文章较长,各位志同道合的朋友们,感谢关注收藏。
书山有路勤为径,学海无涯苦作舟。 ——韩愈,以山川学海比喻学习的艰辛与努力的方向。
明天的我们,必将会感谢昨日的自己。
1 UI自动化测试
UI自动化测试(User Interface Automation Testing)是一种通过编写脚本或使用自动化测试工具,对界面(UI)进行自动化测试的方法。原理主要是模拟用户打开客户端或网页的UI界面,自动化执行用户界面上的操作,如点击按钮、输入文本、选择但下拉框/单选,多选项等,并检查测试对象的响应行为是否符合预期。
比如一些常用的测试框架或者工具(robotframework,testng,pytest,selenium,appnium,playwright等)都支持UI界面的自动化测试,而这节内容主要介绍下pytest框架+selenium工具在web端的自动化实践。
2 selenium安装
使用pip命令安装: pip install selenium -i https://mirrors.aliyun.com/pypi/simple/
下载的是最新版本4.23.1,需要适配python版本3.8+。
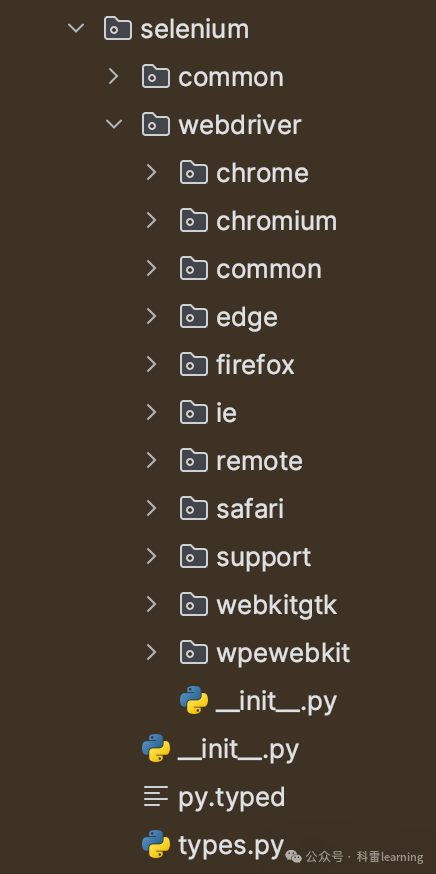
selenium安装后目录结构如下:
3 selenium介绍
Selenium是一个用于Web应用程序的自动化测试工具,支持多平台(Windows、Linux和Mac)、多浏览器(IE,Mozilla Firefox、Safari、Google Chrome、Opera、Edge)、多语言(Java、Python、C#、JavaScript、Ruby),能够让测试脚本像真实用户一样在浏览器中操作。
核心组件:
Selenium IDE:Selenium Suite下的开源Web自动化测试工具,是Firefox的一个插件,具有记录和回放功能,无需编程即可创建测试用例。
Selenium WebDriver:Selenium 2.0及以后版本的核心,通过原生浏览器支持或浏览器扩展直接控制浏览器,取代了Selenium RC中的JavaScript注入技术。
Selenium Grid:一种自动化测试辅助工具,能够加快Web应用的功能测试,支持并行执行多个测试事例。
3.1 MAC系统-配置selenium控制safari浏览器
safari浏览器从10及以上版本通常内置了对WebDriver的支持
不需要下载下载浏览器的驱动,但是需要配置浏览器支持使用selenium打开。如果不配置执行程序会报以下错误:
![]()
1)配置步骤:
-
打开Safari浏览器。
-
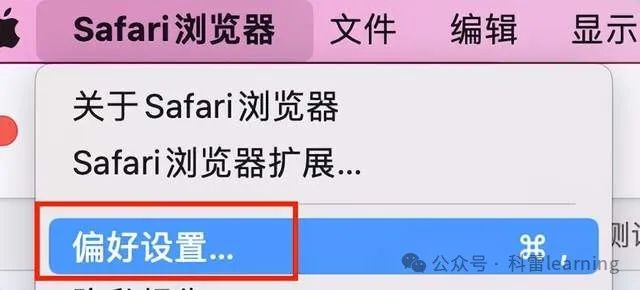
点击菜单栏上的“Safari浏览器”,然后选择“偏好设置”(Preferences)。
-
在偏好设置窗口中,点击“高级”(Advanced)标签页。
-
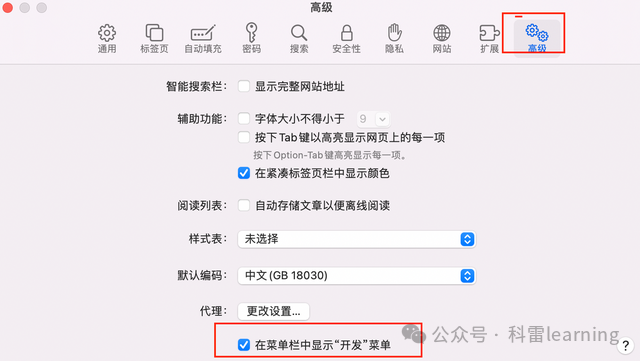
勾选“在菜单栏中显示‘开发’菜单”(Show Develop menu in menu bar)。
-
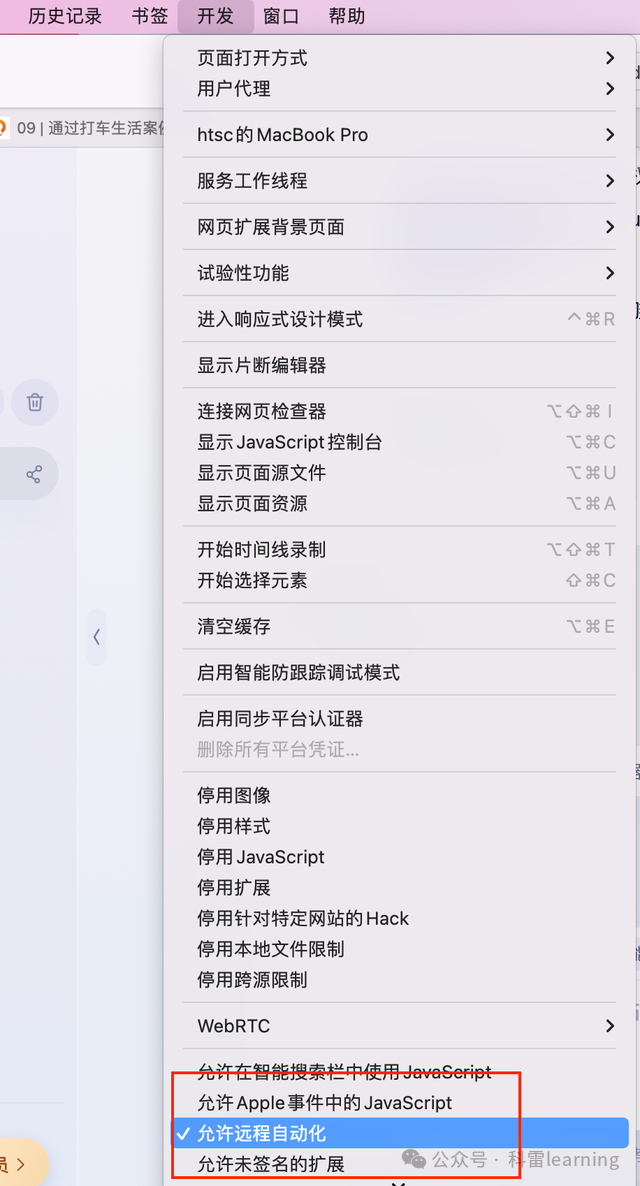
关闭偏好设置窗口,然后点击菜单栏上的“开发”(Develop)菜单。
-
勾选“允许远程自动化”(Allow Remote Automation)。
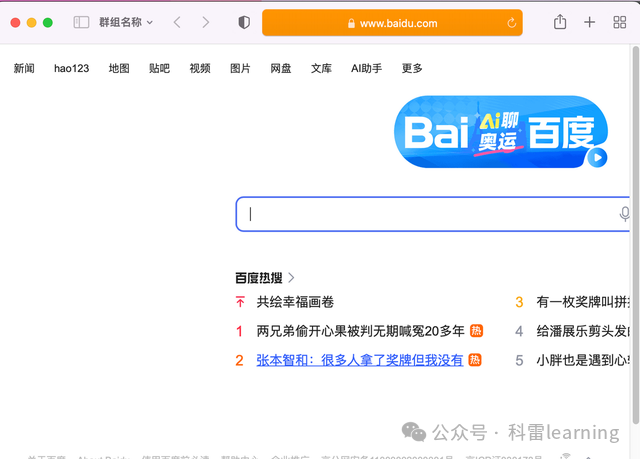
2)配置后我们使用selenium打开safari浏览器
首先导入selenium.webdriver,然后我们打开浏览器,等待一段时间后使用quit函数退出浏览器。
from selenium import webdriver
import time
# 创建Safari浏览器的WebDriver实例
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
#打开后等待60s退出
time.sleep(60)
# 关闭浏览器
driver.quit()python程序执行后,结果如下:会自动打开浏览器输入百度网址,完成访问。
3.2 MAC系统-配置selenium控制google的chrome浏览器
google浏览器不像safari浏览器,使用前我们先要下载驱动程序(下载地址https://chromedriver.storage.googleapis.com/index.html),驱动程序的版本要跟浏览器的版本一致,比如浏览器是127版本,驱动程序也要下载127的版本(目前还没有127的版本驱动,大家可以降低浏览器的版本再下载对应)。
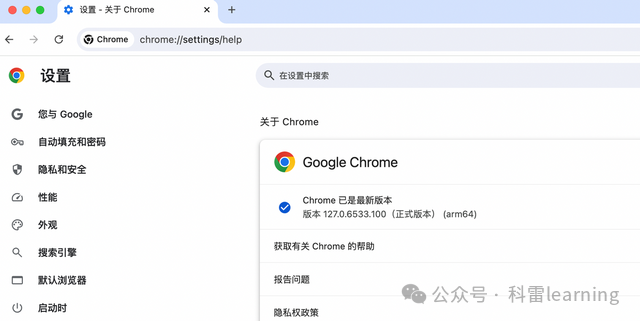
下载网址打开后,选择对应的版本,然后选择支持windows系统的包
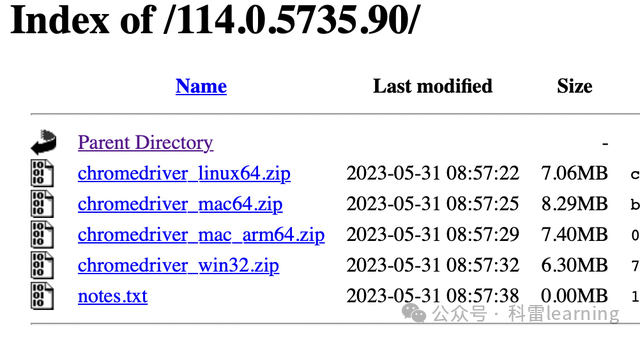
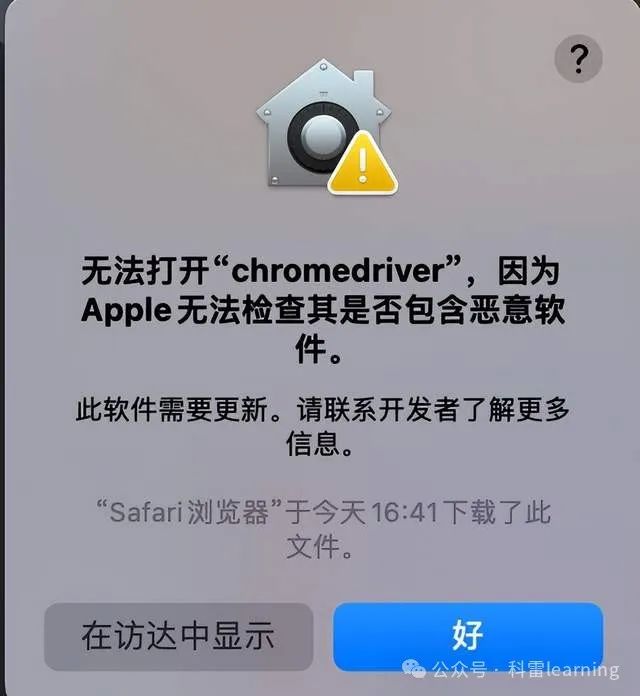
下载后解压,并将程序chromedriver放到/usr/local/bin目录下,并执行命令赋予权限:sudo xattr -d com.apple.quarantine chromedriver。否则无权限通过selenium打开后会报如下错误:
2)配置后我们使用selenium打开google浏览器
首先导入selenium.webdriver,然后我们打开浏览器,等待一段时间后使用quit函数退出浏览器。
from selenium import webdriver
from time import sleep
# 创建浏览器WebDriver实例
driver = webdriver.Chrome()
# 打开一个网页
driver.get("https://www.baidu.com")
# 等待几秒钟以便观察浏览器行为
sleep(60)
# 关闭浏览器
driver.quit()3.3 windows系统-配置selenium控制google的chrome浏览器
跟配置MAC系统一样,使用前我们先要下载驱动程序(下载地址https://chromedriver.storage.googleapis.com/index.html),驱动程序的版本要跟浏览器的版本一致,比如浏览器是127版本,驱动程序也要下载127的版本。
下载网址打开后,选择对应的版本,然后选择支持windows系统的包(目前还没有127的版本驱动,大家可以降低浏览器的版本再下载对应)。
下载网址打开后,选择对应的版本,然后选择支持windows系统的包,
下载后解压,并将程序chromedriver放到python的安装目录下,比如‘D:/Python3’.
