Abstract
本文提出了一种新的训练方法,在保持较高图像质量的前提下,仅用1~4步就能有效地对大规模传统图像扩散模型进行采样,使用分数蒸馏(score distillation),来利用大规模现成的图像扩散模型作为教师信号,并结合对抗损失,以确保即使在1~2个采样步骤的低步骤机制下也能获得高图像保真度。
分析表明,ADD在单个步骤中明显优于现有的少步方法(GANs),并且仅在4个步骤中达到了最先进的扩散模型(SDXL)的性能。ADD是第一种利用基础模型解锁单步实时图像合成的方法。
1 Introduction
扩散模型的迭代推理过程需要大量的采样步骤,阻碍了其实时应用。
GANs的特点是单步生成,速度固定,但是即便推广到大型数据集,GANs的样本质量方面仍然比不过Diffusion Model。
本文方法很简单,提出Adversarial Diffusion Distillation (ADD),将预训练的扩散模型的推理步数降低到1~4步,同时保持较高的采样保真度,并有可能进一步提高模型的整体性能。
为实现上述目标,提出两种训练目标:
- 对抗损失:强制模型在每个前向通道上直接生成真实图像样本,避免其他蒸馏方法中看到的模糊和伪影。
- 蒸馏损失:使用另一个扩散模型作为教师,有效地利用预训练模型的知识,保留大型扩散模型观察到的强组合性。
推理过程中,本方法不使用classifier-free guidance,减少内存需求,通过迭代细化保留模型生成能力。
3 Method
本文目标:在尽可能少的采样步骤中升成高保真度的样本。
对抗损失支持快速生成,因为在一步前向步骤中训练一个在图像流形中输出样本的模型。
将GANs扩展到大型数据集不仅依赖于判别器,还使用预训练的分类器或CLIP网络来改善文本对齐,过度使用判别器会引入伪影,使图像质量受损。
本文通过分数蒸馏目标,利用预训练扩散模型的梯度,来提高文本对齐和采样质量。
本文还使用预训练的扩散模型权重初始化模型,因为预训练的生成网络可以提高带有对抗损失的训练过程。
3.1 Training Procedure

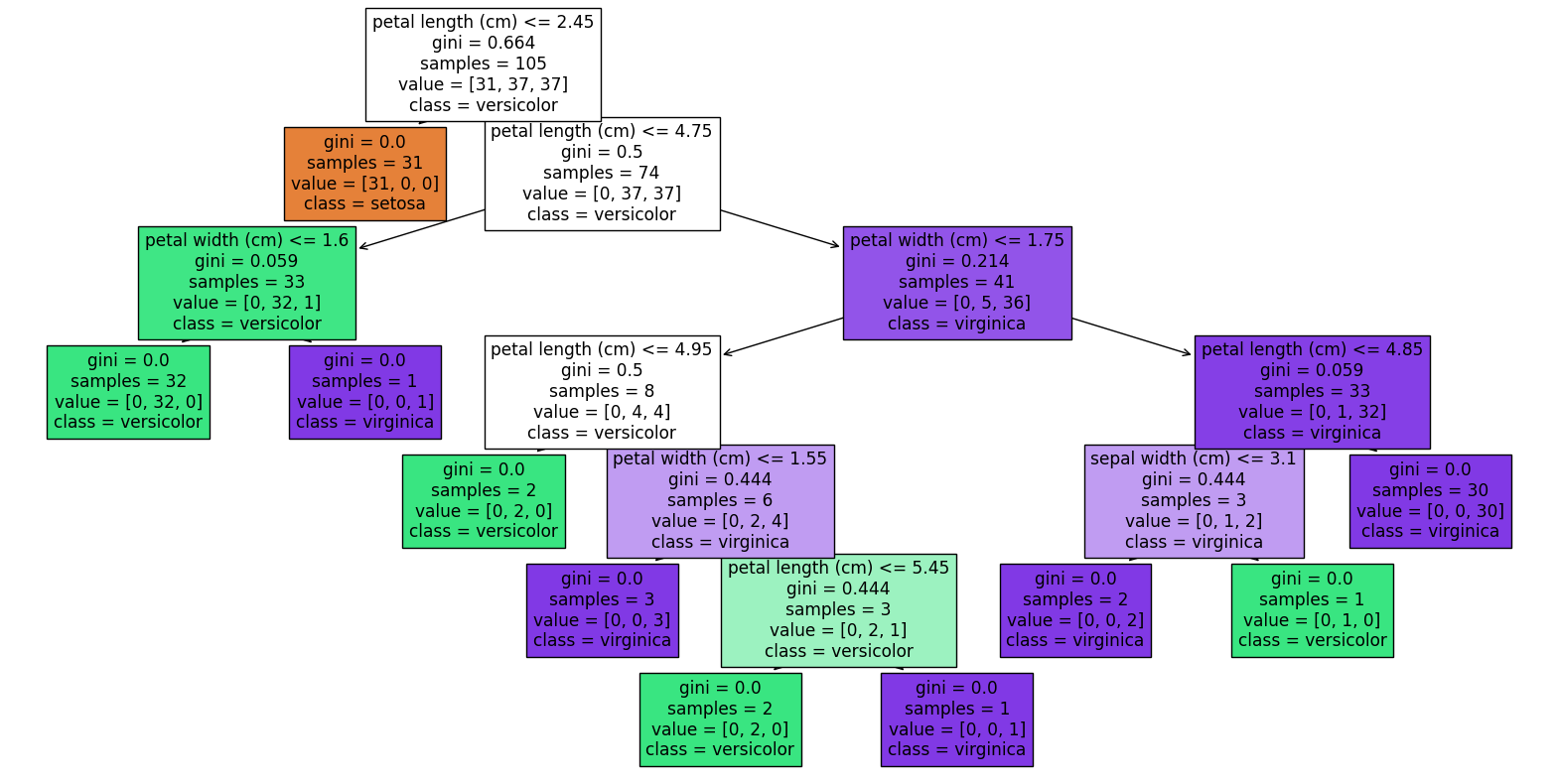
图2:ADD。ADD-student训练成一个denoiser,接受扩散输入图像
x
s
x_s
xs,输出样本
x
^
θ
(
x
s
,
s
)
\hat{x}_\theta(x_s,s)
x^θ(xs,s),然后优化两个目标:
- 对抗损失(adversarial loss),模型旨在误导判别器,判别器经过训练,用于从真实图像集 x 0 x_0 x0中分辨生成样本 x ^ θ \hat{x}_\theta x^θ。
- 蒸馏损失(distillation loss),模型经过训练,用于匹配冻结的扩散模型教师的去噪目标 x ^ ψ \hat{x}_\psi x^ψ。
训练过程如图2所示,包含3个网络。
- ADD-student:借助预训练的UNet-DM初始化
- 判别器:带有可训练权重 ϕ \phi ϕ
