注意: 本文内容于 2024-10-02 02:25:47 创建,可能不会在此平台上进行更新。如果您希望查看最新版本或更多相关内容,请访问原文地址:IO密集型任务及Vertx框架入门。感谢您的关注与支持!
一、背景
1.1 铺垫知识
涉及到阻塞式IO、非阻塞式IO、事件驱动等相关知识,可以查看我以往文章。
- 网络编程BIO-阻塞式
- 网络编程NIO-非阻塞式
1.2 瓶颈解决
我之前使用java封装了一个HTTP反向代理的工具http-proxy-boot,主要是方便自己临时测试时使用的。
该工具存在一个问题,高并发的时候,整体响应就会滞后。原因是因为该工具采用bio实现的,即“一连接一线程”。
假如我这个工具,只开放了200个连接。此时有201个请求过来,顺序依次是,200个慢请求(10秒响应),1个快请求(1秒响应)。
实际出现的情况是这200个连接都被前面200个慢请求阻塞了,以至于后面的快请求一直等待,实际20+1秒后才会响应。而我希望的效果是即使我可支配的线程数不变,快请求仍然可以1秒响应。
题外话,PostgreSQL使用的是“一连接一进程”模型,该问题PostgreSQL也同样存在。
计算机任务有很多种分类,以上属于其中IO密集型任务。尽管CPU参与任务处理,但大部分时间在等待IO完成。这中间的时间,CPU完全可以用来做更多的事。
我采用的做法是将bio切换成nio,也就是cpu不用一直等待,而是去做别的事,当传输完成后,通知cpu过来善后。
对于http来说,成熟的框架有很多。
- Spring WebFlux
- Vert.x
其中,我对比了下两者。
- WebFlux对Spring的生态支持相当友好,可以说是强耦合,健壮的同时也牺牲了些便捷性。
- Vertx就相当轻量、简单了,于是我选择Vertx解决这个问题。
二、计算机任务分类
计算机任务可以根据其特性分为几种类型,主要包括:
- CPU密集型
- IO密集型
- 内存密集型
- 网络密集型
每种类型的任务都有不同的性能瓶颈,了解它们的特点可以帮助我们在设计和优化系统时做出更合适的选择。
2.1 CPU密集型
CPU密集型也叫做计算机密集型。
这类任务主要依赖CPU的处理能力,通常需要大量的计算和复杂的算法。典型的例子包括视频编码、科学计算、数据分析等。
优化方式:并行处理,换用更高性能的CPU。
32线程的CPU同时刻只能跑32个线程。像操作系统里面会有很多线程,几十万个,那是因为其实有很多线程是空闲或者等待中的,CPU来回轮转,间接达到了上万线程同时运行的效果,比如像下面的这种IO密集型任务。
2.2 IO密集型
这类任务主要依赖于输入/输出操作,通常涉及大量的数据读写,如文件操作、网络请求等。
优化方式:减少IO操作次数、使用异步编程、换用更高性能硬盘。
2.3 内存密集型
这类任务对内存的使用量很大,例如处理大数据集、复杂的数据结构等。内存访问速度较快,但如果内存不足,可能会导致性能瓶颈。
优化方式:优化数据结构、减少内存占用、增加内存。
2.4 网络密集型
这类任务主要依赖网络带宽和延迟,通常涉及大量的数据在网络上传输,如Web服务器、大规模分布式系统等。
优化方式:优化网络协议、使用负载均衡、提高带宽等。
三、Vert.x 框架小记
3.1 介绍
Vert.x 是一个基于事件驱动的非阻塞框架,适合如下
- HTTP/TCP等服务器
- 文件上传/下载
这类IO密集型的高并发场景。
像这种非阻塞的框架,不只有vertx,还有很多。
- Netty:很多非阻塞框架都是基于Netty实现。
- Spring WebFlux:类似于Vertx,并且也是基于Netty,与Spring框架强耦合。
- Play Framework:轻量级的反应式 Web 框架,适合高并发 Web 应用。
- Akka:基于 Actor 模型的高并发框架,适合分布式系统和容错系统。超重量级。
但是vertx各模块之间,没有强耦合,都可以灵活组装使用,这点就特别好,因此我选用vertx。
3.2 示例
以下示例均基于Vert.x 4.5.10版本。
所有代码示例放置在meethigher/vertx-examples: learn to use vertx
3.2.1 基础知识
单机
vertx主要有两种线程池
- WorkerPool:主要用于处理阻塞任务的工作线程池。默认
20个。 - EventLoopPool:主要用于处理非阻塞的IO操作和定时器的事件循环线程池。默认
2*core线程。
下面放置一个基础示例,包含阻塞逻辑、事件回调逻辑、定时任务注册与取消逻辑。
private static void basic() {
/**
* workerPoolSize 指定用于处理阻塞任务的工作线程池的大小。默认20个
* eventLoopPoolSize 用于处理事件回调时执行的逻辑。默认CPU实际线程的2倍。因此在注册事件回调时的逻辑不要阻塞,如果必须要执行阻塞逻辑,就丢给workerPool
*/
Vertx tVertx = Vertx.vertx();
Vertx vertx = Vertx.vertx(new VertxOptions().setEventLoopPoolSize(5).setWorkerPoolSize(1));
/**
* 执行过程中,注意线程的名称。
* 使用WorkerPool执行阻塞任务,并使用EventLoopPool执行阻塞完成后的回调。
*/
vertx.executeBlocking(() -> {
//模拟阻塞任务的耗时
log.info("simulate blocking task execution time...");
TimeUnit.SECONDS.sleep(5);
if (System.currentTimeMillis() % 2 == 0) {
int i = 1 / 0;
}
return "Hello World";
})
.onComplete(re -> {
if (re.succeeded()) {
log.info("success, result:{}", re.result());
} else {
log.error("failure, result:", re.cause());
}
})
//以下写法相同
//onSuccess和onFailure是对onComplete更精确的封装,本质还是基于onComplete。
//.onSuccess(r -> {
// log.info("success, result:{}", r);
//}).onFailure(e -> {
// log.error("failure, result:", e);
//})
;
//一次性定时任务
vertx.setTimer(5000, t -> {
log.info("timer id:{}", t);
