前言:这里很抱歉前几期考研专题以及PyTorch这些内容都没有更新,并不是没有在学了,而是事太鸡儿多了,前不久刚刚打完华为开发者比赛,然后有紧接着高数比赛、考研复习,因此这些后续文章都在草稿状态中,等忙完这阵再更新......

然后这里我大三选的方向是“大数据”,也没办法课程钩八多得不行,作业也多,所以我只好迫于无奈为了做作业开启《大数据》得课程学习笔记撰写,希望对软件工程相同开发方向专业的朋友有所帮助。(想完整了解大数据的就从第一大点开始看,只为了【安装部署各个软件】的直接跳到第二大点)
一、大数据是啥?
大数据细分的话要比我之前学的前后端软件开发涉及的切面太多太多,单说那沙笔课就有三四个,又是什么大数据采集与预处理、大数据分布式并行处理、python大数据分析,上了一周课我也没整明白老子到底在学些什么。
1、大数据的概念
看过不少视频后,我总结了大数据简单来看是干什么的:
—— 《就是将海量无穷多的数据,进行【采集】、【存储】、【计算分析】》
;
- 打个比方,你大学有个作业是《研究大学生对心理健康了解程度分析》,那是不是要用到大量数据?那就需要取采访或者填调查表,这就是【采集】(关心得比较少)
- 然后如果你要查全中国大学生的数据,几十亿人口,这些数据可不是你那个烂电脑能存储得下的,就需要用到大数据的【存储】
- 接下来,你希望统计你这个调查数据里“男生的比例”、“女生的比例”、“20-23岁之间的比例”,几亿条数据里你要一点一点人工统计吗?肯定不行,那就得靠大数据来【计算分析】

然后大数据四个特点(简单了解):
——大量(能够存储并处理“无穷无尽”的海量数据)、
——高速(计算快,比如天猫双十一实时计算成交额)、
——多样性(文本、视频、表格、网站...什么类型的数据都能处理)、
——低价值密度(过滤无用信息,只提取有用的,这里与数据总量的大小成反比)

2、大数据需要解决的核心问题(含我们要学哪些技术栈)?
那么针对大数据是什么,我们可以知道后面我们需要学习的内容,也就是大数据需要解决什么问题:(简单了解,不要去记,现在记住以后也会忘)
因为我们知道大数据主要就是处理【存储】和【计算分析】(【采集】先不管),那么:
;
(1)数据的存储:分布式存储
离线数据(历史的、已存在的)存储:HDFS、HBase、Hive
实时数据(未来的、还不存在的)存储:Kafka
;
(2)数据的计算:分布式计算
离线数据计算:MapReduce、Spark Core、Flink DataSet
实时数据计算:Storm、Spark streaming、Flink DataStream
;
这里举个例子什么是离线和实时:
——比如你浏览过的所有黄色网站信息、你发出的所有微信消息,这就是一些离线的数据;
——那比如天猫双十一要实时计算出未来每小时成交量和用户热度...这些数据还不存在,但是要预先为这些数据设计对应的存储方式、计算模型,这就是实时数据
3、数据分析的基本流程
那么有个大概理念之后,我们肯定还是一头懵:那我们到底该怎么用大数据,怎么个大致流程啊?
简单一句话,数据分析流程就是:数据从哪来的?数据最后到哪去?
核心步骤是:【采集】、【处理】、【分析】、【应用(包括数据展现、撰写报告)】
【采集】:通常分为“从无到有”和“从有到无”两种数据
前者就是好比你买了一个传感器收集气象数据、调查填表......原本没有你要的数据,自己产出
后者就是已有的,比如b站、学习强国爬虫获取他们网站的数据、一些公开数据源
;
【处理】:准确来说是【数据预处理】,主要包括(数据清洗、数据转化、数据提取、数据计算),最终将原本文字、视频、音频这些格式乱七八糟的数据,预处理成一种干净规整的结构化数据。
;
【分析】:运用算法和分析工具,对“预处理”过的数据进行分析,提取有价值的部分,相当于一个过滤的过程吧
;
【数据展现】:这里就可以应用我们处理过的数据了,那么因为很多人都是白痴,看不懂文字、表格数据,人们更倾向于看可视化的统计图。
;
【撰写报告】:然后还有报告,报告是针对这个数据分析做出的结果汇报,比如根据2021年高考志愿大数据分析,清华北大是近几年最容易、最少人报的民办大专(我开玩笑的,清华北大校友别网暴我)


4、分布式、集群概念
那老是提到什么分布式分布式,分布式是个啥玩意?集群又是啥玩意?
简单来说:【分布式】就是多个服务器分工干多个事;【集群】就是多个服务器干同一件事。

5、【总结】
简单看一下,学习大数据将要了解、涉及到的各个模块、各个技术栈

二、虚拟机安装
1、介绍虚拟机是啥
相信各位学过Linux的、或者对大学考试作弊深有研究的掉毛们,对虚拟机肯定不陌生,那么既然我们要学习大数据分布式处理,那就需要模拟多个服务器来实现,那一个计算机能配置成一个服务器,那我们总不能把自己的本机电脑配成服务器吧?而且我们一台电脑也没办法整多个服务器出来,那就需要虚拟机来配置构建服务器,来模拟代替一个真正的计算机。(虚拟机就是虚拟的一台计算机)
这里还要提一下硬件虚拟化技术,简单了解即可,我们都知道虚拟机并不是真的一个物理上存在的计算机机器,只是对计算机硬件的一个虚拟化技术 “变出” 这么多类似计算机的机器;
那么阿里云也同理,全中国的开发者基本都会用到阿里云的服务器,但是每个账号都能拥有几个阿里云的服务器,阿里云真的有那么多台硬件服务器吗?当然不是,这也只是阿里公司现有那几台硬件服务器基础上,通过硬件虚拟化技术 “变出” 的无穷无尽的 “云服务器”
市面上的虚拟机很多种,其中最出名的就是【Oracle】和【VMware】

那么我结合大学里教的课程、以及b站所有大数据课程来看,推荐所有人安装【VMware】,因为大家都在用这个。(如果是用来作弊的话建议Oracle,因为装完window系统之后界面会更像一个真的电脑哈哈哈哈,作弊不会被抓)
( 另外,很多啥学校就是直接上课丢一堆安装包给你,然后你直接解压就行了,但是我建议你跟着我的步骤研究一下这些编译器、虚拟机、环境配置,别等会大学几年读完了去公司安装个软件都不会,等着老总还是同事给你发安装压缩包吗?)
2、VMware虚拟机安装步骤
步骤超简单,有手就行,跟着我的步骤不管以后VMware更新到第几代,界面变成啥样,找我做的就没错
1)点击进入VMware官网
VMware by Broadcom - Cloud Computing for the Enterprise
2)找到【搜索框】,然后搜索【Desktop Hypervisor】

3)然后点击【Products】,然后点击下面第一条链接,跳转后点击【Desktop Hypervisor】,然后一直点下去



4)通常这个时候就会跳出登录界面,没有登录过的就去注册一下,登录了的就直接登录,这里登陆注册步骤我就不想教了,都不用看教程白痴都会的,看不懂英文就“网页翻译”去


5)然后登录完就会自动跳到这界面,点击【My Downloads】,然后一直找找到【VWare Workstation Pro】,每一年界面可能都会变,但是虚拟机的名字【VWare Workstation Pro】不会变,找到他点击就行


6)最后找到【VWare Workstation Pro xxx(版本号) for Personal Use(Windows)】
(我的电脑是window x64位的就选这个,你们的不是的话就问一下网上你们的电脑适配什么),
展开后随便找一个版本点击就可以下载了(一般选第一个最新的就行)
在浏览器下载能看到已经下载了
(这里因为我把它移到别的位置了,所以显示“已删除”,图我懒得重新截图,将就看吧)


6)下载好之后点击安装,就跟正常安装软件一样,一直点下一步就行,图我都懒得截了,将就看别人的吧,不需要看清里面的字,就无脑照着大概点下去就行
(只是需要注意,安装的路径如果想安装到自定义的地方,请路径中不要带有“中文”、“空格”...等特殊符号)
这里可以更换安装路径,我个人是安装到 “F:/VWareWorksation17” 这个目录下







7)最后检查【虚拟网卡】有没有安装上,电脑之所以能上网就是因为有网卡,那么虚拟机同理,安装VMware正常情况是会自动安装上【VMnet1】和【VMnet8】这两个虚拟网卡的,如果没有的话,虚拟机就不能上网,因此要检查一下
点击设置——>网络和Internet——>高级网络设置——>更多网络适配器选项
;
如果你的window界面跟我的不一样,也可以【Win + R】输入【ncpa.cpl】也会弹出来
;
如果发现有【VMnet1】和【VMnet8】这两个虚拟网卡就正常,没有的话就把VMware整个卸载,然后重新按上面步骤安装




