Apache Paimon是一种流批统一的数据湖存储格式,结合Flink及Spark构建流批处理的实时湖仓一体架构。Paimon创新地将湖格式与LSM技术结合起来,给数据湖带来了实时流更新以及完整的流处理能力。借助实时计算Flink版与Apache Paimon,可以快速地在云端OSS上构建数据湖存储服务。
Apache Paimon提供以下核心能力:
-
实时入湖能力增强:实时计算Flink版提供了丰富的入湖方式,支持自动同步Schema变更,允许快速将包括MySQL在内的多种数据库系统的实时变化同步至数据湖,在千万级数据规模下也能保持高效率与低延迟。
-
湖上流批一体处理:Paimon结合Flink提供了完整的流处理能力,结合Spark提供了完整的批处理能力。基于统一的数据湖存储,提供数据口径一致的流批一体处理,提高易用性并降低成本。
-
全面生态集成拓展:Paimon与众多计算紧密集成,实时计算Flink版、E-MapReduce(Spark、StarRocks、Hive或Trino)、MaxCompute都与Paimon有着较为完善的集成度,统一存储,计算无边界。
-
湖仓存储格式革新:Paimon在流批技术处理的基础上,提出Deletion Vectors和索引来增强查询性能,在分钟级时效性基础上满足流、批、OLAP等场景的全方位支持。
更多信息请参见Apache Paimon。
使用指南
初次使用
-
如果您想要快速开始体验Paimon,详情请参见Paimon快速开始:基本功能。
-
如果您需要根据主键更新数据,请使用Paimon主键表。如果您没有更新数据的需求,仅需要将无主键的数据导入Paimon表,请使用Paimon Append Only表(非主键表)。
-
如果您想要了解Paimon的时效性与一致性,详情请参见Paimon的时效性与一致性。
-
如果您想要了解利用Flink+Paimon构建流式湖仓的方法,详情请参见基于Flink+Paimon搭建流式湖仓。
创建Paimon Catalog
Paimon Catalog可以方便地管理同一个目录下的所有Paimon表,并与其它阿里云产品连通。我们支持通过Paimon Catalog创建并操作Paimon表。
-
如果您想要创建并使用Paimon Catalog,详情请参见管理Paimon Catalog。
-
如果您想要将Paimon表的元数据同步至数据湖构建DLF,详情请参见管理Paimon Catalog。
-
如果您想要在云原生大数据计算服务MaxCompute中同步创建Paimon外表,以便后续从MaxCompute中对Paimon表进行查询,详情请参见管理Paimon Catalog。
-
如果您想要同时将Paimon表的元数据同步至DLF,并在MaxCompute中创建Paimon外表,详情请参见管理Paimon Catalog。
创建Paimon表
-
如果您想要在Paimon Catalog中创建Paimon表,详情请参见使用Paimon Catalog。
-
如果您想要利用CREATE TABLE AS(CTAS)语句或CREATE DATABASE AS(CDAS)语句,从MySQL、消息队列Kafka等数据源将表同步到Paimon Catalog中,详情请参见通过CREATE TABLE AS(CTAS)语句或REATE DATABASE AS(CDAS)语句创建表。
向Paimon表写入数据
-
如果您想要往Paimon表写入数据或更新数据,详情请参见向Paimon表写入数据。
-
如果您想要在Paimon表中进行数据的打宽和聚合等操作,详情请参见数据合并机制。
-
如果您想要覆写Paimon表的分区,或覆写整张Paimon表,详情请参见通过INSERT OVERWRITE语句覆写数据。
-
如果您想要从Paimon表中删除数据或部分分区,详情请参见通过DELETE语句删除数据。
-
如果您想要删除Paimon表的部分分区,详情请参见管理Paimon Catalog。
从Paimon表消费数据
-
如果您想要从Paimon表中查询或消费数据,详情请参见从Paimon表消费数据。如果您想要对Paimon主键表进行流式消费,请先了解变更数据产生机制。
-
如果您想要从指定位点开始流式消费Paimon表,详情请参见从指定位点消费Paimon表。
-
如果您想保存Paimon表的消费进度,或防止正在被流式消费的快照文件因过期被删除,详情请参见指定Consumer ID。
-
如果您想要利用批作业查询Paimon表过去的状态,详情请参见Batch Time Travel。
