1.项目目标
1.1 需求概述
现在我们想统计历年来的最高温度,要从给定的数据中,计算每一年的最高温度是多少。
1.2 业务分析
要统计给定格式数据中每一年的最高温度,可以使用MapReduce编写一个Hadoop来处理该数据。
Mapper类将提取每一行数据中的年份和温度信息,并输出为键值对,其中键是年份,值是温度。
Reducer类用于找到每年记录中的最高温度。
驱动程序将设置作业的输入格式、输出格式、Mapper和Reducer类,并启动作业。
2. 新建项目
如果没有进行配置项目,则需要先进行配置,可以参考下文的前半部分:
大数据处理从零开始————8.基于Java构建WordCount项目-CSDN博客
如果配置好就可以直接进行下一步。新建项目后,确定好项目的名称,组ID,工作ID的信息。
打开pom.xml文件,添加项目配置,添加如下配置。
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<!--<scope>test</scope>-->
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.11</version>
</dependency>
</dependencies>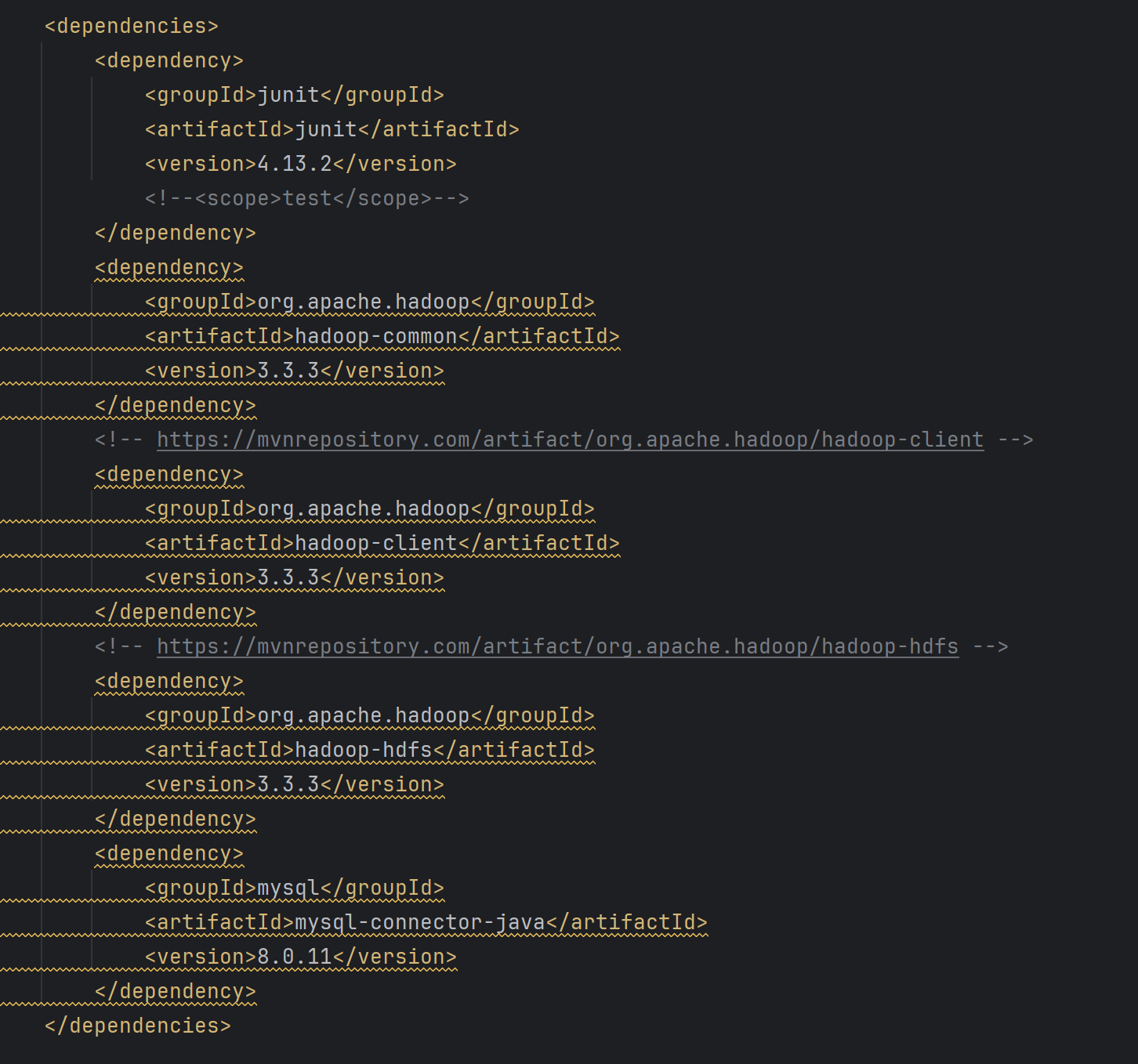
如果pom.xml全部标红可以看上一节解决方法,完全相同。
3.完善项目代码
3.1 创建Mapper类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 0029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999
* 从给定的数据中,计算每一年的最高温度是多少
* 温度数据的说明:
* 1. 每行数据的 [15,18] 位是年份
* 2. 每行的第87个字符,代表温度的符号(正负)
* 3. 每行的第 [88,91] 位代表温度的值,如果温度是9999代表无效温度
* 4. 每行的第92位是一个校验位,如果是0,1,4,5,9代表有效温度
*/
public class TempratureMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text k2;
private IntWritable v2;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
k2 = new Text();
v2 = new IntWritable();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 需要处理的逻辑:
// 1.从字符串中解析出来每一个需要的数据:年份、温度、校验
// 2.将年份作为K2,将温度作为V2,写出到环形缓冲区中
String line = value.toString();
// 1.获取年份
String year = line.substring(15, 19);
// 2.获取温度
int temprature = Integer.parseInt(line.substring(87, 92));
// 3.获取校验位
String check = line.substring(92, 93);
// 4.验证温度是否是一个合法的温度
if (Math.abs(temprature) == 9999 || check.matches("[^01459]")) {
// 表示不合法的温度
return;
}
// 5.所有的校验都没问题了,将年份和温度写出
k2.set(year);
v2.set(temprature);
context.write(k2, v2);
}
}
3.2 实现Reducer类
package com.jyd;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class TempratureReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable v3;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
v3 = new IntWritable();