三、Ubuntu或CentOs系统
好了,现在有了虚拟机,那我们都知道,如果你有一台电脑,没有Windows系统......那还玩个鸡毛啊?还不如卖废铁丢掉。那么虚拟机同理,只不过这里我们大数据需要配置的是服务器,服务器需要的操作系统是Linux而不是Windows,所以我们就要给VWare虚拟机再准备好Linux系统。
这里就需要介绍一下Linux系统,这个系统其实是一个开源代码项目,就好比我们写完的一些网站、软件项目,也可以放开源网站给别人用,那么别人就可以基于你的项目的基础再进行修改完善。那么【Ubuntu】和【CentOs】就是这么个玩意,是后人在基于Linux源码的基础上,开发出的自己的新的Linux操作系统,这样的操作系统有千千万万个,其中最多人用的就是【Ubuntu】和【CentOs】。

简单来说,就是Linux是【Ubuntu】和【CentOs】的爹,那么【Ubuntu】和【CentOs】就带着Linux的基因,虽然它两有一些区别,但是本质都是【Linux系统】!!!我们就是要给VWare虚拟机装上【Ubuntu】或【CentOs】。
1、Ubuntu系统安装配置
首先进入官网,三个网址看个人喜好(前两个是官网国外网址,所以下载速度很慢,第三个推荐)
(较慢)英文版官网:https://ubuntu.com/download/desktop
(较慢)中文版官网:https://cn.ubuntu.com/download/desktop
(最快)清华大学镜像下载网站:清华大学开源软件镜像站 | Tsinghua Open Source Mirror
1)点击下载
(英文版官网,等到明年你毕业了就可以安装完了)

(中文版官网,等到明年你毕业了就可以安装完了)

(清华大学镜像下载网站,比你🦌的速度还快)
进入镜像网站直接搜索ubuntu,然后选择ubuntu-releases
;
进入页面后,选择自己需要的版本,我选择的是“24.04.1/”
选中之后点击,进入下个页面。
;
进入最终下载页面,选择“ubuntu-24.04.1-desktop-amd64.iso”下载保存即可。(注:文件后缀名一定要是iso)



2)在VWare安装Ubuntu
(上面其实是为了演示怎么安装Ubuntu,其实本人因为课堂老师要用的是20.04.5版本的,所以被迫无奈还是选择用老师发的压缩包了哈哈,但是至少我是会怎么下载Ubuntu的)
这里下载好的Ubuntu你可以随便放个位置,只要你以后记得在哪就行,然后有一个【重点问题】!!!有的人的电脑显示这个iso文件是一个“光盘图标”,有的可能是一个压缩包,尤其是那些用老师百度网盘发的压缩包的,它们是一个玩意!!!记住!!!!【不要解压!!!】【不要解压!!!】【不要解压!!!】
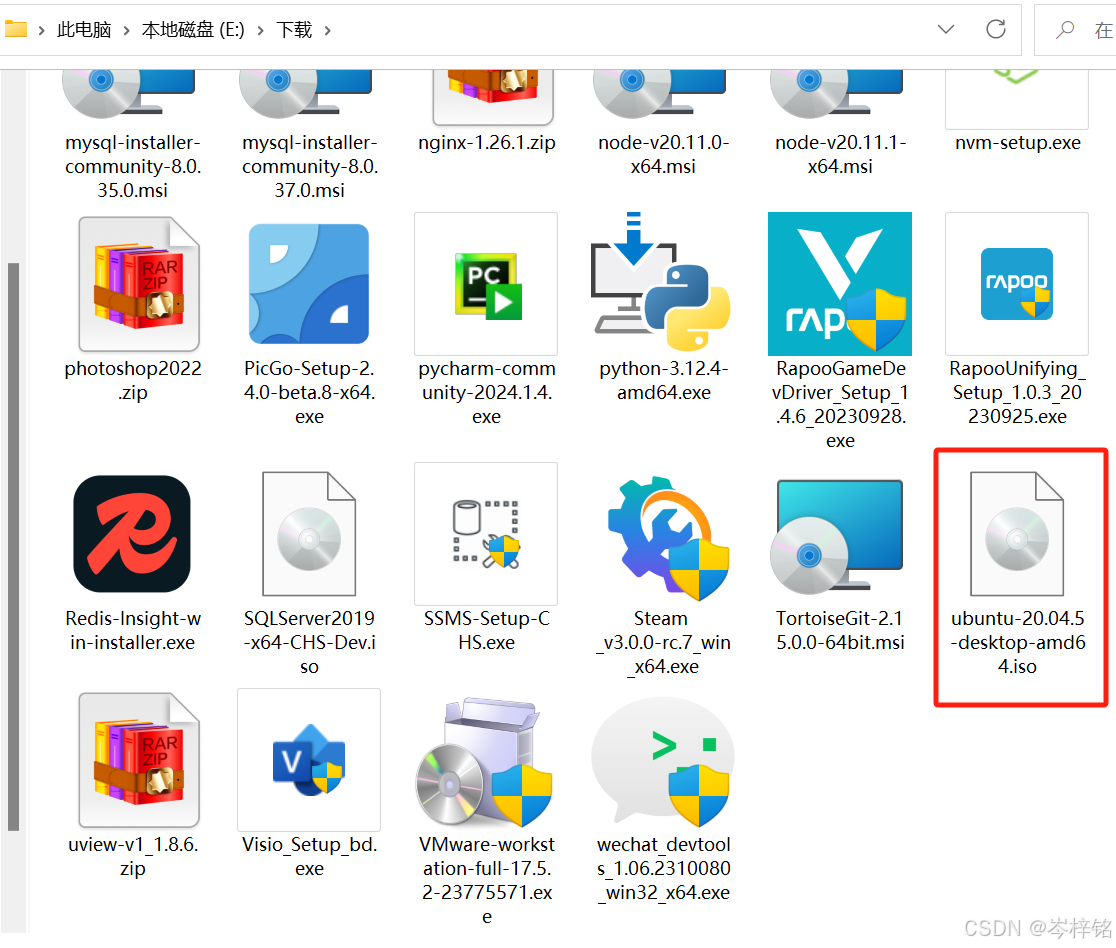
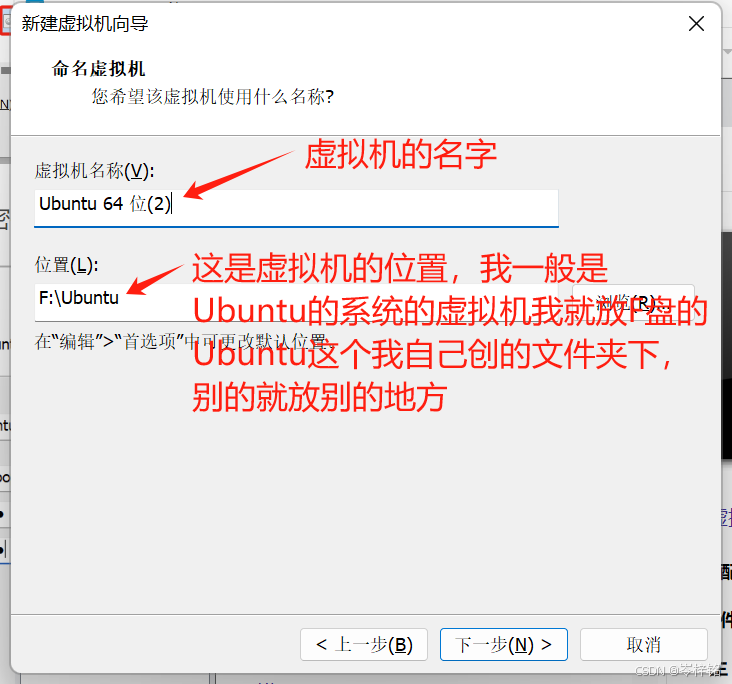
然后回到VWare,我们点击打开VWare,然后点下面位置来【创建一个虚拟机】
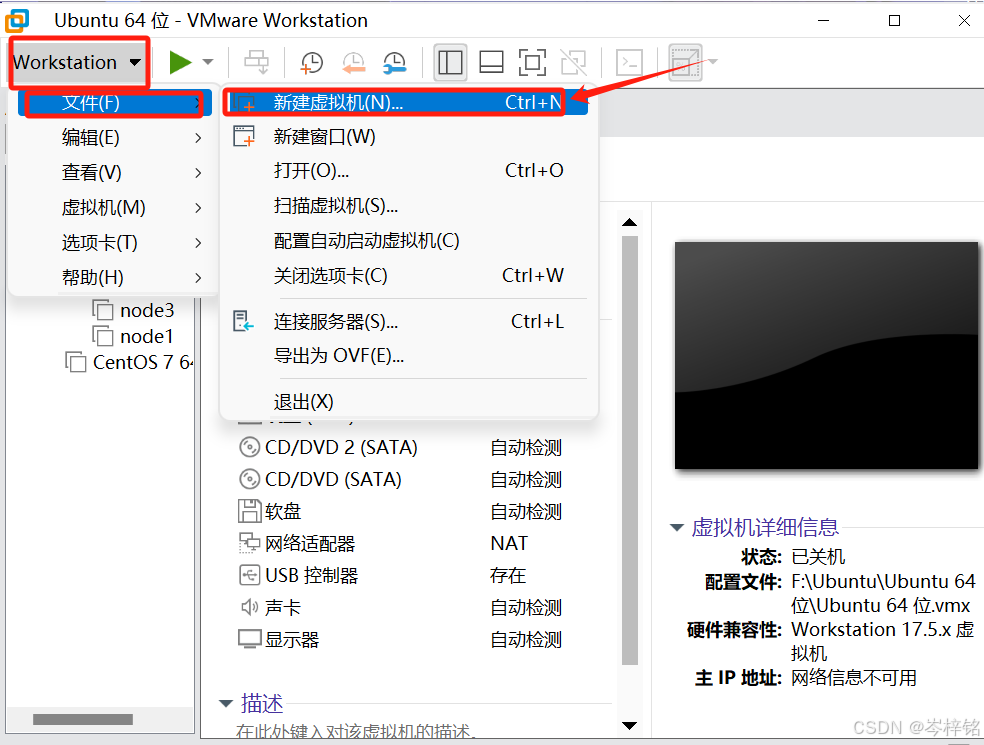
用最简单的方式创建,跟我图片一步一步点下去就行