- DM教师模型:带有冻结参数 ψ \psi ψ的。
训练过程中,ADD-student从ADD-student从噪声数据 x s x_s xs中生成样本 x ^ θ ( x s , s ) \hat{x}_\theta(x_s,s) x^θ(xs,s)。噪声数据是从真实图像 x 0 x_0 x0通过前向扩散过程 x s = α s x 0 + σ s ϵ x_s=\alpha_s x_0+\sigma_s\epsilon xs=αsx0+σsϵ产生的。
本实验中,使用了和学生DM模型相同的 α s \alpha_s αs和 σ s \sigma_s σs系数,从集合 T student = { τ 1 , ⋯ , τ n } T_\text{student}=\{\tau_1,\cdots,\tau_n\} Tstudent={τ1,⋯,τn}中,用 N N N个学生选定的timestep均匀采样 s s s个样本(实践中 N = 4 N=4 N=4, τ n = 1000 \tau_n=1000 τn=1000,强制模型推理时从纯噪声开始)。
对于对抗目标,生成的样本
x
^
θ
\hat{x}_\theta
x^θ和真实图像
x
0
x_0
x0送入判别器中区分他们。为了从DM教师处蒸馏知识,将学生样本
x
^
θ
\hat{x}_\theta
x^θ使用教师模型的前向过程扩散得到
x
^
θ
,
t
\hat{x}_{\theta,t}
x^θ,t,再使用DM教师的
x
^
ψ
(
x
^
θ
,
t
,
t
)
\hat{x}_\psi(\hat{x}_{\theta,t},t)
x^ψ(x^θ,t,t)去噪预测过程作为蒸馏损失
L
distill
\mathcal{L}_\text{distill}
Ldistill的引导目标:
L
=
L
adv
G
(
x
^
θ
(
x
s
,
s
)
,
ϕ
)
+
λ
L
distill
(
x
^
θ
(
x
s
,
s
)
,
ψ
)
(1)
\mathcal{L}=\mathcal{L}_\text{adv}^\text{G}(\hat{x}_\theta(x_s,s),\phi)+\lambda\mathcal{L}_\text{distill}(\hat{x}_\theta(x_s,s),\psi)\tag{1}
L=LadvG(x^θ(xs,s),ϕ)+λLdistill(x^θ(xs,s),ψ)(1)
上述过程是基于像素域描述的,但在潜变量域上操作的过程是一样的。
3.2 Adversarial Loss
本文使用冻结的预训练特征网络
F
F
F和一些轻量判别器头
D
ϕ
,
k
\mathcal{D}_{\phi,k}
Dϕ,k。
对于特征网络
F
F
F,之前的工作提出ViTs做的很好。可训练的判别器头被放到
F
k
F_k
Fk上(特征网络上的不同层)。
实践中,使用额外的特征网络提取图像嵌入
c
img
c_\text{img}
cimg。