Paimon表的维护
-
如果您想要了解Paimon的常见问题,详情请参见上下游存储。
-
如果您想要了解读写Paimon表的常见优化,详情请参见Paimon性能优化。
-
如果您想要查询Paimon表目前有哪些分区,文件总数是多少等数据,详情请参见Paimon系统表。
-
如果您想要修改Paimon Catalog表结构,例如增加一列,或修改列名等,详情请参见管理Paimon Catalog。
-
如果您想要删除Paimon Catalog表,详情请参见删除Paimon Catalog表。
-
如果您想要调整Paimon的分桶数量,详情请参见调整固定分桶表的分桶数量。
-
如果您想要清理表目录下的废弃文件,详情请参见清理过期数据。
使用Flink+Hologres搭建实时数仓可以充分利用Flink强大的实时处理能力和Hologres提供的Binlog、行列共存和资源强隔离等能力,实现高效、可扩展的实时数据处理和分析,帮助您更好地应对不断增长的数据量和实时业务需求。本文介绍如何通过实时计算Flink版和实时数仓Hologres搭建实时数仓。
背景信息
随着社会数字化发展,企业对数据时效性的需求越来越强烈。除传统的面向海量数据加工场景设计的离线场景外,大量业务需要解决面向实时加工、实时存储、实时分析的实时场景问题。传统离线数仓搭建的方法论比较明确,通过定时调度实现数仓分层(ODS->DWD->DWS->ADS);但对于实时数仓的搭建,目前缺乏明确的方法体系。基于Streaming Warehouse理念,实现数仓分层之间实时数据的高效流动,可以解决实时数仓分层问题。
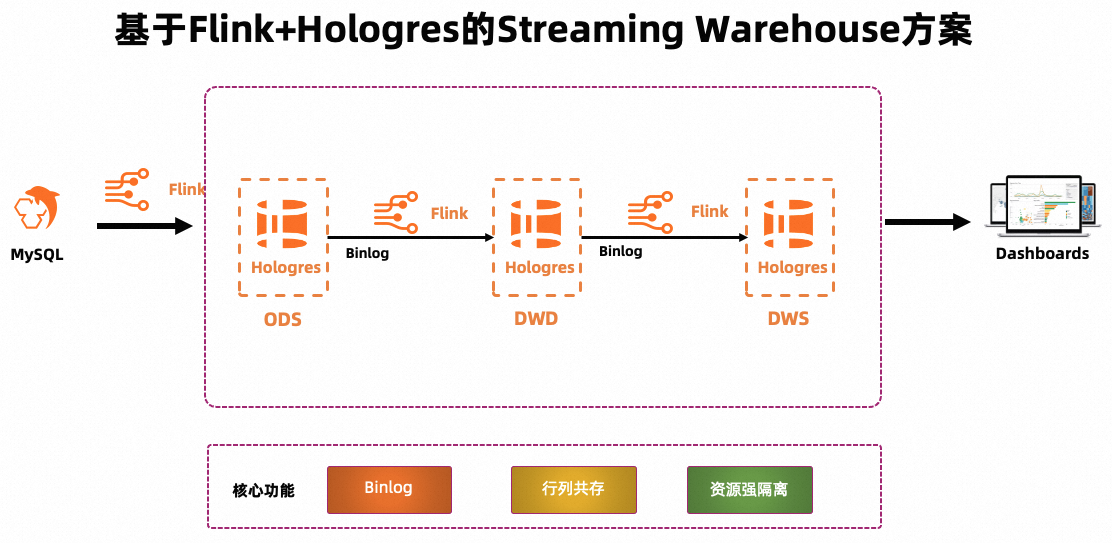
方案架构
实时计算Flink版是强大的流式计算引擎,支持对海量实时数据高效处理。Hologres是一站式实时数仓,支持数据实时写入与更新,实时数据写入即可查。Hologres与Flink深度集成,能够提供一体化的实时数仓联合解决方案。本文基于Flink+Hologres搭建实时数仓的方案架构如下:
-
Flink将数据源写入Hologres,形成ODS层。
-
Flink订阅ODS层的Binlog进行加工,形成DWD层再次写入Hologres。
-
Flink订阅DWD层的Binlog,通过计算形成DWS层,再次写入Hologres。
-
最后由Hologres对外提供应用查询。
该方案有如下优势:
-
Hologres的每一层数据都支持高效更新与修正、写入即可查,解决了传统实时数仓解决方案的中间层数据不易查、不易更新、不易修正的问题。
-
Hologres的每一层数据都可单独对外提供服务,数据的高效复用,真正实现数仓分层复用的目标。
-
模型统一,架构简化。实时ETL链路的逻辑是基于Flink SQL实现的;ODS层、DWD层和DWS层的数据统一存储在Hologres中,可以降低架构复杂度,提高数据处理效率。
该方案依赖于Hologres的3个核心能力,详情如下表所示。
| Hologres核心能力 | 详情 |
| Binlog | Hologres提供Binlog能力,用于驱动Flink进行实时计算,以此作为流式计算的上游。Hologres的Binlog能力详情请参见订阅Hologres Binlog。 |
| 行列共存 | Hologres支持行列共存的存储格式。一张表同时存储行存数据和列存数据,并且两份数据强一致。该特性保证中间层表不仅可以作为Flink的源表,也可以作为Flink的维表进行主键点查与维表Join,还可以供其他应用(OLAP、线上服务等)查询。Hologres的行列共存能力详情请参见表存储格式:列存、行存、行列共存。 |
| 资源强隔离 | Hologres实例的负载较高时,可能影响中间层的点查性能。Hologres支持通过主从实例读写分离部署(共享存储)或计算组实例架构实现资源强隔离,从而保证Flink对Hologres Binlog的数据拉取不影响线上服务。 |
实践场景
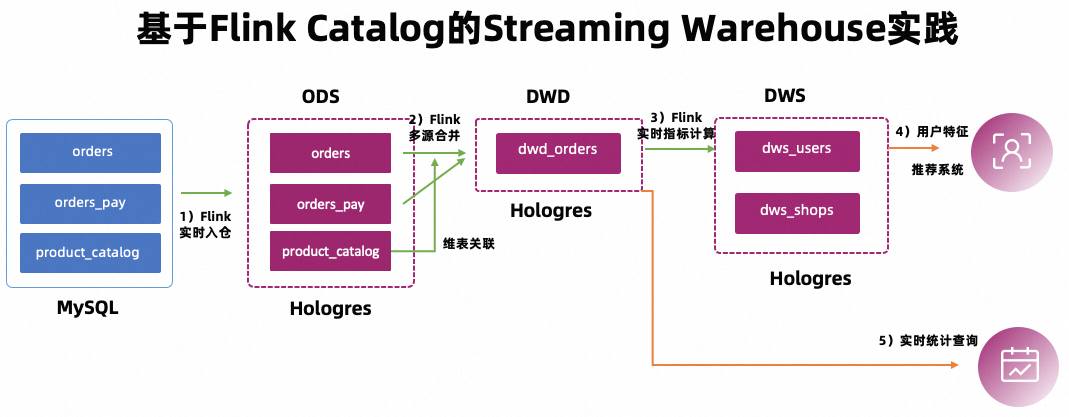
本文以某个电商平台为例,通过搭建一套实时数仓,实现数据的实时加工清洗和对接上层应用数据查询,形成实时数据的分层和复用,支撑各个业务方的报表查询(交易大屏、行为数据分析、用户画像标签)以及个性化推荐等多个业务场景。
-
构建ODS层:业务数据库实时入仓
MySQL有orders(订单表),orders_pay(订单支付表),product_catalog(商品类别字典表)3张业务表,这3张表通过Flink实时同步到Hologres中作为ODS层。
