作者:UC 浏览器后端工程师,梁若羽
传统 ELK 方案
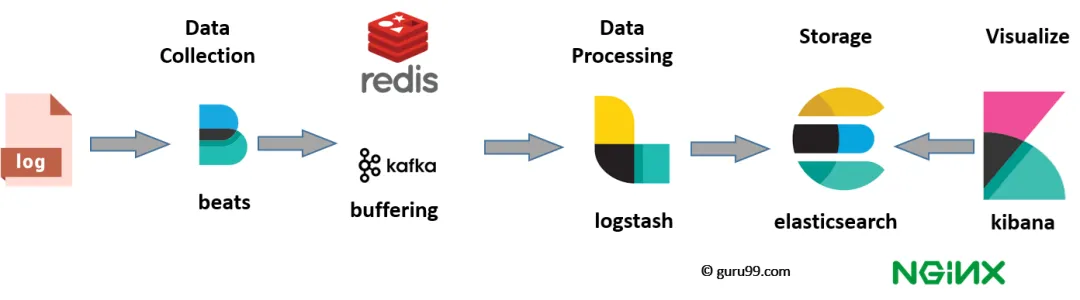
众所周知,ELK 中的 E 指的是 ElasticSearch,L 指的是 Logstash,K 指的是 Kibana。Logstash 是功能强大的数据处理管道,提供了复杂的数据转换、过滤和丰富的数据输入输出支持。Filebeat 是师出同门的轻量级日志文件收集器,在处理大量日志文件、需要低资源消耗时,它们通常被一起使用。其经典使用场景如下图,Filebeat 将日志文件从各个服务器发送到 Kafka 解耦,然后 Logstash 消费日志数据,并且对数据进行处理,最终传输到 ElasticSearch,由 Kibana 负责可视化。这种架构兼顾了效率和功能。
iLogtail 的优势
请注意,iLogtail 也是轻量级、高性能的数据采集工具,也有不俗的处理能力,重要的是,压测显示,iLogtail 性能比 Filebeat 领先太多。究其原理,Polling + inotify 机制可能是 iLogtail 性能如此优秀的最重要原因。这方面,社区已经有详尽的文档,这里就不深入了。
让我们关注性能测试结果,实际的业务场景,比较贴近下面表格第四行“容器文件采集多配置”一项,可以看到,同流量输入下,随着采集配置增加,filebeat CPU 增加量是 iLogtail CPU 增加量的两倍。其它场景,iLogtail 在 CPU 方面的优势也是遥遥领先,有五倍的、有十倍的,具体数值可以参考下面的链接。

《容器场景 iLogtail 与 Filebeat 性能对比测试》:
https://ilogtail.gitbook.io/ilogtail-docs/benchmark/performance-compare-with-filebeat#dui-bi-zong-jie
《Logtail 技术分享(一) : Polling + Inotify 组合下的日志保序采集方案》:
https://zhuanlan.zhihu.com/p/29303600
iLogtail 替换 Logstash 可行性分析(What to do)
那么,iLogtail 能够在生产环境中替换 Filebeat 和 Logstash,直接采集日志到 ElasticSearch 呢?
如果是过去,答案是不能。主要有四个方面的原因。
- 插件性能。
- 配置管理。
- 容灾。
- 自身状态监控。
现在逐一分析一下。
插件性能
虽然 iLogtail 核心部分性能突出,但是它原先的 elasticsearch flusher 插件存在短板。
配置管理
- 我们生产环境有很多采集实例,缺少一个前端页面,供管理员白屏化维护采集配置。因为 Config Server 已经提供了 API 接口,所以这也是最容易实现的。
- iLogtail Agent 缺少生命周期管理,当 Agent 进程退出后,该 Agent 对应的心跳信息长期保留在 Config Server 数据库中,而且没有存活状态,即使是想清理也不知道应该清理哪些记录。
- 我们上千个应用实例是分组部署的,每个组的采集配置可能不一样,所以 Config Server 也要支持按照标签,对各个 Agent 进行分组管理。
容灾
生产环境所有节点都要求多实例部署,Config Server 也一样,而现在的 leveldb 存储方案使得它是有状态的,需要替换为 MySQL 等具有成熟容灾方案的关系数据库。
自身状态监控
在 Agent 运行过程中,需要以合适的方式上报 CPU 使用率、内存占用等信息给 Config Server,方便管理员掌握其负载状况。
目标:iLogtail 替换 Logstash(How to do)
除去 Config Server 前端页面,针对以上四个方面留存的五大问题,我们在过去一段时间做了全面优化提升,最终实现了目标。下面,参考 OKR 工作法,介绍这五大问题的解决方案。当然,留意到现在社区开始讨论 Config Server 的通信协议修改,我们的方案是在前一段时间的基础上实现的,可能与最终方案有所不同。
KR1:解决 elasticsearch flusher 性能瓶颈
方案分为三部分,分别如下:
- 使用 esapi 的 BulkRequest 接口批量向后端发送日志数据。批量之后,一个请求可以发送几百上千条日志,请求次数直接降低两三个数量级。
- Agent 在 flush 阶段之前,有聚合的过程,会自动生成一个随机的 pack id,以它作为 routing 参数,把同一批次的日志数据路由到同一个分片上,以免 ElasticSearch 按照自动生成的文档 ID 作为分片字段,减少不必要的计算和 IO 操作,降低负载,提高吞吐量。
- 启用 go routine 池,并发向后端发送日志数据。
KR2:解决 Agent 生命周期管理与存活状态判断
方案参考 HAProxy 的实现,尽量避免网络抖动带来的影响。
- Config Server 只有收到连续指定次数的心跳,才会认为该 Agent 在线。
- 只有连续指定次数的周期内都没有收到心跳,才会认为该 Agent 离线。
- Agent 离线达到一定时长后,即可自动清理该 Agent 的残余心跳信息。
KR3:解决 Agent 按标签分组
这个方案需要修改一下通信协议。原协议的相关部分如下:
message AgentGroupTag {
string name = 1;
string value = 2;
}
message AgentGroup {
string group_name = 1;
...
repeated AgentGroupTag tags = 3;
}
message Agent {
string agent_id = 1;
...
repeated string tags = 4;
...
