本文将以部门场景和技术领域场景为例,为您介绍实时计算Flink版的大数据是实时化场景。
背景信息
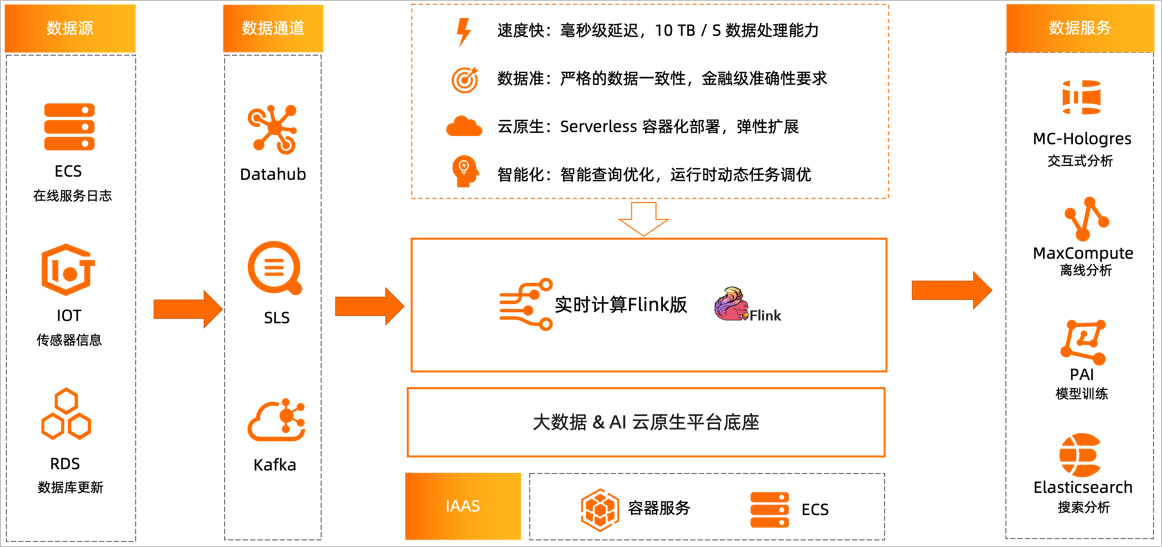
作为流式计算引擎,Flink可以广泛应用于实时数据处理领域,例如ECS在线服务日志,IoT场景下传感器数据等。同时Flink还能订阅云上数据库RDS、PolarDB等关系型数据库中Binlog的更新,并利用DataHub、SLS、Kafka等产品将实时数据收集到实时计算产品中进行分析和处理。最终,分析结果可写入不同的数据服务中,例如MaxCompute、MaxCompute-Hologres交互式分析、人工智能平台 PAI、Elasticsearch等,以提高数据利用率,满足业务需求。
部门场景
从企业部门职能的角度,可以将实时计算Flink版划分为以下场景:

-
业务部门:实时风控、实时推荐、搜索引擎的实时索引构建等。
-
数据部门:实时数仓、实时报表、实时大屏等。
-
运维部门:实时监控、实时异常检测和预警、全链路Debug等。
技术领域
从技术领域的角度,实时计算Flink版主要用于以下场景:
实时ETL和数据流
实时ETL和数据流的目的是实时地把数据从A点投递到B点。在投递的过程中可能添加数据清洗和集成的工作,例如实时构建搜索系统的索引、实时数仓中的ETL过程等。
实时数据分析
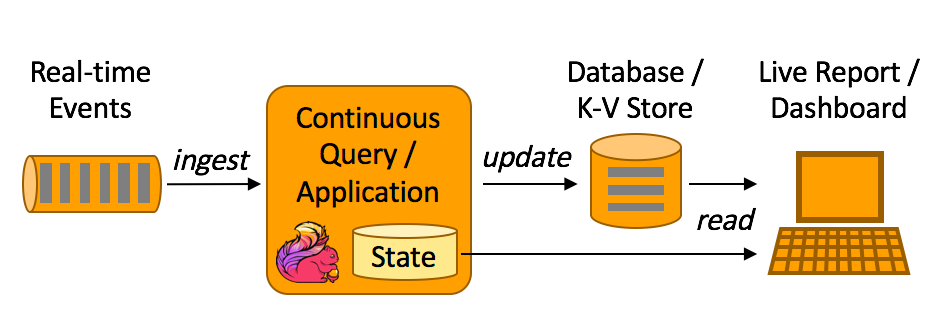
数据分析指的是根据业务目标,从原始数据中抽取对应信息并整合的过程。例如,查看每天销量前10的商品、仓库平均周转时间、文档平均单击率、推送打开率等。实时数据分析则是上述过程的实时化,通常在终端体现为实时报表或实时大屏。
事件驱动应用
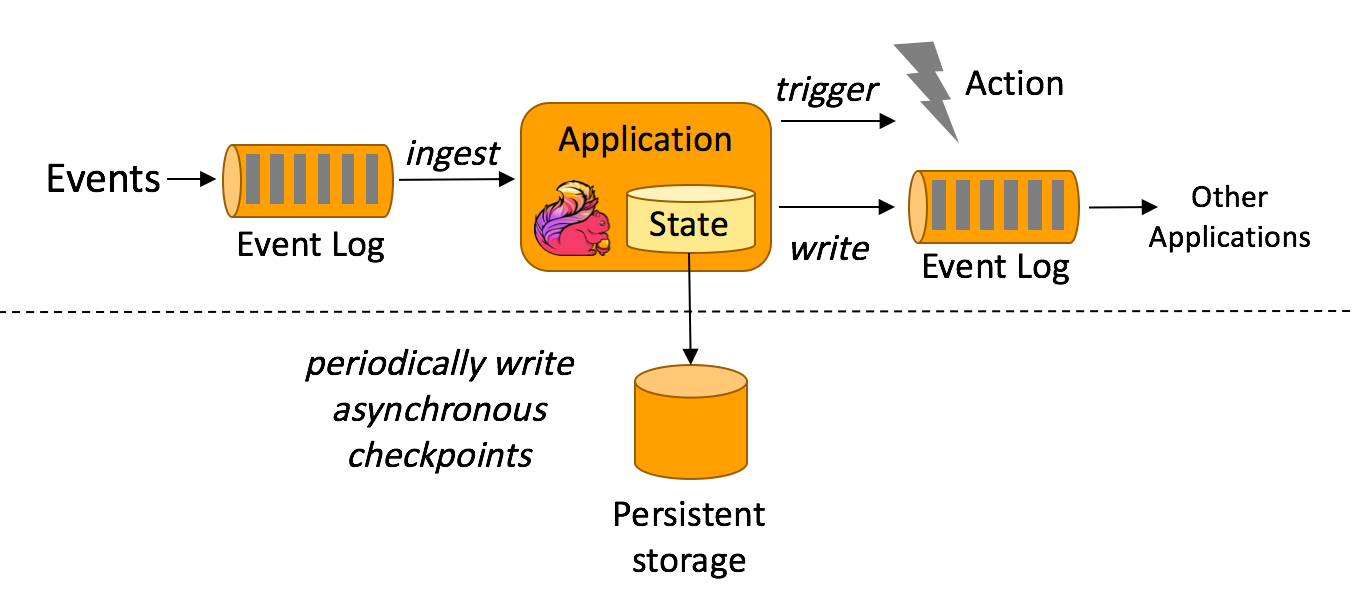
事件驱动应用是对一系列订阅事件进行处理或作出响应的系统。事件驱动应用通常需要依赖内部状态,例如欺诈检测、风控系统、运维异常检测系统等。当用户行为触发某些风险控制点时,系统会捕获这个事件,并根据用户当前和之前的行为进行分析,决定是否对用户进行风险控制。
风控监测系统
实时计算Flink版可以处理复杂的流处理和批处理任务,也提供了强大的API,执行复杂的数学计算并执行复杂事件处理规则,帮助企业对实时数据进行实时分析,提高企业的风控能力。例如检测APP中的点击行为、识别IoT数据流不规则变化等。