-
构建DWD层:实时主题宽表
将订单表、商品类别字典表、订单支付表进行实时打宽,生成DWD层宽表。
-
构建DWS层:实时指标计算
实时消费宽表的binlog,事件驱动地聚合出相应的DWS层指标表。
注意事项
-
仅实时计算引擎VVR 6.0.7及以上版本支持该实时数仓方案。
-
仅1.3及以上版本的独享Hologre实例支持该实时数仓方案。
-
实时计算Flink版、RDS MySQL和Hologres需要在同一VPC。如果不在同一VPC,需要先打通跨VPC的网络或者使用公网的形式访问,详情请参见如何访问跨VPC的其他服务?和Flink全托管如何访问公网?。
-
通过RAM用户或RAM角色等身份访问实时计算Flink、Hologres和RDS MySQL资源时,需要其具备对应资源的权限。
准备工作
创建RDS MySQL实例并准备数据源
-
创建RDS MySQL实例,详情请参见创建RDS MySQL实例。
-
创建数据库和账号。
为目标实例创建名称为order_dw的数据库和具有对应数据库读写权限的普通账号。具体操作请参见创建数据库和账号和管理数据库。
-
准备MySQL CDC数据源。
-
在目标实例详情页面,单击上方的登录数据库。
-
在弹出的DMS页面中,填写创建的数据库账号名和密码,然后单击登录。
-
登录成功后,在左侧双击order_dw数据库,切换数据库。
-
在SQL Console区域编写三张业务表的建表DDL以及插入的数据语句。
CREATE TABLE `orders` ( order_id bigint not null primary key, user_id varchar(50) not null, shop_id bigint not null, product_id bigint not null, buy_fee numeric(20,2) not null, create_time timestamp not null, update_time timestamp not null default now(), state int not null ); CREATE TABLE `orders_pay` ( pay_id bigint not null primary key, order_id bigint not null, pay_platform int not null, create_time timestamp not null ); CREATE TABLE `product_catalog` ( product_id bigint not null primary key, catalog_name varchar(50) not null ); -- 准备数据 INSERT INTO product_catalog VALUES(1, 'phone_aaa'),(2, 'phone_bbb'),(3, 'phone_ccc'),(4, 'phone_ddd'),(5, 'phone_eee'); INSERT INTO orders VALUES (100001, 'user_001', 12345, 1, 5000.05, '2023-02-15 16:40:56', '2023-02-15 18:42:56', 1), (100002, 'user_002', 12346, 2, 4000.04, '2023-02-15 15:40:56', '2023-02-15 18:42:56', 1), (100003, 'user_003', 12347, 3, 3000.03, '2023-02-15 14:40:56', '2023-02-15 18:42:56', 1), (100004, 'user_001', 12347, 4, 2000.02, '2023-02-15 13:40:56', '2023-02-15 18:42:56', 1), (100005, 'user_002', 12348, 5, 1000.01, '2023-02-15 12:40:56', '2023-02-15 18:42:56', 1), (100006, 'user_001', 12348, 1, 1000.01, '2023-02-15 11:40:56', '2023-02-15 18:42:56', 1), (100007, 'user_003', 12347, 4, 2000.02, '2023-02-15 10:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2001, 