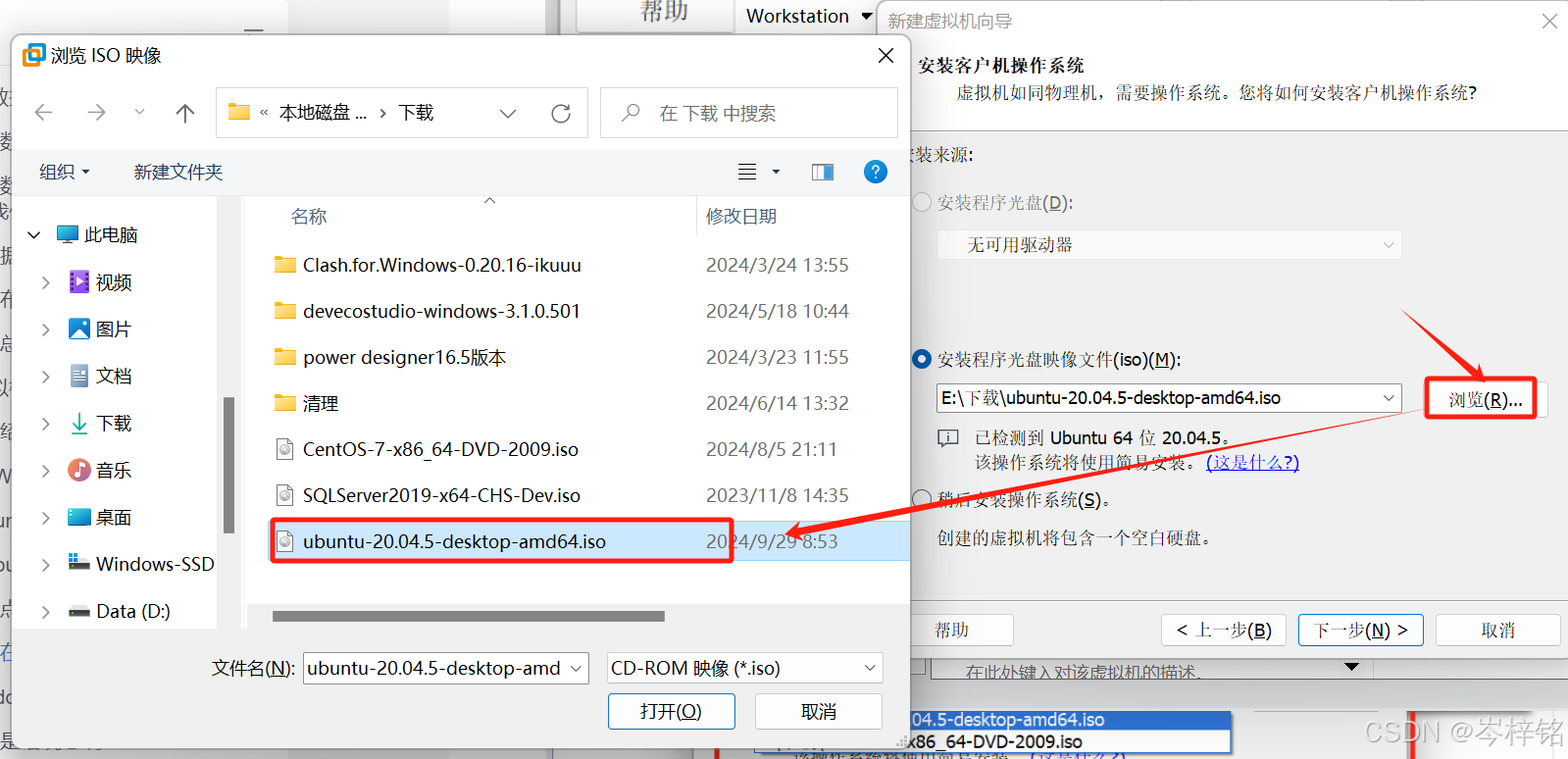
通常VWare会自动扫描整个电脑,如果你有下载好Linux系统(iso文件),它就会自动找到,比如我这里Ubuntu和CentOs的光盘文件他都自动找到,如果没有的话,你也可以自己手动找到Ubuntu的文件地址,添加进去
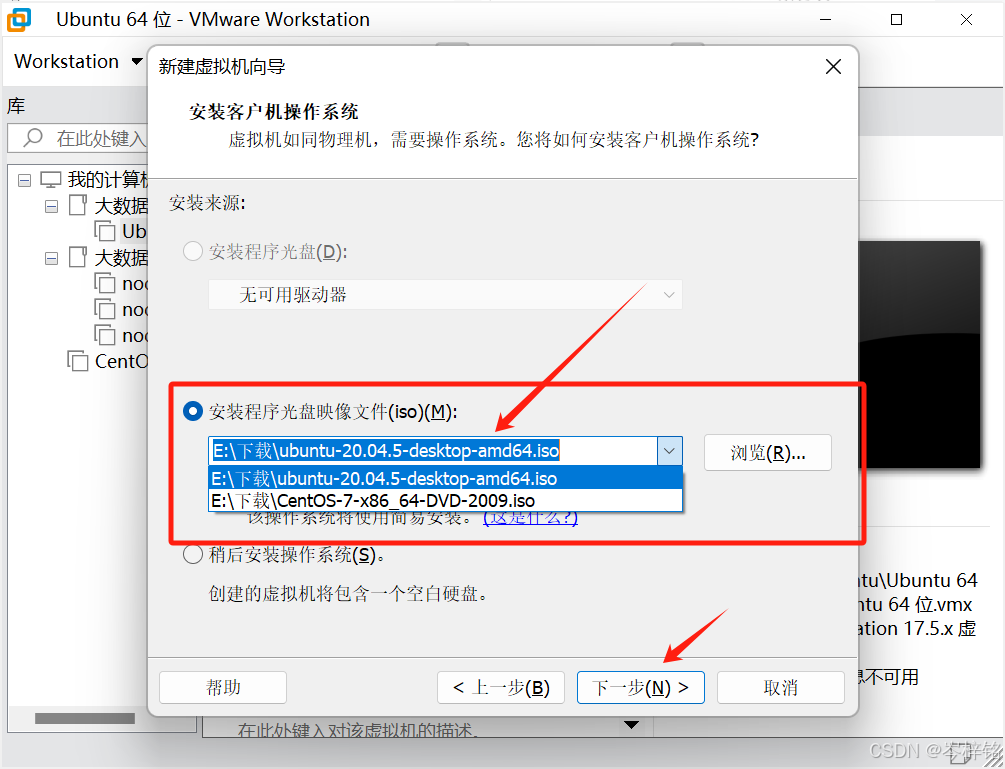
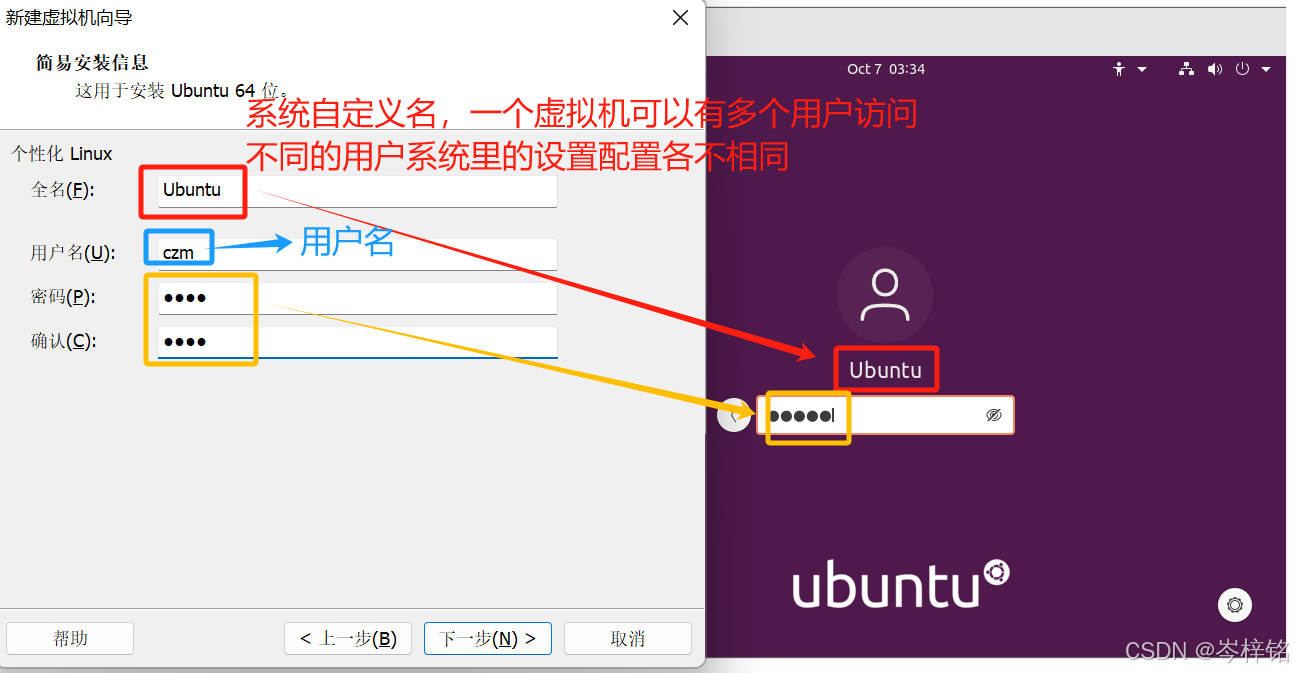
然后起名、设置密码啥的
然后进入页面之后,直接Skip跳过,然后一直点右上角的Next就行
注意弹出弹窗让你更新的话尽量别更新,容易不稳定
然后可能我们会发现左边的侧边栏图标很少,点击左下角菜单,把常用的【终端】和【设置】已过去就行
右键图标,点【Add to Favorites】就可以移过去
【拓展】
终端除了在这里点图标打开,还可以【Ctrl + Alt + T】打开
另外以后如果创建的虚拟机比较多,那么就可以新建文件夹管理一下,把你的虚拟机移进去就行了