2)配置后我们使用selenium打开google浏览器
首先导入selenium.webdriver,然后我们打开浏览器,等待一段时间后使用quit函数退出浏览器。
from selenium import webdriver
from time import sleep
# 创建浏览器WebDriver实例
driver = webdriver.Chrome()
# 打开一个网页
driver.get("https://www.baidu.com")
# 等待几秒钟以便观察浏览器行为
sleep(60)
# 关闭浏览器
driver.quit()4 selenium的webdriver介绍
从selenium导入webdriver模块,在pycharm中跳转webdriver模块的__init__.py文件,内容如图所示:从selenium包的子目录中导入了很多模块并做了重命名,用于支持如下Chrome/Edge/Ie/Firefox/Safari浏览器。
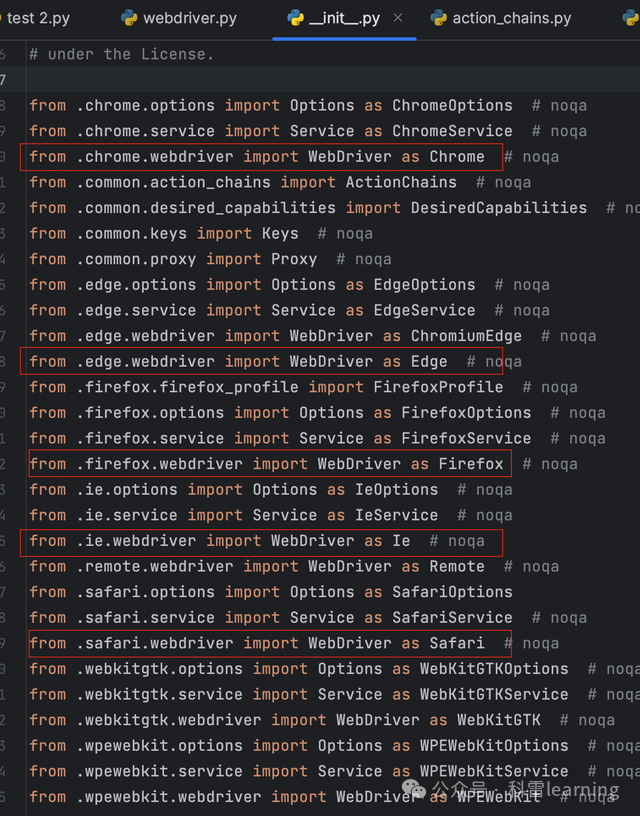
使用方法类似如下:
先导入webdriver模块
from selenium import webdriver初始化各个浏览器的webdriver类:
driver = webdriver.Chrome()
driver = webdriver.Edge()
driver = webdriver.Firefox()
driver = webdriver.Ie()
driver = webdriver.Safari()然后使用get函数打开网页地址,比如打开百度
driver.get("https://www.baidu.com/")4.1 web页面元素的查找方法
当打开网页后我们得先定位到网页中各个元素的位置和信息,这样selenium才能做对应的操作。
举例:打开百度网页后,通过查找元素,找到输入框和百度一下对应元素信息。
1)输入框的元素信息:<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
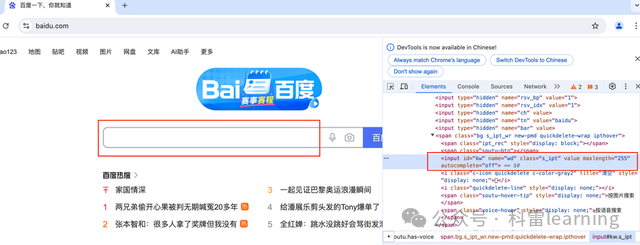
复制Xpath地址为://*[@id="kw"]
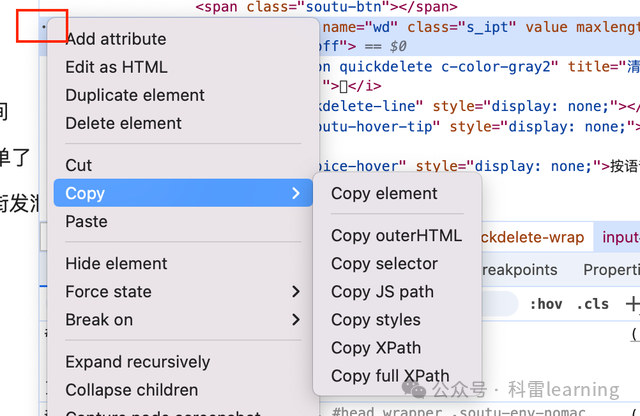
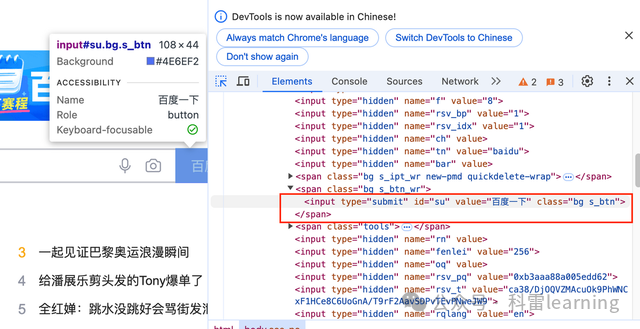
2)百度一下按钮的元素信息:
<input type="submit" id="su" value="百度一下" class="bg s_btn">
对应Xpath为://*[@id="su"]
3)通过以上元素信息我们就拿到了输入框和百度一下按钮的id信息,然后获取后输入文本和点击按钮,就完成了一次查找和点击的动作。
当然我们除了通过id获取元素,也可以通过name,xpath等方式操作,大家不妨多试下,此处不再赘述。
4.2 webdriver.WebDriver类中的常用方法
在webdriver模块中WebDriver类提供了很多方法,比如我们最常用的find_element方法用于找元素,get方法用于打开网页等,具体介绍如下:
| 类型 | 函数 | 作用 |
| 网页相关 | get() | 打开传入的URL网页地址 |
| current_url | 是一个属性方法,返回当前url | |
| page_source | 是一个属性方法,返回当前打开页面的源代码 | |
| refresh() | 刷新当前页面。 | |
| back() forward() | 浏览器的后退和前进操作。 | |
| implicitly_wait() | 是一种智能等待,指在设置的等待时间范围内,只要满足了执行条件,就会立即结束等待,继续往下进行,如果超时,则抛出异常。 | |
| set_script_timeout(seconds) | 设置脚本执行的时间,指在设置的等待时间范围内,只要满足了执行条件,就会立即结束等待,继续往下进行,如果超时,则抛出异常。 | |
| set_page_load_timeout(seconds) | 设置页面加载的时间,指在设置的等待时间范围内,只要满足了执行条件,就会立即结束等待,继续往下进行,如果超时,则抛出异常。 | |
| timeouts | 属性方法,返回包含上面三个时间的Timeouts对象,并可以设置三个时间的值。 | |
| cookies操作 | get_cookies() | 获取页面对应的cookie列表 |
| get_cookie(name) | 获取cookie列表中其中一个name=传入值的cookie,获取不到返回None | |
| delete_cookie(name) | 删除cookie列表中其中一个name=传入值的cookie | |
| delete_all_cookies() | 删除所有的cookie | |
| add_cookie(cookie_dict) | 添加一个cookie字典 | |
| 窗口操作 | maximize_window() minimize_window() fullscreen_window() | 最大化或最小化或者全屏浏览器窗口。 |
| window_handles() | 存放打开窗口的句柄,用于切换不同窗口 | |
| current_window_handle() | 返回当前窗口的句柄 | |
| switch_to.window() | 切换不同的窗口页面(参数传入window_handles() 返回的列表中的某个句柄) | |
| get_window_rect() | 获取窗口的坐标和大小 | |
| set_window_rect() | 设置窗口的坐标和大小(坐标指距离屏幕左上角的横坐标和竖坐标值) | |
| get_window_position() | 获取窗口的坐标,默认是当前窗口,也可以传某个窗口句柄(坐标指距离屏幕左上角的横坐标和竖坐标值) | |
| set_window_position() | 设置窗口的坐标,默认是当前窗口,也可以传某个窗口句柄 | |
| get_window_size() | 获取窗口的大小,默认是当前窗口,也可以传某个窗口句柄 | |
| set_window_size() | 窗口的大小,默认是当前窗口,也可以传某个窗口句柄 | |
| close() | 关闭当前窗口 | |
| SwitchTo类对应的一些操作: 提示框操作 frame操作 | switch_to.alert() | 切换到提示框对象 |
| switch_to.frame() | 切换到不同的frame | |
| switch_to.default_content() | 退出到默认frame | |
| switch_to.parent_frame() | 退出到上一级frame | |
| 执行js脚本 | execute_script() | 执行js脚本 |
| execute_async_script() | 异步的执行js脚本 | |
| 退出操作 | quit() | 关闭所有窗口,退出浏览器 |
selenium中查找元素方法
初始化好某浏览器的webdriver后,使用get函数打开网页地址,然后使用find_element(返回元素对象WebElement)或者find_elements方法(返回元素对象WebElement的列表)查找页面元素对象,有了元素对象,才能做接下来的一些操作,比如输入文本/点击按钮等。
,函数源代码如下:适用selenium4.23.1版本
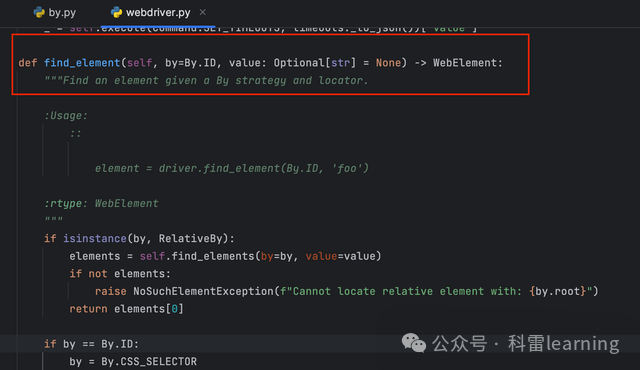
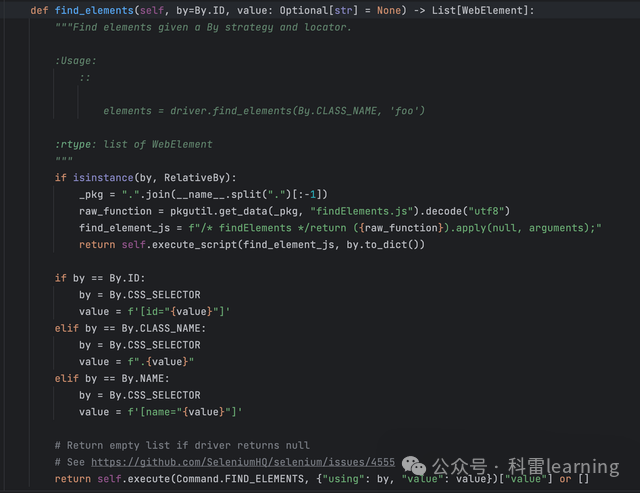
函数中的参数by表示定位元素的方式,在
selenium.webdriver.common.by.By中定义如下:
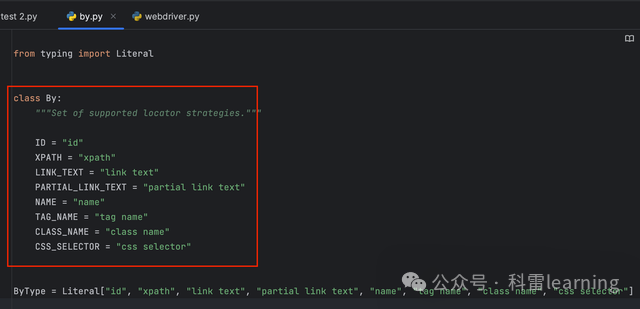
函数中的参数value表示参数by对应的值。
也就是说find_element函数可以通过以下8种方式进行元素定位:
["id", "xpath", "link text", "partial link text", "name", "tag name", "class name", "css selector"]
举例:使用Safari浏览器打开百度,以id来定位搜索框的元素位置。
from selenium import webdriver
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
driver.find_element(By.ID,'kw')举例:使用Safari浏览器打开百度,以name来定位搜索框的元素位置。
driver.find_element(By.NAME,'wd')
举例:使用Safari浏览器打开百度,以class来定位搜索框的元素位置。
driver.find_element(By.CLASS_NAME,'s_ipt')
举例:使用Safari浏览器打开百度,以Xpath来定位搜索框的元素位置。
driver.find_element(By.XPATH,'//*[@id="kw"]')
举例:使用Safari浏览器打开百度,以link text来定位新闻链接的元素位置。
driver.find_element(By.LINK_TEXT,'新闻')
设置隐式等待时间implicitly_wait
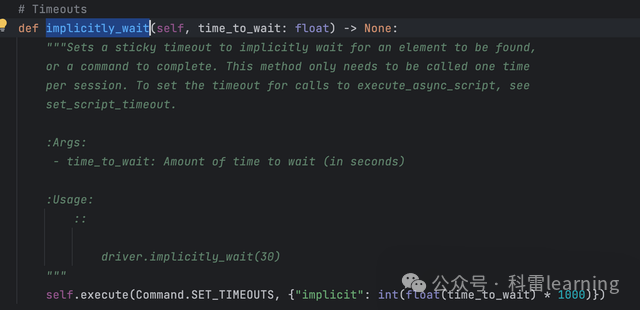
测试代码:
from selenium import webdriver
driver = webdriver.Safari()
driver.implicitly_wait(5)设置脚本等待时间set_script_timeout
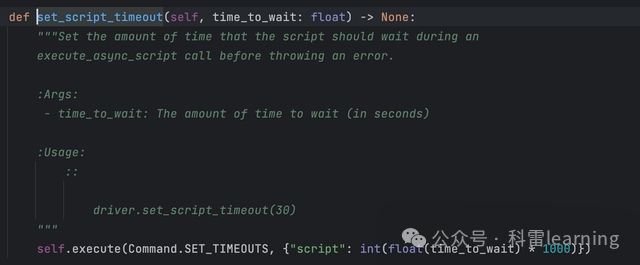
测试代码:
from selenium import webdriver
driver = webdriver.Safari()
driver.set_script_timeout(5)设置页面加载等待时间set_page_load_timeout
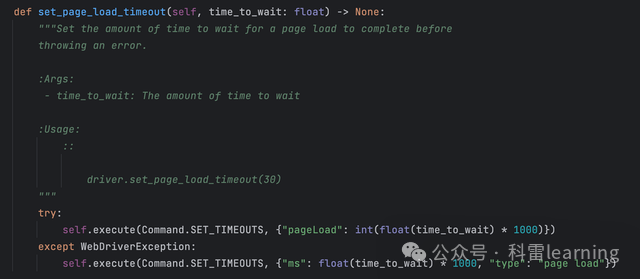
测试代码:
from selenium import webdriver
driver = webdriver.Safari()
driver.set_page_load_timeout(5)获取所有设置的等待或者超时时间timeouts
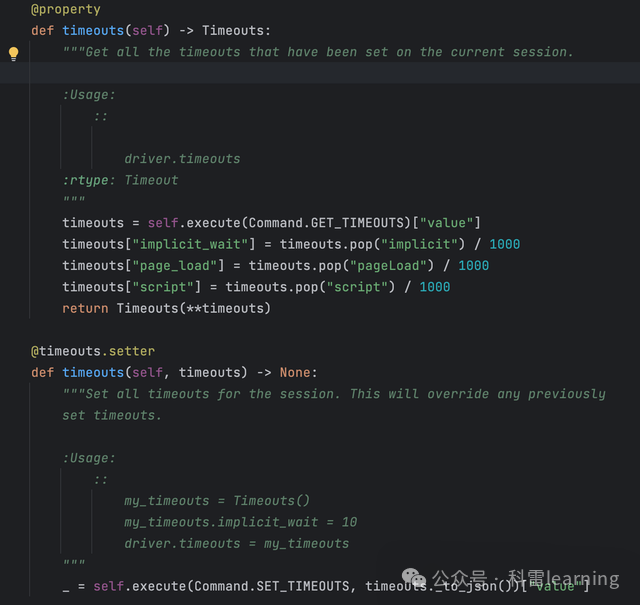
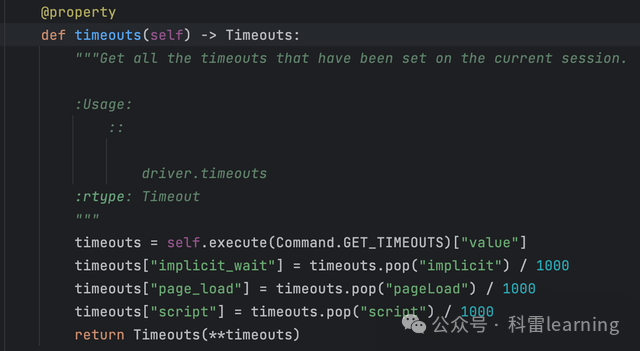
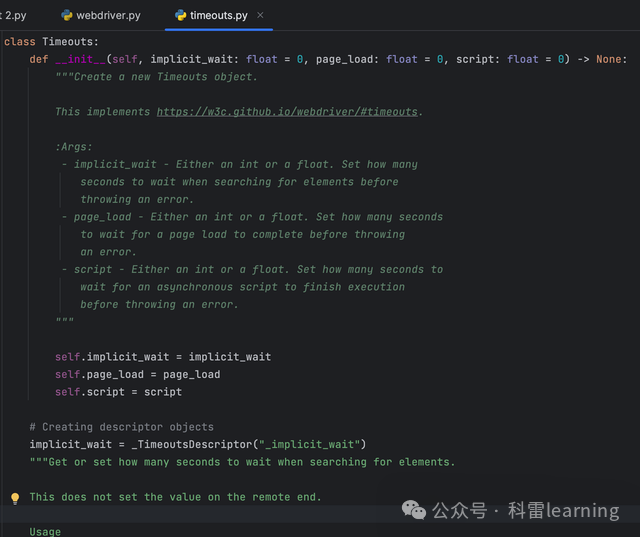
timeouts属性函数返回的是Timeouts类,包含三个属性
测试代码:
1)设置等待和超时时间后,通过timeouts属性函数读取这些设置的时间
from selenium import webdriver
driver = webdriver.Safari()
driver.implicitly_wait(5)
driver.set_script_timeout(5)
driver.set_page_load_timeout(5)
print(driver.timeouts.implicit_wait)
print(driver.timeouts.page_load)
print(driver.timeouts.script)执行结果:
5.0
5.0
5.0
2) 设置timuouts属性中三个时间
先导入Timeouts类
from selenium.webdriver.common.timeouts import Timeouts测试代码:
from selenium import webdriver
#初始化Timeouts类 并设置时间
timeouts_new = Timeouts()
timeouts_new.implicit_wait = 4
timeouts_new.page_load = 4
timeouts_new.script = 4
#将属性timeouts设置为Timeouts对象
driver.timeouts = timeouts_new
#打印3个时间值
print(driver.timeouts.implicit_wait)
print(driver.timeouts.page_load)
print(driver.timeouts.script)执行结果:
4.0
4.0
4.0
网页的一些操作方法
先定义Safari浏览器的driver对象
from selenium import webdriver
driver = webdriver.Safari()-
打开传入的URL网页地址
driver.get("https://www.toutiao.com/")
-
返回当前url
print(driver.current_url)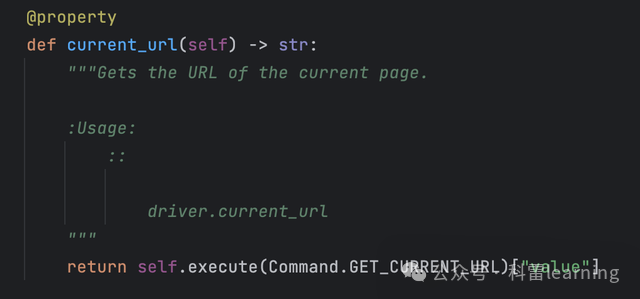
-
page_source 是一个属性方法,返回当前打开页面的源代码
print(driver.page_source)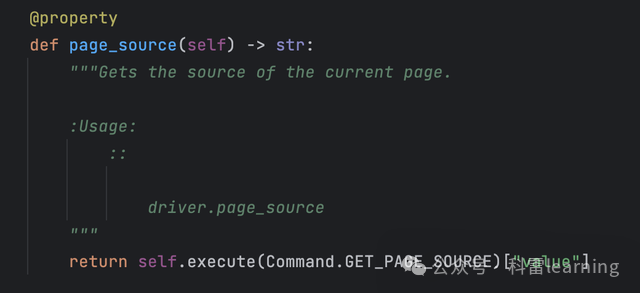
-
refresh() 刷新当前页面。
driver.refresh()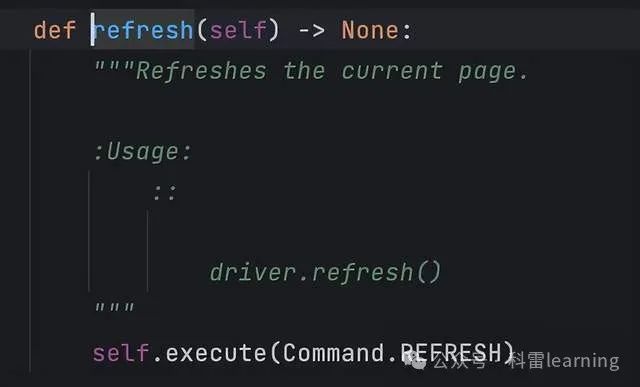
-
back()和forward() 浏览器的后退和前进操作。
driver.back()
driver.forward()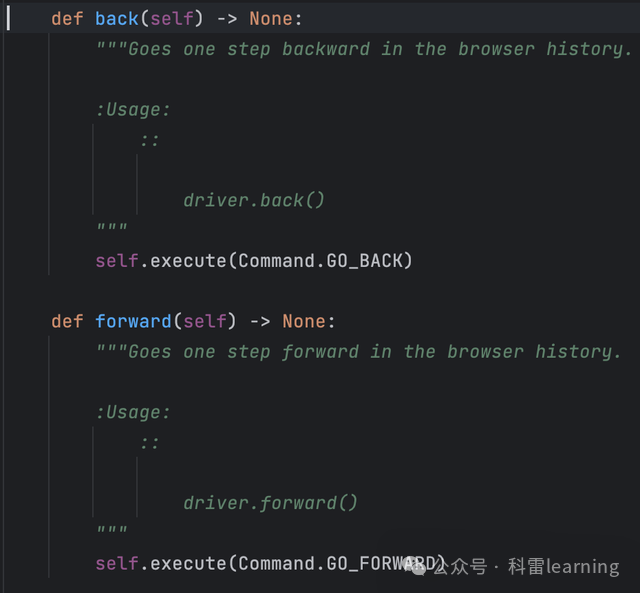
-
退出webdriver
driver.quit()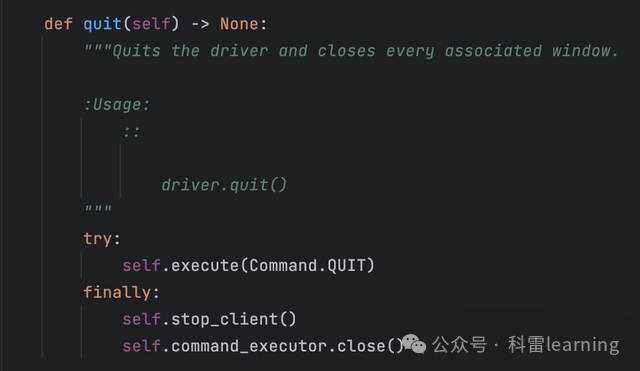
cookie操作方法
from selenium import webdriver-
获取所有cookie
print(driver.get_cookies())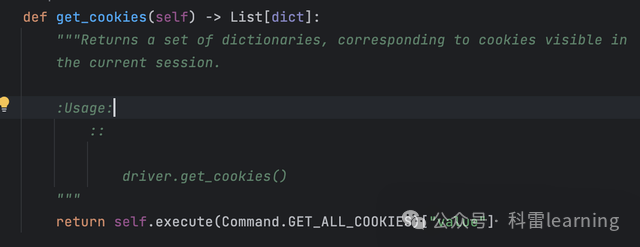
-
获取某个name值的cookie
print(driver.get_cookie('__ac_nonce'))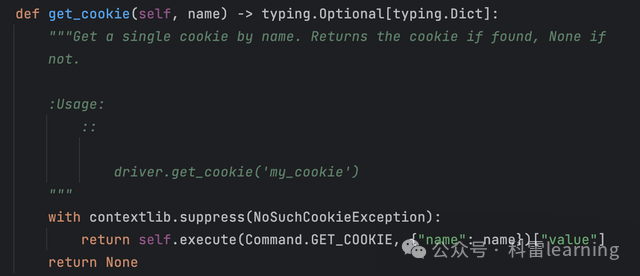
-
删除某个name值的cookie
driver.delete_cookie('__ac_nonce')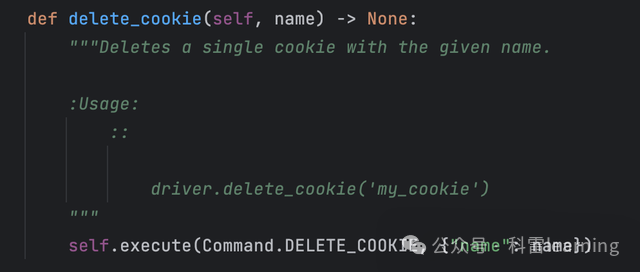
-
删除所有cookie
driver.delete_all_cookies()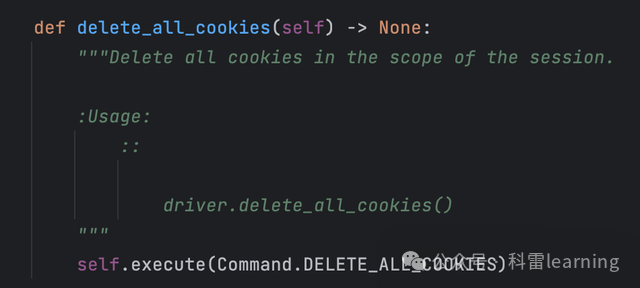
-
添加一个cookie
driver.add_cookie({'name':'nonce', 'value': '7421004976065267240'})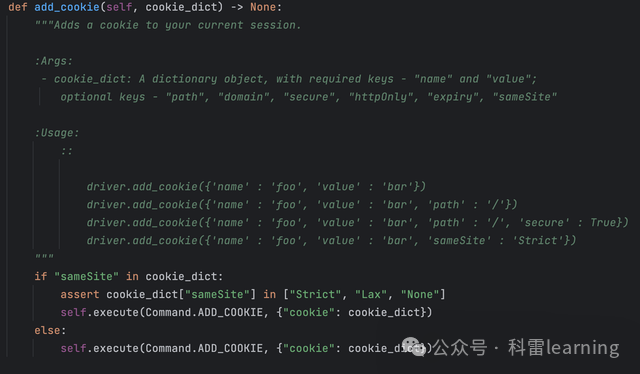
窗口操作方法
from selenium import webdriver-
获取窗口大小并设置窗口大小
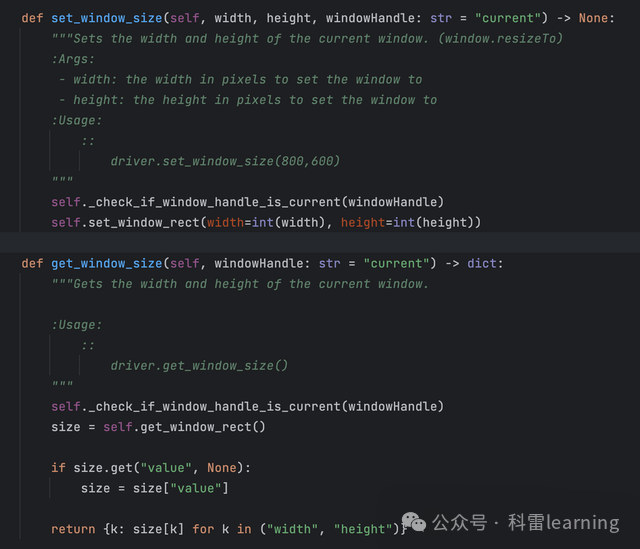
#获取窗口大小
print(driver.get_window_size())
#设置大小
driver.set_window_size(1000,600)
print(driver.get_window_size())-
获取窗口坐标并设置窗口坐标
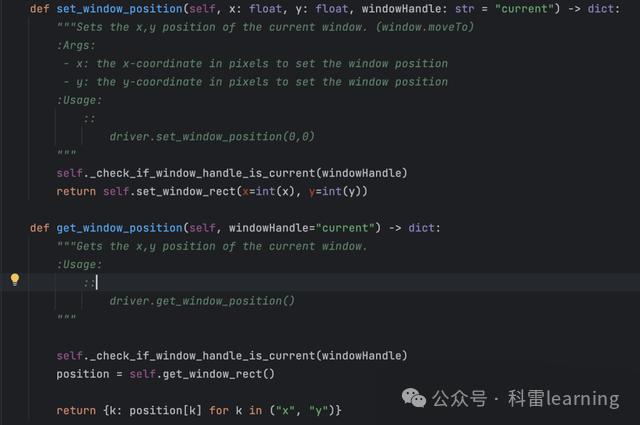
#获取坐标
print(driver.get_window_position())
#设置坐标
driver.set_window_position(20,30)
print(driver.get_window_position())-
获取窗口坐标和大小并设置窗口坐标和大小
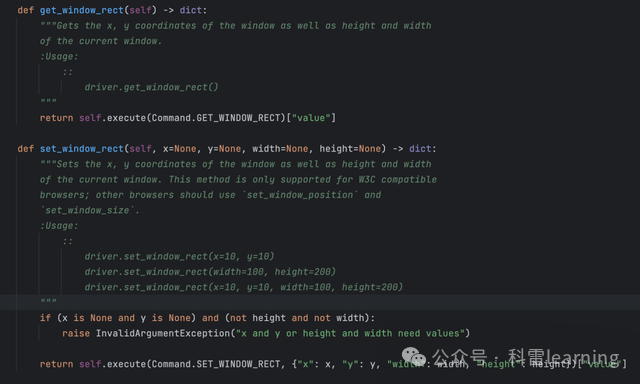
#获取坐标和大小
print(driver.get_window_rect())
#设置坐标和大小
driver.set_window_rect(20,30,800,700)
print(driver.get_window_rect())-
窗口最大化/最小化/全屏
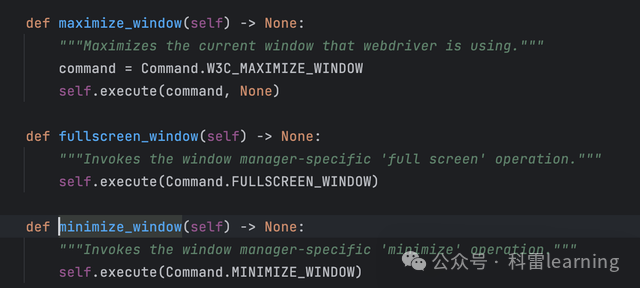
driver.minimize_window()
driver.maximize_window()
driver.fullscreen_window()-
关闭窗口
driver.close()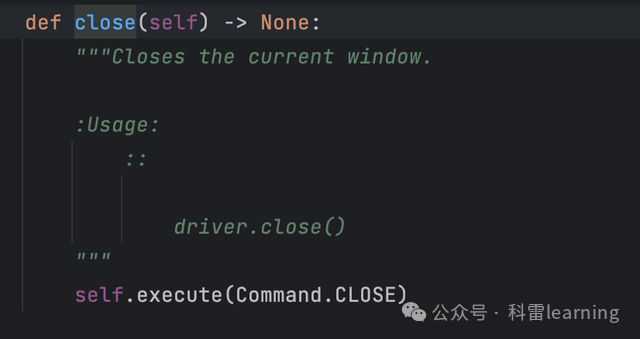
-
切换窗口
通过driver.window_handles获取打开窗口的句柄列表,然后通过driver.switch_to.window()切换不同的窗口
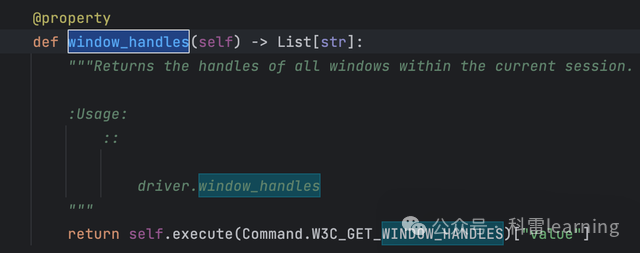
以百度网站举例,打开新闻链接,然后切换窗口
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
driver.maximize_window()
sleep(2)
#打开新闻链接
driver.find_element(By.LINK_TEXT,'新闻').click()
#打印文件句柄
print(driver.window_handles)
#循环切换窗口
while True:
for i in driver.window_handles:
sleep(1)
driver.switch_to.window(i)程序执行后,会打开新闻,然后来回切换两个窗口

当我们通过webdriver中的find_element函数定位到元素后,其实返回的是WebElement对象,而该对象有很多重要的方法,比如输入文本,点击按钮,获取属性,截屏等
5 WebElement类的方法介绍
常用方法
| 文本输入与清除 | send_keys() | 在元素上模拟按键输入,通常用于向输入框中填充文本。 |
| clear() | 清除元素的输入内容,如清空一个文本输入框。 | |
| 点击操作 | click() | 单击元素,可以是按钮、链接等可点击的元素。 |
| submit() | 提交表单,也可以使用click()方法,但submit()方法专门用于表单的提交。 | |
| 元素属性与状态获取 | get_attribute(element_name) | 获取元素的属性值,如id、name、type等。 |
| is_selected() | 判断元素是否被选中,常用于单选框、复选框等。 | |
| is_displayed() | 判断元素是否可见,返回一个布尔值。 | |
| is_enabled() | 判断元素是否可启用,例如,某些按钮在特定条件下可能不可点击。 | |
| 获取元素尺寸与位置 | size | 返回元素的尺寸,通常包含宽度和高度。 |