这里使用hinge loss作为对抗目标函数。ADD学生的对抗目标
L
adv
(
x
^
θ
(
x
s
,
s
)
,
ϕ
)
\mathcal{L}_\text{adv}(\hat{x}_\theta(x_s,s),\phi)
Ladv(x^θ(xs,s),ϕ)写作:
L
adv
G
(
x
^
θ
(
x
s
,
s
)
,
ϕ
)
=
−
E
s
,
ϵ
,
x
0
[
∑
k
D
ϕ
,
k
(
F
k
(
x
^
θ
(
x
s
,
s
)
)
)
]
(2)
\mathcal{L}_\text{adv}^\text{G}(\hat{x}_\theta(x_s,s),\phi)=-\mathbb{E}_{s,\epsilon,x_0}[\sum_k\mathcal{D}_{\phi,k}(F_k(\hat{x}_\theta(x_s,s)))]\tag{2}
LadvG(x^θ(xs,s),ϕ)=−Es,ϵ,x0[k∑Dϕ,k(Fk(x^θ(xs,s)))](2)
判别器头通过最小化下式训练:
L
adv
D
(
x
^
θ
(
x
s
,
s
)
,
ϕ
)
=
E
x
0
[
∑
k
max
(
0
,
1
−
D
ϕ
,
k
(
F
k
(
x
0
)
)
)
+
γ
R1
(
ϕ
)
]
+
E
x
^
θ
[
∑
k
max
(
0
,
1
+
D
ϕ
,
k
(
F
k
(
x
^
θ
)
)
)
]
(3)
\begin{aligned} \mathcal{L}_\text{adv}^\text{D}(\hat{x}_\theta(x_s,s),\phi)&=\mathbb{E}_{x_0}[\sum_k\max(0,1-\mathcal{D}_{\phi,k}(F_k(x_0)))+\gamma\text{R1}(\phi)] \\ &+\mathbb{E}_{\hat{x}_\theta}[\sum_k\max(0,1+\mathcal{D}_{\phi,k}(F_k(\hat{x}_\theta)))]\tag{3} \end{aligned}
LadvD(x^θ(xs,s),ϕ)=Ex0[k∑max(0,1−Dϕ,k(Fk(x0)))+γR1(ϕ)]+Ex^θ[k∑max(0,1+Dϕ,k(Fk(x^θ)))](3)
3.3 Score Distillation Loss
蒸馏损失可写为
L
distill
(
x
^
θ
(
x
s
,
s
)
,
ψ
)
=
E
t
,
ϵ
′
[
c
(
t
)
d
(
x
^
θ
,
x
^
ψ
(
sg
(
x
^
θ
,
t
)
;
t
)
)
]
(4)
\mathcal{L}_\text{distill}(\hat{x}_\theta(x_s,s),\psi)=\mathbb{E}_{t,\epsilon'}[c(t)d(\hat{x}_\theta,\hat{x}_\psi(\text{sg}(\hat{x}_{\theta,t});t))]\tag{4}