2、CentOs系统的安装配置
那么根据黑马程序员、尚硅谷的视频,它们都是以CentOs系统来讲大数据课程的,那也讲一下CentOs的安装配置过程
1)点击下载
首先到下面阿里云的镜像网站中去下载CentOs的系统光盘文件,还是一样,一定要选后缀是.iso的!!!
网址:centos-7.9.2009-isos-x86_64安装包下载_开源镜像站-阿里云
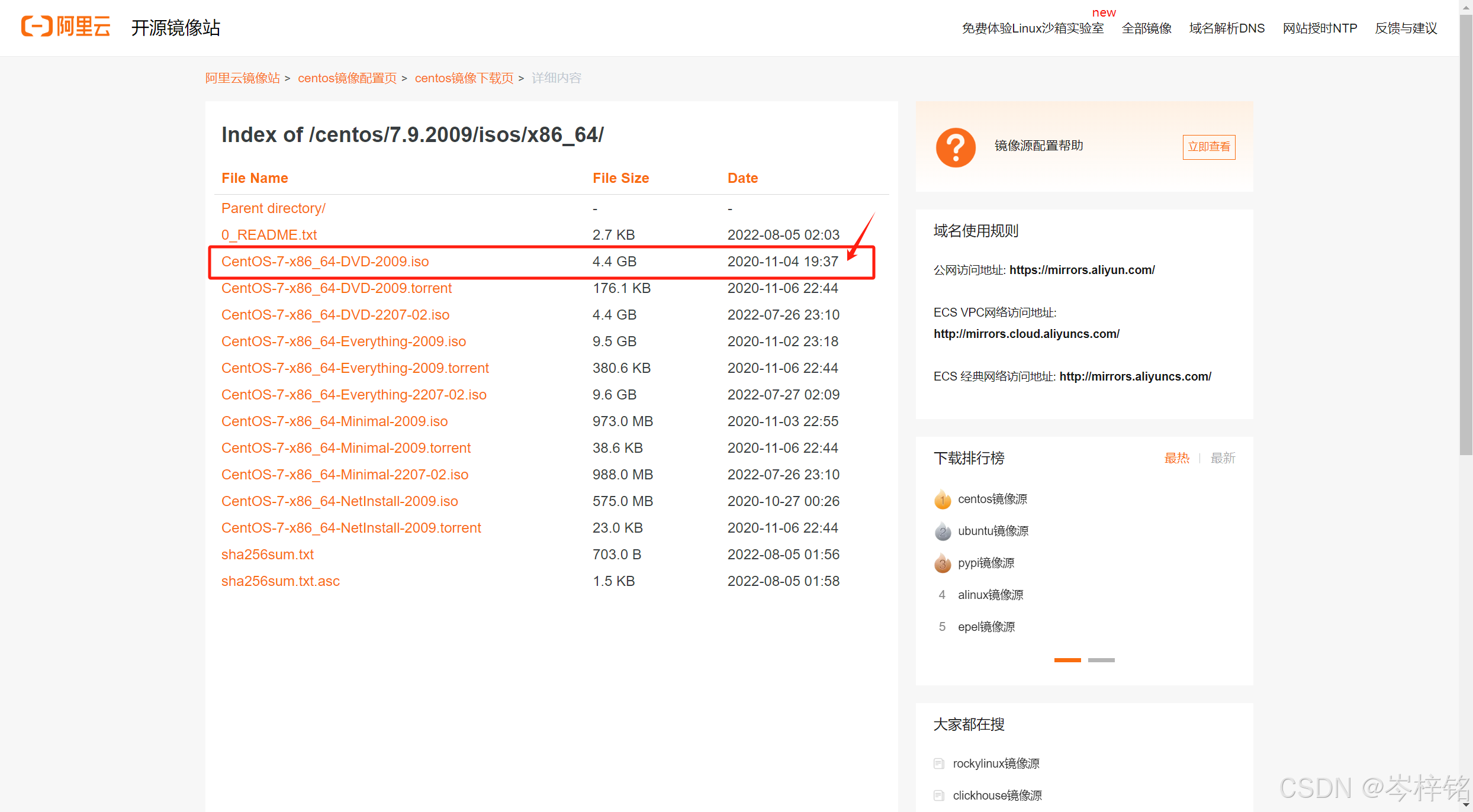
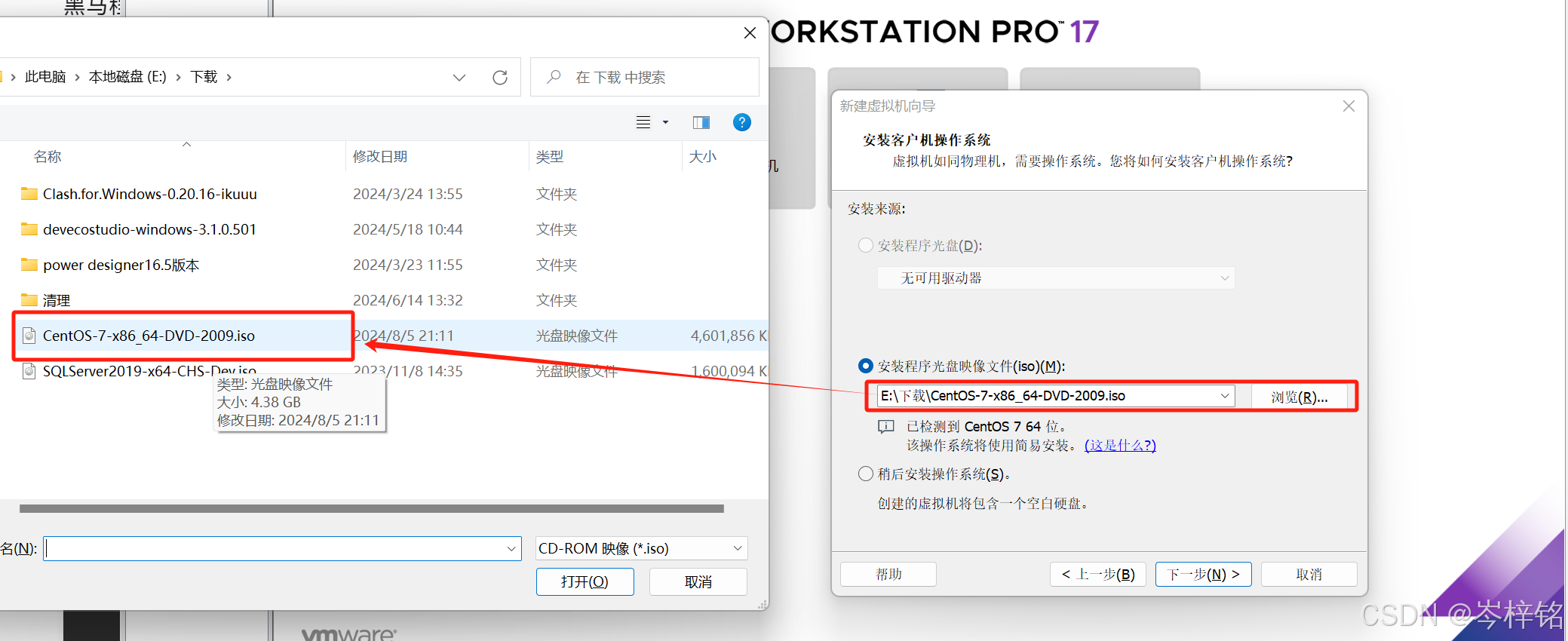
2)在VMware安装CentOs
然后跟上面安装Ubuntu的步骤一样,只不过是把“安装程序光盘映像文件”换成CentOs的
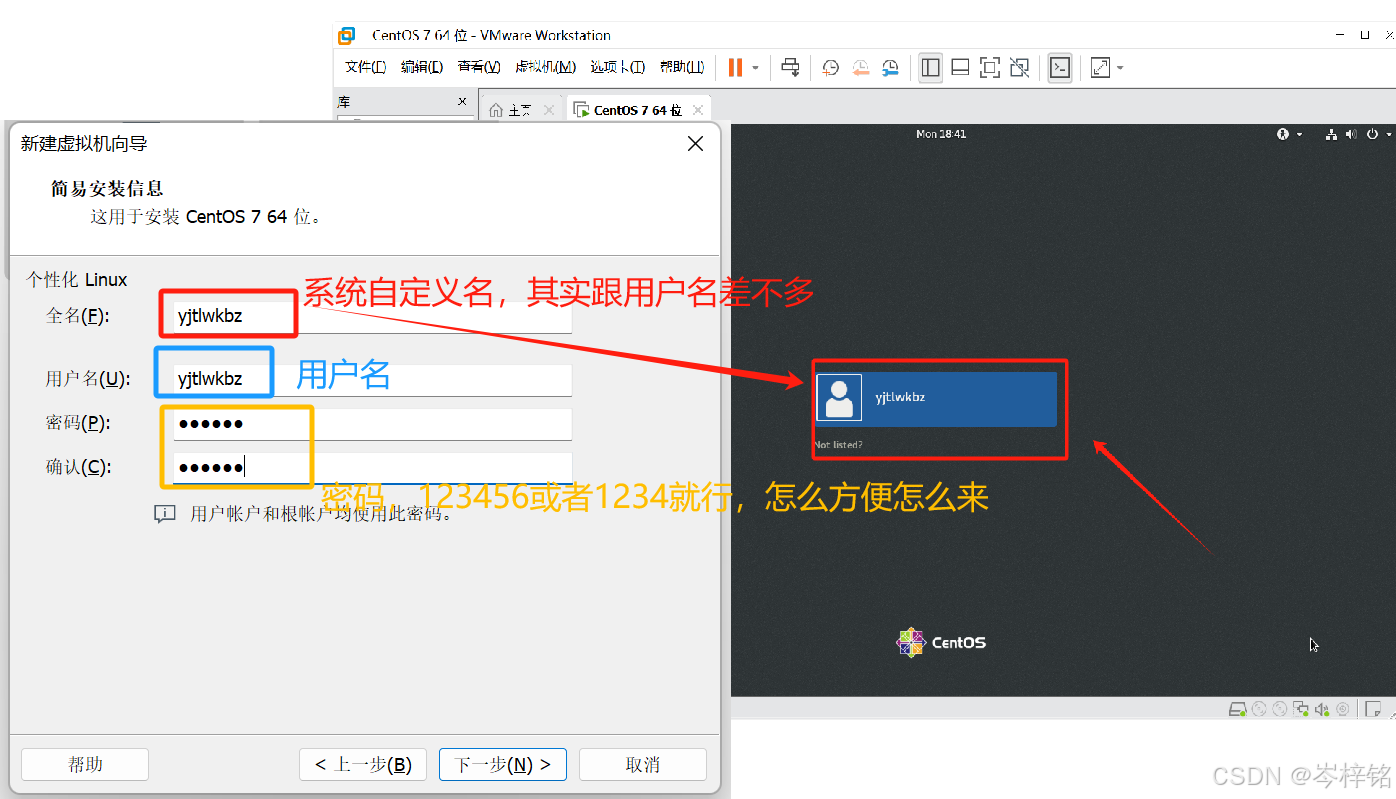


