技术架构的演进之路
我们以电商系统的技术架构发展为例文章目录
- 1. 单体架构
- 2. 应用数据分离架构
- 3. 应用服务集群架构
- 4. 读写分离、主从分离架构
- 5. 冷热分离架构
- 6. 垂直分库架构
- 7. 微服务架构
- 8. 容器编排架构
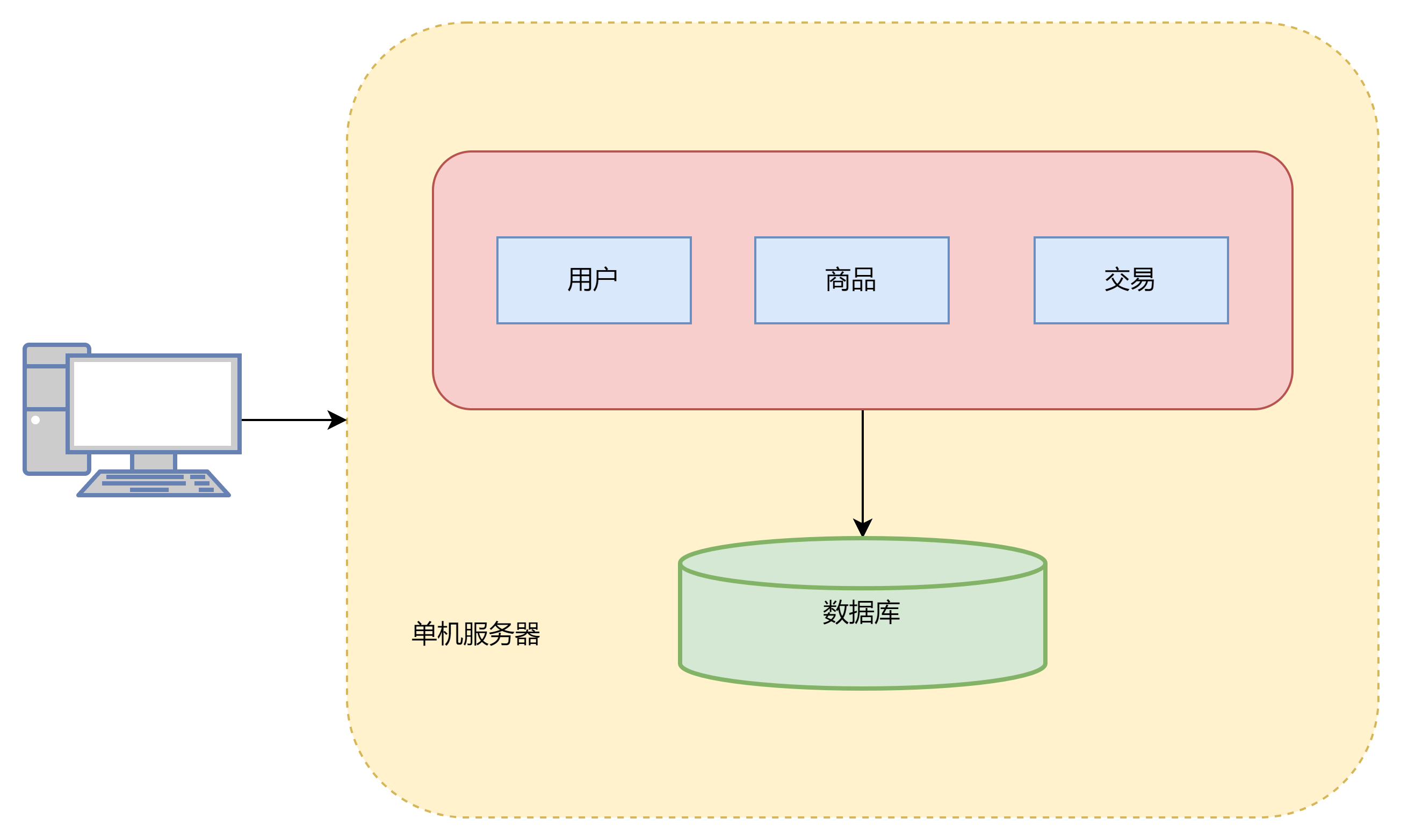
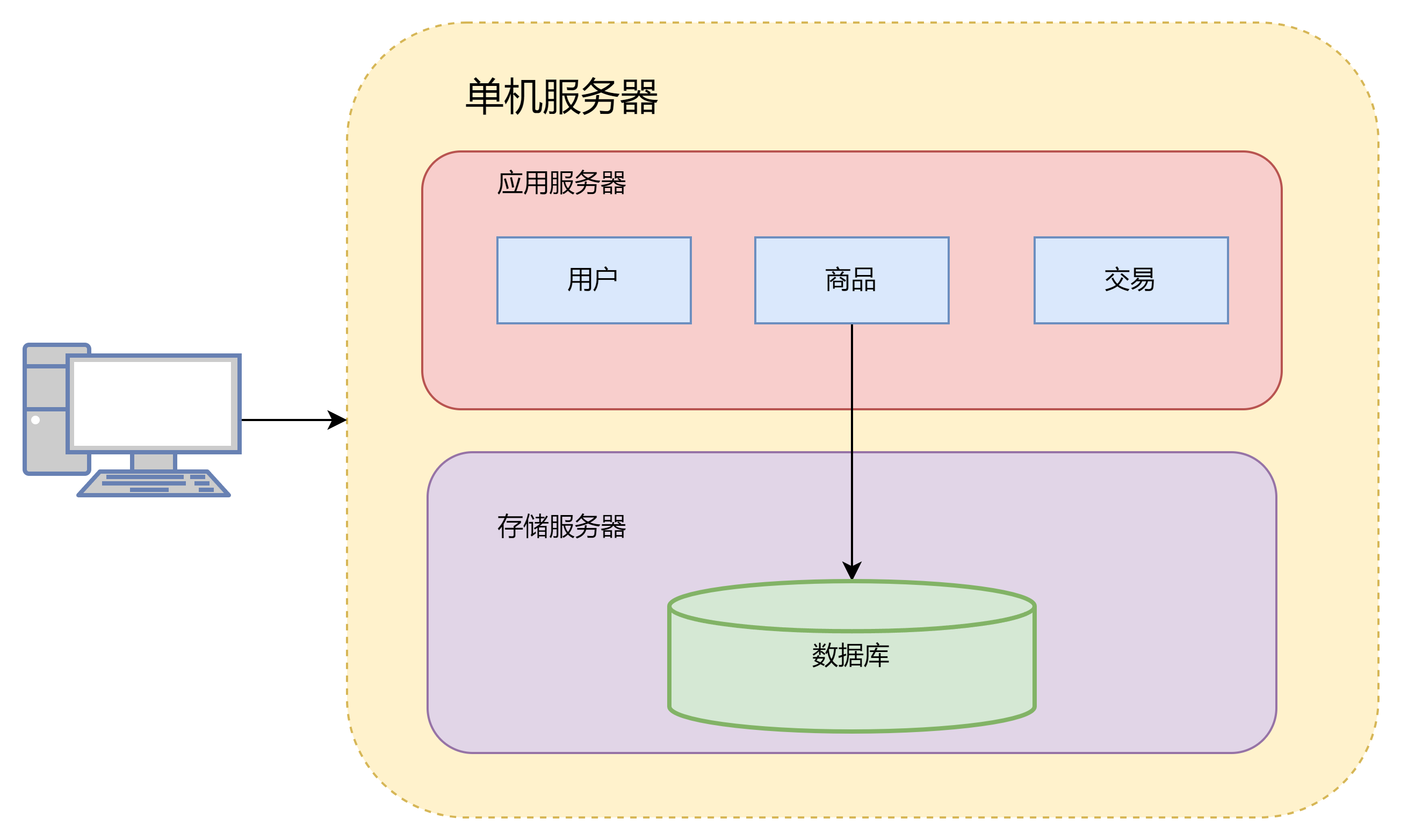
1. 单体架构
在前期用户访问量很少的时候,没有对性能、安全等提出很高的要求,系统架构简单,无需专业的运维团队,因此单体架构是合适的
此时用户访问服务器的流程就为
单体架构的优点就是部署简单,并且成本低
缺点也很明显,存在严重的性能瓶颈,数据库和应用存在互相竞争资源的情况
2. 应用数据分离架构
后续随着系统的访问量逐步上升,为了缓解服务器的压力,采取了将应用和数据分离的做法,提升了系统的承载能力
此时用户访问服务器的流程就为
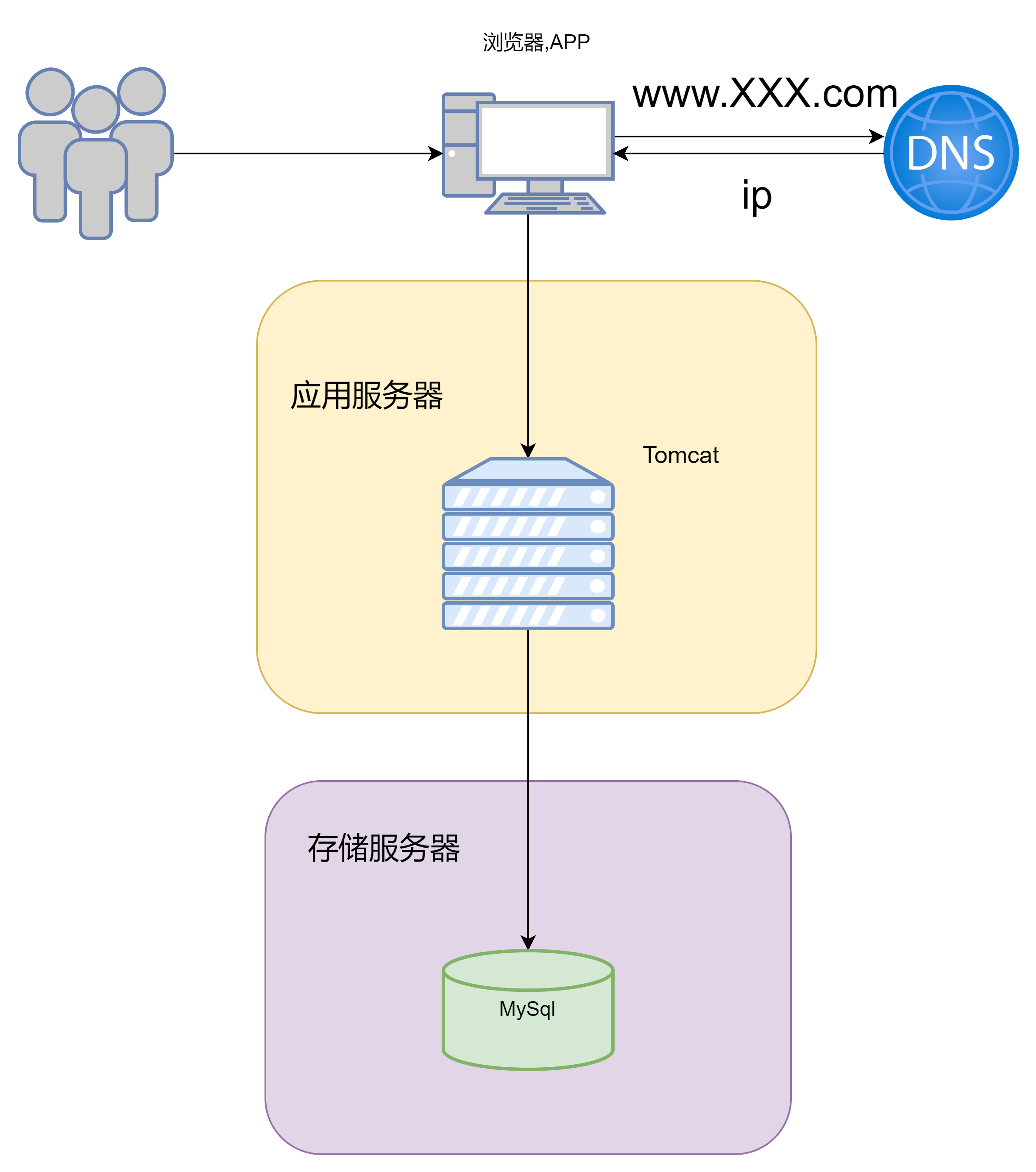