100001, 1, '2023-02-15 17:40:56'), (2002, 100002, 1, '2023-02-15 17:40:56'), (2003, 100003, 0, '2023-02-15 17:40:56'), (2004, 100004, 0, '2023-02-15 17:40:56'), (2005, 100005, 0, '2023-02-15 18:40:56'), (2006, 100006, 0, '2023-02-15 18:40:56'), (2007, 100007, 0, '2023-02-15 18:40:56');
-
-
单击执行,单击直接执行。
创建Hologres实例和计算组
-
创建独享Hologres实例,详情请参见购买Hologres。
为了体验Hologres通过读写分离实现资源强隔离的核心能力,本文以计算组型实例为例为您进行介绍。
-
在HoloWeb页面连接目标实例后,创建数据库并授权。
创建名为order_dw的数据库(需要开启简单权限模型),并授予用户admin权限。数据库创建和授权操作,请参见DB管理。
说明
-
如果在被授权账号的下拉列表找不到对应的账号,则说明该账号并未添加至当前实例,您需要前往用户管理页面添加用户为SuperUser。
-
Hologres2.0之后版本默认开启binlog扩展,无需手动执行。Hologres1.3版本在创建完数据库后,需要执行
create extension hg_binlog命令才能开启binlog扩展。
-
-
新增计算组。
您可以通过不同的计算组实现资源隔离,使用初始计算组init_warehouse用于写入数据,使用read_warehouse_1计算组用于服务查询。
预留计算资源会全部分配给初始计算组init_warehouse,需先减少计算组资源,再新增计算组。详情请参见场景1:创建全新的计算组实例。
-
单击安全中心 > 计算组管理,确认实例名为目标实例名称。
-
单击已有资源组init_warehouse操作列下的调整配置,调小资源后单击确认。
-
单击新增计算组,新增名称为read_warehouse_1的计算组,单击确认。
-
创建Flink工作空间和Catalog
-
创建Flink工作空间,详情请参见开通实时计算Flink版。
-
登录实时计算控制台,单击目标工作空间操作列下的控制台。
-
创建Session集群,为后续创建Catalog和查询脚本提供执行环境,详情请参见步骤一:创建Session集群。
-
创建Hologres Catalog。
在数据开发 > 数据查询页面的查询脚本页签,将如下代码拷贝到查询脚本,并修改目标参数取值,选中目标片段后单击左侧代码行上的运行。
CREATE CATALOG dw WITH ( 'type' = 'hologres', 'endpoint' = '<ENDPOINT>', 'username' = '<USERNAME>', 'password' = '<PASSWORD>', 'dbname' = 'order_dw@init_warehouse', --数据库名称,并指定连接init_warehouse计算组。 'binlog' = 'true', -- 创建catalog时可以设置源表、维表和结果表支持的with参数,之后在使用此catalog下的表时会默认添加这些默认参数。 'sdkMode' = 'jdbc', -- 推荐使用jdbc模式。 'cdcmode' = 'true', 'connectionpoolname' = 'the_conn_pool', 'ignoredelete' = 'true', -- 宽表merge需要开启,防止回撤。 'partial-insert.enabled' = 'true', -- 宽表merge需要开启此参数,实现部分列更新。 'mutateType' = 'insertOrUpdate', -- 宽表merge需要开启此参数,实现部分列更新。 'table_property.binlog.level' = 'replica', --也可以在创建catalog时传入持久化的hologres表属性,之后创建表时,默认都开启binlog。 'table_property.binlog.ttl' = '259200' );您需要修改以下参数取值为您实际Hologres服务信息。
参数
说明
备注
endpoint
Hologres的Endpoint地址。
详情请参见实例配置。
username