想关机的话就这样两种方式
四、FinalShell远程连接操作
那很多垃圾学校就不会教这个,比如我们学校,那么正常跟着老师课程来的同学们就可以跳过这一大点不看了,那么跟着网上视频或者自己自学的这些朋友们就留步,看一下这个是啥玩意。
我们知道不管是Ubuntu还是CentOs系统,都有方便我们观看使用的GUI图形化界面了,像个傻子一样点那些图标就行了,但是!作为程序员!我们不是傻子,我们迟早要用命令行来进行 “命令操作” 以代替 “用鼠标点点点”,然后有两种方式:1、在我们VMware虚拟机里打开对应虚拟机的终端,输出命令行; 2、用第三方软件FinalShell,远程连接上我们的Linux系统,然后统一用FinalShell输入命令来操作
简而言之,FianlShell就是一个远程操控我们虚拟机的Linux系统的第三方软件
1、下载
网址是:FinalShell SSH工具,服务器管理,远程桌面加速软件,支持Windows,macOS,Linux,版本4.5.9,更新日期2024.9.26 - FinalShell官网
2、安装
3、连接虚拟机的Linux系统
1)CentOs的连接
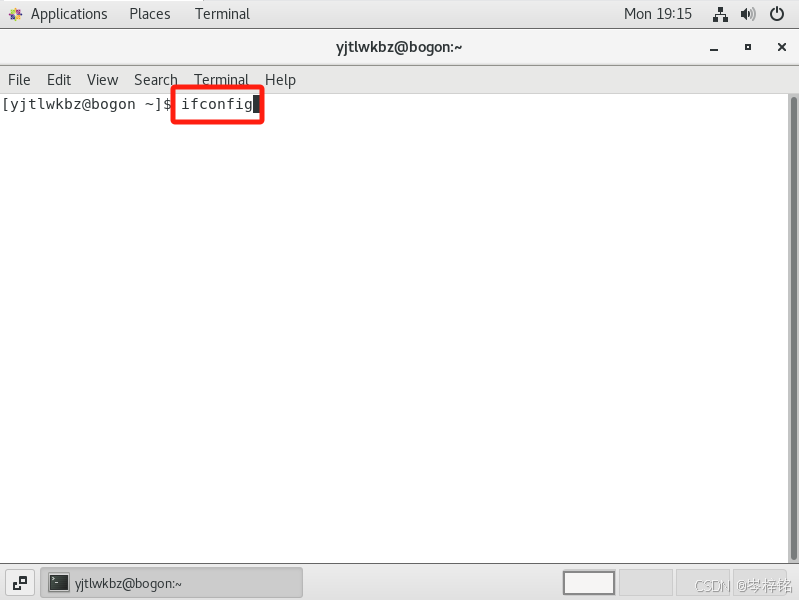
首先回到VMware的用了CentOs系统的虚拟机,右键点击【Open Terminal】,就是打开这个虚拟机的终端
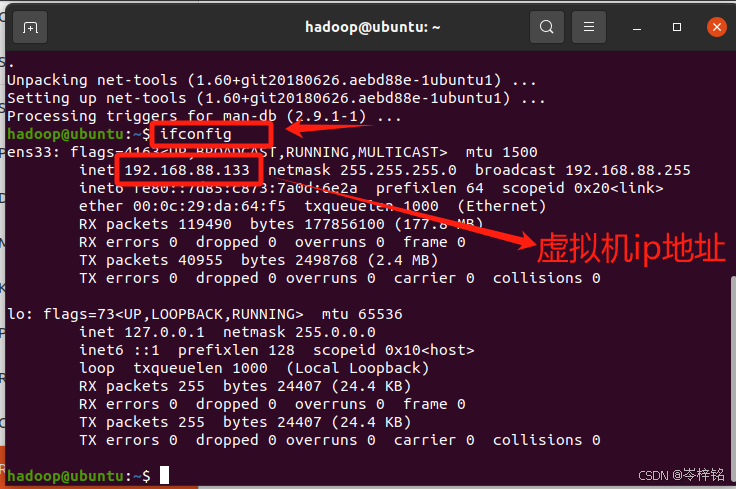
然后输入命令【ifconfig】,这个命令就类似window系统的ipconfig,就是查询这个虚拟机的ip地址
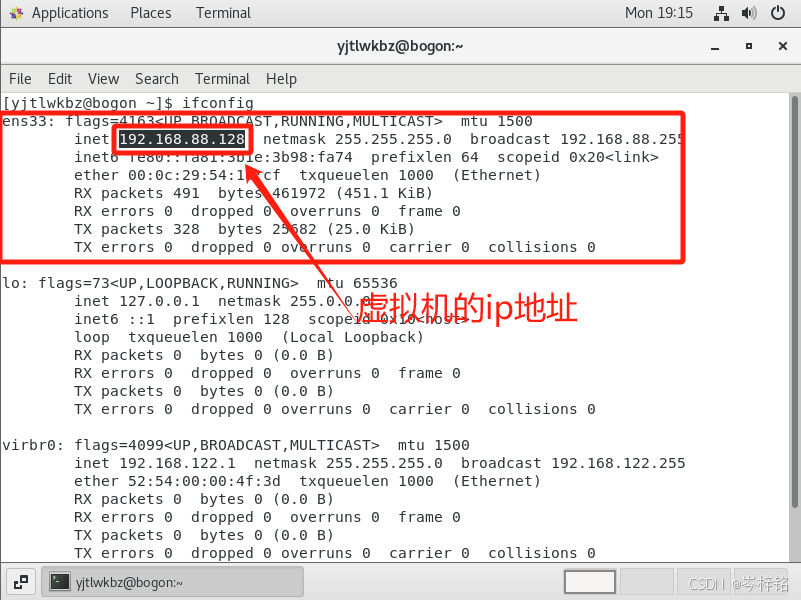
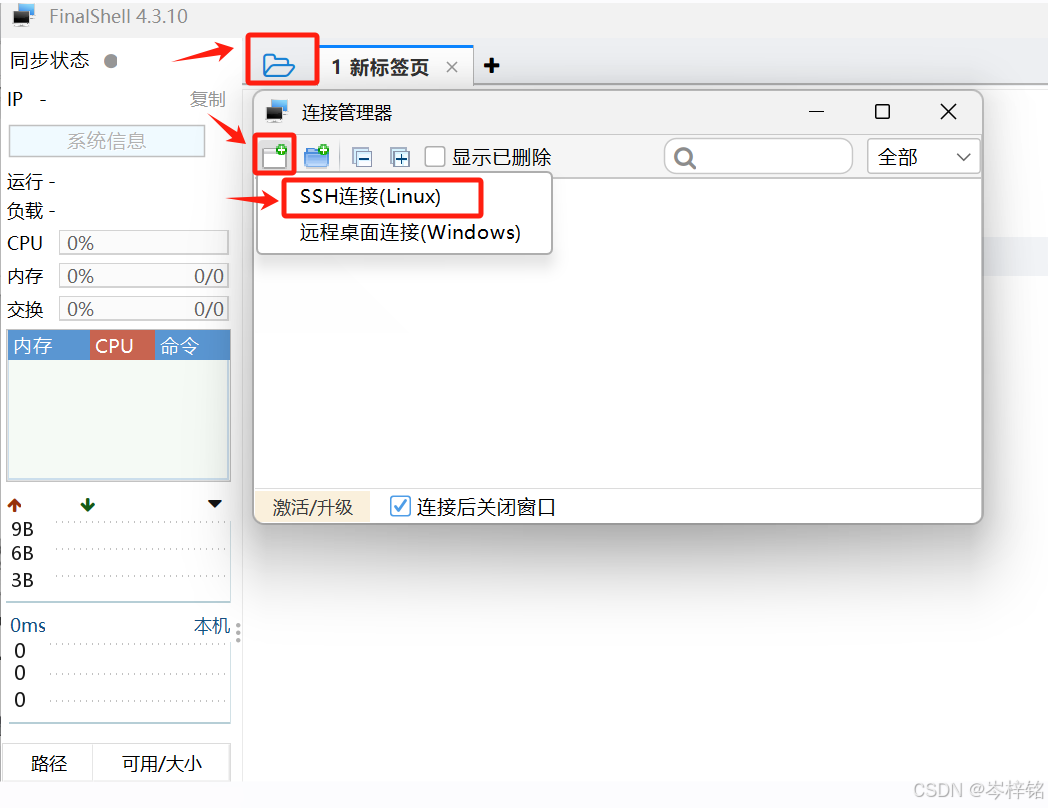
然后再打开FinalShell,点击左上角的“文件夹”小图标,然后再点击弹窗里左上角的小图标,点击【SSH连接(Linux)】
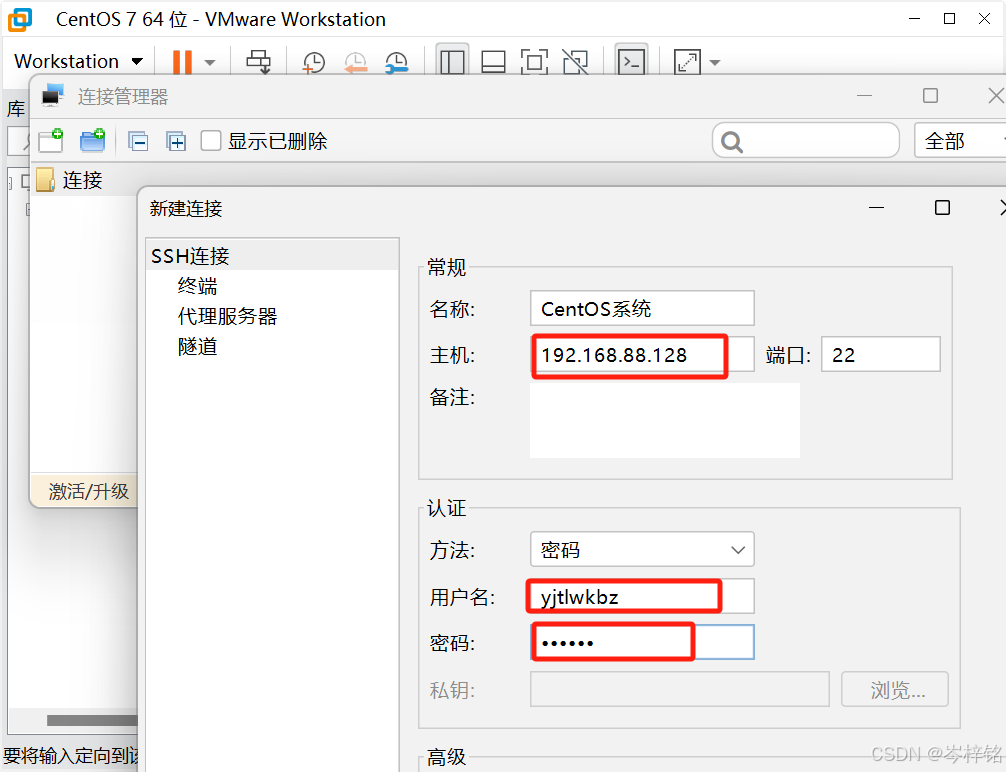
然后输入刚刚查到的虚拟机的ip地址,以及这个虚拟机的用户名、密码
创建成功后,就会显示在弹窗,此时我们双击它,就可以开始发起连接
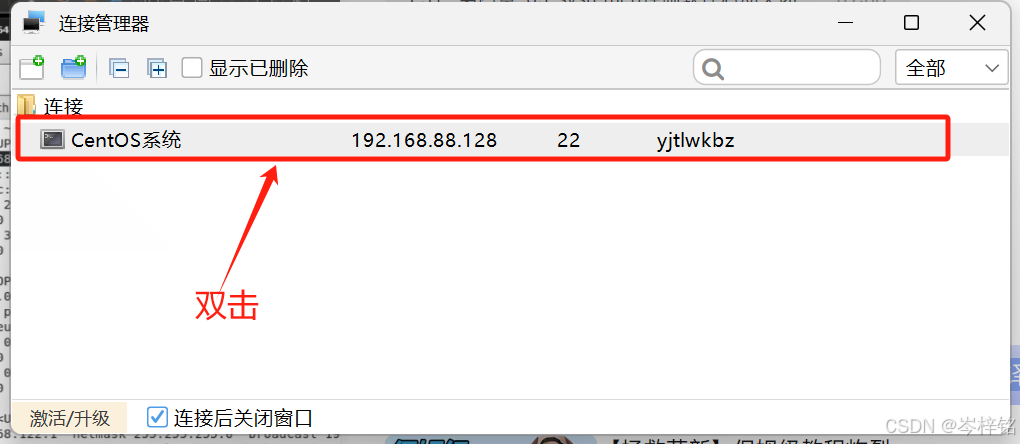
