1、背景
之前做了个大宽表,将近100个字段,但是后来发现很多字段在实际生产上都没有用到,并且随着数据量的增加,给集群的存储以及消费任务的解析带来了比较大的压力。所以决定对字段做删除处理。
当前的表是使用routine load任务从kafka消费数据,为了不影响线上的服务,所以我们最终的方案是保留字段,但是在routine load任务里只消费需要的字段。
但是为了搞清楚对于一个已经有大量数据的表删除字段的影响,单独起了个表做了个测试。
2、构建一个测试表
CREATE TABLE `ods_s_topic_obu_rt_inc_test` (
`report_time` bigint(20) NOT NULL COMMENT "设备数据上报时间时间戳",
# `device_code` varchar(255) NOT NULL COMMENT "设备编码",
) ENGINE=OLAP
PRIMARY KEY(`report_time`)
DISTRIBUTED BY HASH(`report_time`)
PROPERTIES (
"replication_num" = "3",
"in_memory" = "false",
"enable_persistent_index" = "true",
"replicated_storage" = "true",
"compression" = "LZ4"
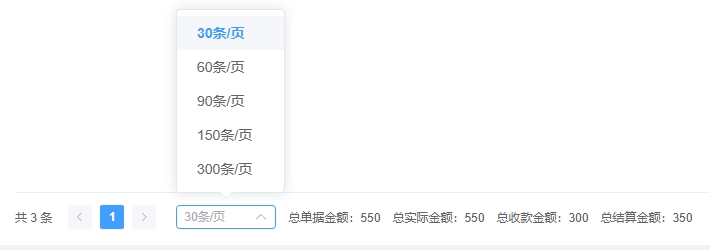
);3、当前表里的数据量

4、删除字段 device_code
4.1、停止routine load任务
pause routine load for ods_s_topic_obu_rt_inc_load_101114 \G 感觉还是先停止为好,防止出现幺蛾子。
4.2、删除字段
ALTER TABLE ods_s_topic_obu_rt_inc_test DROP COLUMN device_code ;5、结果演示

效果非常明显,数据量是2kw左右,未观察到其他的指标有明显的变化
6、升华
个人理解:因为是列存,所以当我把字段删除之后,这个字段对应的数据也会被sr标记然后删除。个人理解是物理删除。