| location | 返回元素在页面上的位置,通常是元素的左上角坐标。 | |
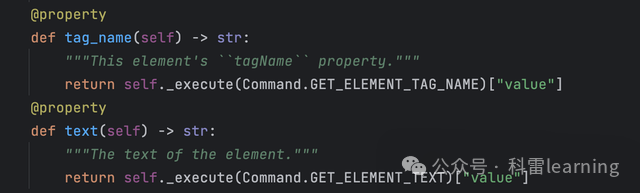
| 获取元素信息 | text | 获取元素的文本内容,如获取一个段落或链接的文本。 |
| tag_name | 获取元素的tag信息。 | |
| 截屏 | screenshot(filename) | 将当前元素截屏保存为png图片 |
| screenshot_as_base64 | 将当前元素截屏保存为base64编码的字符串 | |
| screenshot_as_png | 将当前元素截屏保存为base64字符串,然后解码为2进制字节码 |
以上函数位于如下webelement.WebElement类中:
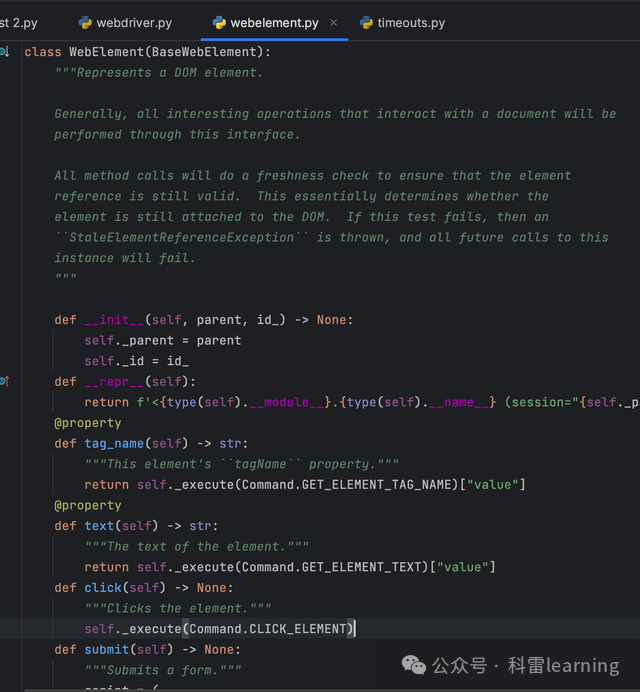
示例:打开百度输入文本后点击搜索(输入框操作)
我们以获取元素的id举例,先上代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 创建Safari浏览器的WebDriver实例
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
#最大化网页
driver.maximize_window()
#查找id=kw的元素位置,对应于搜索输入框,找到后我们输入字符python
driver.find_element(By.ID,'kw').send_keys('python')
##查找id=su的元素位置,对应于‘百度一下’的按钮,找到后我们点击按钮
driver.find_element(By.ID,'su').click()
# 等待几秒
sleep(5)
# 关闭浏览器
driver.quit()代码执行后,网页自动打开并搜索如下:
示例:打开百度输入用户名和密码进行登录(表单操作)
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
driver.maximize_window()
sleep(1)
#点击登录
driver.find_element(By.ID,'s-top-loginbtn').click()
sleep(1)
#输入用户名
driver.find_element(By.ID,'TANGRAM__PSP_11__userName').send_keys('*****')
sleep(1)
#输入密码
driver.find_element(By.ID,'TANGRAM__PSP_11__password').send_keys('*****')
sleep(1)
#点击同意
driver.find_element(By.ID,'TANGRAM__PSP_11__isAgree').click()
sleep(1)
#点击提交
driver.find_element(By.ID,'TANGRAM__PSP_11__submit').submit()程序执行后会自动输入用户和密码,点击登录。
示例:获取元素后将元素截屏
我们获取元素后,使用函数screenshot将元素截屏,参数filename传入完整的png文件名路径或者文件名(放在当前路径)
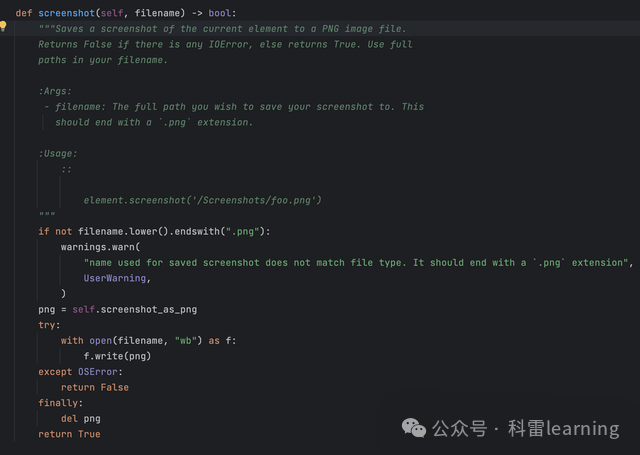
测试代码:打开头条网站,定位到左上角的‘下载头条app’然后截屏保存。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
#打开传入的URL网页地址
driver.get("https://www.toutiao.com/")
sleep(6)
element = driver.find_element(By.XPATH,'//*[@id="root"]/div/div[3]/div[1]/div')
element.screenshot('1.png')
element.screenshot('/Users/aaa/Donwloads/1.png')执行后打开截图如下:

示例:获取元素的text/ta gtag_name信息
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
#打开传入的URL网页地址
driver.get("https://www.toutiao.com/")定位到左上角的‘下载头条app’元素,并打印元素的信息
element = driver.find_element(By.XPATH,'//*[@id="root"]/div/div[3]/div[1]/div')
#打印该元素的一些信息
print(element.tag_name)
print(element.text)
执行结果:
DIV
下载头条APP扫码下载今日头条示例:获取元素的属性值
通过get_attribute函数,传入参数比如id,class,xpath等信息,返回对应的值。
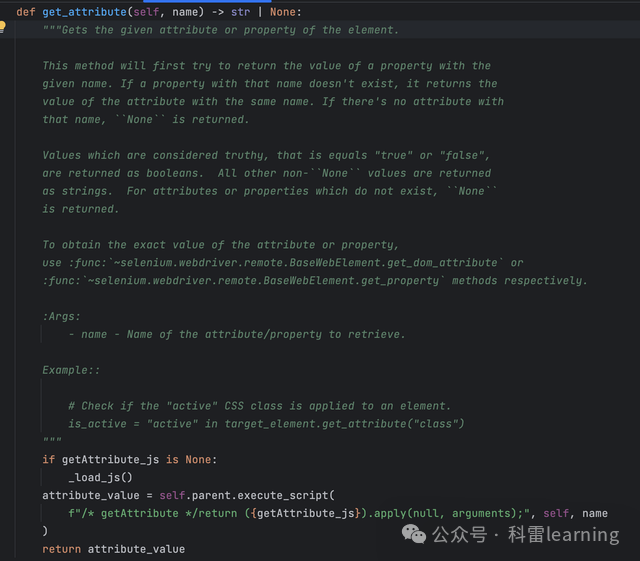
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
#打开传入的URL网页地址
driver.get("https://www.toutiao.com/")
#定位到左上角的‘下载头条app’然后截屏保存。
element = driver.find_element(By.XPATH,'//*[@id="root"]/div/div[3]/div[1]/div')
#打印该元素的属性值
print(element.get_attribute('class'))执行结果:
download-app-wrapper
6 Alert类用于操作提示框/确认弹框
之前文章我们提到,在webdriver.WebDriver类有一个switch_to方法,通过switch_to.alert()
可以返回Alert对象,而Alert对象主要用于网页中弹出的提示框/确认框/文本输入框的确认或者取消等动作。
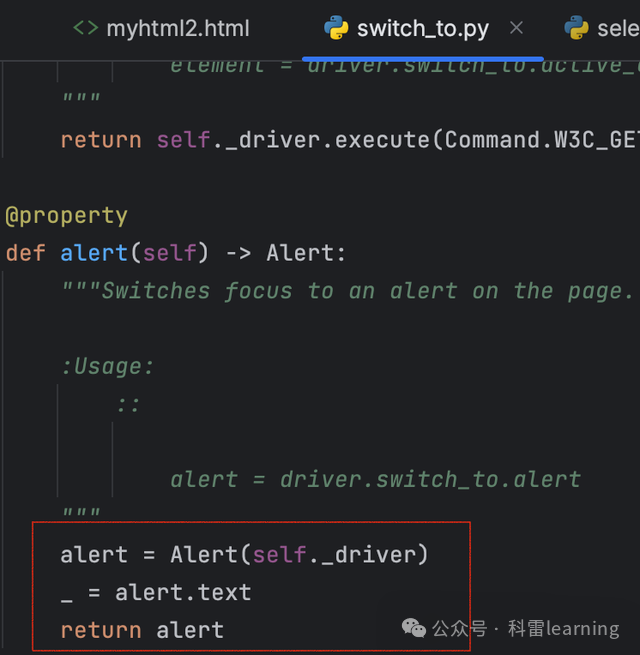
Alert介绍
当在页面定位到提示框/确认框/文本录入框并点击后,页面会弹出对话框,通过driver.switch_to.alert切换到Alert对象。
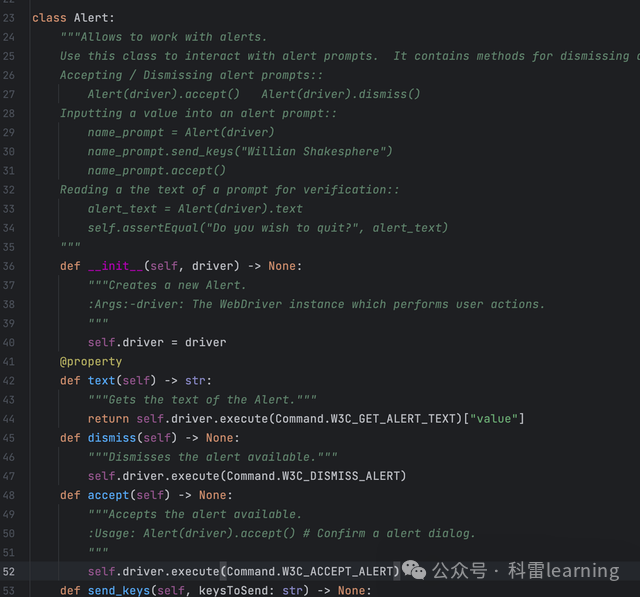
Alert类主要提供四个方法:
-
accept(): 在弹出的对话框中点击确认
-
dismiss():在弹出的对话框中点击取消
-
send_keys(str):在弹出的对话框中录入文本
-
text:属性方法,获取对话框的text信息
示例:自定义一个html文件包括提示框/确认框/文本录入框
我们自定义一个html文件,包含一个提示框 确认框 文本输入框信息,html文件如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<a href="javascript:alert('提示框')" id="alert" >提示</a><br>
<a href="javascript:confirm('确认删除吗?')" id="conform" >删除</a><br>
<a href="javascript:var content=prompt('请输入文本');document.write(content)" id="prompt" >录入</a><br>
<input type="submit" value="提交" id="su" class="btn self-btn bg s_btn">
</body>
</html>html文件打开后如下,可以点击弹出提示框,确认框和文本输入框

示例:点击提示框,点击确认
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
# 打开一个网页
driver.get("file:///Users/htsc/Desktop/myhtml2.html")
driver.maximize_window()
sleep(2)
#定位到提示框并点击
driver.find_element(By.ID,'alert').click()
sleep(1)
#切换到提示框对象
alertins = driver.switch_to.alert
#点击确认
alertins.accept()
sleep(3)点击删除,弹出确认框,可点击取消或者确认
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
# 打开一个网页
driver.get("file:///Users/htsc/Desktop/myhtml2.html")
driver.maximize_window()
sleep(2)
#定位到删除并点击
driver.find_element(By.ID,'confirm').click()
sleep(1)
#切换到确认框对象
alertins = driver.switch_to.alert
#点击确认或者点击取消
alertins.accept()
alertins.dismiss()
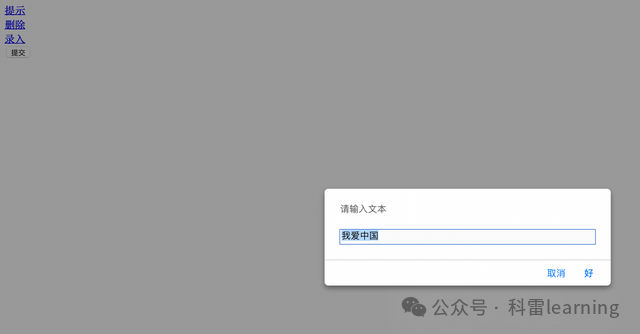
sleep(3)点击录入,弹出文本输入框,输入文本后点击确认或者取消
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
# 打开一个网页
driver.get("file:///Users/htsc/Desktop/myhtml2.html")