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int maxTemperature = Integer.MIN_VALUE; // 设定一个初始的最低温度
// 遍历所有的温度值,找到最大值
for (IntWritable value : values) {
maxTemperature = Math.max(maxTemperature, value.get());
}
// 设置最后的结果
v3.set(maxTemperature);
// 将年份和其对应的最大温度输出
context.write(key, v3);
}
}
3.3 构建驱动器Driver类
package com.jyd;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* K1: 行偏移量
* V1: 行记录
*
* K2: 年份,Text、IntWritable
* V2: 温度,IntWritable
*
* K3: 年份,Text、IntWritable
* V3: 温度,IntWritable
*/
public class TempratureDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
System.setProperty("HADOOP_USER_NAME", "root");
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(TempratureDriver.class);
job.setMapperClass(TempratureMapper.class);
job.setReducerClass(TempratureReducer.class);
job.setCombinerClass(TempratureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4.运行程序
首先给程序打包。

上传到hadoop。

启动hadoop,并将程序上传到hadoop中。
./myhadoop.sh start 启动hadoop
cd /user/local/data #转到文件夹下
vim temp #创立测试文件
hdfs dfs -put temp /sy/temp #将temp上传到/sy/temp中注意:我这里有/sy,如果没有的话,应该先用下面命令创建/sy
hdfs dfs mkdir /sy #在hadoop下创建一个cs文件。
temp测试文件内容如下:
0029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00781+99999102001ADDGF108991999999999999999999999
0029029070999991901010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9+01231+99999102001ADDGF108991999999999999999999
0029029070999991910010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9+01501+99999102001ADDGF108991999999999999999999
0029029070999991910010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9-00231+99999102001ADDGF108991999999999999999999
0029029070999991920010106004+64333+023450FM-12+000599999V0202701N015919999999N0000001N9+02451+99999102001ADDGF108991999999999999999999

运行jar包:hadoop jar jyd.jar com.jyd.TempratureDriver /sy/temp /tempoutput

查看结果:hdfs dfs -cat /tempoutput/part-r-00000












![LeetCode[简单] 70. 爬楼梯](https://i-blog.csdnimg.cn/direct/e0cf9b907be049e3a6f74dfd97d0e77d.png)