});
//周期性定时任务,并注册取消定时任务的逻辑
vertx.setPeriodic(5000, t -> {
log.info("periodic id:{}", t);
if (System.currentTimeMillis() % 2 == 0) {
vertx.cancelTimer(t);
log.info("cancel timer:{}", t);
}
});
}
在vertx中,还有执行任务的单元verticle,一个vertx实例可以部署多个verticle。verticle的分类有如下
-
标准Verticle:使用EventLoopPool执行的Verticle,这也是默认的Verticle类型。一个Verticle中的所有代码都会在一个事件循环(底层对应线程)中执行。
-
工作者Verticle:使用WorkerPool执行的Verticle,这类Verticle被设计用来执行阻塞任务,不过阻塞任务也可以不通过工作者Verticle,直接executeBlocking也可。
vertx支持部署任意语言编写的verticle,
private static void verticle() {
Vertx vertx = Vertx.vertx();
//部署标准Verticle
vertx.deployVerticle(new AbstractVerticle() {
@Override
public void start() throws Exception {
log.info("eventLoopVerticle start");
}
}).onFailure(e -> {
log.error("error", e);
});
//部署工作者Verticle
vertx.deployVerticle(new AbstractVerticle() {
@Override
public void start() throws Exception {
log.info("workerVerticle start");
}
}, new DeploymentOptions().setThreadingModel(ThreadingModel.WORKER)).onFailure(e -> {
log.error("error", e);
});
}
在vertx中,还有事件总线。这要求事件的发布、消费,都注册在同一个vertx实例或者集群中。
private static void eventBus() {
Vertx vertx = Vertx.vertx();
vertx.eventBus().consumer("test",t->{
Object body = t.body();
log.info("consumer: {}",body.toString());
});
vertx.eventBus().publish("test","hello world");
}
集群
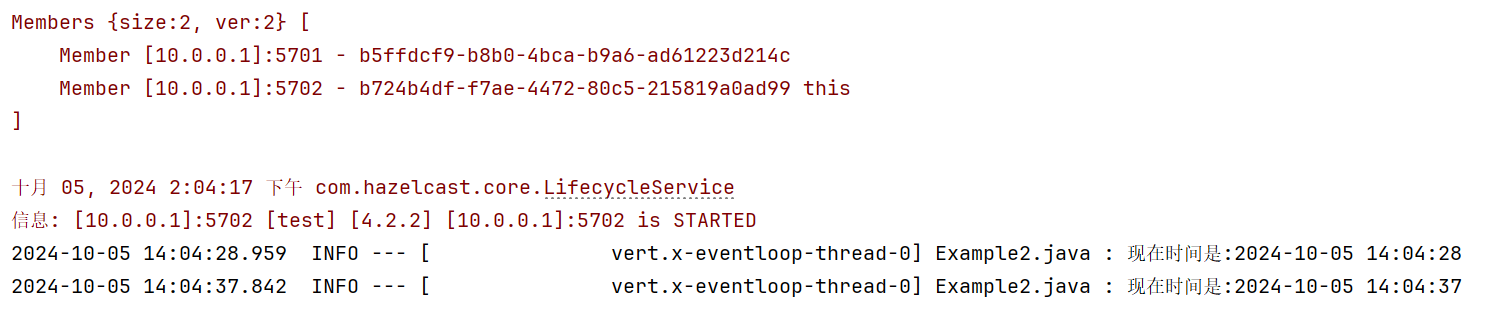
vertx构建集群需要依赖一些分布式服务。比如hazelcast或者redis。下面给出示例
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-core</artifactId>
<version>${vertx.version}</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-web</artifactId>
<version>${vertx.version}</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-hazelcast</artifactId>
<version>${vertx.version}</version>
<exclusions>
<exclusion>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>${hazelcast.version}</version>
</dependency>
示例代码
public static void main(String[] args) throws Exception {
Config config = new Config();
config.setClusterName("test");
HazelcastClusterManager clusterManager = new HazelcastClusterManager(config);
Future<Vertx> vertxFuture = Vertx.builder()
.with(new VertxOptions())
.withClusterManager(clusterManager)
//.build()//构建单节点
.buildClustered();
//阻塞直到获取集群中的vertx实例
Vertx vertx = vertxFuture.toCompletionStage().toCompletableFuture().get();
vertx.eventBus().consumer("test", t -> {
log.info(t.body().toString());
});
vertx.setTimer(20000, t -> {
vertx.eventBus().publish("test", "现在时间是:" + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()));
});
}
当启动两个程序实例时,会发现接收到了两条消息。这说明事件总线发送的消息,已经被集群中所有节点消费了。
3.2.2 HttpServer
创建一个HTTP服务器,并且注册响应的接口
/test/test?test=xxx:该接口在等待10秒后返回xxx/halo/*:该接口匹配/halo/下面的目录及子目录,并返回html形式的helloworld。- 这点与SpringWeb不同,SpringWeb中
/*表示当前目录,/**表示当前目录及子目录。
- 这点与SpringWeb不同,SpringWeb中
缺省值:表示匹配其他所有路径,并返回text形式helloworld。
public static void main(String[] args) {
Vertx vertx = Vertx.vertx();
vertx.deployVerticle(new AbstractVerticle() {
@Override
public void start() throws Exception {
int port = 4321;
