上一章简单的介绍了一下各种内存,本章开始详细讲解各个内存的合理使用,在所有设备中,全局内存的访问速度最慢,是CUDA程序的一个性能瓶颈,所以值得特别关注
1 全局内存的合并与非合并访问
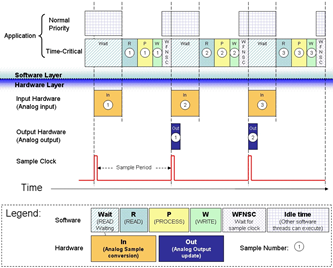
对全局内存的访问将触发内存事务(memory transaction),也就是数据传输(data transfer)。
从费米架构开始,在启用了L1缓存的情况下,对全局内存的读取将首先尝试经过 L1 缓存;如果未中,则接着尝试经过L2缓存;如果再次未中,则直接从DRAM读取。一次数据传输处理的数据量在默认情况下是 32 字节。
关于全局内存的访问模式,有合并(coalesced)与非合并(uncoalesced)之分。
1.1 合并访问
多个线程(一个线程束)在同一时间内访问全局内存中的连续地址,从而减少内存访问的次数,提高内存带宽的利用率。合并访问是优化CUDA程序性能的重要手段之一。
1.1.1 基本概念
-
线程束: CUDA中的线程是以线程束的形式执行的。一个线程束包含32个线程,这些线程在同一个SM上并行执行。
如果线程束中的所有线程访问的是连续的内存地址,那么这些访问可以被合并成一次或几次较大的内存事务,从而提高内存访问的效率。 -
合并访问的条件:
①连续性: 线程束中的所有线程访问的地址必须是连续的,例如,如果一个warp包含32个线程,每个线程访问一个4字节的float数据,那么这32个线程应该访问连续的128字节
②对齐: 访访问的起始地址应对4字节对齐(对于float类型),理想情况下应对128字节对齐,以减少内存事务的数量。
1.1.2 举例
观察下面数组相加的核函数:
__global__ void add(float *x, float *y, float *z) {
int n = threadIdx.x + blockIdx.x * blockDim.x;
z[n] = x[n] + y[n];
}
......
add << <128, 32 >> > (d_x, d_y, d_z);
......
①连续性: 在这个例子中,每个线程的索引 n 是通过 threadIdx.x + blockIdx.x * blockDim.x 计算的,所以第一个线程束中的线程0访问 x[0] 和 y[0],线程1访问 x[1] 和 y[1],依此类推,直到线程31访问 x[31] 和 y[31],符合连续性
②对齐: float 类型的数据占用4字节,因此只要数组 x 和 y 的起始地址是对4字节对齐的,每个线程访问的地址也会是对4字节对齐的,理想情况下,起始地址应对128字节对齐。而数组x和y是由cudaMalloc分配的内存,所以首地址至少是 256 字节的整数倍,所以符合对齐
综上所述,是合并访问。
例如:一个线程束中的32个线程将分别访问数组x中0~31个float元素,后者是连续的128字节内存,所以最快只需要4次传输就能完成,由于线程是连续地址、访问的地址也对齐了,所以只需要4次就能完成传输,合并度是4/4=100%
1.2 非合并访问
1.2.1 不对齐的非合并访问
在线程索引后面+1
__global__ void add(float *x, float *y, float *z) {
int n = threadIdx.x + blockIdx.x * blockDim.x+1;
z[n] = x[n] + y[n];
}
......
add << <128, 32 >> > (d_x, d_y, d_z);
......
①连续性: int n = threadIdx.x + blockIdx.x * blockDim.x + 1;多了一个偏移量,所以线程0将访问 x[1] 和 y[1],线程1将访问 x[2] 和 y[2],依此类推,不符合连续性
②对齐: 由于线程0访问 x[1],而不是 x[0],这意味着访问的起始地址不是128字节对齐的,而是128的倍数+4,所以不符合对齐
综上所述,是非合并访问。
例如:一个线程束中的32个线程将分别访问数组x中1~32个float元素,后者是连续的128字节内存,所以最快只需要4次传输就能完成,但是由于线程索引多了一个偏移量,则线程访问的起始地址不再与128字节对齐。
①理想情况: 如果线程从数组索引0开始,每个线程访问连续的数组元素(例如,线程0访问x[0],线程1访问x[1],线程2访问x[2],…),那么32个线程的访问可以被合并为 1次传输操作。
②实际情况: 线程访问的内存范围是x[1]到x[32],但因为访问地址不是对齐的,所以被分割为x[1]到x[31]和x[32]
前者虽然传输了128/432=4次数据,但是x[0]的数据是没用的,所以还需要后者再传输1次,所以总共传输了5次。
合并度=4/5=80%
1.2.2 跨越时的非合并访问
void __global__ add_stride(float *x, float *y, float *z) {
int n = blockIdx.x + threadIdx.x * gridDim.x;
z[n] = x[n] + y[n];
}
......
add_stride<<<128, 32>>>(x, y, z);
......
因为这里 的每一对数据都不在一个连续的 32 字节的内存片段,故该线程束的访问将触发 32 次 数据传输,合并度为 4/32 = 12:5%。
2 例子:矩阵转置
将通过一个矩阵转置的例子讨论全局内存的合理使用,假设一个矩阵
A
i
j
A_{ij}
Aij ,则其转置矩阵
B
j
i
=
A
T
B_{ji}=A^T
Bji=AT ,取