此时优点就是,成本相对可控,性能也比单机架构有所提高,数据库单独隔离出来,能够很好的防止由于应用故障把数据破坏了
缺点还是性能存在很大的瓶颈,无法应对海量并发的情况
3. 应用服务集群架构
后续请求越来越多,单机应用服务器已经无法满足需求了,此时就会对应出现两种解决方案
- 垂直拓展: 即通过购买性能更优,价格更高的应用服务器来应对更多的流量,优势在于不必对系统的软件进行任何的调整,但是劣势是硬件性能和价格的增长是非线性的,成本是不可控的
- 水平拓展: 通过调整软件架构,增加应用层硬件,将用户流量分担到不同的应用层服务器上,来提升系统的承载能力。这种优势在于成本相对来说比较低,并且提升的上限大,但是劣势是给系统带来流量更多的复杂性,需要技术团队有更加丰富的经验
这个架构选择的解决方案是水平拓展,此时就不得不引入新的组件 – 负载均衡,用来解决用户流量向哪台应用服务器分发方问题
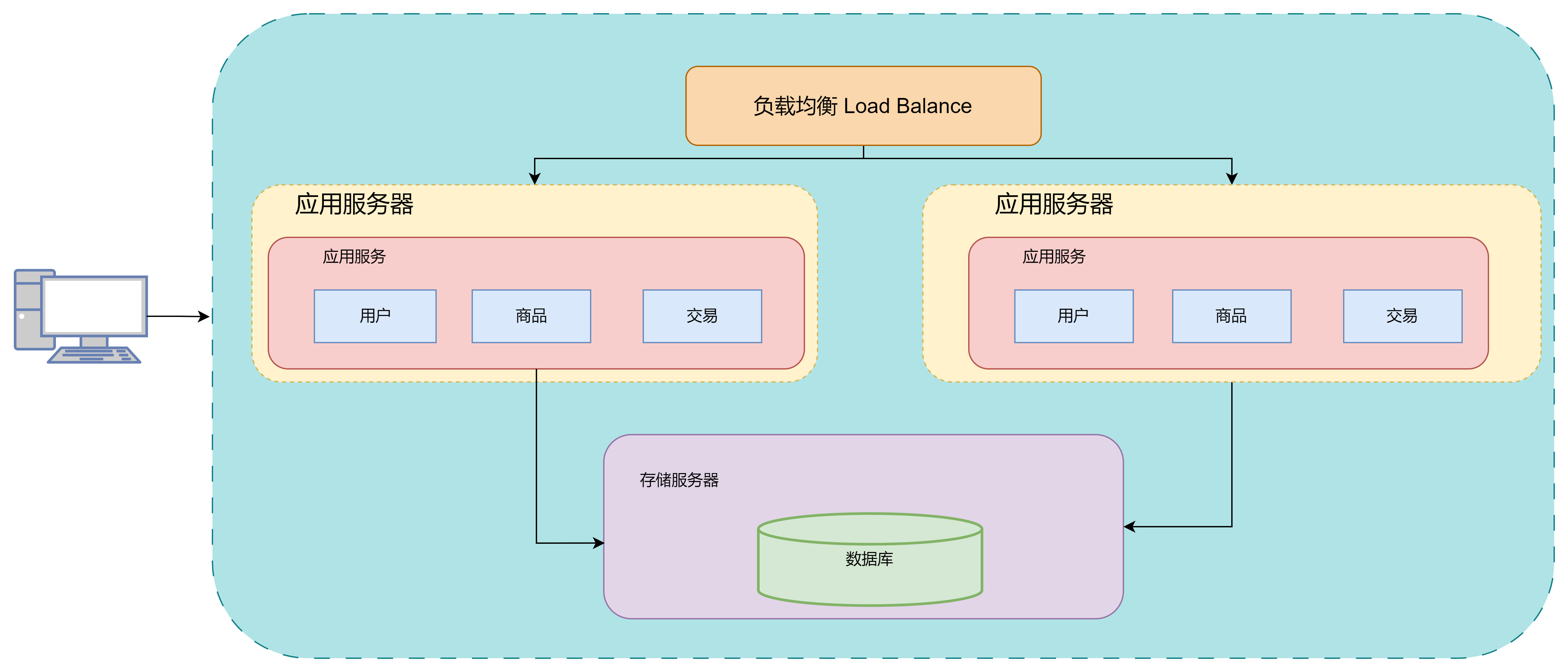
此时用户访问服务器的流程就为
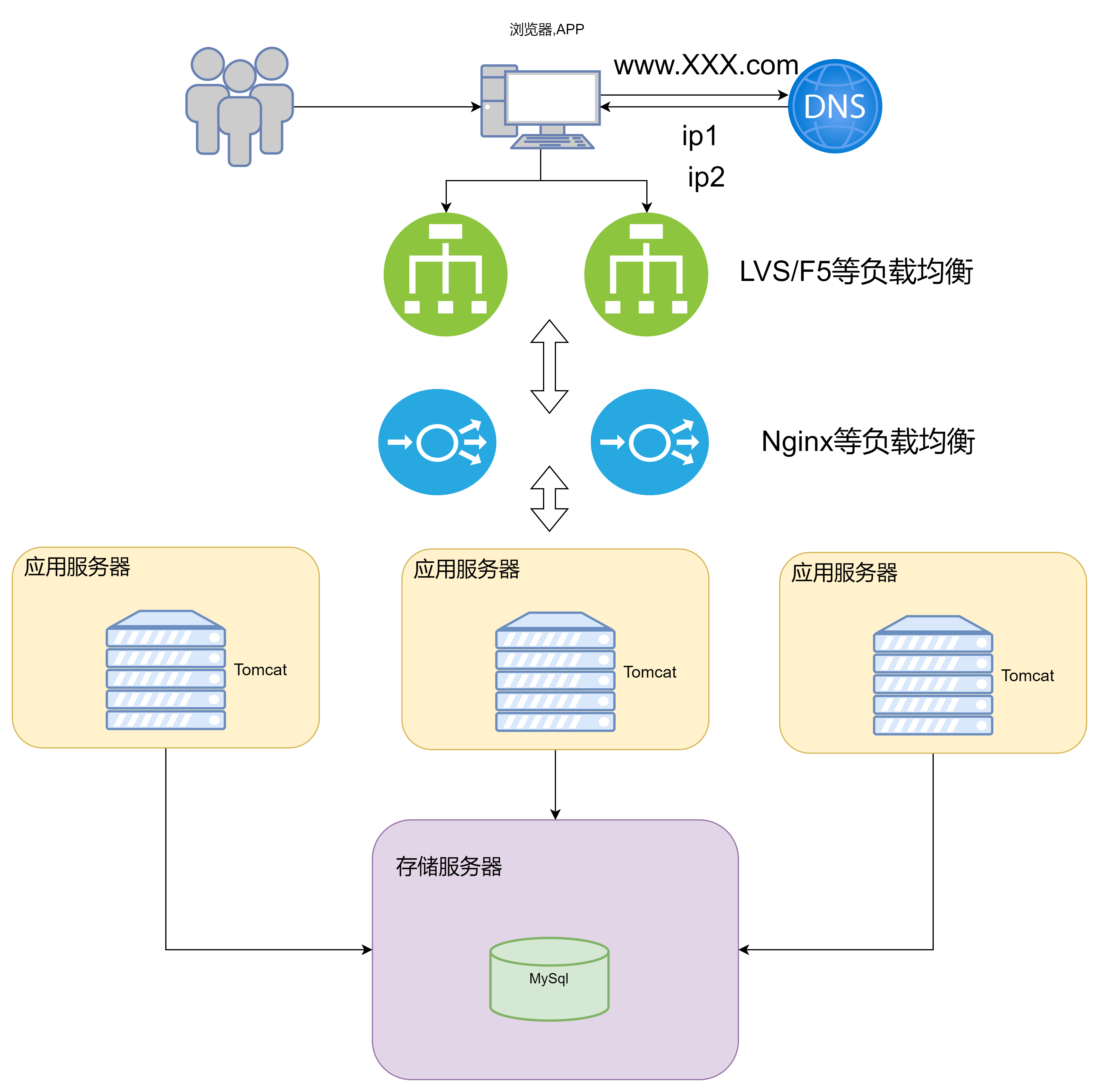