driver.maximize_window()
sleep(2)
#定位到删除并点击
driver.find_element(By.ID,'prompt').click()
sleep(1)
#输入文本信息
alertins.send_keys('我爱中国')
sleep(1)
#切换到确认框对象
alertins = driver.switch_to.alert
#点击确认或者点击取消
alertins.accept()
alertins.dismiss()
sleep(3)程序执行后,录入信息,截图如下:
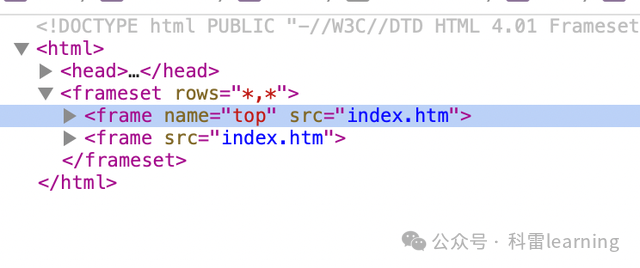
7 selenium有多个frame页时的操作方法
之前文章我们提到,在webdriver.WebDriver类有一个switch_to方法,通过switch_to.frame()可以切换到不同的frame页然后才再定位某个元素做一些输入/点击等操作。
比如下面这个测试网站有2个frame页:
http://www.sahitest.com/demo/framesTest.htm,每个frame页的元素是一样的。
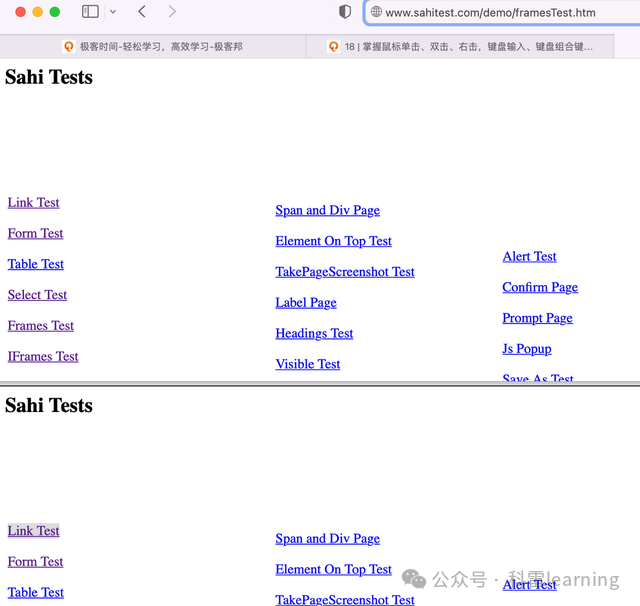
检查下Link Test的元素信息,发现两个frame,在每个frame下面都有这个元素的相同信息。
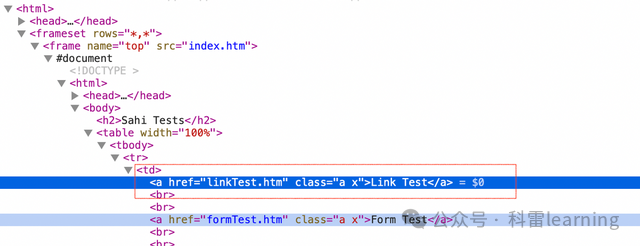
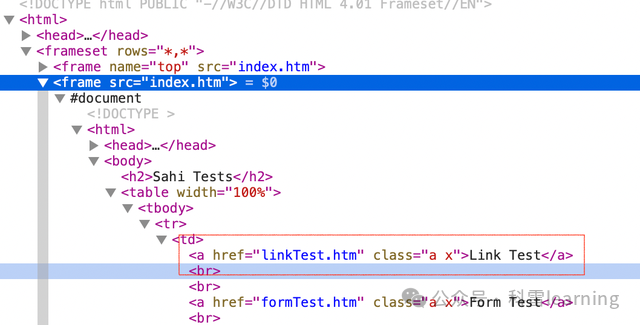
switch_to.frame方法
当我们定义好driver对象,打开网页并使用driver.switch_to.frame()方法切换frame时,该方法其实调用了selinium中的SwitchTo类中的frame方法:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
# 打开一个网页
driver.get("http://www.sahitest.com/demo/framesTest.htm")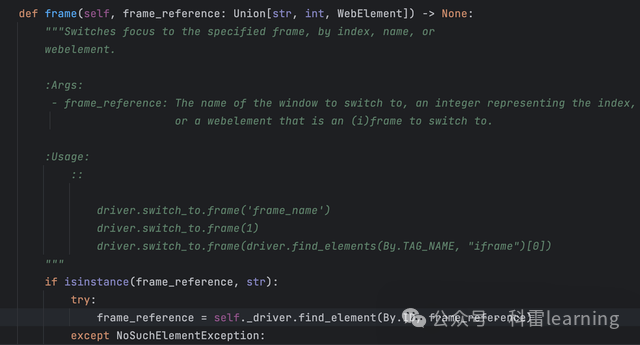
方法中的参数frame_reference可以是fame的name,或者代表frame的数字(从0开始),或者是该frame元素位置,如函数中的的介绍。
-
driver.switch_to.frame('frame_name')
-
driver.switch_to.frame(1)
-
driver.switch_to.frame(driver.find_elements(By.TAG_NAME, "iframe")[0])
示例:分别打开网页上面和下面对应的‘Link Test’链接
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
# 打开一个网页
driver.get("http://www.sahitest.com/demo/framesTest.htm")
driver.maximize_window()
sleep(2)
#先切换到第1个frame
driver.switch_to.frame(0)
sleep(1)
#点击TestLink链接
driver.find_element(By.XPATH,'/html/body/table/tbody/tr/td[1]/a[1]').click()
sleep(2)
#完成后 先返回上一级frame或者默认frame 然后才能切换到第2个frame
#以下两个方法都可使用
driver.switch_to.default_content()
#driver.switch_to.parent_frame()
#切换第2个frame
driver.switch_to.frame(1)
sleep(1)
driver.find_element(By.XPATH,'/html/body/table/tbody/tr/td[1]/a[1]').click()
sleep(4)8 ActionChains类模拟鼠标和键盘操作
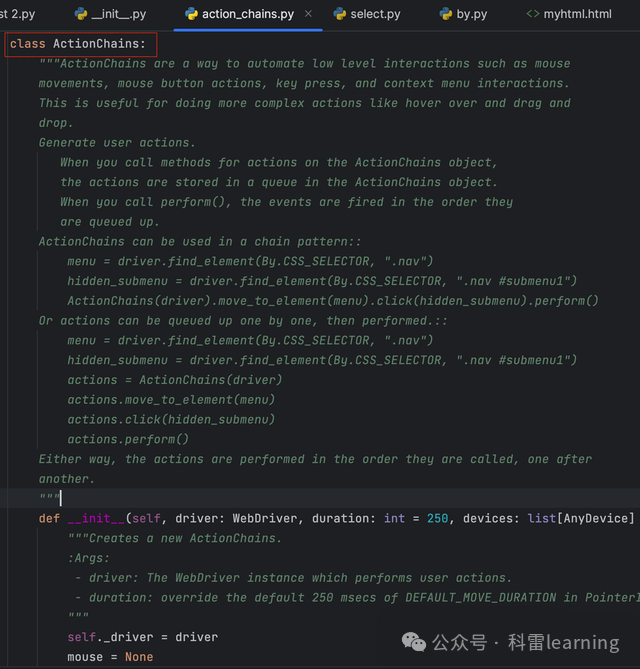
selenium包中提供了ActionChains类,主要用于鼠标和键盘的一些操作,比如鼠标移动,鼠标按键,或者是悬停和拖放等;模拟键盘按键输入,比如按住control+C键等。
使用时先导入该类:
from selenium.webdriver import ActionChains
ActionChains类的方法
| 函数 | 功能 |
| move_to_element | 鼠标移动到某个元素位置 |
| move_to_element_with_offset | 鼠标移动到离某个元素距离多少的位置 |
| move_by_offset | 移动鼠标到某个坐标 |
| click | 单击鼠标左键 |
| click_and_hold | 单击鼠标左键不松开 |
| double_click | 双击鼠标左键 |
| context_click | 点击鼠标右键 |
| drag_and_drop | 拖拽到某个元素然后松开 |
| drag_and_drop_by_offset | 拖拽到某个坐标然后松开 |
| key_down | 按下某个键盘上的按键; 键盘输入通常用到如下Keys类中的属性 from selenium.webdriver.common.keys import Keys |
| key_up | 松开某个按键 |
| first_selected_option | 第一个选择的选项 |
| send_keys | 可发送多个键盘上的按键到当前焦点位置,循环的模拟输入按键和松开按键 ; 上面提到的send_keys模拟文本输入,功能有所不同。 |
| send_keys_to_element | 发送某个按键到某个元素 |
| pause | 暂停执行一段时间 |
| release | 在元素上释放按住的鼠标按钮 |
| reset_actions | 清除已经储存的上述方法中的动作 |
| perform | 执行已经存储的上述方法中的动作。想要执行上述方法,最后需要执行该函数来生效。 |
方法执行类似如下:移动鼠标到某个定位到的元素,然后右键点击,最后加上perform函数完成整个动作(actchain_ins为ActionChains类初始化的实例对象)。
actchain_ins.move_to_element(driver.find_element(By.ID,'su')).context_click().perform()
示例:打开百度网页,将鼠标定位到‘更多’展示隐藏的内容
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
driver.maximize_window()
sleep(2)
#初始化ActionChains类
actchain_ins = webdriver.ActionChains(driver)
#移动到‘更多’元素的位置
actchain_ins.move_to_element(driver.find_element(By.NAME,'tj_briicon')).perform()
actchain_ins.pause(5).perform()执行后展示如图:

示例:打开百度输入用户名和密码进行登录(表单操作)
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
driver.maximize_window()
sleep(1)
#初始化ActionChains类
actchain_ins = webdriver.ActionChains(driver)
#模拟鼠标点击登录按钮
actchain_ins.move_to_element(driver.find_element(By.ID,'s-top-loginbtn')).click().perform()
sleep(1)
#输入用户名
driver.find_element(By.ID,'TANGRAM__PSP_11__userName').send_keys('*******')
sleep(1)
#输入密码
driver.find_element(By.ID,'TANGRAM__PSP_11__password').send_keys('*******')
sleep(1)
#模拟鼠标点击‘阅读并接受’前面的选框
actchain_ins.move_to_element(driver.find_element(By.ID,'TANGRAM__PSP_11__isAgree')).click().perform()
sleep(1)
#模拟鼠标点击登录
actchain_ins.move_to_element(driver.find_element(By.ID,'TANGRAM__PSP_11__submit')).click().perform()
sleep(3)程序执行后会自动输入用户和密码,点击登录,如下图:
示例:打开百度后在百度一下按钮处点击鼠标右键
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
driver.maximize_window()
sleep(2)
#ActionChains初始化
actchain_ins = webdriver.ActionChains(driver)
#在百度一下按钮处,点击右键
