μ2,...μk,
2.对于每个样本
x
i
x_i
xi,将其标记为距离类别中心最近的类别:
l
a
b
e
l
i
=
arg max
1
≤
j
≤
k
∣
∣
x
i
−
μ
j
∣
∣
label_i=\argmax\limits_{1\leq j\leq k}||x_i-\mu_j||
labeli=1≤j≤kargmax∣∣xi−μj∣∣
3.把每个类别的中心更新为该类别下所有样本的均值:
μ
j
=
1
∣
c
j
∣
∑
i
∈
c
j
x
i
\mu_j=\frac{1}{|c_j|}\sum\limits_{i\in c_j}x_i
μj=∣cj∣1i∈cj∑xi
重复2.和3.直到类别中心的变化率小于某个阈值。
终止条件:迭代次数、簇中心变化率、最小平方误差(MSE)
K-means算法对初值很敏感,因此如果簇中存在异常点,会导致均值偏离验证!
层次聚类
自下而上聚类:数据慢慢合并,最后变为一类。

以该图为例,不同物种有着不同的长度(length)。
1.计算两两之间的长度差的绝对值,并构造距离矩阵。

2.挑选出表格中距离最小对应的两个物种,将他们归为一类[RD,BD],其长度为所有的均值(此处为3.3),再次计算距离矩阵。

3.同理,得到[PW,KW],重复计算距离矩阵。
4.重复,最后我们得到聚类[[[BD,RD],[PW,KW]],[HW,FW]]
层次聚类不可伸缩,不可逆!