优点:
- 应用服务高可用: 应用满足高可用,不会因为一个服务出现问题导致整个站点垮掉
- 应用服务具备一定高性能:在不访问数据库的前提下,此时的应用程序可以支持海量请求快速响应
- 应用服务具有一定的可拓展性,即支持横向拓展
缺点:
- 数据库成为瓶颈,无法应对数据的海量查询
- 运维工作增多,拓展后部署运维的工作增多,需要开发对应的工具应对快速部署
- 硬件成本高
4. 读写分离、主从分离架构
数据的压力成为系统承载能力的瓶颈,但是我们不能将存储服务器像应用服务器一样拓展,如果将存储服务器进行拓展,那么各个数据库之间的数据一致性将无法保证
此时采取的方法是: 保留一个主要的数据库作为写入数据库,其他的数据库作为从属数据库
从库的所有数据全部来自于主库的数据,经过同步之后,从库可以维护着于主库一致的数据。为了分担数据库的压力,可以将写数据的请求全部交给主库来处理,而读请求分散到各个从库中
由于大部分的情况下,读写的请求是不成比例的,可能100次请求里面就只有1次是写请求,所以只要将读请求由各个从库分担之后,数据库的压力就没有那么大了。当然不可否认的是主库和从库之间的数据同步是需要时间代价的
