Faker:自动化测试数据生成利器
- 前言
- 1. 安装
- 2. 多语言支持
- 3. 常用方法
- 3.1 生成姓名和地址
- 3.2 生成电子邮件和电话号码
- 3.3 生成日期和时间
- 3.4 生成公司名称和职位
- 3.5 生成文本和段落
- 3.6 生成图片和颜色
- 3.7 生成用户代理和浏览器信息
- 3.8 生成文件和目录
- 3.9 生成UUID和哈希
- 3.10 生成信用卡信息和银行信息
- 总结
前言
- 在自动化测试中,无论是测试用户注册、登录、数据展示还是API接口,都需要大量的测试数据来支持;
- Faker库正是为了解决这一问题而生。它支持多种编程语言,能够生成各种类型的假数据,如姓名、地址、电子邮件、电话号码等;
- 使用Faker,我们可以轻松创建出符合特定格式和规则的数据,极大地提高了测试的效率和质量。
1. 安装
在开始使用Faker之前,我们需要先将其安装到我们的测试环境中。
Faker可以通过以下pip命令进行安装:
pip install faker
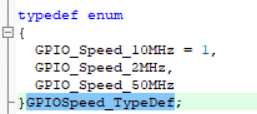
安装成功如下图所示:

安装成功后,我们就可以在Python脚本中导入并使用Faker了。
from faker import Faker # 导入Faker库
fake = Faker()
print(fake.name()) # 生成一个随机的姓名
Faker库的使用非常简单,只需几行代码即可生成所需的数据。
2. 多语言支持
Faker不仅支持英语,还支持多种其他语言,如中文、日语、法语、德语等。要使用特定语言的数据生成,我们只需在创建Faker实例时指定语言代码即可。
from faker import Faker
fake_cn = Faker('zh_CN')
print(fake_cn.name())
print(fake_cn.address())
fake_jp = Faker('ja_JP')
print(fake_jp.name())
print(fake_jp.address())
执行结果如下:

以上代码是如何生成中文和日文的姓名和地址。通过指定不同的语言代码,Faker可以灵活地生成各种语言环境下的假数据。
3. 常用方法
Faker库提供了丰富的数据生成方法,涵盖了各种常见的数据类型。
以下是一些常用的方法及其示例:
3.1 生成姓名和地址
from faker import Faker
fake = Faker()
print(fake.name()) # 生成一个随机的姓名
print(fake.address()) # 生成一个随机的地址
3.2 生成电子邮件和电话号码
print(fake.email()) # 生成一个随机的电子邮件
print(fake.phone_number()) # 生成一个随机的电话号码
3.3 生成日期和时间
print(fake.date()) # 生成一个随机的日期
print(fake.date_time()) # 生成一个随机的日期时间
3.4 生成公司名称和职位
print(fake.company()) # 生成一个随机的公司名称
print(fake.job()) # 生成一个随机的职位
3.5 生成文本和段落
print(fake.text(max_nb_chars=200)) # 生成一个200字符的随机文本
print(fake.paragraph(nb_sentences=3)) # 生成一个包含3个句子的随机段落
3.6 生成图片和颜色
print(fake.image_url()) # 生成一个随机的图片URL
print(fake.color_name()) # 生成一个随机的颜色名称
3.7 生成用户代理和浏览器信息
print(fake.user_agent()) # 生成一个随机的用户代理
print(fake.chrome()) # 生成一个随机的Chrome浏览器信息
3.8 生成文件和目录
print(fake.file_name()) # 生成一个随机的文件名
print(fake.directory()) # 生成一个随机的目录名
3.9 生成UUID和哈希
print(fake.uuid4()) # 生成一个随机的UUID
print(fake.sha256()) # 生成一个随机的SHA256哈希
3.10 生成信用卡信息和银行信息
print(fake.credit_card_number()) # 生成一个随机的信用卡号
print(fake.bank_country()) # 生成一个随机的银行国家
总结
通过本文的介绍和示例,相信大家对Faker有了更深入的了解。在实际测试工作中,合理利用Faker库,可以为我们节省大量的时间和精力,让我们专注于测试用例的设计和优化。