}
可以看到,iLogtail 的 Agent Group 和 Agent 均已经带有标签属性(tags),但两者的数据结构并不一致,Agent Group 是 Name-Value 数组,Agent 是字符串数组。
方案把它们都统一为 Name-Value 数组,并在 Agent Group 加上运算符,表达两种语义:“与”、“或”。这样,Agent Group 就拥有一个由标签和运算符组成的“表达式”,如果该表达式能够和 Agent 持有的标签匹配上,那么即可认为该 Agent 属于该分组。例如:
- 如果某个 Agent Group 的标签定义为 cluster: A 和 cluster: B,运算符定义为“或”,那么,所有持有 cluster: A 标签或者 cluster: B 标签其中之一的 Agent 都属于该分组。
- 如果某个 Agent Group 的标签定义为 cluster: A 和 group: B,运算符定义为“与”,那么,所有同时持有 cluster: A 标签和 group: B 标签的 Agent 才属于该分组。
KR4:解决 Config Server 容灾
Config Server 已经提供一套 Database 存储接口,只要实现了该接口的全部方法,即完成了持久化,leveldb 存储方案给了一个很好的示范。
type Database interface {
Connect() error
GetMode() string // store mode
Close() error
Get(table string, entityKey string) (interface{}, error)
Add(table string, entityKey string, entity interface{}) error
Update(table string, entityKey string, entity interface{}) error
Has(table string, entityKey string) (bool, error)
Delete(table string, entityKey string) error
GetAll(table string) ([ ]interface{}, error)
GetWithField(table string, pairs ...interface{}) ([ ]interface{}, error)
Count(table string) (int, error)
WriteBatch(batch *Batch) error
}
于是,我们依次实现该接口的所有方法,每个方法,基本都是通过反射获得表的实体和主键,再调用 gorm 的 Create、Save、Delete、Count、Find 等方法,即完成了 gorm 的 CRUD 操作,也就是实现了持久化到 MySQL、Postgre、Sqlite、SQLServer,也实现了从数据库读取数据。
这里有一个细节,Database 接口定义了 WriteBatch 方法,本意是批量处理心跳请求,提高数据库写入的能力。如果是 MySQL,与之相应的处理办法是数据库事务。但是,在实践过程中,DBA 发现在事务中更新一批心跳数据,事务可能会变得过大,非常容易导致数据库死锁,放弃使用 WriteBatch 就恢复正常。由于心跳间隔默认 10 秒,即使一个心跳请求进行一次写入操作,在 Agent 数量上千个的规模下,那么,TPS 每秒也就上百,数据库压力并不算特别大。
KR5:iLogtail 自身状态监控
该方案可能最简单直接,在心跳请求的 extras 字段中上报 Agent 进程的 CPU 使用率和内存占用字节数。Config Server 最终会把这些信息保存到 MySQL 数据库,另外再安排一个定时任务做快照,多个快照按照时间序列形成趋势,再进行可视化分析,协助定位解决问题。
日志查询服务
上面解决了怎样把大量日志存储到 ElasticSearch 中,用户需求解决了一半。剩下一半,就是对用户提供查询服务,还需要一个界面。
理论上,Kibana 可以提供数据展示功能,但它主要面向管理员,而且是通用设计,不是面向日志服务,对于一些企业核心需求,例如:内部系统集成、多用户角色权限控制、日志库配置、多 ElasticSearch 集群管理,均无能为力,只适合在小团队、单集群使用。因此,要实现公司级别的统一界面,还需要自研一个最简版日志查询平台,才能与日志采集形成一个大的闭环,提供一个完整的解决方案。不过这一部分,基本上和 iLogtail 关系不大,暂且略过。
日志采集实践总结
逐一解决 iLogtail 替换 Logstash 的五大问题后,我们可以从容地说,iLogtail 在配置管理、采集、反馈等方面初步形成了一个小的闭环,无需过多依赖于其它工具,在技术上,是 Filebeat、Logstash 的最佳替代者。
我们使用的 iLogtail 是基于开源版 1.8.0 开发的,从 2024 年 2 月底正式上线至今,已稳定运行超过三个月,高峰期每小时采集日志超过百亿条,数据量是 TB 级别,服务业务应用 pod 上千个,ElasticSearch 存储节点数量上百个。
目前这些代码变更,在部分实现细节上,涉及到通信协议的修改,需要继续与社区负责人沟通,希望不久之后部分变更能够合并到 iLogtail 的主干分支。
以上五大问题,除了第一个 elasticsearch flusher,其它四个都与 Config Server 息息相关。因此,我曾经在社区钉钉群里说过:“Config Server 是皇冠上的明珠”,意思是它具有很高的用户价值,希望社区同学在这方面共同努力。
iLogtail 两周年系列宣传文章:
iLogtail 开源两周年:感恩遇见,畅想未来
iLogtail 进化论:重塑可观测采集的技术边界