阿里云实时计算Flink全托管产品的功能点和价值,以及和开源Flink的对比优势。
| 类型 | 功能 | 描述 | 价值 |
| 性能与成本 | 兼容性 | 全面兼容开源Flink,包括各层API、参数配置及SQL语法等。 | 更好的引擎性能和更细粒度资源配置使得整体TCO优于开源,且灵活的付费模式以及智能扩缩容,进一步提高了资源使用的精细程度。 |
| 核心性能提升 |
| ||
| 资源利用率提升 | 您可以根据业务负载进行弹性扩缩容,详情请参见动态扩缩容与参数动态更新。 | ||
| 您可以配置智能调优,无人值守自动监控并调整作业资源分配,并可以在指定时间段应用对应的资源计划,帮助您平稳顺利地度过业务洪峰,同时最大程度的节省成本,详情请参见配置自动调优。 | |||
| 您可以进行细粒度资源管理,支持SQL算子级别的精细化资源(CPU和Memory)配置,大规模作业资源利用率提升100%,详情请参见配置作业资源。 | |||
| 付费类型 | 您可以根据自身业务特点,选择包年包月或者按量付费,详情请参见计费项。 | ||
| 特色能力 | 数据实时入湖入仓 | 支持整库实时同步、分库分表实时同步和表结构变更实时同步,详情请参见数据同步模板。 | 可以更加高效便捷地对包含分库分表等架构的业务数据库、消息中间件中的数据进行实时的入湖入仓。 |
| 实时风控场景能力 | 企业级复杂事件处理(CEP)支持作业无需重启动态可配置规则,实现在线实时风控等场景的不间断生产级能力,详情请参见复杂事件处理(CEP)语句。 | 应用于实时营销、实时风控、安全态势感知等领域,提升开发效率和大规模数据处理能力,同时保证业务连续性。 | |
| 上下游数据连接(Connector) |
| 您无需自己开发对接各种上下游生态,并操心稳定性和性能。 | |
| 开发效率 | 作业开发 | 多语言支持:一站式开发管理平台,包括SQL、Java、Scala和Python语言。 | 您无需自己搭建或者对接开源。Flink SQL简单易懂,整体开发环境上手便捷。 |
| 多版本支持:支持主流Flink版本,包括多版本作业代码比较和回滚,详情请参见管理作业版本。 | |||
| 提供元数据管理:您可以通过Catalog连接常见的上下游组件(例如MySQL、Hive、Hologres、DLF和Kafka等),进行统一元数据管理与使用,详情请参见管理元数据。 | |||