actchain_ins.move_to_element(driver.find_element(By.ID,'su')).context_click().perform()
示例:打开百度输入要搜索的内容后发送键盘键进行剪切和粘贴
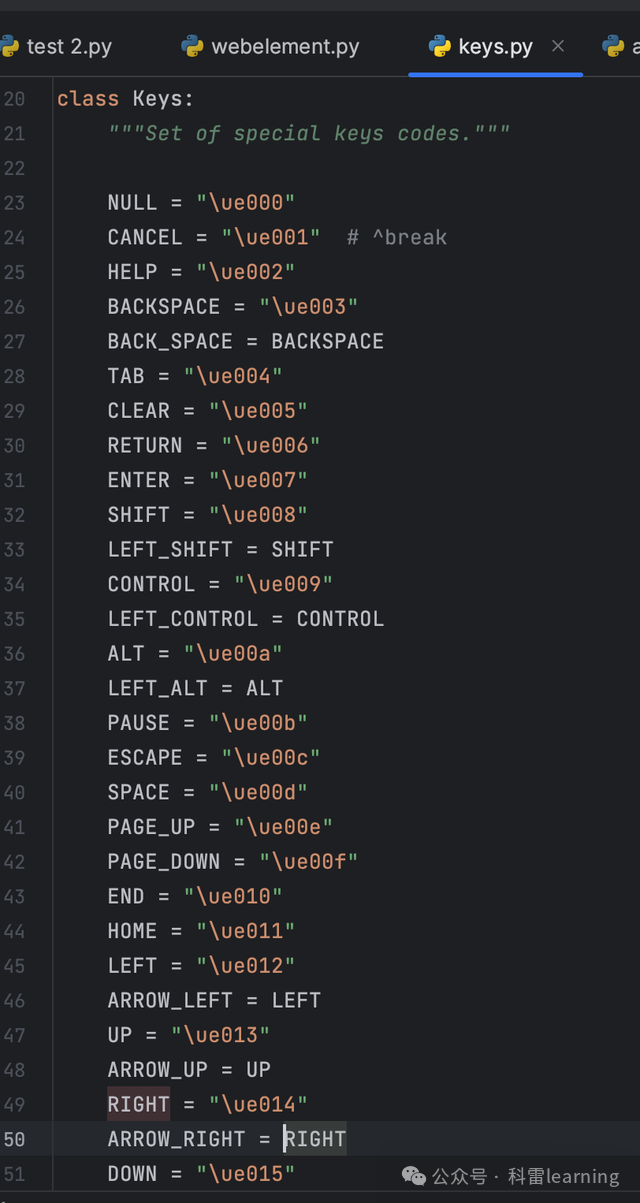
键盘输入使用的是如下Keys类,使用前我们先导入
from selenium.webdriver.common.keys import KeysKeys类有很多键盘的按键属性:

主要使用方法:通过key_down按下某个按键,通过send_keys发送某个按键,然后key_up松开某个按键。比如下面这个按住苹果电脑上的COMMAND+A键,然后再松开COMMAND键,完成全选动作。
actchain_ins.key_down(Keys.COMMAND).send_keys('A').key_up(Keys.COMMAND).perform()
测试代码如下:输入搜索内容后,全选文本后,剪切然后再粘贴。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
driver.maximize_window()
sleep(2)
#初始化
actchain_ins = webdriver.ActionChains(driver)
driver.find_element(By.ID,'kw').send_keys('python')
#control+A复制 苹果电脑是COMMAND键
actchain_ins.key_down(Keys.COMMAND).send_keys('A').key_up(Keys.COMMAND).perform()
sleep(1)
#control+X剪切
actchain_ins.key_down(Keys.COMMAND).send_keys('X').key_up(Keys.COMMAND).perform()
sleep(1)
#control+V粘贴
actchain_ins.key_down(Keys.COMMAND).send_keys('V').key_up(Keys.COMMAND).perform()
sleep(20)执行后,录制的视频如下:
剪切粘贴
示例:使用ActionChains 类模拟鼠标滚轮操作
使用函数ActionChains.send_keys发送按键Keys.PAGE_DOWN往下滑动页面,发送按键Keys.PAGE_UP往上滑动页面。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.toutiao.com/")
driver.maximize_window()
sleep(6)
actions = webdriver.ActionChains(driver)
# 向下翻页
actions.send_keys(Keys.PAGE_DOWN).perform()
# 向上翻页
actions.send_keys(Keys.PAGE_UP).perform()9 复选框/下拉框操作的Select类
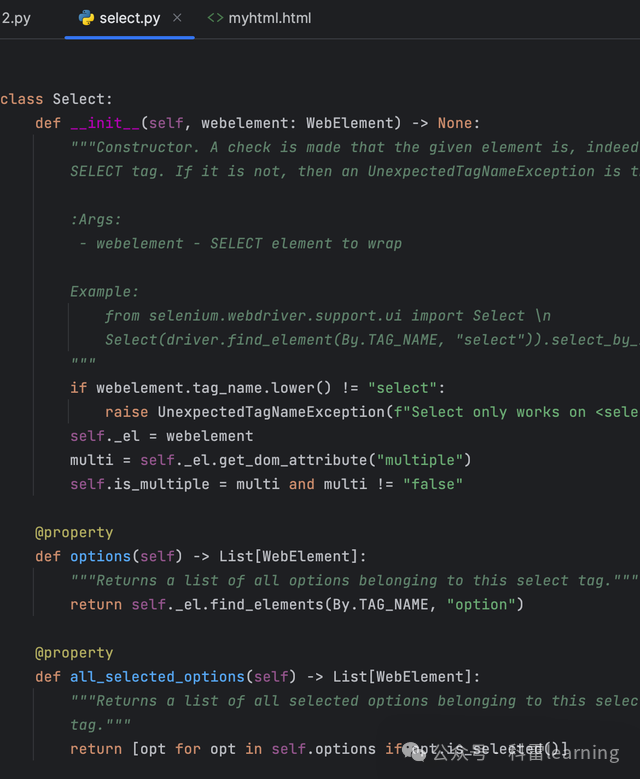
主要使用selinium中的类Select来模拟选择网页上的下拉框或者复选框中的内容,使用前先导入
from selenium.webdriver.support.ui import Select
主要方法如下:
| 函数 | 功能 |
| select_by_value | 根据复选框/下拉框的值选择 |
| select_by_index | 根据复选框/下拉框的索引选择 |
| select_by_visible_text | 根据复选框/下拉框文本描述选择 |
| deselect_by_value | 根据复选框/下拉框的值反选 |
| deselect_by_index | 根据复选框/下拉框的索引反选 |
| deselect_by_visible_text | 根据复选框/下拉框文本描述反选 |
| deselect_all | 反选所有值 |
| options | 返回所有选项 |
| all_selected_options | 返回所有选中的选项 |
| first_selected_option | 第一个选择的选项 |
我们自定义一个html文件,放一个多选框和下拉框方便测试
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="/submit-path">
<label for="fruits">Choose your favorite fruit:</label>
<select id="fruits" name="fruits" multiple>
<option value="apple">Apple</option>
<option value="orange">Orange</option>
<option value="banana">Banana</option>
<option value="grape">Grape</option>
</select>
</form>
<form action="/submit-path">
<label for="animals">Choose your favorite animal:</label>
<select id="animals" name="animals">
<option value="dog">Dog</option>
<option value="cat">Cat</option>
<option value="tiger">Tiger</option>
</select>
</form>
<input type="submit" value="提交" id="su" class="btn self-btn bg s_btn">
</body>
</html>打开这个html页面如下:一个多选框和一个下拉框
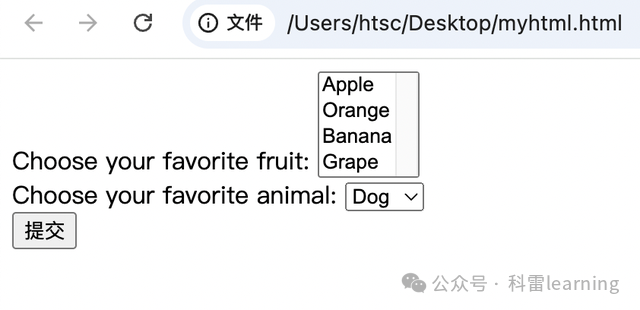
示例:打开html文件,选择多选框内容和下拉框内容。
打开网页,并初始化Select类:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
driver = webdriver.Safari()
# 打开一个网页
driver.get("file:///Users/abc/Desktop/myhtml.html")
driver.maximize_window()
sleep(2)
#初始化Select类,传入水果多选框对应的元素位置
select_content1 = Select(driver.find_element(By.ID,'fruits'))
#初始化Select类,传入动物下拉框对应的元素位置
select_content2 = Select(driver.find_element(By.ID,'animals'))使用select_by_value函数选择水果多选框第1个和第2个内容
select_content1.select_by_value('apple')
select_content1.select_by_value('orange')
使用deselect_all函数去掉水果多选框的所有的选择
select_content1.deselect_all()使用select_by_index函数选择动物下拉框的第3个内容
select_content2.select_by_index(2)执行结果如视频所示:
,时长00:05
10 selenium支持操作滚动条
使用ActionChains 类模拟鼠标滚轮操作
使用函数ActionChains.send_keys发送按键Keys.PAGE_DOWN往下滑动页面,发送按键Keys.PAGE_UP往上滑动页面。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.toutiao.com/")
driver.maximize_window()
sleep(6)
actions = webdriver.ActionChains(driver)
# 向下翻页
actions.send_keys(Keys.PAGE_DOWN).perform()
# 向上翻页
actions.send_keys(Keys.PAGE_UP).perform()使用函数execute_script执行js脚本滚动页面
可以使用如下三种方式
1)使用window.scrollBy(x, y)
driver.execute_script('window.scrollBy(0, 1000)')
参数解释:
x:正数表示向右滑动的像素值,负数表示向左滑动的像素值
y:正数表示向下滑动的像素值,负数表示向上滑动的像素值
2)使用window.scrollTo(x, y)
driver.execute_script('window.scrollTo(0, 1000)')
参数解释:
x:正数表示向右滑动到某个像素值,负数表示向左滑动到某个像素值
y:正数表示向下滑动到某个像素值,负数表示向上滑动到某个像素值
3)使用
document.documentElement.scrollTop()设置滚动条高度
设置滚动高度为某个像素值:
driver.execute_script("document.documentElement.scrollTop=1000")
测试代码:使用上面3个️方式向下滚动,然后再向上滚动(中间通过sleep等待几秒方便观察效果).