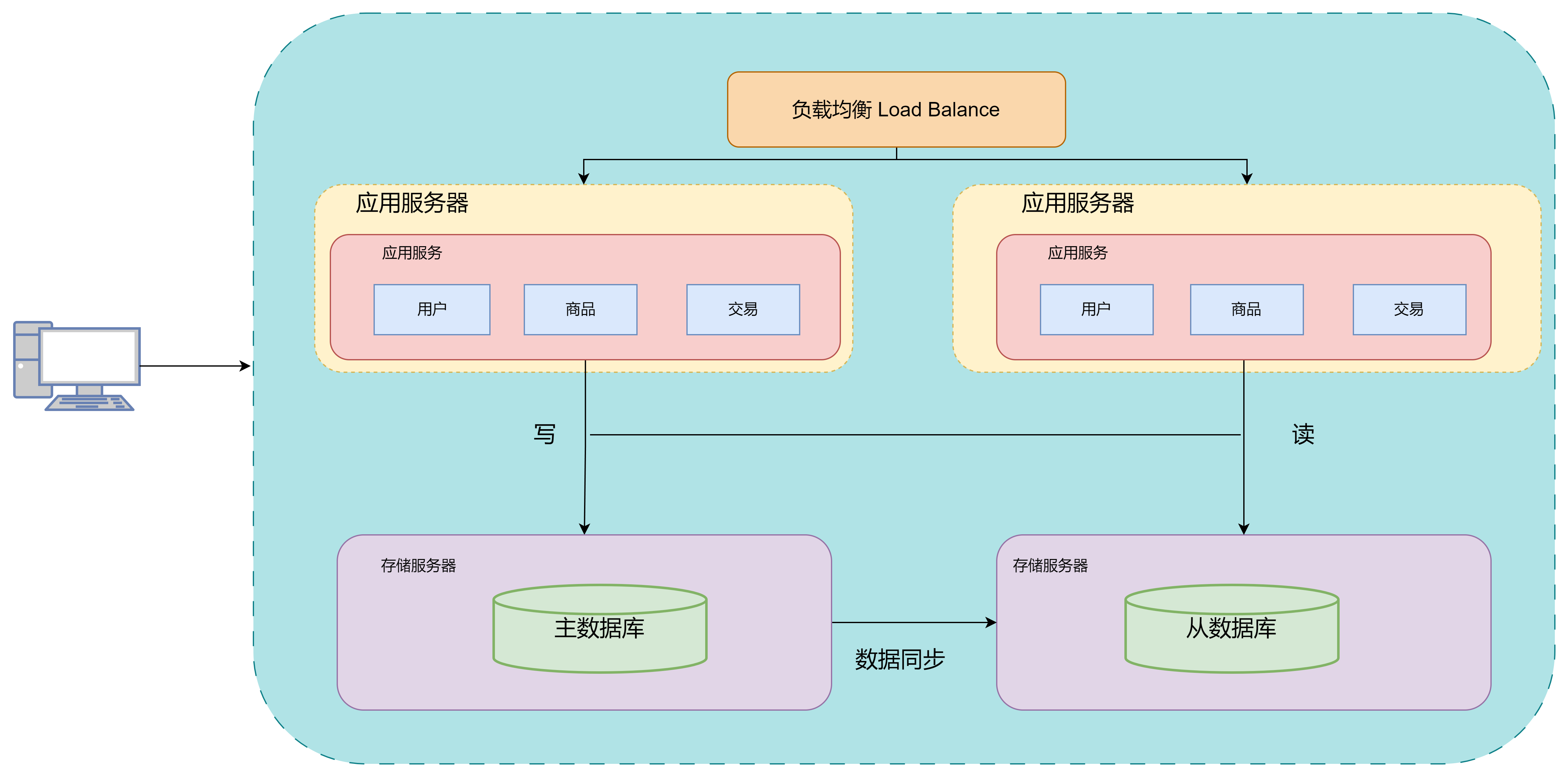
此时用户访问服务器的流程就为
优点:
- 数据库的读取性能提升,同时由于读的功能被从库分担,写的性能也提升
- 数据库由从库,数据库的可用性提高
缺点:
- 热点数据频繁读取还是会导致数据库的负载很高
- 当同步挂掉,或者当同步延迟比较大的时候,从库和主库之间的数据不一致
- 服务器需要的成本进一步增加
5. 冷热分离架构
有些数据的读取频率远大于其他数据的读取频率,这部分数据称为热点数据
针对热数据,为了提升读取的响应时间,可以增加本地缓存,并在外部增加分布式缓存,缓存热数据(如热门商品信息等等)。通过缓存可以将绝大部分请求在读写数据库之间拦截掉,大大降低了数据库的压力。
其中我们可以使用memcached作为本地缓存,使用Redis作为分布式缓存,但是需要应对缓存一致性,缓存击穿,缓存雪崩,热点数据集中失效等问题
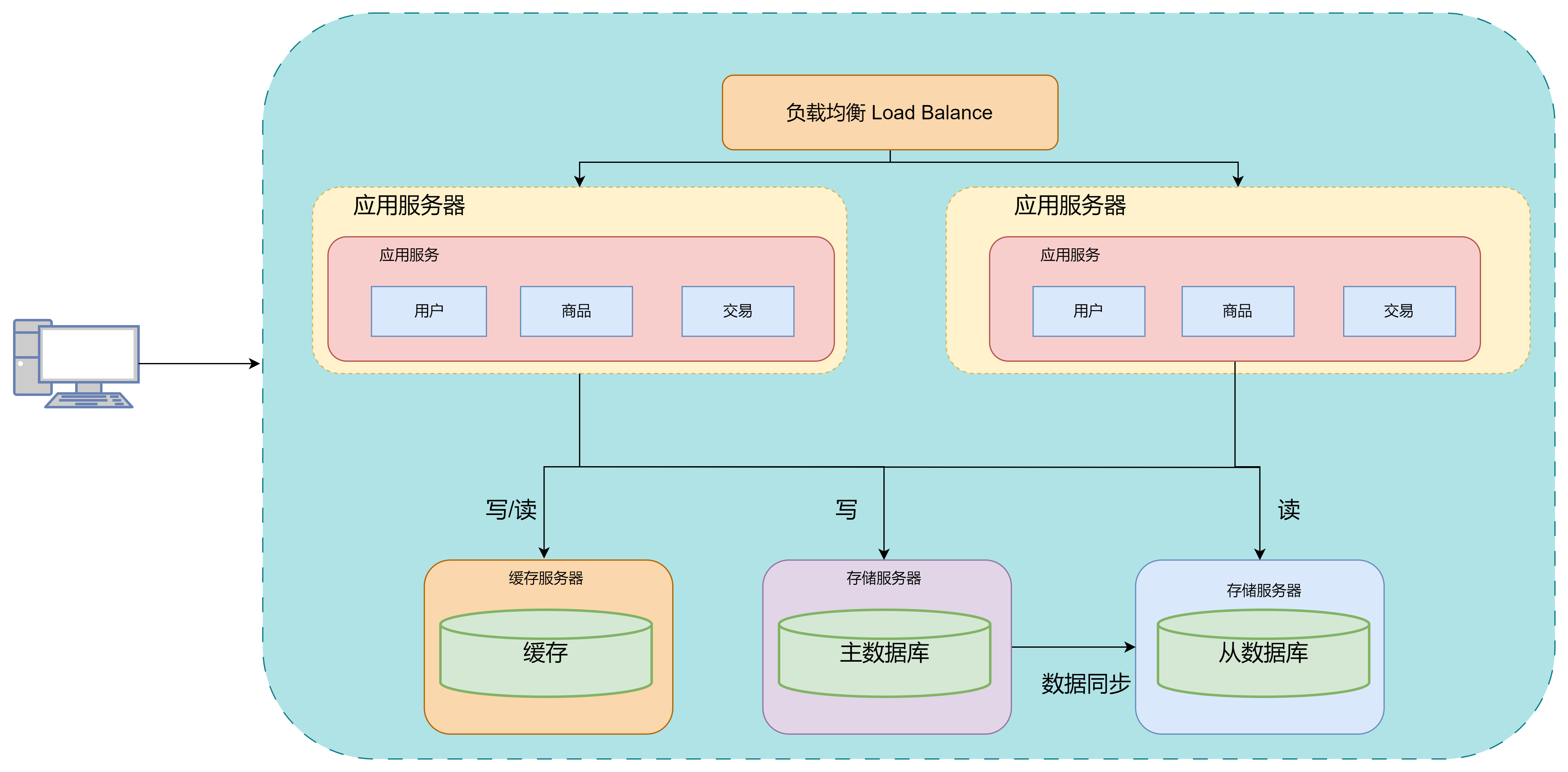
