当我们通过webdriver中的find_element函数定位到元素后,其实返回的是WebElement对象,而该对象有很多重要的方法,比如输入文本,点击按钮,获取属性,截屏等
WebElement类的方法介绍
| 文本输入与清除 | send_keys() | 在元素上模拟按键输入,通常用于向输入框中填充文本。 |
| clear() | 清除元素的输入内容,如清空一个文本输入框。 | |
| 点击操作 | click() | 单击元素,可以是按钮、链接等可点击的元素。 |
| submit() | 提交表单,也可以使用click()方法,但submit()方法专门用于表单的提交。 | |
| 元素属性与状态获取 | get_attribute(element_name) | 获取元素的属性值,如id、name、type等。 |
| is_selected() | 判断元素是否被选中,常用于单选框、复选框等。 | |
| is_displayed() | 判断元素是否可见,返回一个布尔值。 | |
| is_enabled() | 判断元素是否可启用,例如,某些按钮在特定条件下可能不可点击。 | |
| 获取元素尺寸与位置 | size | 返回元素的尺寸,通常包含宽度和高度。 |
| location | 返回元素在页面上的位置,通常是元素的左上角坐标。 | |
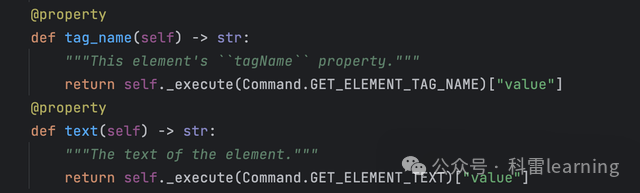
| 获取元素信息 | text | 获取元素的文本内容,如获取一个段落或链接的文本。 |
| tag_name | 获取元素的tag信息。 | |
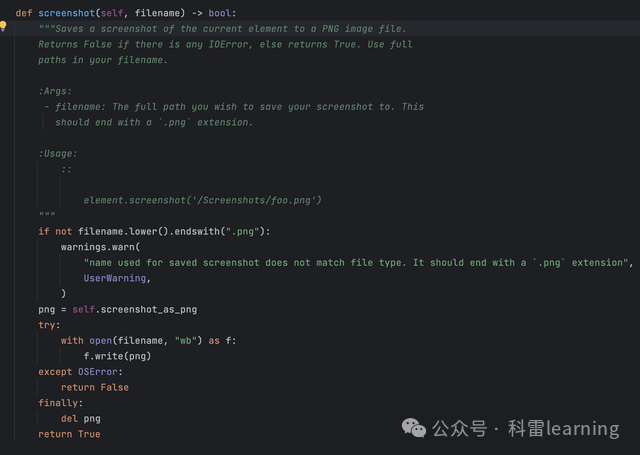
| 截屏 | screenshot(filename) | 将当前元素截屏保存为png图片 |
| screenshot_as_base64 | 将当前元素截屏保存为base64编码的字符串 | |
| screenshot_as_png | 将当前元素截屏保存为base64字符串,然后解码为2进制字节码 |
以上函数位于如下webelement.WebElement类中:

示例:打开百度输入文本后点击搜索(输入框操作)
我们以获取元素的id举例,先上代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
# 创建Safari浏览器的WebDriver实例
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
#最大化网页
driver.maximize_window()
#查找id=kw的元素位置,对应于搜索输入框,找到后我们输入字符python
driver.find_element(By.ID,'kw').send_keys('python')
##查找id=su的元素位置,对应于‘百度一下’的按钮,找到后我们点击按钮
driver.find_element(By.ID,'su').click()
# 等待几秒
sleep(5)
# 关闭浏览器
driver.quit()代码执行后,网页自动打开并搜索如下:
示例:打开百度输入用户名和密码进行登录(表单操作)
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Safari()
# 打开一个网页
driver.get("https://www.baidu.com")
driver.maximize_window()
sleep(1)
#点击登录
driver.find_element(By.ID,'s-top-loginbtn').click()
sleep(1)
#输入用户名
driver.find_element(By.ID,'TANGRAM__PSP_11__userName').send_keys('*****')
sleep(1)
#输入密码
driver.find_element(By.ID,'TANGRAM__PSP_11__password').send_keys('*****')
sleep(1)
#点击同意
driver.find_element(By.ID,'TANGRAM__PSP_11__isAgree').click()
sleep(1)
#点击提交
driver.find_element(By.ID,'TANGRAM__PSP_11__submit').submit()程序执行后会自动输入用户和密码,点击登录
示例:获取元素后将元素截屏
我们获取元素后,使用函数screenshot将元素截屏,参数filename传入完整的png文件名路径或者文件名(放在当前路径)
测试代码:打开头条网站,定位到左上角的‘下载头条app’然后截屏保存。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
#打开传入的URL网页地址
driver.get("https://www.toutiao.com/")
sleep(6)
element = driver.find_element(By.XPATH,'//*[@id="root"]/div/div[3]/div[1]/div')
element.screenshot('1.png')
element.screenshot('/Users/aaa/Donwloads/1.png')执行后打开截图如下:

示例:获取元素的text/ta gtag_name信息
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
#打开传入的URL网页地址
driver.get("https://www.toutiao.com/")定位到左上角的‘下载头条app’元素,并打印元素的信息
element = driver.find_element(By.XPATH,'//*[@id="root"]/div/div[3]/div[1]/div')
#打印该元素的一些信息
print(element.tag_name)
print(element.text)
执行结果:
DIV
下载头条APP扫码下载今日头条示例:获取元素的属性值
通过get_attribute函数,传入参数比如id,class,xpath等信息,返回对应的值。

from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Safari()
#打开传入的URL网页地址
driver.get("https://www.toutiao.com/")
#定位到左上角的‘下载头条app’然后截屏保存。
element = driver.find_element(By.XPATH,'//*[@id="root"]/div/div[3]/div[1]/div')
#打印该元素的属性值
print(element.get_attribute('class'))执行结果:
download-app-wrapper
共勉: 东汉·班固《汉书·枚乘传》:“泰山之管穿石,单极之绠断干。水非石之钻,索非木之锯,渐靡使之然也。”
-----指水滴不断地滴,可以滴穿石头;
-----比喻坚持不懈,集细微的力量也能成就难能的功劳。
----感谢读者的阅读和学习,谢谢大家。