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
# 打开一个网页
#driver.get("http://www.sahitest.com/demo/framesTest.htm")
driver.get("https://www.toutiao.com/")
driver.maximize_window()
sleep(6)
#向下滚动
driver.execute_script('window.scrollBy(0, 100)')
sleep(1)
driver.execute_script('window.scrollTo(0, 200)')
sleep(1)
driver.execute_script("document.documentElement.scrollTop=300")
sleep(1)
#向上滚动
driver.execute_script('window.scrollBy(0, -100)')
sleep(1)
driver.execute_script('window.scrollTo(0, -200)')
sleep(1)
driver.execute_script("document.documentElement.scrollTop=-300")
sleep(1)使用函数execute_script执行js脚本滚动到特定元素
我们可以直接找到需要滚动到的元素位置,并使用scrollIntoView方法滚到该位置
示例代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
driver.get("https://www.toutiao.com/")
driver.maximize_window()
sleep(6)
# 找到某个目标元素
element = driver.find_element(By.XPATH,'//*[@id="root"]/div/div[5]/div[2]/div[6]/a[15]')
# 滚动到目标元素
driver.execute_script("arguments[0].scrollIntoView();", element)11 selenium工具的几种截屏方法
将整个页面截屏
在webdriver模块中有几种截屏的方法,主要介绍如下:
- save_screenshot(filename)
filename传入以png结尾的文件路径。
- get_screenshot_as_file (filename)
filename传入以png结尾的文件路径。
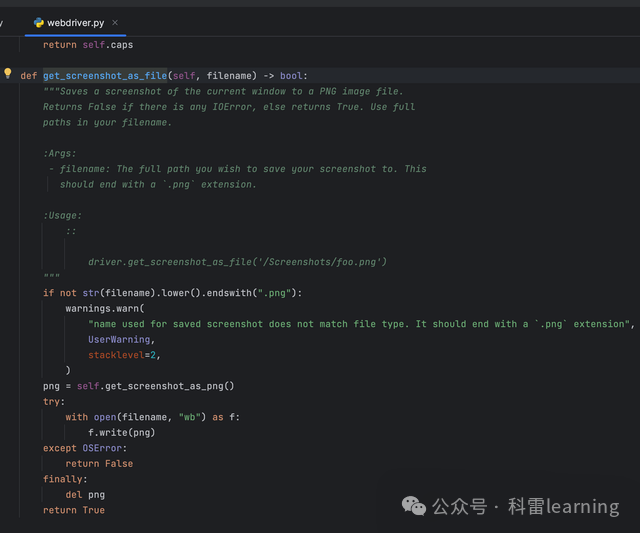
- 还有两个方法保存的是字节码或者字符串
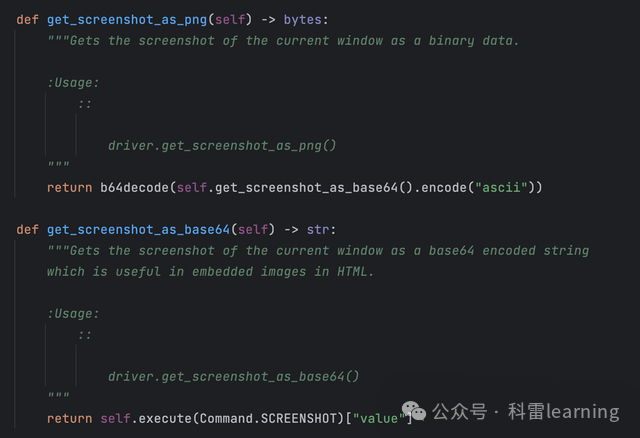
使用get_screensho_as_png函数保存截屏为字节码
使用get_screensho_as_base64函数保存截屏为base64编码后的字符串
driver.get_screenshot_as_png()
driver.get_screenshot_as_base64()示例:打开头条后,截图
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
#打开传入的URL网页地址
driver.get("https://www.toutiao.com/")
driver.maximize_window()使用save_screenshot函数截图保存为png图片
driver.save_screenshot('toutiao1.png')使用save_screensho_as_filet函数截图保存为png图片
driver.get_screenshot_as_file('toutiao2.png')12 selenium的IDE插件进行录制和回放并导出为python/java脚本
Selenium IDE:Selenium Suite下的开源Web自动化测试工具,是Firefox或者chrome的一个插件,具有记录和回放功能,无需编程即可创建测试用例,并且可以将用例直接导出为可用的python/java等编程语言的脚本。
我们以chrome浏览器介绍如何使用IDE工具
下载selenium IDE工具
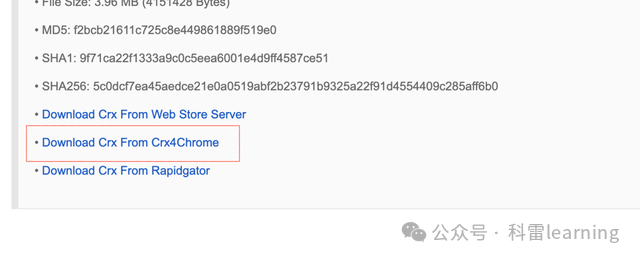
下载插件地址:国内下载地址:https://www.crx4chrome.com/crx/77585/
点击如下红框处的链接下载插件
chrome浏览器导入selenium IDE插件
打开chrome浏览器,按照下图找到‘管理扩展程序’,
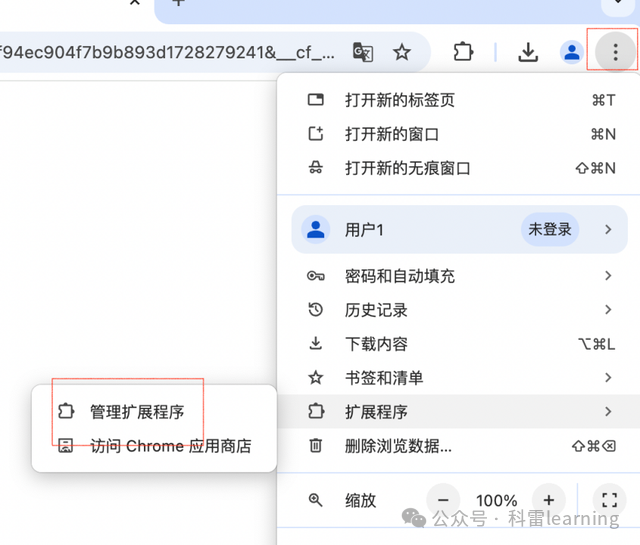
然后将下载的插件拖动到页面上,选择‘添加扩展程序’。
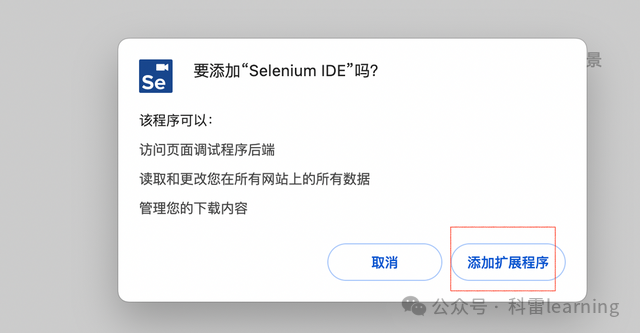
添加后如下
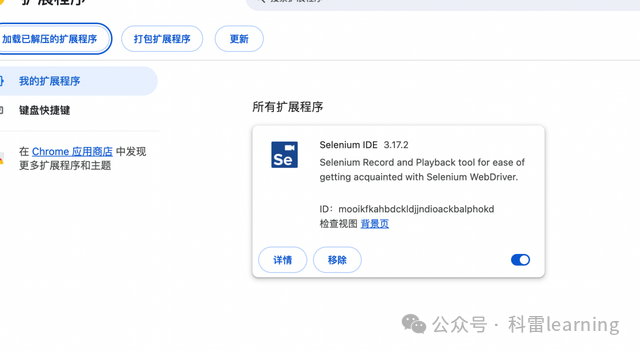
chrome浏览器打开selenium IDE插件
按照如下图双击打开插件
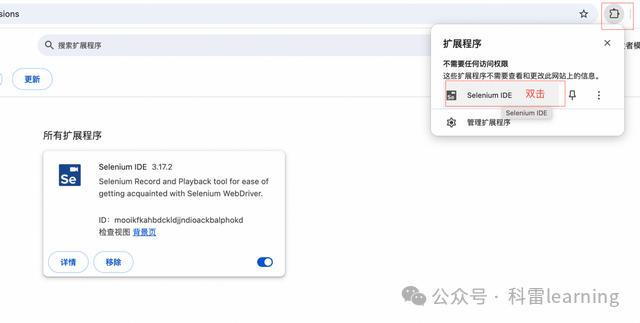
选择创建一个新的project

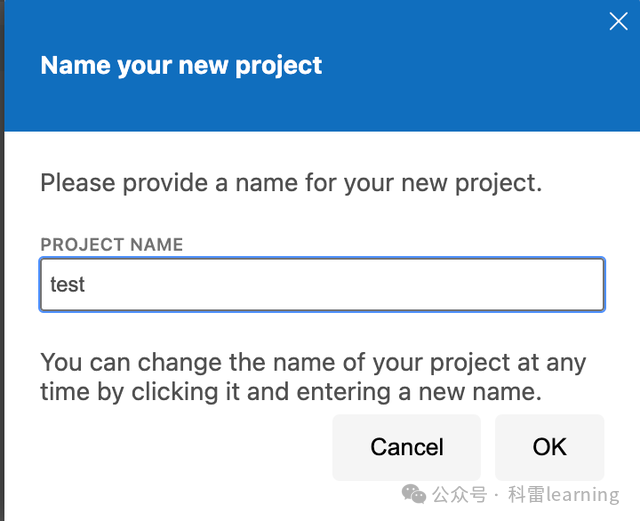
点击ok后,进入如下页面,功能区主要功能标识如下:
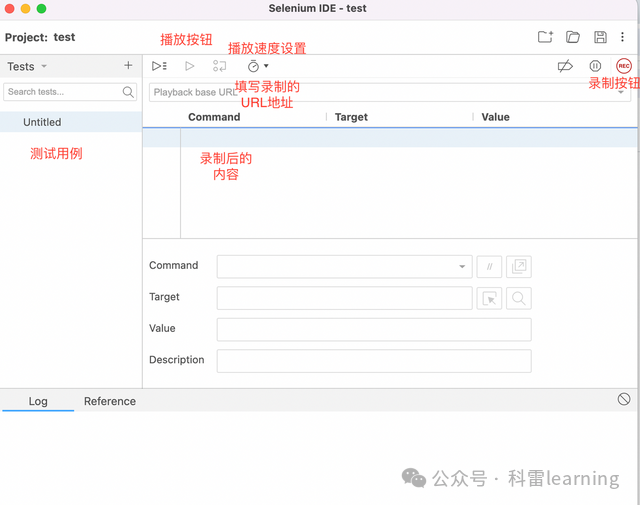
开始录制和回放
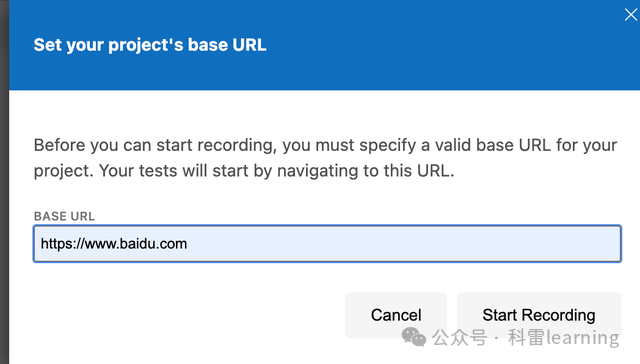
点击录制按钮,会自动打开chrome浏览器,填写比如百度地址
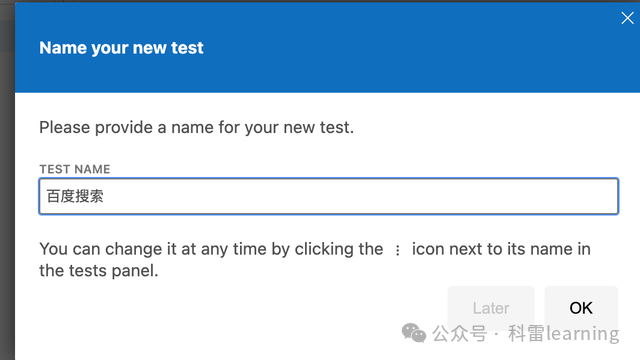
点击‘Start Recording’,开始录制,我们输入python点击百度一下进行搜索,然后点击第一个搜索到的内容,最后点击录制按钮结束录制,输入用例名称。
录制后如下,会自动填充整个操作过程,
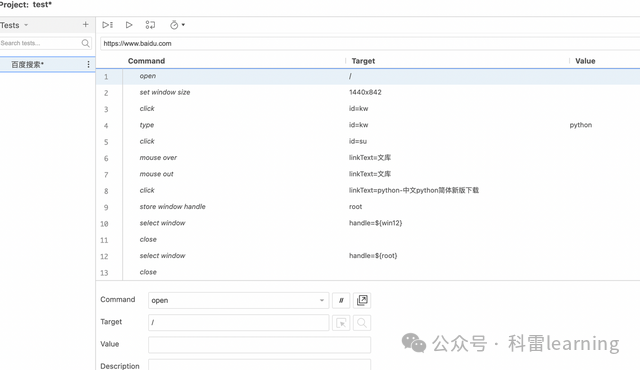
如果录制有些问题,可以右键某个动作进行删除,或者在该区域中进行修改。
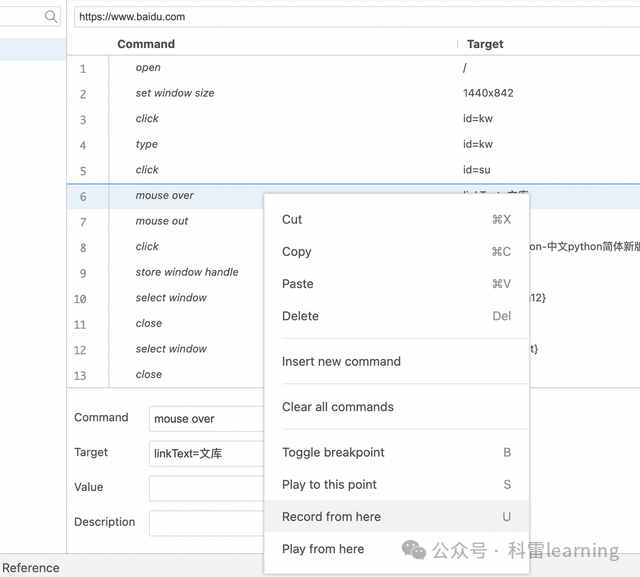
最后点击回放按钮,可以回放这个用例,检验录制是否正确(回放时可以适当调整播放速度)。
导出用例
按照如下图,选择用例,点击‘Export’可导出用例。
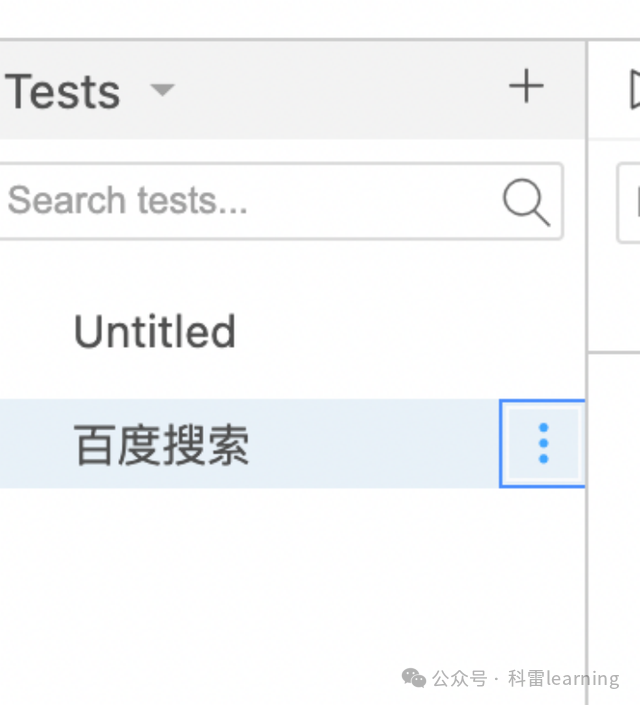

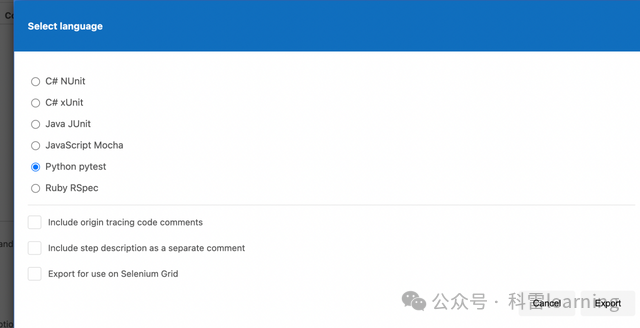
我们导出基于pytest框架的用例(大家根据实际情况导出其他编程语言的用例,比如java,ruby,C等)
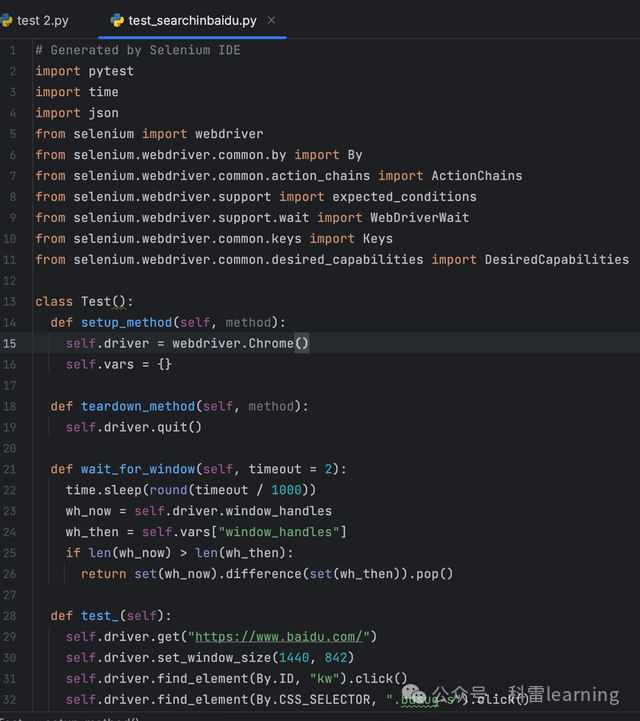
导出后使用pycharm打开用例,如下图,导出的pytest框架用例,格式很清晰,还有setup和teardown功能,大家可以自行修改和调试。
大家不妨在线下尝试下selenium IDE插件,感受下插件的魅力。
13 pytest+selenium进行网页UI自动化测试
pytest安装
使用pip命令安装: pip install pytest -i https://mirrors.aliyun.com/pypi/simple/
pytest框架实现selenium自动化用例
在pytest框架下我们创建1条测试用例,在百度查找内容后,校验下输入框中的内容是不是我们之前输入的内容,具体代码如下:
import pytest
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
def test_1():
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
driver.maximize_window()
driver.find_element(By.ID, 'kw').send_keys('python')
driver.find_element(By.ID, 'su').click()
sleep(1)
assert driver.find_element(By.ID, 'kw').get_attribute('value') == 'python'
# 等待几秒钟以便观察浏览器行为
sleep(5)
# 关闭浏览器
driver.quit()
用例执行的结果为通过。
我们将用例改造下,通过设置fixture函数来实现用例的setup和teardown动作,并在用例中实现参数化,增加多个搜索的文本。
@pytest.fixture()
def open_close_web():
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
driver.maximize_window()
yield driver
# 关闭浏览器
driver.quit()
@pytest.mark.parametrize('text',['python','pytest'])
