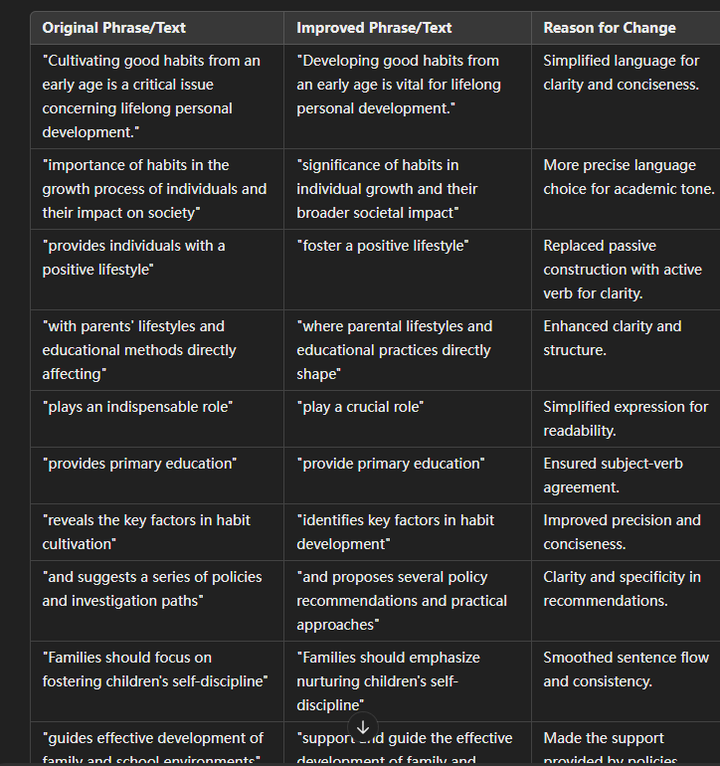
Modnet 人像抠图(论文复现)
本文所涉及所有资源均在传知代码平台可获取
文章目录
- Modnet 人像抠图(论文复现)
- 论文概述
- 论文方法
- 复现
- WebUI
- 部署
论文概述
人像抠图(Portrait matting)旨在预测一个精确的 alpha 抠图,可以用于提取给定图像或视频中的人物。
MODNet 是一个轻量级的实时无 trimap 人像抠图模型, 与以往的方法相比,MODNet在单个阶段应用显式约束解决抠图子目标,并增加了两种新技术提高效率和鲁棒性。
MODNet 具有更快的运行速度,更准确的结果以及更好的泛化能力。简单来说,MODNet 是一个非常强的人像抠图模型。下面两幅图展示了它的抠图效果

论文方法

ModNet 基于三个基础模块构建:语义预测(semantic estimation),细节预测(detail prediction),语义-细节混合(semantic-detail fusion)。分别对应图中的左下(S)、上(D)、右下(F)三个模块。
语义预测主要作用于预测人像的整体轮廓,但是仅仅是一个粗略的前景 mask,用于低分辨率监督信号。细节预测用于区分前景与背景的过度区域,判断该区域内的点属于前景还是背景,可以预测边缘细节,用于高分辨率监测信号。两个相结合便可以实现整体的人像分离。
语义预测模块(S)中使用 channel-wise attention 的 SE-Block。监督信号为使用下采样及高斯模糊后的GT,损失函数采用L2-Loss。
细节预测模块(D)的输入由三部分组成,原始图像,S 的中间特征, S 的输出(语义分割图)。D 整体上是一个 Encoder-Decoder 结构,D的监督信号为

复现
官方并没有给出训练代码以及训练数据集,因此本文主要介绍推理的步骤。
项目的结构如下图

首先导入库并加载模型,工作目录为代码所在文件夹。
import gradio as gr
import os, sys
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
from src.models.modnet import MODNet
import numpy as np
from PIL import Image
modnet = MODNet(backbone_pretrained=False)
modnet = nn.DataParallel(modnet)
ckpt_path = "./pretrained/modnet_photographic_portrait_matting.ckpt"
if torch.cuda.is_available():
modnet = modnet.cuda()
weights = torch.load(ckpt_path)
else:
weights = torch.load(ckpt_path, map_location=torch.device('cpu'))
modnet.load_state_dict(weights)
modnet.eval()
ref_size = 512
之后加载图片并处理数据,此处加载名称为1的图片

image = '1.jpg'
im = Image.open(image)
im = np.asarray(im)
if len(im.shape) == 2:
im = im[:, :, None]
if im.shape[2] == 1:
im = np.repeat(im, 3, axis=2)
elif im.shape[2] == 4:
im = im[:, :, 0:3]
im_transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]
)
im = Image.fromarray(im)
im = im_transform(im)
im = im[None, :, :, :]
im_b, im_c, im_h, im_w = im.shape
if max(im_h, im_w) < ref_size or min(im_h, im_w) > ref_size:
if im_w >= im_h:
im_rh = ref_size
im_rw = int(im_w / im_h * ref_size)
elif im_w < im_h:
im_rw = ref_size
im_rh = int(im_h / im_w * ref_size)
else:
im_rh = im_h
im_rw = im_w
im_rw = im_rw - im_rw % 32
im_rh = im_rh - im_rh % 32
im = F.interpolate(im, size=(im_rh, im_rw), mode='area')
得到可以处理的数据
im后,投入模型进行推理。将得到的结果保存为名为temp.png的图片
_, _, matte = modnet(im.cuda() if torch.cuda.is_available() else im, True)
matte = F.interpolate(matte, size=(im_h, im_w), mode='area')
matte = matte[0][0].data.cpu().numpy()
matte_temp = './temp.png'
运行之后得到结果,可以看见模型很好的得到了人像

WebUI
在原项目的基础上,构建了一个 WebUI 方便大家进行操作,界面如下所示

拖拽你想抠图的人像到左侧的上传框中,点击提交,等待片刻即可在右侧得到对应的结果。此处使用 flickr 的图片进行演示

模型推导的 mask 会暂时保存在 temp 文件夹中,例如上面的图像得到的就是下图:

部署
运行 pip install -r requirements.txt 安装所需依赖,并确保你的环境中安装有 PyTorch。在文件夹中运行 python webui.py 即可启动网站,在浏览器中访问即可进入网页
文章代码资源点击附件获取