此时用户访问服务器的流程就为
优点:大幅降低对数据库的访问请求,性能提升非常明显
缺点:
- 带来了缓存一致性,缓存击穿,缓存失效,缓存雪崩的问题
- 服务器成本进一步提升
- 业务体量支持变大后,数据不断增加,数据库单库太大,单个表的体量也太大,数据查询会很慢,导致数据库再度成为系统瓶颈
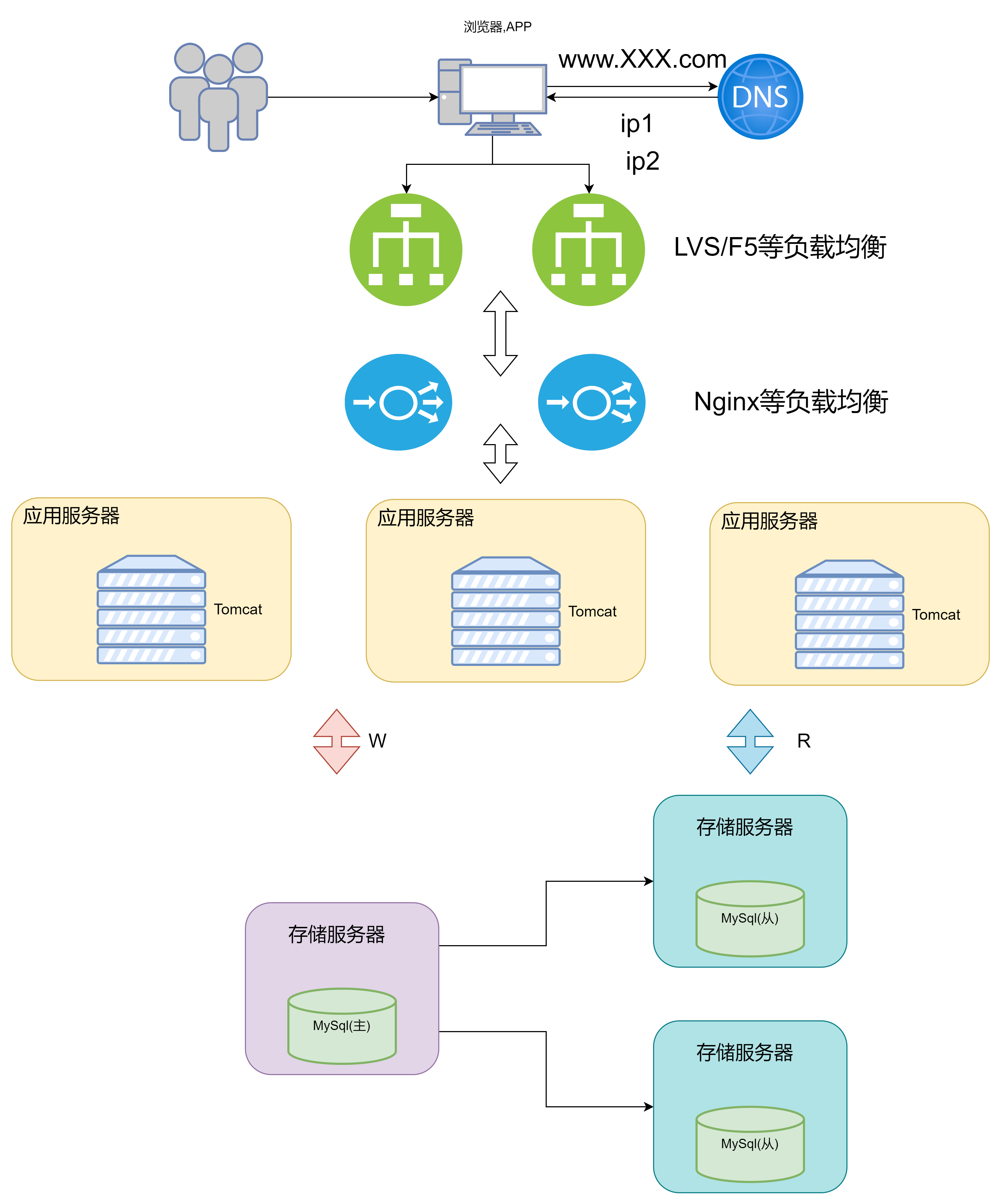
6. 垂直分库架构
大量的数据存储在同一个库中不太能够支撑数据量的不断增大,可以按照业务,将数据分别存储
比如针对评论数据,可以按照商品ID进行哈希计算,路由到对应的表中存储; 针对支付记录,可以按照小时创表,每小时表再继续拆分为小标,使用用户ID或记录编号来路由数据。
其中前面提到的mtcat数据库中间件也支持在大表拆分为小表的情况下的访问控制
数据库到达这种结构的时候,已经可以称为是分布式数据库,但从用户的角度来看,它仍然是一个统一的数据库系统,数据库里不同的组成部分是由不同的组件单独来实现的,如分库分表的管理请求和请求分发,有Mycat实现,SQL