文章目录
- Linux中真正的调度算法
- 补充
- 命令行参数
- 什么是命令行参数?
- 命令行参数的用途
- 如何在不同的编程语言中使用命令行参数
- 命令行参数好处
Linux中真正的调度算法
这是Linux2.6的内核中进程队列的数据结构

其中有这两个指针*active,*expired,而Linux为了实现优先级设计了一个哈希(说白了就是数组)的一个结构,而*active,*expired分别指的是活跃的和过期的数组,其实这两个数组差不多所以先拿出一个来讲。

这个数组一共140个元素数组名先不用管我们知道是struct task_struct* [140]就可以后面会解释数组名,而这140个元素前100个元素是给实时进程准备的所以我们不用考虑,那么剩下的就是后面40个,上一篇博客优先级范围中咱们确定了nice值正好是[-20,19],40个那么进程的范围是[60,99]
也是40个。说假设有一个进程经过计算优先级是61那么是怎么放到这个数组中的呢?

是通过pir-stratpir+100,用自己的pir减去pir的初始值就是60,在加上前面的100所以的到了下标是101,所以本来这个数组是子队列所以我们可以直接把这个进程挂到下标是101的地方,同理如果有其他进程优先级也是61的时候也是挂队列,这样其实就形成了一个开散列式的哈希桶,并且这个哈希桶中相同的优先级会被映射到一起。这样在遍历数组不仅能较为快速的寻找进程而且还是根据优先级的先后来查找调度进程。
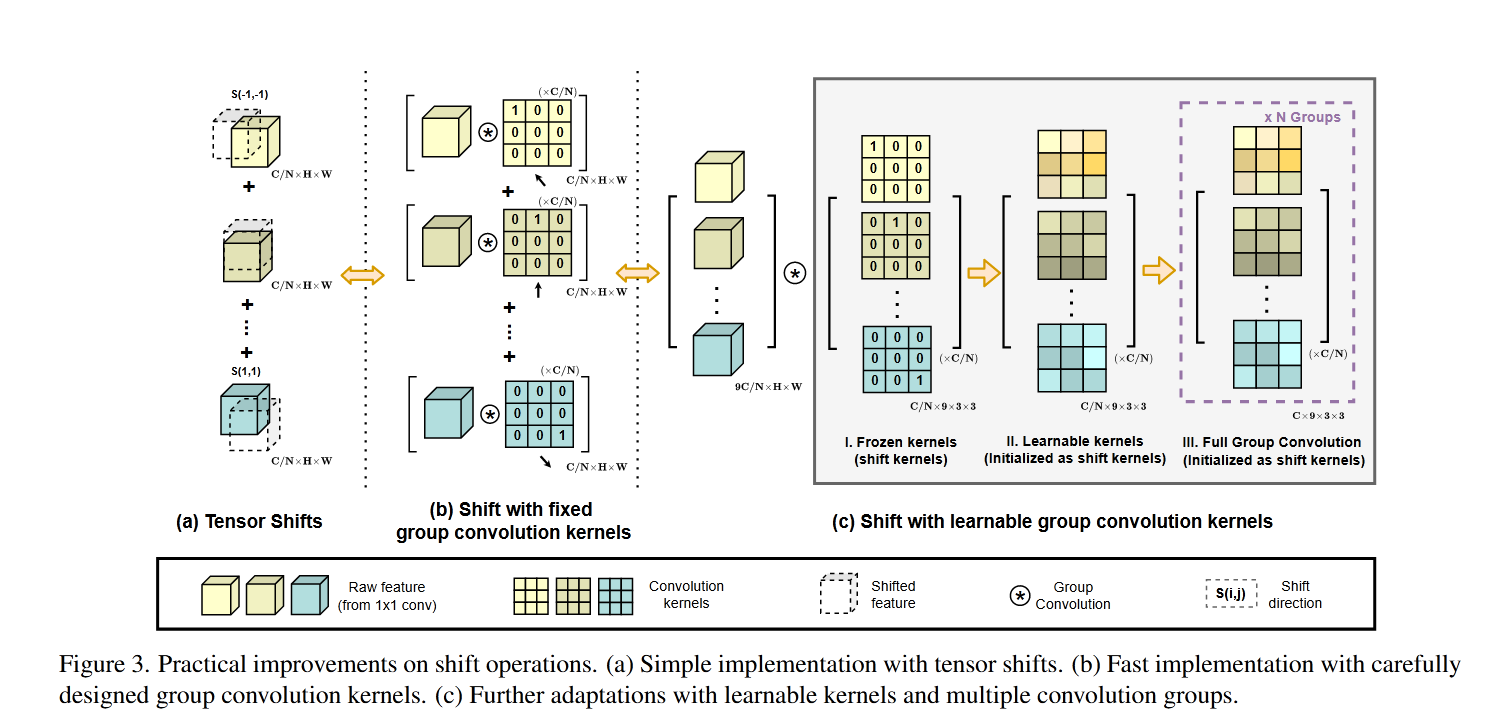
那么我们对struct task_struct* [140]有一定了解之后呢,其实在一个CPU中这样的哈希表有两张,虽然两个都是queue[140]但是在内核中是怎么写的呢?