Ldistill(x^θ(xs,s),ψ)=Et,ϵ′[c(t)d(x^θ,x^ψ(sg(x^θ,t);t))](4)
其中
sg
\text{sg}
sg表示中断梯度操作。
d
d
d衡量ADD学生生成的样本
x
θ
x_\theta
xθ和DM教师的输出
x
^
ψ
(
x
^
θ
,
t
,
t
)
=
(
x
^
θ
,
t
−
σ
t
ϵ
^
ψ
(
x
^
θ
,
t
,
t
)
)
/
α
t
\hat{x}_\psi(\hat{x}_{\theta,t},t)=(\hat{x}_{\theta,t}-\sigma_t\hat{\epsilon}_\psi(\hat{x}_{\theta,t},t))/\alpha_t
x^ψ(x^θ,t,t)=(x^θ,t−σtϵ^ψ(x^θ,t,t))/αt之间的距离。
教师不是直接用在生成图像
x
^
θ
\hat{x}_\theta
x^θ上,而是扩散后的输出
x
^
θ
,
t
=
α
t
x
^
θ
+
σ
t
ϵ
′
\hat{x}_{\theta,t}=\alpha_t\hat{x}_\theta+\sigma_t \epsilon'
x^θ,t=αtx^θ+σtϵ′,因为对于教师而言和生成图像的数据分布不同。
定义距离函数
d
(
x
,
y
)
=
∣
∣
x
−
y
∣
∣
2
2
d(x,y)=||x-y||_2^2
d(x,y)=∣∣x−y∣∣22。
关于加权函数
c
(
t
)
c(t)
c(t),考虑两个选择:
- 指数加权(exponential weighting),即 c ( t ) = α t c(t)=\alpha_t c(t)=αt
- 分数蒸馏采样加权(score distillation sampling, SDS)。
实现过程中,
d
(
x
,
y
)
=
∣
∣
x
−
y
∣
∣
2
2
d(x,y)=||x-y||_2^2
d(x,y)=∣∣x−y∣∣22,且对
c
(
t
)
c(t)
c(t)有特定的选择时,蒸馏损失和SDS目标
L
SDS
\mathcal{L}_\text{SDS}
LSDS等价。SDS损失为:
L
SDS
(
ϕ
,
x
=
g
(
θ
)
)
=
∇
θ
E
t
[
σ
t
/
σ
t
w
(
t
)
KL
(
q
(
z
t
∣
g
(
θ
)
;
y
,
t
)
∣
∣
p
θ
(
z
t
;
y
,
t
)
)
]
\mathcal{L}_\text{SDS}(\phi,x=g(\theta))=\nabla_\theta\mathbb{E}_t[\sigma_t/\sigma_tw(t)\text{KL}(q(z_t|g(\theta);y,t)||p_\theta(z_t;y,t))]
LSDS(ϕ,x=g(θ))=∇θEt[σt/σtw(t)KL(q(zt∣g(θ);y,t)∣∣pθ(zt;y,t))]
本文公式的优点是它能够使重建目标直接可视化,并且它自然地促进了连续几个去噪步骤的执行。