阿里云账号的AccessKey ID。
当前配置的AccessKey对应的用户需要能够访问所有的Hologres数据库,Hologres数据库权限请参见Hologres权限模型概述。
password
阿里云账号的AccessKey Secret。
说明
创建Catalog时可以设置默认的源表、维表和结果表的WITH参数,也可以设置创建Hologres物理表的默认属性,例如上方table_property开头的参数。详情请参见管理Hologres Catalog和实时数仓Hologres WITH参数。
-
创建MySQL Catalog。
将如下代码拷贝到查询脚本,并修改目标参数取值,选中目标片段后单击左侧代码行上的运行。
CREATE CATALOG mysqlcatalog WITH( 'type' = 'mysql', 'hostname' = '<hostname>', 'port' = '<port>', 'username' = '<username>', 'password' = '<password>', 'default-database' = 'order_dw' );您需要修改以下参数取值为您实际的MySQL服务信息。
参数
说明
hostname
MySQL数据库的IP地址或者Hostname。
port
MySQL数据库服务的端口号,默认值为3306。
username
MySQL数据库服务的用户名。
password
MySQL数据库服务的密码。
搭建实时数仓
构建ODS层:业务数据库实时入仓
基于Catalog的CREATE DATABASE AS(CDAS)语句功能,可以一次性把ODS层建出来。ODS层一般不直接做OLAP或SERVING(KV点查),主要作为流式作业的事件驱动,开启binlog即可满足需求。Binlog是Hologres的核心能力之一,Hologres连接器也支持先全量读取再增量消费Binlog的全增量模式。
-
创建CDAS同步作业ODS。
-
在数据开发 > ETL页面,新建名为ODS的SQL流作业,并将如下代码拷贝到SQL编辑器。
CREATE DATABASE IF NOT EXISTS dw.order_dw -- 创建catalog时设置了table_property.binlog.level参数,因此通过CDAS创建的所有表都开启了binlog。 AS DATABASE mysqlcatalog.order_dw INCLUDING all tables -- 可以根据需要选择上游数据库需要入仓的表。 /*+ OPTIONS('server-id'='8001-8004') */ ; -- 指定mysql-cdc实例server-id范围。说明
-
本示例默认将数据同步到数据库order_dw的Public Schema下。您也可以将数据同步到Hologres目标库的指定Schema中,详情请参见作为CDAS的目标端Catalog,指定后使用Catalog时的表名格式也会发生变化,详情请参见使用Hologres Catalog。
-
如果源表的数据结构发生变化,则需要等待源表的数据出现变更(删除、插入、更新),结果表的数据结构才会看到变化。
-
-
单击右上方的部署,进行作业部署。
-
单击左侧导航栏的运维中心 > 作业运维,单击刚刚部署的ODS作业操作列的启动,选择无状态启动后单击启动。
-
-
向计算组加载数据。
Table Group是Hologres中数据的载体。使用read_warehouse_1查询order_dw数据库中Table Group(本示例为order_dw_tg_default)的数据时,为计算组read_warehouse_1加载order_dw_tg_default,以实现使用
init_warehouse计算组写入数据,使用read_warehouse_1计算组进行服务查询。在HoloWeb开发页单击SQL编辑器,确认实例名和数据库名称后,执行如下命令。更多详情请参见场景1:创建全新的计算组实例。加载后,可以查看到read_warehouse_1已经加载了order_dw_tg_default Table Group的数据。
--查看当前数据库有哪些Table Group SELECT tablegroup_name FROM hologres.hg_table_group_properties GROUP BY tablegroup_name; --为计算组加载Table Group CALL hg_table_group_load_to_warehouse ('order_dw.order_dw_tg_default', 'read_warehouse_1', 1); --查看计算组加载Table Group的情况 select * from hologres.hg_warehouse_table_groups; -