性能度量
外部指标(类似F1指数)
对于
m
m
m个样本,我们定义:
a
a
a:聚类中相同类别,模型中相同类别的个数。
b
b
b:聚类中相同类别,模型中不同类别的个数。
c
c
c:聚类中不同类别,模型中相同类别的个数。
d
d
d:聚类中不同类别,模型中不同类别的个数。
Jaccard系数:
J
C
=
a
a
+
b
+
c
JC=\frac{a}{a+b+c}
JC=a+b+ca
FM指数:
F
M
I
=
a
a
+
b
⋅
a
a
+
c
FMI=\sqrt{\frac{a}{a+b}\cdot\frac{a}{a+c}}
FMI=a+ba⋅a+ca
Rand指数:
2
(
a
+
d
)
m
(
m
−
1
)
\frac{2(a+d)}{m(m-1)}
m(m−1)2(a+d)
内部指标
对于
k
k
k个簇,我们定义:
a
v
g
avg
avg:簇内样本间平均距离
d
i
a
m
diam
diam:簇内样本间最远距离
d
m
i
n
d_{min}
dmin:两个簇之间最近的样本距离
d
c
e
n
d_{cen}
dcen:两个簇中心之间的距离
DB指数:
D
B
I
=
1
k
∑
i
=
1
k
max
j
≠
i
(
a
v
g
(
C
i
)
+
a
v
g
(
C
j
)
d
c
e
n
(
μ
i
,
μ
j
)
)
DBI=\frac{1}{k}\sum\limits_{i=1}^{k}\max\limits_{j\neq i}(\frac{avg(C_i)+avg(C_j)}{d_{cen}(\mu_i,\mu_j)})
DBI=k1i=1∑kj=imax(dcen(μi,μj)avg(Ci)+avg(Cj))
DI指数:
D
I
=
min
1
≤
i
≤
k
{
min
j
≠
i
(
d
m
i
n
(
C
i
,
C
j
)
max
1
≤
l
≤
k
d
i
a
m
(
C
l
)
)
}
DI=\min\limits_{1\leq i\leq k}\{\min\limits_{j\neq i}(\frac{d_{min}(C_i,C_j)}{\max\limits_{1\leq l\leq k}diam(C_l)})\}
DI=1≤i≤kmin{j=imin(1≤l≤kmaxdiam(Cl)dmin(Ci,Cj))}
距离计算
曼哈顿距离与欧氏距离
七、文本挖掘
文本数据是半结构化数据,既不是完全无结构也不是完全结构化。
有结构化的字段:标题、坐着、出版日期等
非结构化的文本:摘要、内容。
文本挖掘从非结构化文本中获取有用或感兴趣的模式的过程,目的是从文档集合中搜寻只是而并不试图改进自然语言理解,只是利用该领域成果尽可能多的提取知识。
离散型表示方式
独热编码(one-hot,某一个维度是1,其他是0的向量)
1.不同词向量互相正交,无法衡量词汇之间的联系。
2.无法反映不同词汇的重要程度,仅仅只能反映是否出现。
3.独热编码是高维稀疏矩阵,会浪费计算&存储资源。
词袋模型(bag of words,BOW)
不考虑词汇之间的上下文联系,仅考虑词汇的词频权重,将词汇装入一个个“袋子”。
向量中元素表示单词词频,其长度等于词典长度。
分词
→
\rightarrow
→统计词频
→
\rightarrow
→特征标准化
1.丢失了词的位置信息,词的位置不一样语义会有很大的差别.
2.单词词频并不与该词的重要程度完全正相关,如文中大量出现的词汇比如“你”、“我”以及一些介词等对于区分文本类别意义不大。
词频-逆文档频率(TF-IDF)
单词在其所在文本中词频越高,且在其他文本中词频越少,则可以很好的表征单词所在的文本。
I
D
F
=
−
l
o
g
(
D
F
)
IDF=-log(DF)
IDF=−log(DF)
T
F
I
D
F
=
T
F
∗
I
D
F
TFIDF = TF*IDF
TFIDF=TF∗IDF
其中
T
F
TF
TF为单词在所在文档的频率,
D
F
DF
DF为单词在其他文档的频率。
1.不能反映位置信息。
2.IDF精度不高,适用于频度较小的词。
3.TF-IDF严重依赖于语料库,对语料库要求高。
分布型/连续型表示方式
N-gram(基于统计语言模型)
基于词频统计。
与词袋模型的区别:
1.词袋模型只是简单的计算单词频度,而n-gram计算两个词在一个窗口下出现的频率,强调词与词间的关系。
2.词袋模型目的是对一篇文章编码,而n-gram是对词编码,颗粒度有巨大差异。
Word2Vec
一个单隐藏层的神经网络。
可以学习到语义和语法信息(考虑了上下文),且词向量维度小通用性强,可以应用到各种NLP任务中。
缺点
词和向量是一对一的关系,无法解决多义词的问题;
word2vec是一种静态的模型,虽然通用性强,但无法针对特定的任务做动态优化。
Glove:基于全局词频统计的词表征算法
ELMO算法:可以根据上下文信息对word embedding 进行调整,解决无法多义词的问题
类比评估

例如:对于一个词向量,变换时(如形容词变成比较级或者最高级)如果存在相同的变换方向,则这种词向量为“好向量”。
外部指标:命名实体识别、词义消歧、文本分类等

文本预处理(分词)
将连续的字序列根据一定规范组合成词序列。

文本摘要
对大型文档或文档集合做简要概述。

信息抽取(关键字抽取)

文本分类
对未知文本类型进行分类。
基于深度学习的方法:RNN、CNN、Bert、word2Vec词向量训练等。
非深度学习方法:FastText

文本聚类:常用K-Means聚类与层次聚类
八、Web挖掘

PageRank算法(独立与查询,主流方法)
将锚定文本(anchor text)标记、词频统计等因素相结合,对检索出的结果进行相关度排序。
链入网页数、链入网页质量、链入网页的链出网页数。
(如果某个网页被其他很多网页链入,则PageRank值较高;如果一个PageRank值较高的网页链接到其他网页,则该网页的PageRank值也会提高。)
HITS算法(查询相关)
分为两类页面:
中心网页(Hub):指向权威网页(authority)。
权威网页:被多个Hub指向的网页。
指向都是单向的,好的Hub应该指向多个authority,好的authority应该被多个hub指向(多对多)。
提高网站的权重

Web数据预处理

九、多媒体挖掘
文本查询:Query by text,QBT