Router router = Router.router(vertx);
//注册接口
router.route("/test/test").handler(t -> {
//接口逻辑
String testParam = t.request().getParam("test");
if (testParam == null) {
t.response().setStatusCode(400)
.end("missing 'test' query parameter");
} else {
vertx.setTimer(10000, tt -> {
t.response().putHeader("Content-Type", "text/plain")
.end(testParam);
});
}
});
router.route("/halo/*").handler(t -> {
String s = t.request().absoluteURI();
t.response().putHeader("Content-Type", "text/html")
.end("<h1>Hello World</h1> " + s);
});
router.route().handler(t -> {
t.response().end("Hello World");
});
vertx.createHttpServer()
//注册路由
.requestHandler(router)
.listen(port).onComplete(re -> {
if (re.succeeded()) {
log.info("http server started on port {}", port);
} else {
log.error("http server failed to start", re.cause());
}
});
}
});
}
3.2.3 HttpClient
应用场景:
有一个接口,http://localhost:4321/test/test?test=参数,该接口10秒后会返回参数值。
我现在需要在10秒左右获取到2000次个接口的请求响应。
如果使用传统的做法,那么就得需要2000个线程,但如果使用vertx,只需要一个线程即可。
public static void main(String[] args) throws Exception {
Vertx vertx = Vertx.vertx(new VertxOptions().setEventLoopPoolSize(1).setWorkerPoolSize(1));
// 创建HttpClient时指定的PoolOptions里面的EventLoopSize不会生效。以Vertx的EventLoopSize为主。默认http/1为5并发,http/2为1并发
HttpClient httpClient = vertx.createHttpClient(new PoolOptions().setHttp2MaxSize(2000).setHttp1MaxSize(2000).setEventLoopSize(2000));
HttpClient httpsClient = vertx.createHttpClient(new HttpClientOptions().setSsl(true).setTrustAll(true).setConnectTimeout(60000), new PoolOptions().setHttp2MaxSize(2000).setHttp1MaxSize(2000).setEventLoopSize(2000));
/**
* 输出当前活着的线程
*/
vertx.deployVerticle(new AbstractVerticle() {
@Override
public void start() throws Exception {
vertx.setPeriodic(5000, t -> {
vertx.executeBlocking(() -> {
ThreadGroup threadGroup = Thread.currentThread().getThreadGroup();
int i = threadGroup.activeCount();
Thread[] threads = new Thread[i];
threadGroup.enumerate(threads);
List<String> list = new ArrayList<>();
for (Thread thread : threads) {
list.add(thread.getName());
}
//模拟耗时操作
try {
log.info("calculating...");
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return String.join(",", list);
}).onComplete(r -> {
if (r.succeeded()) {
log.info("threads:\n{}", r.result());
} else {
log.warn(r.cause().getMessage(), r.cause());
}
});
});
}
});
int total = 2000;
CountDownLatch countDownLatch = new CountDownLatch(total);
long start = System.currentTimeMillis();
for (int i = 0; i < total; i++) {
int finalI = i;
vertx.deployVerticle(new AbstractVerticle() {
@Override
public void start() throws Exception {
httpClient.request(HttpMethod.GET, 4321, "localhost", "/test/test?test=" + finalI)
//httpsClient.request(HttpMethod.GET, 443, "reqres.in", "/api/users?page=" + finalI)
.onComplete(r -> {
if (r.succeeded()) {
HttpClientRequest request = r.result();
log.info("{} send request {}", this, request.absoluteURI());
request.putHeader("User-Agent", "I am Vertx");