在右上角切换计算组为read_warehouse_1,后续使用read_warehouse_1进行查询分析。

-
在HoloWeb中执行如下命令,查看MySQL同步到Hologres的3张表数据。
---查orders中的数据。 SELECT * FROM orders; ---查orders_pay中的数据。 SELECT * FROM orders_pay; ---查product_catalog中的数据。 SELECT * FROM product_catalog;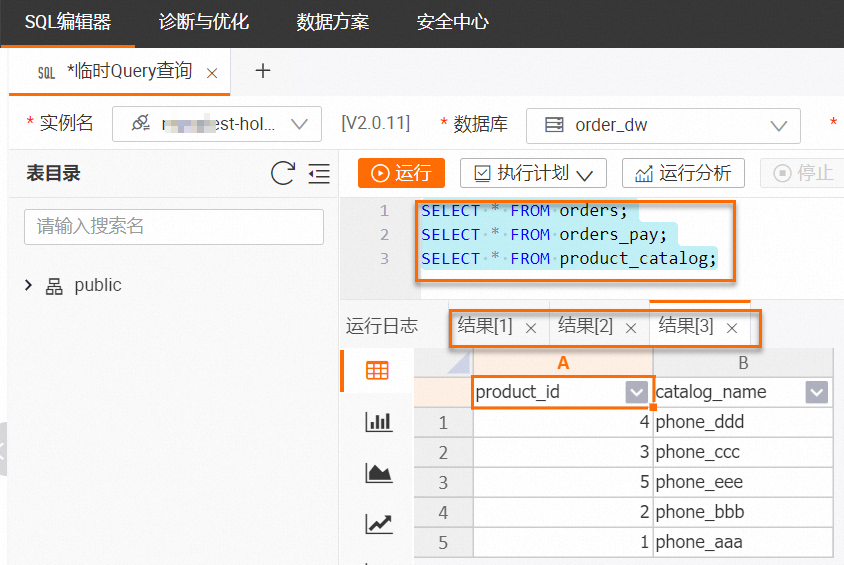
构建DWD层:实时主题宽表
构建DWD层用到了Hologres连接器特有的部分列更新能力,可以使用INSERT DML方便地表达部分列更新的语义。作业中需要对不同的维表进行查询,是基于Hologres行存以及行列共存表提供的高性能的点查能力。同时,Hologres资源强隔离的架构,可以保证写入、读取、分析等作业之间互不干扰。
-
通过Flink Catalog功能在Hologres中建DWD层的宽表dwd_orders。
在数据开发 > 数据查询页面的查询脚本页签,将如下代码拷贝到查询脚本后,选中目标片段后单击左侧代码行上的运行。
-- 宽表字段要nullable,因为不同的流写入到同一张结果表,每一列都可能出现null的情况。 CREATE TABLE dw.order_dw.dwd_orders ( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int comment 'platform 0: phone, 1: pc', pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ); -- 支持通过catalog修改Hologres物理表属性。 ALTER TABLE dw.order_dw.dwd_orders SET ( 'table_property.binlog.ttl' = '604800' --修改binlog的超时时间为一周。 ); -
实现实时消费ODS层orders、orders_pay表的binlog。
在数据开发 > ETL页面,新建名为DWD的SQL流作业,并将如下代码拷贝到SQL编辑器后,部署并启动作业。通过如下SQL作业,orders表会与product_catalog表进行维表关联,将最终结果写入dwd_orders表中,实现数据的实时打宽。
BEGIN STATEMENT SET; INSERT INTO dw.order_dw.dwd_orders ( order_id, order_user_id, order_shop_id, order_product_id, order_fee, order_create_time, order_update_time, order_state, order_product_catalog_name ) SELECT o.*, dim.catalog_name FROM dw.order_dw.orders as o LEFT JOIN dw.order_dw.product_catalog FOR SYSTEM_TIME AS OF proctime() AS dim ON o.product_id = dim.product_id; INSERT INTO dw.order_dw.dwd_orders (pay_id, order_id, pay_platform, pay_create_time) SELECT * FROM dw.order_dw.orders_pay; END; -
查看宽表dwd_orders数据。
在HoloWeb开发页面连接Hologres实例并登录目标数据库后,在SQL编辑器上执行如下命令。
SELECT * FROM dwd_orders;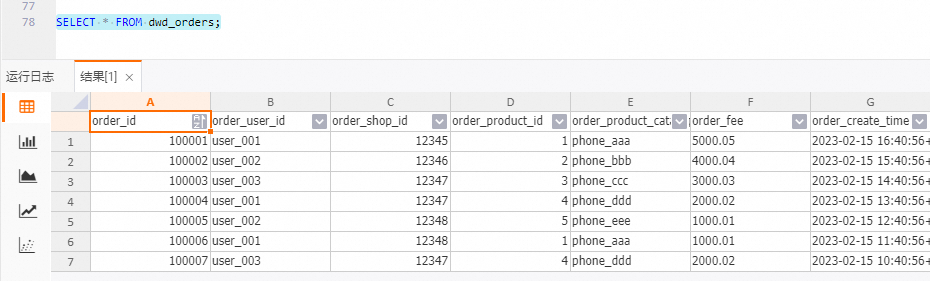
构建DWS层:实时指标计算
-
通过Flink Catalog功能,在Hologres中创建dws层的聚合dws_users以及dws_shops。
在数据开发 > 数据查询页面的查询脚本页签,将如下代码拷贝到查询脚本后,选中目标片段后单击左侧代码行上的运行。