在内核中定义一个结构名字就是queue,之后我们基于这个结构体定义了一个有两个元素的数组,之后呢就有runqueue就是我们上面图片说的。为了方便理解我们之后的图中不考虑前一百个元素下标直接从0~39。首先途中里面的两个方块分别代表array[0]和array[1]就是struct queue array[2]中的两个元素。而因为是struct queue类型的数组其中包括nr_active,bitmap[5],而runqueue因为包含struct queue array[2]于是整个大框就是runqueue其中包含struct queue* active,strurct queue* expired这就职这个图的整体

而在工作的时候呢假设struct queue* active指向array[0],strurct queue* expired指向array[1]。而CPU在调度的时候之后从active中选择进程来进行调度。而在active中的进程的调度就和咱们上面的struct task_struct* [140]原理相同。
而在调度期间会出现的三种情况:
1.运行退出
2.有新的进程产生
3.没有退出,但是时间片到了
运行退出直接从队列中把你的进程拿掉就好,那么有新进程产生的时候怎么解决的呢?我们想每当我们创建了一个新进程的时候,正常情况操作系统就会根据优先级来插入到队列中可是整个队列还在调度,那么是进行插入还是调度呢?无论怎么选择都会导致两个任务相互影响使操作系统出现问题。而我们知道调度器要非常的均衡的进行调度但是又有优先级的存在二者不会很冲突吗,假设一个优先级非常高的新进程进入队列,那么由于这个进程优先级非常高队列就是一直调用这个进程,很明显这样绝对有问题的。所以说优先级低的表示你要一直不会被调度吗?优先级高的表示你要一直调度吗?所以说这是饥饿问题。

其实呢我们不是还有一个队列array[1],每当有新进程创建的时候不会之间放到CPU正在调度的队列(active)中而是会先放到过期队列(expired)中而在活跃队列被CPU调度完时间片到了的进程(过期进程)也会被放到过期队列所以这样就能避免上面的饥饿问题,所以上面的三种情况2.和3.的解决方案是一样的,这就保证active队列永远都是一个存量进程竞争的情况(active队列中的进程只会越来越少,不会增多)那么当active为空的时候操作系统只需要做一件事情swap(&active,&expired),将两个队列的指针交换那么就循环起来了,而CPU只看active指针指向的队列。 这样swap之前队列按照优先级来进行调度,swap之后有之间来整理优先级给其他进程调度的机会。其中nr_active的作用就是判断array是否为0确定swap的时间,CPU在按优先级寻找进程的时候也要一遍一遍的遍历数组而bitmap[5]在32位的机器上面5*32=160覆盖140个位置,用bitmap[5]充当位图,每一个比特位代表一个位置是否为空(000000…000000一共160个,为1有进程,为0就是空),这样每次只看bitmap[5]就能很快又简洁的确定哪里为空和非空(这个设计的真的很优雅)。那么是这样判定是否为空的:
for(int i=0;i<5;i++)
{
if(bitmap[i]==0) contine;//一次就能检测32个位置
else
{
//在32个bit位中确定哪一个队列
......
//int确定比特位是1的问题
//while(x)
//{
//x&=(x-1);
//}
}
}
所以这个搜索的成本就是常数成本很小。这种调度算法就是Linux内核O(1)调度算法。
补充
在之前我们说过进程是用链表来链接的,进程可以在调度队列中也可以在阻塞队列中等等那进程又要被操作系统管理到一个链表中那进程是如何做到的呢?
实际上链式结构不采用单链表,而是双链表结构,而这个双链表如图:

那这样做的原因呢?
一个进程,既可以在全局变量中,又可以在任意一个数据结构中,只要加节点字段即可
struct task_struct
{
//进程的属性
......
struct node linstnode;
struct node queuenode;
......
}
当遍历的时候,只能找到Link的地址,那怎么访问其他属性呢?
我们举个例子:

我们有一个结构体A,其中我们知道char c的地址,但是我们知道一个struct的地址是连续的所以说我们用已知的地址减去偏移量就能得到这个结构体最开始的地址,那么知道最开始的地址就能访问任何成员了。
那么怎么求偏移量呢?
 我认为从0的地址放就会存在一个 struct A,我们把0强转成目标结构体类型,然后访问c,之后在对c取地址,所以这个值就是c对于这个结构体的偏移量。所以任意结构体的偏移量就可以这样求:
我认为从0的地址放就会存在一个 struct A,我们把0强转成目标结构体类型,然后访问c,之后在对c取地址,所以这个值就是c对于这个结构体的偏移量。所以任意结构体的偏移量就可以这样求:

命令行参数
什么是命令行参数?
命令行参数是在程序运行时通过命令行传递给程序的参数。当我们在命令提示符或终端中运行程序时,可以在程序名称后面添加一些参数,这些参数可以被程序读取并用于控制程序的行为。
例如,在 Linux 系统中,我们可以使用ls命令来列出当前目录下的文件和文件夹。ls命令还可以接受一些参数,如-l参数可以以长格式显示文件信息,-a参数可以显示隐藏文件。
命令行参数的用途
- 定制程序行为:通过命令行参数,用户可以根据自己的需求定制程序的行为。例如,一个图像处理程序可以接受参数来指定输入图像的文件名、输出图像的文件名、图像的大小等。
- 提高程序的可重用性:命令行参数使得程序可以在不同的场景下使用,而不需要修改程序的源代码。例如,一个数据处理程序可以接受参数来指定输入数据的文件名、输出数据的文件名、数据处理的方式等。
- 方便自动化脚本:命令行参数可以方便地与自动化脚本结合使用,实现批量处理任务。例如,我们可以编写一个脚本,使用命令行参数来指定要处理的文件列表,然后调用一个程序对这些文件进行处理。
如何在不同的编程语言中使用命令行参数
#include <stdio.h>
#include <stdlib.h>
void print_help() {
printf("Usage: program [options]\n");
printf("Options:\n");
printf(" -h, --help Display this help message.\n");
printf(" -s <string>, --string <string> Process a string.\n");
printf(" -n <number>, --number <number> Process a number.\n");
}
int main(int argc, char *argv[]) {
char *string_arg = NULL;
int number_arg = 0;
for (int i = 1; i < argc; i++) {
if (strcmp(argv[i], "-h") == 0 || strcmp(argv[i], "--help") == 0) {
print_help();
return 0;
} else if (strcmp(argv[i], "-s") == 0 || strcmp(argv[i], "--string") == 0) {
if (i + 1 < argc) {
string_arg = argv[i + 1];
i++;
} else {
printf("Error: Missing argument for -s/--string.\n");
return 1;
}
} else if (strcmp(argv[i], "-n") == 0 || strcmp(argv[i], "--number") == 0) {
if (i + 1 < argc) {
number_arg = atoi(argv[i + 1]);
i++;
} else {
printf("Error: Missing argument for -n/--number.\n");
return 1;
}
} else {
printf("Error: Unknown option '%s'.\n", argv[i]);
return 1;
}
}
if (string_arg!= NULL) {
printf("Processing string: %s\n", string_arg);
}
if (number_arg!= 0) {
printf("Processing number: %d\n", number_arg);
}
return 0;
}
在这个例子中,程序可以接受以下命令行参数:
-h或--help:显示帮助信息。-s <string>或--string <string>:处理一个字符串参数。-n <number>或--number <number>:处理一个数字参数。
使用方法如下:
- 显示帮助信息:
./program -h
- 处理字符串参数:
./program -s "Hello, World!"
- 处理数字参数:
./program -n 42
命令行参数好处
- 提供清晰的使用说明:在程序中,应该提供清晰的使用说明,告诉用户如何使用命令行参数。可以在程序的帮助信息中或者在命令行参数数量不足时打印使用说明。
- 使用有意义的参数名称:为了提高程序的可读性和可维护性,应该使用有意义的参数名称。可以使用短参数和长参数,短参数通常是一个字符,长参数通常是一个单词或短语。
- 处理错误情况:在程序中,应该处理错误情况,例如参数数量不足、参数格式错误等。可以打印错误信息并返回错误码,以便用户知道程序出现了问题。
- 使用命令行参数解析库:为了提高程序的可靠性和可维护性,可以使用命令行参数解析库。这些库可以帮助我们解析命令行参数,处理错误情况,并提供更好的用户体验。