def test_1(text,open_close_web):
open_close_web.find_element(By.ID, 'kw').send_keys(f'{text}')
open_close_web.find_element(By.ID, 'su').click()
sleep(1)
assert open_close_web.find_element(By.ID, 'kw').get_attribute('value') == f'{text}'
以上代码都实际执行ok。
总结:本章我们简要介绍了使用python库selenium在pytest框架下的UI自动化脚本和用例的编写调试过程,大家可以在线下多多实践,当然对于大型的项目,我们还要规划好整个测试用例和脚本目录结构,方便后续维护。
14 RobotFramework框架+selenium进行UI网页自动化测试
安装RF框架所需的robotframework-seleniumlibrary包
关于RF框架中的selenium包版本说明如下:有两个robotframework-seleniumLibrary和robotframework-selenium2Library
1)robotframework-seleniumLibrary版本说明
robotframework-seleniumLibrary包最新的版本6.5.0(发布时间2024年6月15日),支持Python 3.8到3.11,安装该包时会默认安装依赖的selenium库4.0的版本.
如果自己使用的pyhon版本低于3.8可以参考历史包找到适配的版本(官网地址https://pypi.org/project/robotframework-seleniumlibrary/#history)
每个版本都会有适配的python版本说明:
通过pip命令安装以下包
pip install robotframework-seleniumlibrary安装最新版本或者指定版本
pip install robotframework-seleniumlibrary==5.1.3
2)robotframework-selenium2Library版本说明
robotframework-selenium2Library包最新的版本3.0.0(发布时间2017年12月5日),已经停止更新了。而且从3.0版本开始,Selenium2Library更名为SeleniumLibrary,支持Python 2.7以及Python 3.3及更新版本。
通过pip命令安装包:
pip install robotframework-selenium2library安装最新版本或者指定版本
pip install robotframework-seleniumlibrary==1.8.0
PS: python版本 selenium版本 robotframework-seleniumlibrary版本三个要适配,否则会报错
3)本次使用的RF框架的各个包的适配版本
robotframework-ride 1.7.4
robotframework 3.2.1
robotframework-selenium2library 3.0.0
robotframework-seleniumlibrary 3.3.1
selenium 3.141.0
python 3.7.7
在RF中使用seleniumlibrary库编写用例
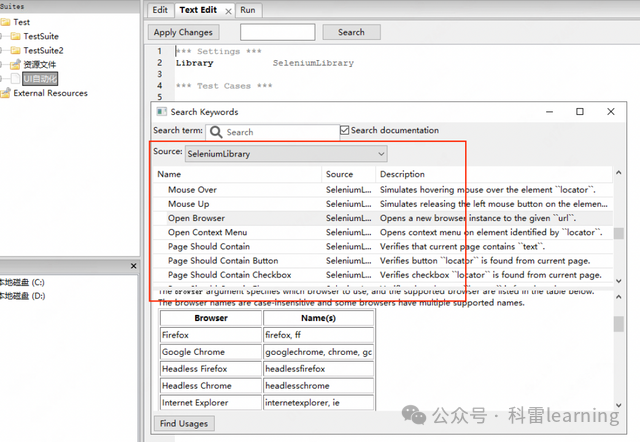
1)打开ride导入seleniumlibrary库
打开ride客户端,我们先创建测试套件,然后导入SeleniumLibrary库,按F5键查看一些关键字信息。
2)在SUITE中创建用例
在suite套件中创建一条用例,打开谷歌浏览器,输入文本后点击搜索,返回上一个页面,再次输入后搜索,最后在teardown中关闭浏览器。
以下元素定位的方式采用的是id,大家不妨试下name,class,xpath等方式。
*** Settings ***
Library SeleniumLibrary
*** Variables ***
${URL} https://www.baidu.com
${BROWSER} Chrome
*** Test Cases ***
打开百度输入文本后点击查询
Open Browser ${URL} ${BROWSER}
Input Text id=kw python
click button id=su
${text1} get_value id=kw
#校验输入的内容是否成功
should be equal ${text1} python
sleep 2
go_back
Input Text id=kw selenium
click button id=su
${text1} get_value id=kw
#校验输入的内容是否成功
should be equal ${text1} selenium
sleep 2
${cur_url} log_location
${source} get_source
log ${cur_url}
[Teardown] close_browser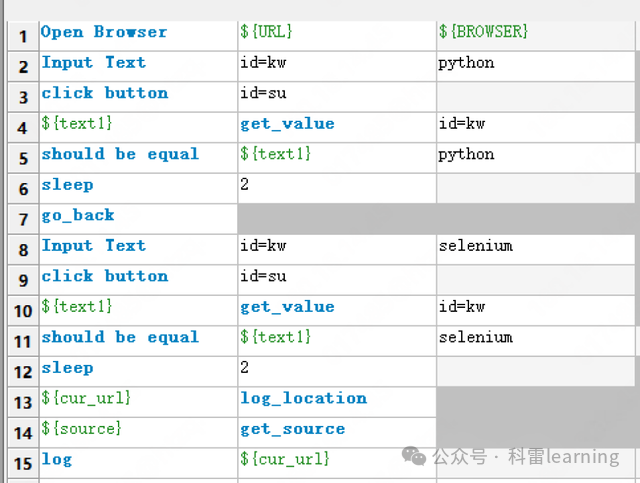
常用关键字介绍
1)浏览器操作相关的关键字
关键字位于文件
SeleniumLibrary/keywords/browsermanagement.py
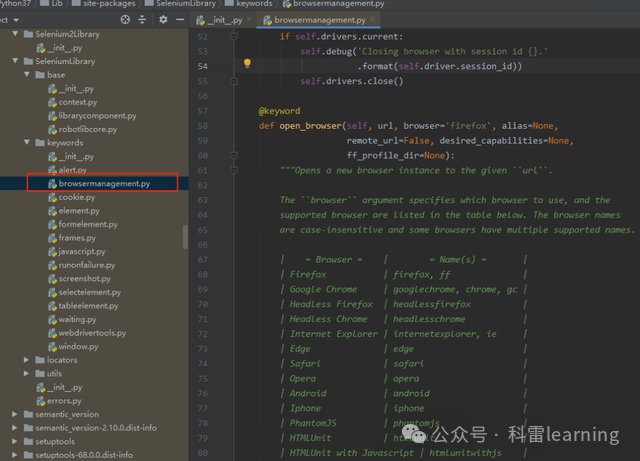
- open_browser:打开某个浏览器访问传入的URL,浏览器可以是firefox,chrome,edge,safari等
- close_all_browsers:关闭打开的所有浏览器
- close_browser:关闭当前使用的浏览器
- go_back:返回上一个页面
- go_to:跳转到其他url
- reload_page:刷新页面
- log_location: 返回当前页面的URL
- location_should_be:返回当前页面的URl 与传入的对比,不相等会报错。
2)表单相关的关键字
关键字位于文件
SeleniumLibrary/keywords/formelement.py
- submit_form:提交表单
- select_checkbox:选择某个复选框
- unselect_checkbox:取消选择某个复选框
- checkbox_should_be_selected:检查复选框是否被选中
- checkbox_should_not_be_selected:检查复选框没有被选中
- page_should_contain_checkbox:检查页面包含某个复选框
- page_should_not_contain_checkbox:检查页面不包含某个复选框
- page_should_contain_radio_button:检查页面包含某个单选框
- page_should_not_contain_radio_button:检查页面不包含某个单选框
- select_radio_button:选中某个单选框
- radio_button_should_be_set_to:检查某个单选框设置为某个名称
- radio_button_should_not_be_selected:检查某个单选框没有被选中
- choose_file:选择一个文件
- input_password:输入密码
- input_text:输入文本
- page_should_contain_button:检查页面包含某个按钮
- page_should_not_contain_button:检查页面不包含某个按钮
3)元素相关的关键字
关键字位于文件
SeleniumLibrary/keywords/element.py
- get_element_attribute:获取元素的属性,比如元素的id,name,value等
- get_value:获取元素的value值
- get_text:获取元素的text
- click_button:点击某个按钮
- click_image:点击某个图片
- click_link:点击某个链接
- click_element:点击某个元素,可以是按钮/图片等
- double_click_element:双击某个元素
- mouse_down:鼠标往下移动
- mouse_out:鼠标移出
- mouse_over:鼠标悬停
- mouse_up:鼠标往上移动
4)窗口相关的关键字
关键字位于文件
SeleniumLibrary/keywords/window.py
- maximize_browser_window:最大化窗口
- set_window_size:设置窗口的大小
- close_window:关闭浏览器窗口
共勉: 东汉·班固《汉书·枚乘传》:“泰山之管穿石,单极之绠断干。水非石之钻,索非木之锯,渐靡使之然也。”
-----指水滴不断地滴,可以滴穿石头;
-----比喻坚持不懈,集细微的力量也能成就难能的功劳。
----感谢读者的阅读和学习,谢谢大家。