-- 用户维度聚合指标表。 CREATE TABLE dw.order_dw.dws_users ( user_id string not null, ds string not null, paied_buy_fee_sum numeric(20,2) not null comment '当日完成支付的总金额', primary key(user_id,ds) NOT ENFORCED ); -- 商户维度聚合指标表。 CREATE TABLE dw.order_dw.dws_shops ( shop_id bigint not null, ds string not null, paied_buy_fee_sum numeric(20,2) not null comment '当日完成支付总金额', primary key(shop_id,ds) NOT ENFORCED ); -
实时消费DWD层的宽表dw.order_dw.dwd_orders,在Flink中做聚合计算,最终写入Hologres中的DWS表。
在数据开发 > ETL页面,新建名为DWS的SQL流作业,并将如下代码拷贝到SQL编辑器后,部署并启动作业。
BEGIN STATEMENT SET; INSERT INTO dw.order_dw.dws_users SELECT order_user_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds, SUM (order_fee) FROM dw.order_dw.dwd_orders c WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL -- 订单流和支付流数据都已写入宽表。 GROUP BY order_user_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd'); INSERT INTO dw.order_dw.dws_shops SELECT order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds, SUM (order_fee) FROM dw.order_dw.dwd_orders c WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL -- 订单流和支付流数据都已写入宽表。 GROUP BY order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd'); END; -
查看DWS层的聚合结果,其结果会根据上游数据的变更实时更新。
-
在Hologres控制台查看变更前数据
-
查询dws_users表结果。
SELECT * FROM dws_users;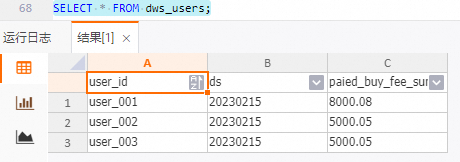
-
查询dws_shops表结果。
SELECT * FROM dws_shops;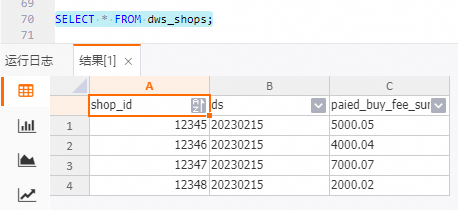
-
-
在RDS控制台向order_dw数据库orders和orders_pay表中分别插入1条新数据。
INSERT INTO orders VALUES (100008, 'user_003', 12345, 5, 6000.02, '2023-02-15 09:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2008, 100008, 1, '2023-02-15 19:40:56'); -
在Hologres控制台查看变更后的数据。
-
dwd_orders表
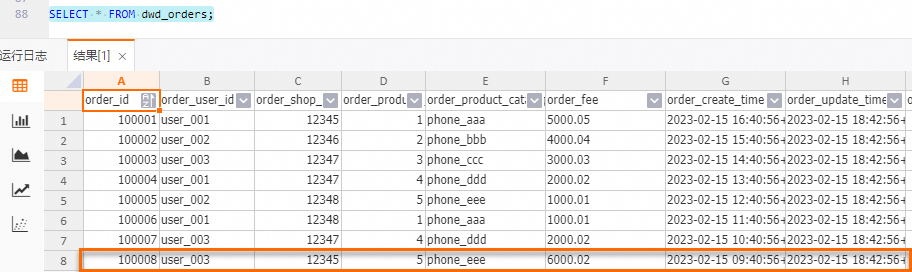
-
dws_users表
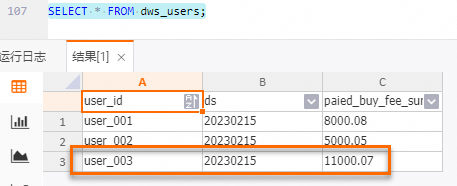
-
dws_shops表
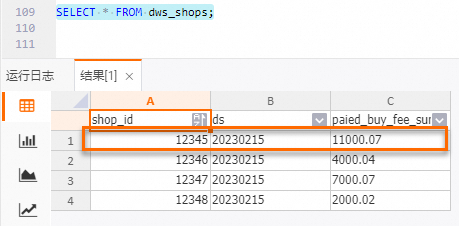
-
-
数据探查
因为开启了Binlog,所以可直接探查到数据的变化情况。如果对中间结果需要即席(Ad-hoc)性质的业务数据探查,或者对最终计算结果进行数据正确性排查,此方案的每一层数据都实现了持久化,可以便捷地探查中间过程。
-
流模式探查
-
新建并启动数据探查流作业。