则其转置矩阵为

2.1 矩阵复制
在讨论矩阵转置之前,先讨论一个更简单的问题,矩阵复制,代码如下:
#include <cuda_runtime.h>
#include <iostream>
#include "error_check.cuh"
#define TILE_DIM 32 // 定义每个block的线程块维度
// 将矩阵 A 复制到矩阵 B
__global__ void cpy_matrix(const float* A, float* B, const int N) {
// 计算当前线程的全局索引(行列坐标)
const int nx = blockIdx.x * TILE_DIM + threadIdx.x; // 计算当前线程的列索引
const int ny = blockIdx.y * TILE_DIM + threadIdx.y; // 计算当前线程的行索引
// 计算当前线程在矩阵中的线性索引(行优先存储)
const int idx = ny * N + nx; // 线性索引公式:行索引 * 行长度 + 列索引
// 检查当前线程是否在矩阵范围内,避免越界访问
if (nx < N && ny < N) {
// 将矩阵 A 中对应位置的值复制到矩阵 B 中
B[idx] = A[idx];
}
}
int main() {
// 定义矩阵大小
const int N = 1024;
const int size = N * N * sizeof(float);
// 主机上分配内存
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
// 初始化矩阵数据
for (int i = 0; i < N*N; i++) {
h_A[i] = 1.0f;
}
// 在设备上分配内存
float* d_A, *d_B;
CHECK(cudaMalloc((void**)&d_A, size));
CHECK(cudaMalloc((void**)&d_B, size));
// 将主机矩阵数据拷贝到设备
CHECK(cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice));
// 创建线程块和线程块网格
dim3 threads(TILE_DIM, TILE_DIM);// 线程块是32 * 32
dim3 gridSize((N + TILE_DIM - 1) / TILE_DIM, (N + TILE_DIM - 1) / TILE_DIM);// 确保矩阵大小能被线程块整除
// 调用核函数,将矩阵 A 复制到矩阵 B
cpy_matrix<<<gridSize, threads>>>(d_A, d_B, N);
// 将矩阵B 从设备拷贝到主机
CHECK(cudaMemcpy(h_B, d_B, size, cudaMemcpyDeviceToHost));
// 检查复制结果,确保正确性
bool success = true;
for (int i = 0; i < N * N; i++) {
if (h_B[i] != h_A[i]) {
success = false;
break;
}
}
if (success) {
std::cout << "Matrix copy successful!" << std::endl;
}
else {
std::cout << "Matrix copy failed!" << std::endl;
}
// 释放主机和设备内存
free(h_A);
free(h_B);
cudaFree(d_A);
cudaFree(d_B);
return 0;
}
之前我们的线程索引都是一维的,为什么这里要使用二维线程索引呢?主要与处理二维数据(如矩阵)更自然和高效
①矩阵本身是二维结构:
矩阵是由行和列组成的二维数据结构,因此使用二维的线程索引来直接表示矩阵的行和列,使得每个线程可以自然地与矩阵中的一个元素相对应,在核函数中:
- nx 代表线程的列索引(横坐标)。
- ny 代表线程的行索引(纵坐标)。
每个线程根据其nx和ny,访问矩阵中对应位置的元素,从而完成并行化的矩阵操作。
②简化索引计算:
使用二维线程索引可以简化矩阵元素的索引计算,在二维线程索引中:
- 行索引
ny = blockIdx.y * TILE_DIM + threadIdx.y:block的y索引加上线程的y索引,可以直接对应矩阵中的行。 - 列索引
nx = blockIdx.x * TILE_DIM + threadIdx.x:block的x索引加上线程的x索引,可以直接对应矩阵中的列。
2.2 使用全局内存进行矩阵转置
2.2.1代码实现
在上述代码的核函数中:
const int idx = ny * N + nx;
if (nx < N && ny < N) {
B[idx] = A[idx];
}
可以简化为以下代码:
if (nx < N && ny < N) {
B[ny * N + nx] = A[ny * N + nx];
}
意味着把矩阵通过行优先存储转化为一维数组,然后复制给矩阵
B
B
B,所以我们只需要略微修改代码,就能完成转置的效果,看似方法类似,但其实性能不同:
法①:
if (nx < N && ny < N) {
// 行索引转列索引,实现矩阵转置
B[nx * N + ny] = A[ny * N + nx];
}

法②
if (nx < N && ny < N) {
// 列索引转行索引,实现矩阵转置
B[ny * N + nx] = A[nx * N + ny];
}

2.2.2 结果分析
为什么方法类似,性能差距这么大呢?
我们将行索引转列索引命名为htol,列索引转行索引命名为ltoh,可以看出:
①在htol中: 对矩阵 A 中数据的读取是顺序的,即对A的访问是合并访问;对矩阵 B 中数据的写入不是顺序的,即对B的访问是非合并访问。
②在ltoh中: 对矩阵A中的数据读取不是顺序的,即对A的访问是非合并访问;对矩阵B中的数据写入是顺序的,即对B的访问是合并访问。
这是因为,在核函数ltoh中,读取操作虽然是非合并的,但利用了只读数据缓存的加载函数 __ldg()。
从帕斯卡架构开始,如果编译器能够判断一个全局内存变量在 整个核函数的范围都只可读(如这里的矩阵 A),则会自动用函数 __ldg() 读取全局内存, 从而对数据的读取进行缓存,缓解非合并访问带来的影响。
2.3 总结
所以,在全局内存下,如果不能同时满足读取和写入都是合并的情况下,一般来说应当尽量做到写入操作是合并访问。
注意: 在使用开普勒架构和麦克斯韦架构的 GPU 时,需要明显地使用 __ldg() 函数。