request.send()
.onComplete(r1 -> {
if (r1.succeeded()) {
HttpClientResponse result = r1.result();
log.info("{} received response with status code {}", this, result.statusCode());
//这种做法其实对内存要求较大,相当于是一次性将内容写到buffer里了
result.body().onComplete(re -> {
if (re.succeeded()) {
Buffer result1 = re.result();
log.info("result: {}", result1);
} else {
log.warn("warn: ", re.cause());
}
});
} else {
log.error("{} send failed: {}", this, r1.cause().getMessage(), r1.cause());
}
countDownLatch.countDown();
});
} else {
log.error("request failed: {}", r.cause().getMessage(), r.cause());
countDownLatch.countDown();
}
});
}
});
}
countDownLatch.await();
log.info("done {} ms", System.currentTimeMillis() - start);
}
3.2.4 文件系统
vertx中的FileSystem提供了许多方法,并且都有阻塞版本和非阻塞版本的api。如下
public static void fileCopy() {
Vertx vertx = Vertx.vertx();
FileSystem fs = vertx.fileSystem();
/**
* 非阻塞方法
*/
fs.copy("D:/Downloads/yjwj_2024-06-05-10-50.zip", "D:/Desktop/test.zip")
.onComplete(re -> {
if (re.succeeded()) {
log.info("copy success");
} else {
log.error("copy failed, ", re.cause());
}
});
/**
* 对应的阻塞方法
*/
fs.copyBlocking("D:/Downloads/yjwj_2024-06-05-10-50.zip", "D:/Desktop/test1.zip");
log.info("done");
}
3.2.5 HTTP反向代理
添加依赖
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-web-proxy</artifactId>
<version>${vertx.version}</version>
</dependency>
其实这个依赖提供的功能非常简陋,如果想要实现强大的HTTP反向代理,需要自己编写代理逻辑。如下给出示例代码
public static void main(String[] args) {
int port = 8080;
Vertx vertx = Vertx.vertx();
HttpServer httpServer = vertx.createHttpServer();
Router router = Router.router(vertx);
HttpClient httpClient = vertx.createHttpClient();
HttpClient httpsClient = vertx.createHttpClient(new HttpClientOptions().setSsl(true).setTrustAll(true));
HttpProxy httpProxy = HttpProxy.reverseProxy(httpClient);
HttpProxy httpsProxy = HttpProxy.reverseProxy(httpsClient);
// 默认处理逻辑ProxyHandler,这个是由vertx-web-proxy扩展提供
router.route("/halo/*").handler(ProxyHandler.create(httpProxy, 4321, "10.0.0.1"));
router.route().handler(ProxyHandler.create(httpsProxy, 443, "meethigher.top"));
// 自定义逻辑,自己实现
router.route("/api/*").handler(ctx -> {
HttpServerRequest request = ctx.request();
httpsClient.request(HttpMethod.valueOf(request.method().name()), 443, "reqres.in", request.uri())
.onSuccess(r -> {
r.headers().setAll(request.headers());
r.putHeader("Host", "reqres.in");
r.send()
.onSuccess(r1 -> {
ctx.response()
.setStatusCode(r1.statusCode())
.headers().setAll(r1.headers());
r1.handler(data -> {
ctx.response().write(data);
});
r1.endHandler(v -> ctx.response().end());
})
.onFailure(e1 -> {
ctx.response().setStatusCode(500).end(e1.getMessage());
});
})
.onFailure(e -> {
ctx.response().setStatusCode(500).end("Internal Server Error");
});
});
httpServer.requestHandler(router).listen(port).onSuccess(t -> {
log.info("http server started on port {}", port);
});
}
3.3 参考致谢
Documentation | Eclipse Vert.x
Vert.x Core | Eclipse Vert.x
Web Proxy | Eclipse Vert.x