的解析由单机的数据库实现,读写分离可能由网关和消息队列来实现,查询结果的汇总可能有数据库接口层开实现等等,这种架构实际上是MMP(大规模并行处理)架构的一类实现
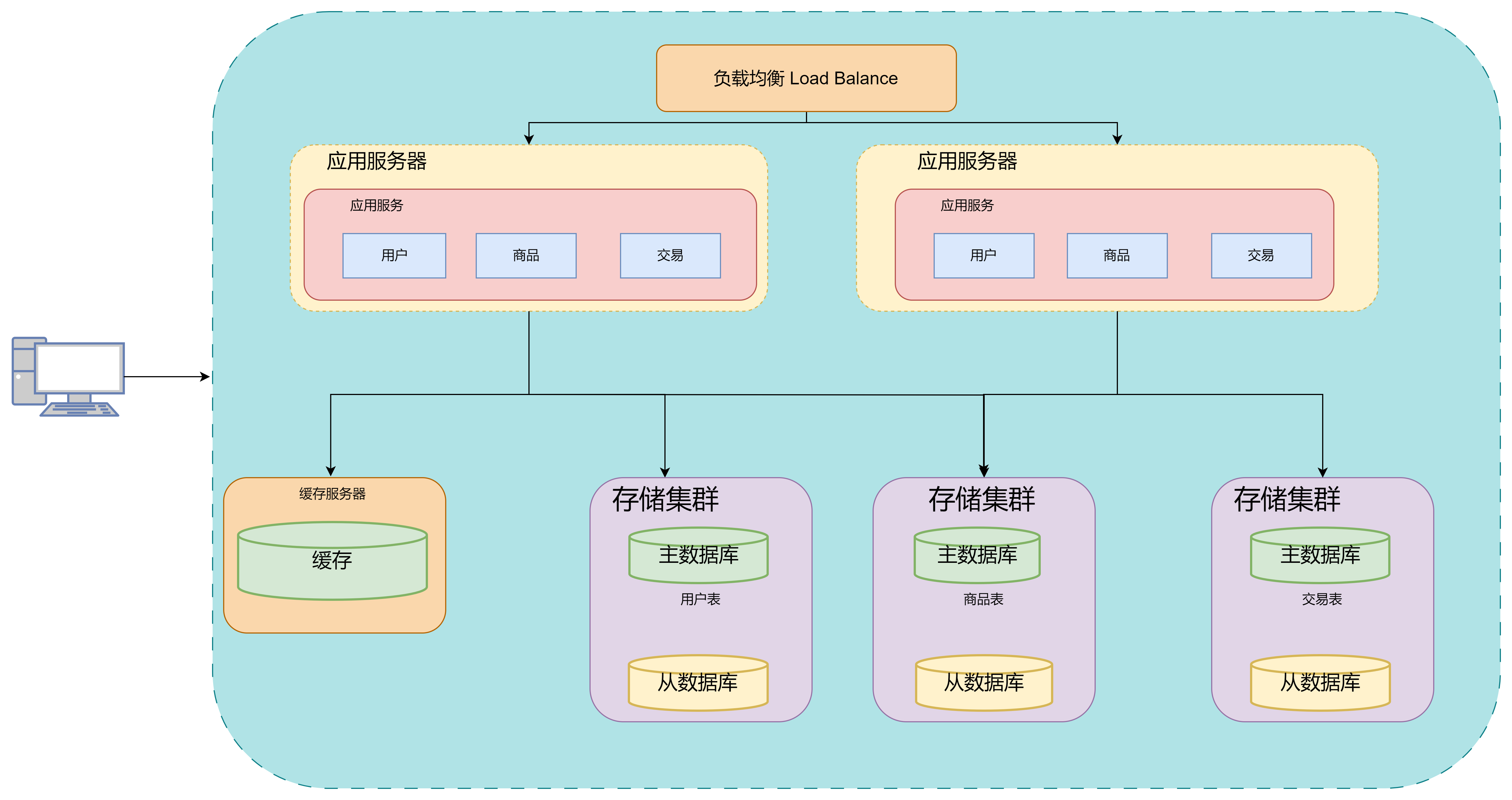
此时用户访问服务器的流程就为
优点:数据库吞吐量大幅提升,不再是瓶颈
缺点:
- 跨库join、分布式事务等问题,这些需要对应的去进行解决(目前的mpp都有对应的解决方案)
- 数据库和缓存结合目前能够抗住海量的请求,但是应用的代码整体耦合在一起,修改一行代码需要整体重新发布,所以又回到应用的问题
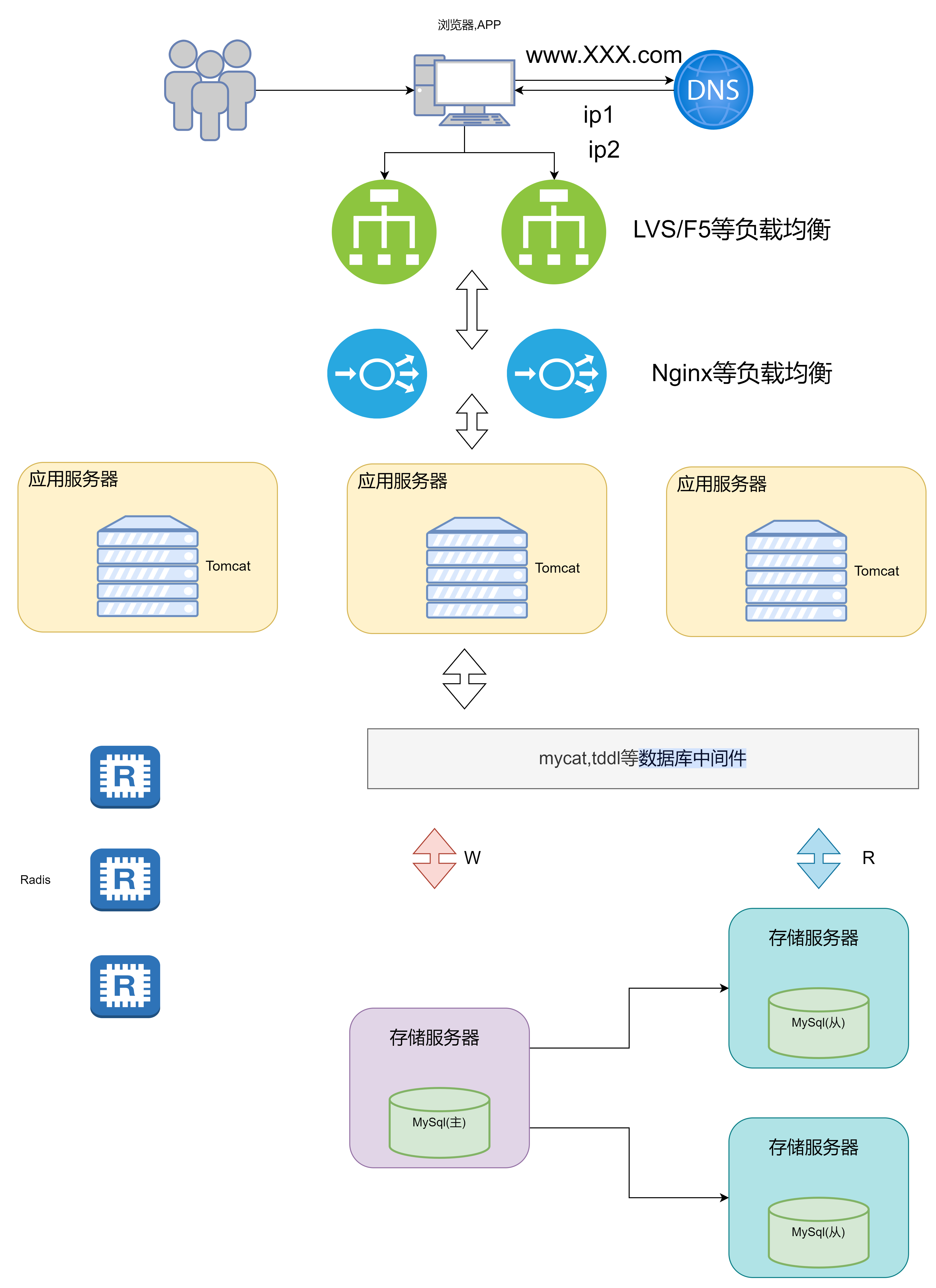
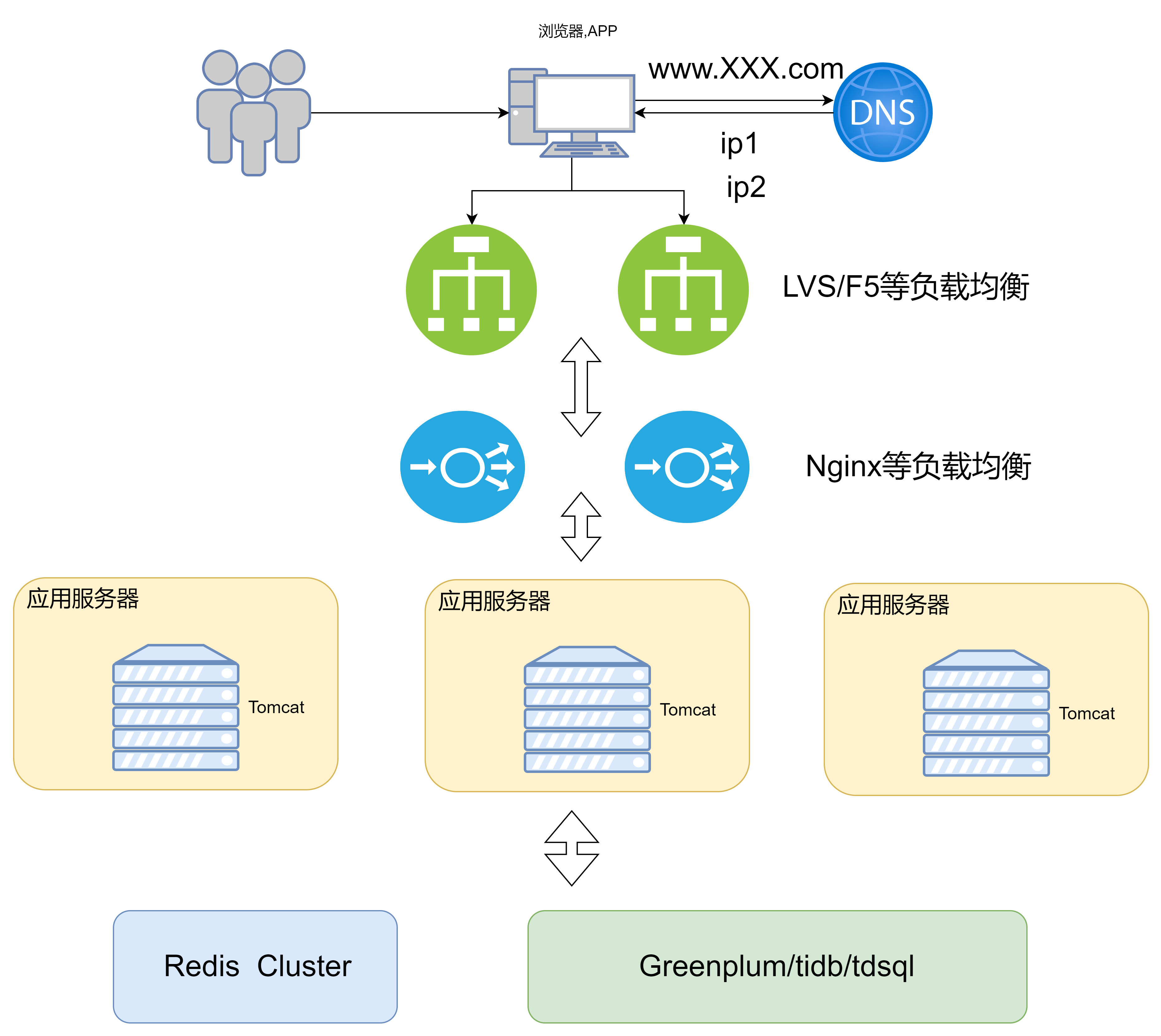
7. 微服务架构
随着业务的发展,可以将业务分给不同的团队去维护,每个团队独立实现自己的微服务,然后互相之间对数据的直接访问进行隔离,可以利用Gateway、消防总线等技术,实现相互之间的调用关联。甚至可以把一些如用户管理等业务提升成公共服务