| 自定义函数:您可以方便地管理和使用自定义函数,详情请参见管理自定义函数(UDF)。 | |||
| 代码模板:提供20多个Flink SQL通用场景的模板,帮助您快速了解如何使用Flink SQL构建作业代码,详情请参见代码模板。 | |||
| 代码调试 | 测试数据管理:支持线上采样和模拟测试数据管理,方便构建测试流程,详情请参见作业调试。 | 程序员、甚至是数据分析师都可以完成调试和上线的动作,大幅减少调试测试成本,提高作业上线速度和质量。 | |
| 快速运行调试:基于Session集群实现作业秒级启停,大幅提高作业调试效率。 | |||
| 中间结果展示:支持中间结果展示,提高复杂SQL的调试效率。 | |||
| 开发生产隔离:开发调试过程不影响生产作业和数据。 | |||
| 运维管理 | 监控告警 | 丰富的指标监控和维度聚合,便于排查作业延迟、数据倾斜、反压等问题,详情请参见监控指标说明。 | 大幅提高系统稳定性,减少运维工作量,降低调优的难度。精细化资源管理,大幅度降低成本。提供原厂高可用服务保障。 |
| 通过钉钉、邮件、短信、电话等途径进行及时告警,并可对接企业内部统一监控告警系统(Prometheus),详情请参见自定义监控指标及上报渠道。 | |||
| 问题分析与诊断 | 动态修改作业的配置,无需启停即可对日志Level、火焰图是否开启等配置进行在线调整。 | ||
| 对于反压、Job异常、TM失联等常见问题提供智能化诊断和快速日志定位分析,给出调优或者修改建议,并联动自动调优能力帮助您定位问题,详情请参见作业智能诊断。 | |||
| 高可用保障 | 原厂运维服务兜底,SLA 99.9%保证。 | ||
| 全链路自动容错能力,支持JobManager容错,系统无单点,更稳定。 | |||
| 提供更快速的非全局(单点)容错恢复能力,在数据一致性和业务连续性间提供灵活平衡。 | |||
| 状态管理 | 提供完整的系统检查点和作业快照生命周期管理,提供状态兼容性检查和状态数据迁移,以最大可能地复用原来的状态数据。 | ||
| 企业安全 | 空间隔离 | 支持租户级和项目级的资源和代码隔离,满足跨团队协作需求。 | 提供了企业多部门协同工作互不干扰的能力,安全可控地满足企业内控外审要求。 |
| 访问控制 | 与阿里云账号体系打通,支持多角色的访问控制。 |