在数据开发 > ETL页面,新建名为Data-exploration的SQL流作业,并将如下代码拷贝到SQL编辑器后,部署并启动作业。
-- 流模式探查,打印到print可以看到数据的变化情况。 CREATE TEMPORARY TABLE print_sink( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int, pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'print' ); INSERT INTO print_sink SELECT * FROM dw.order_dw.dwd_orders /*+ OPTIONS('startTime'='2023-02-15 12:00:00') */ --这里的startTime是binlog生成的时间 WHERE order_user_id = 'user_001'; -
查看数据探查结果。
在运维中心 > 作业运维详情页面,单击目标作业名称,在作业日志页签下左侧运行日志页签,单击运行Task Managers页签下的Path, ID。在Stdout页面搜索user_001相关的日志信息。
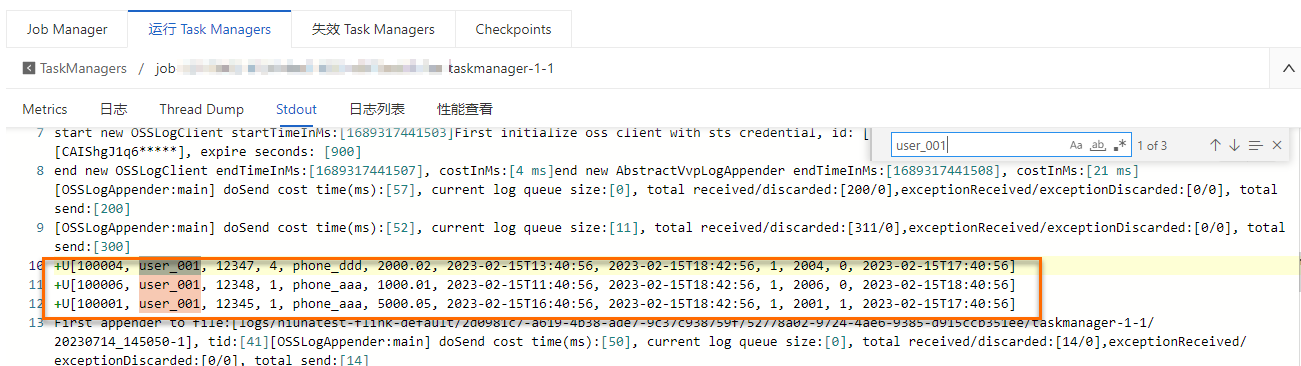
-
-
批模式探查
在数据开发 > ETL页面,创建SQL流作业,并将如下代码拷贝到SQL编辑器后,单击调试。详情请参见作业调试。
批模式探查是获取当前时刻的终态数据,在Flink作业开发界面调试结果如下图所示。
SELECT * FROM dw.order_dw.dwd_orders /*+ OPTIONS('binlog'='false') */ WHERE order_user_id = 'user_001' and order_create_time > '2023-02-15 12:00:00'; --批量模式支持filter下推,提升批作业执行效率。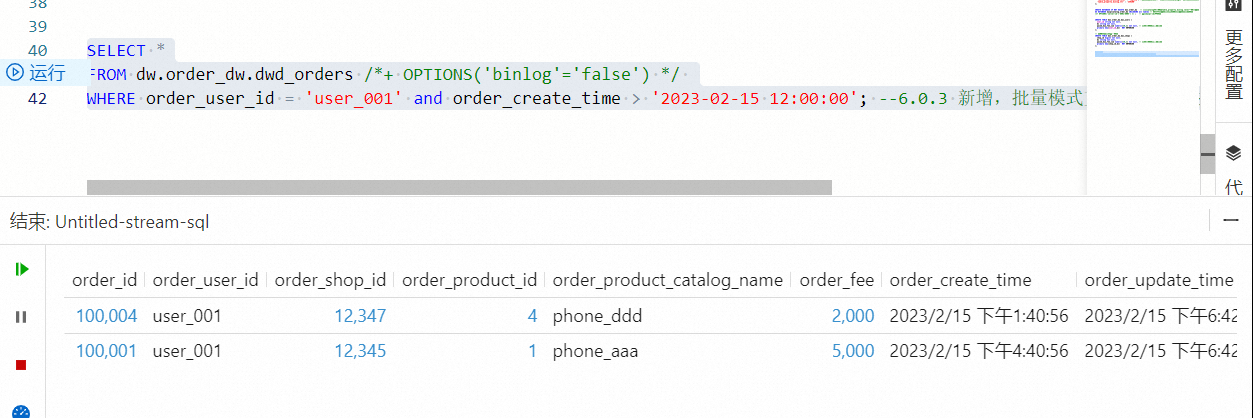
使用实时数仓
上一小节展示了通过Flink Catalog,可以仅在Flink侧搭建一个基于Flink和Hologres的Streaming Warehouse实时分层数仓。本节则展示数仓搭建完成之后的一些简单应用场景。
Key-Value服务
根据主键查询DWS层的聚合指标表,支持百万级RPS。
在HoloWeb开发页面查询指定用户指定日期的消费额的代码示例如下。
-- holo sql
SELECT * FROM dws_users WHERE user_id ='user_001' AND ds = '20230215';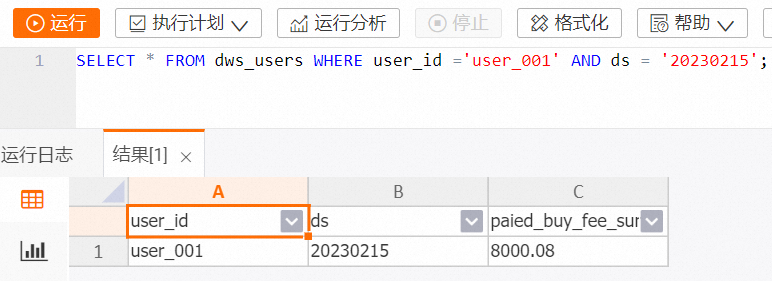
明细查询
对DWD层宽表进行OLAP分析。
在HoloWeb开发页面查询某个客户23年2月特定支付平台支付的订单明细的代码示例如下。
-- holo sql
SELECT * FROM dwd_orders
WHERE order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
AND order_user_id = 'user_001'
AND pay_platform = 0
ORDER BY order_create_time LIMIT 100;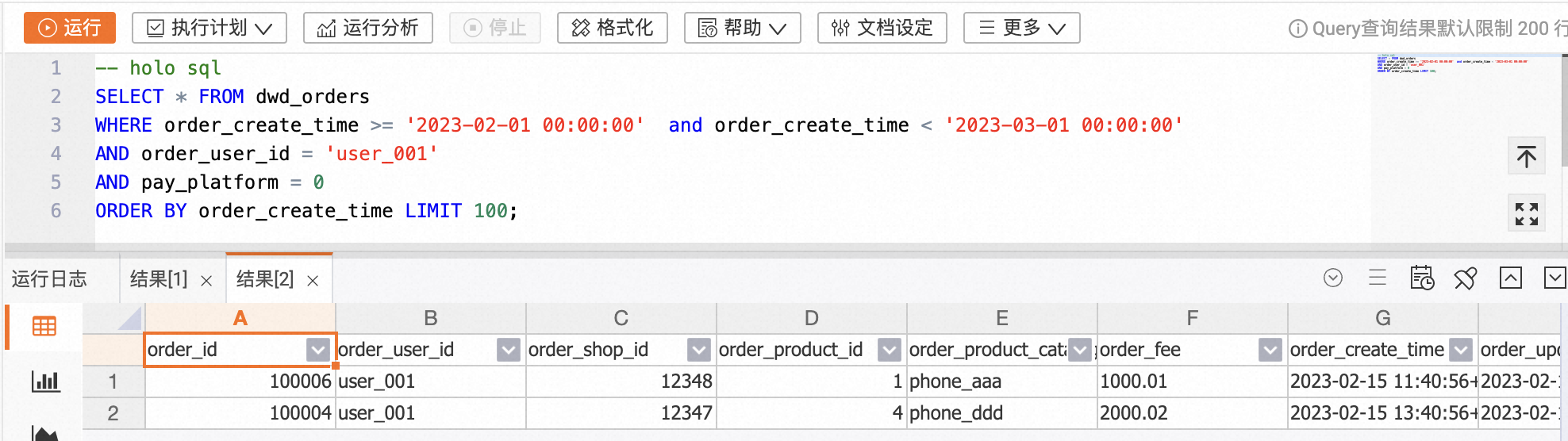
实时报表
基于DWD层宽表数据展示实时报表,Hologres的行列共存以及列存表有非常优秀的OLAP分析能力,支持秒级响应。
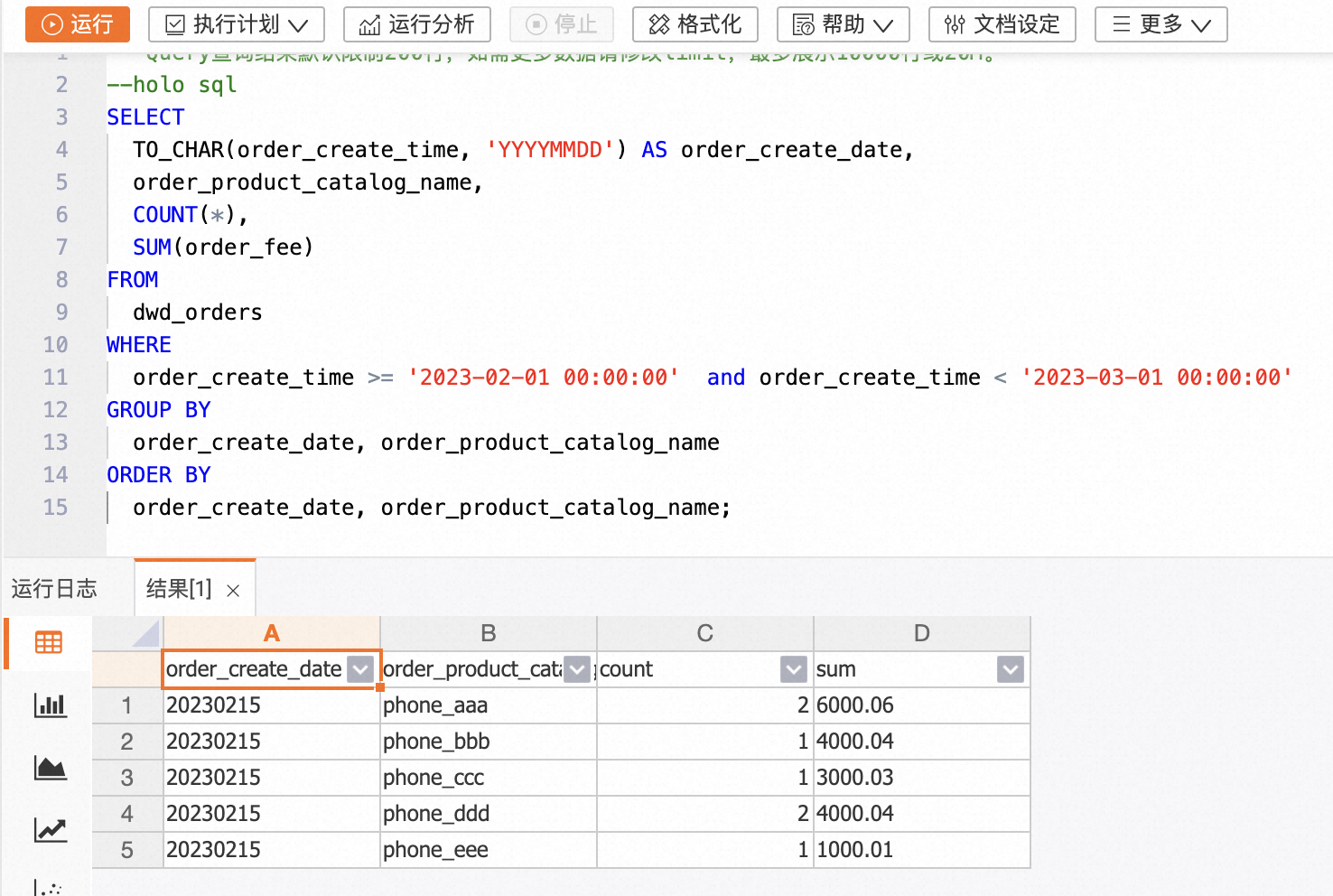
在HoloWeb开发页面查询23年2月内每个品类的订单总量和订单总金额的代码示例如下。
-- holo sql
SELECT
TO_CHAR(order_create_time, 'YYYYMMDD') AS order_create_date,
order_product_catalog_name,
COUNT(*),
SUM(order_fee)
FROM
dwd_orders
WHERE
order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
GROUP BY
order_create_date, order_product_catalog_name
ORDER BY
order_create_date, order_product_catalog_name;