此时用户访问服务器的流程就为
优点:
- 灵活性高:服务独立测试、部署、升级、发布
- 独立扩展:每个服务可以各自进行扩展
- 提高容错性:一个服务问题并不会让整个系统瘫痪
- 新技术的应用容易:支持多种编程语言
缺点:
- 运维复杂度高:应用和服务都不断变多,应用和服务的部署变得复杂,同一台服务器上部署多个服务还要解决运行环境冲突的问题,此外,对于如大促这类需要动态扩缩容的场景,需要水平扩展服务的性能,就需要在新增的服务上准备运行环境,部署服务等,运维将变得十分困难
- 资源使用变多:所有这些独立运行的微服务都需要需要占用内存和 CPU
- 处理故障困难:一个请求跨多个服务调用,需要查看不同服务的日志完成问题定位
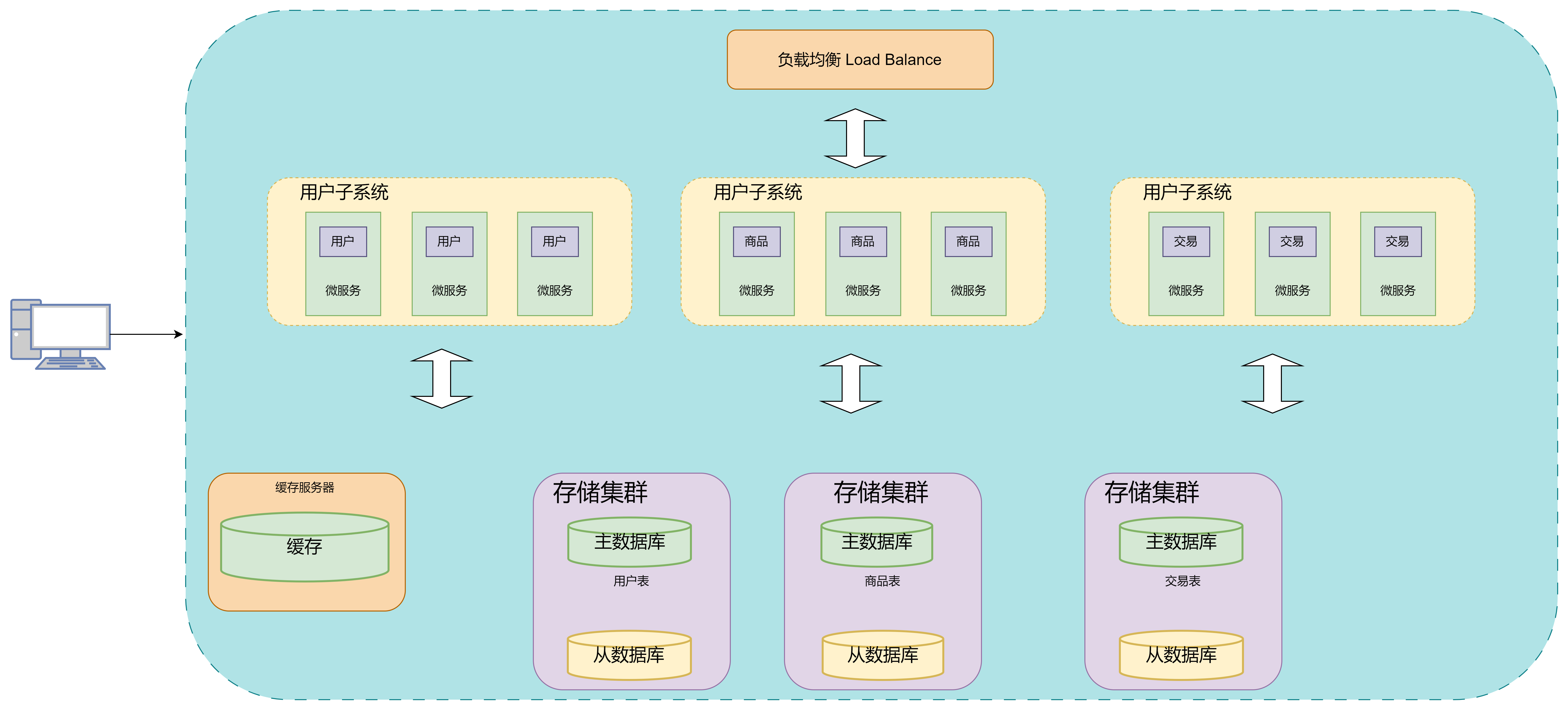
8. 容器编排架构
随着业务的增长,发现系统的资源利用率并不高,很多资源用来应对短时高并发,但是平时又闲置,就需要动态扩缩容,但是又不能直接下线服务器,而且开发、测试、生产每套环境都需要单独隔离的环境,运维的工作量非常大。
容器化开发的技术给这些问题的解决带来的新的思路
目前最流行的容器是Docker,最流行的容器管理服务是Kubernetes(K8S),服务可以打包成Docker镜像,通过K8S来动态分发和部署镜像。
Docker可以理解成一个能够运行服务的最小操作系统,里面放着服务的运行代码,运行环境根据实际的需要进行设置,把整个服务打包成一个镜像之后,就可以分发到需要的服务器上,直接启动Docker镜像就能将服务启动起来,使服务的部署和运维变得简单

此时用户访问服务器的流程就为
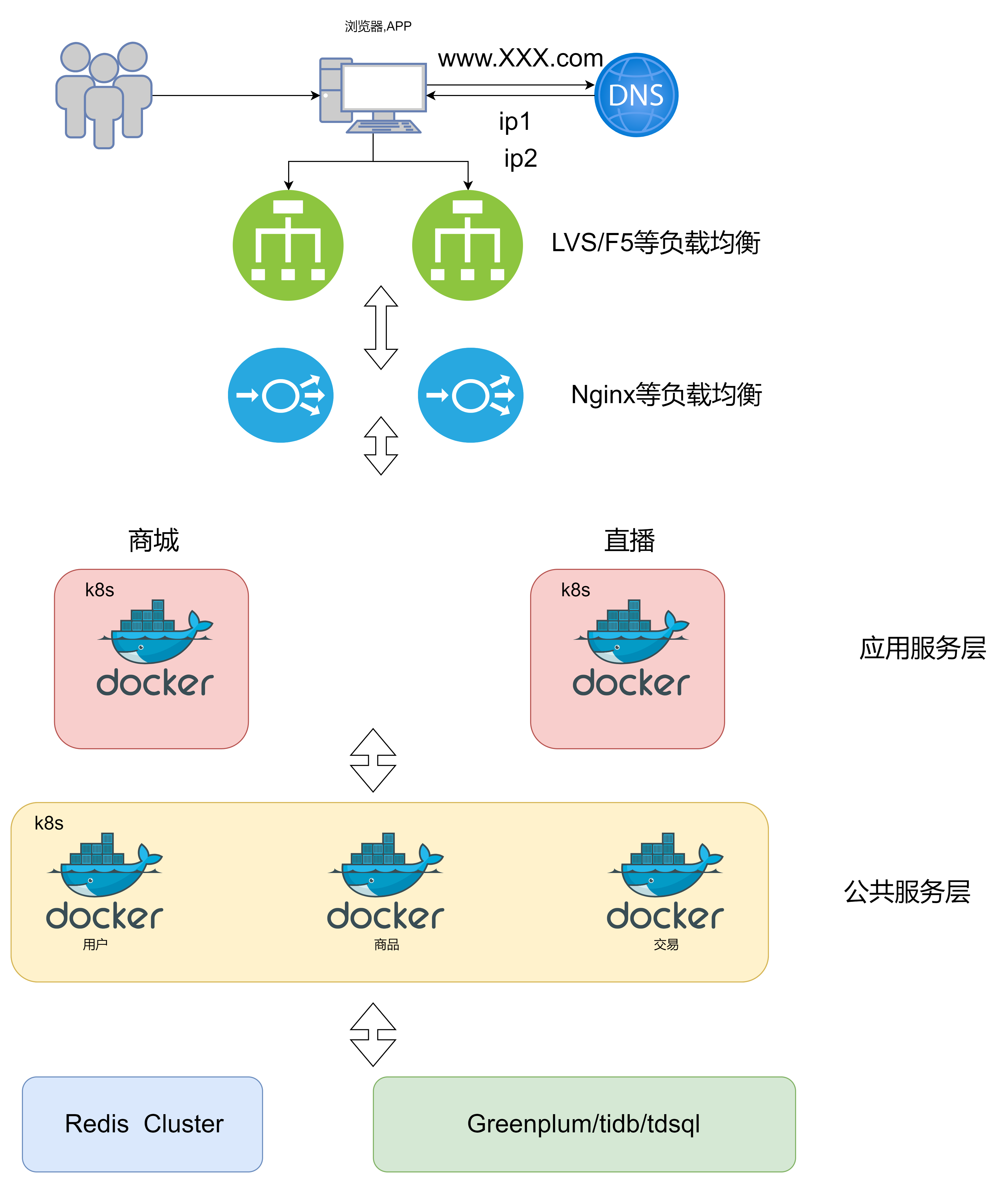
优点:
- 部署、运维简单快速:一条命令就可以完成几百个服务的部署或者扩缩容
- 隔离性好:容器与容器之间文件系统、网络等互相隔离,不会产生环境冲突
- 轻松支持滚动更新:版本间切换都可以通过一个命令完成升级或者回滚
缺点:
- 技术栈变多,对研发团队要求高
- 机器还是需要公司自身来管理,在非大促的时候,还是需要闲置着大量的机器资源来应对大促,机器自身成本和运维成本都极高,资源利用率低,可以通过购买云厂商服务器解决。