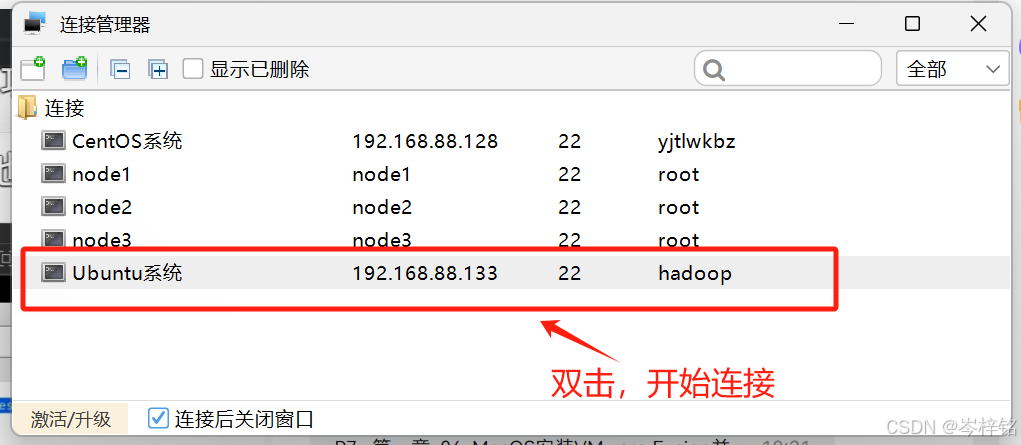
就会弹出弹窗,这是连接信息已经发送过来,我们只需要点击【接受并保存】
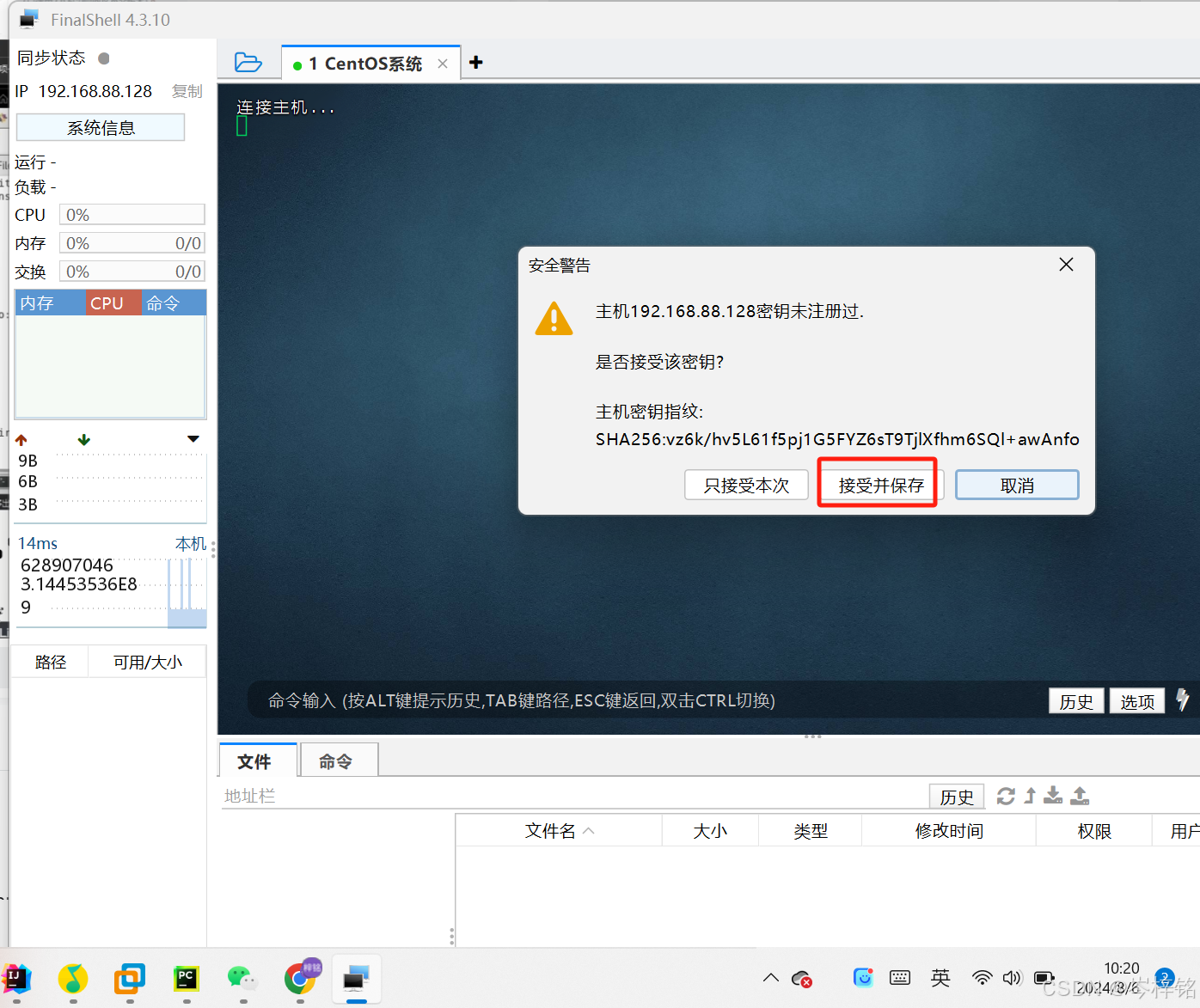
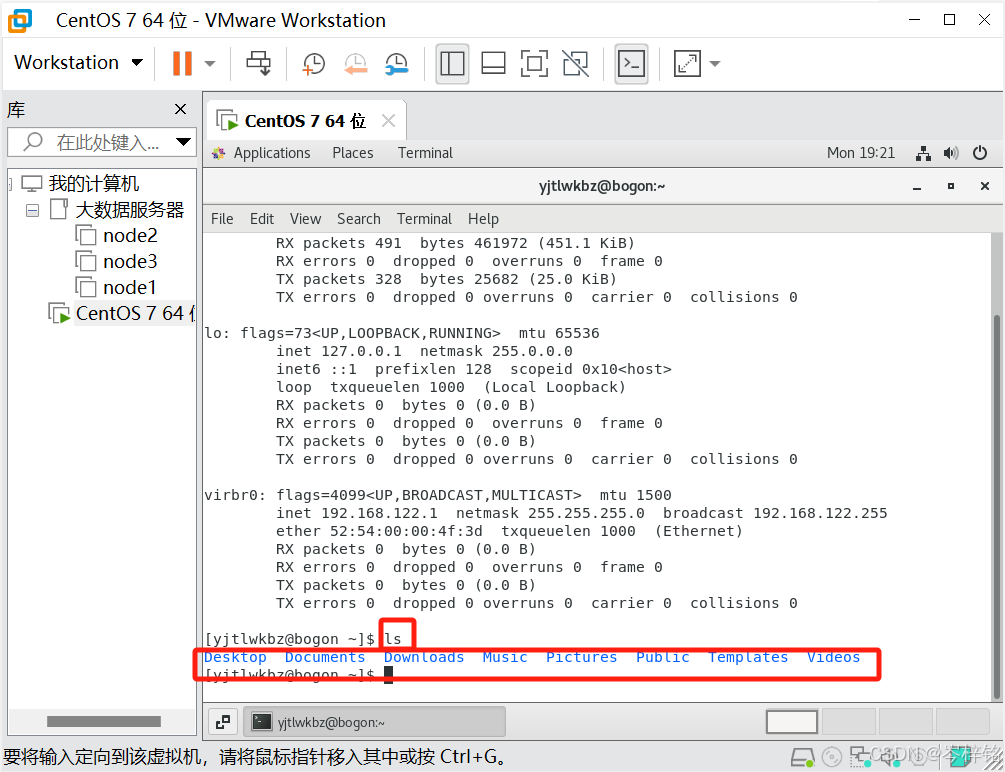
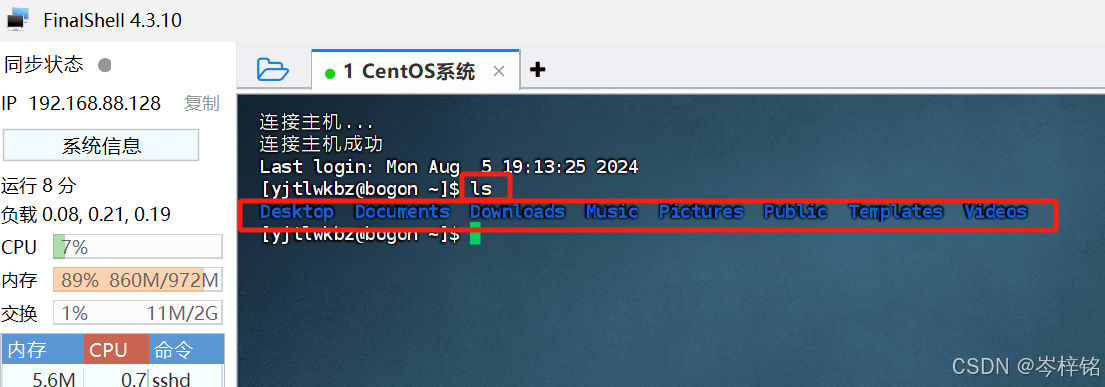
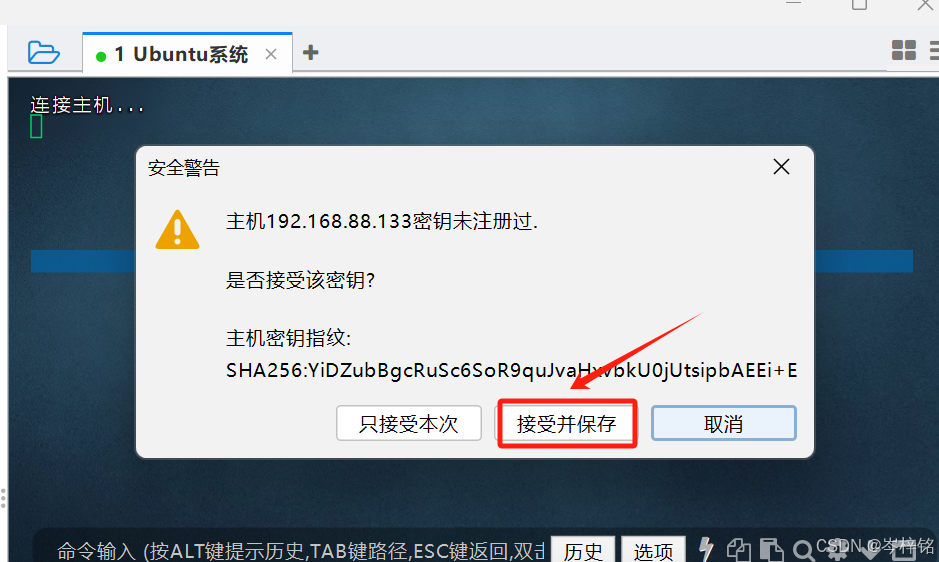
最后检测是否连接成功,分别在FinalShell跟VMware虚拟机中输入【ls】这个命令,如果返回的结果一样的话,就是连接成功
2)Ubuntu的连接
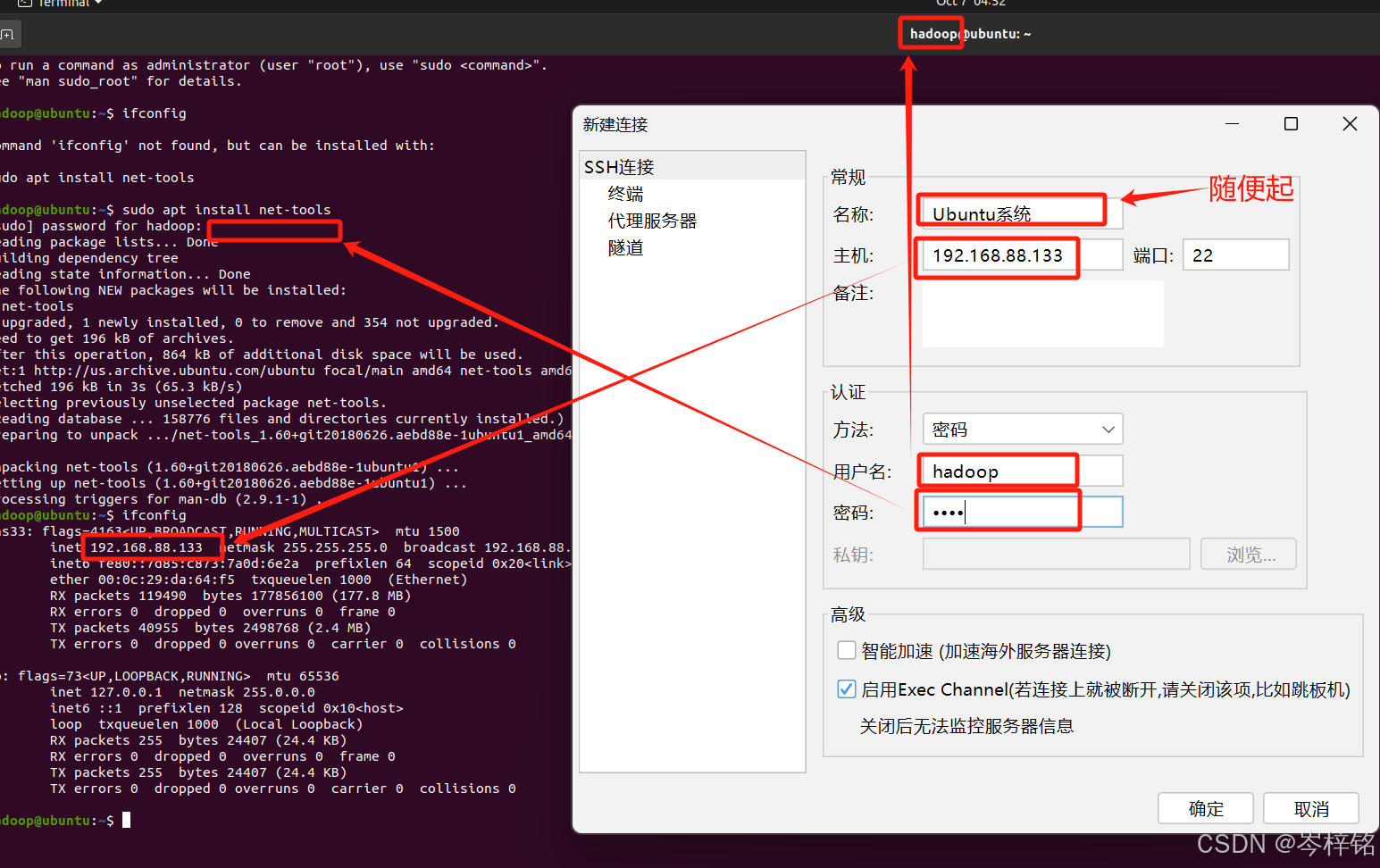
Ubuntu连接FinalShell有点不太一样,我们首先打开终端,输入【ifconfig】后提示:Command 'ifconfig' not found,but can be installed with:sudo apt install net-tools。表示刚安装的Ubantu系统中没有安装net工具包
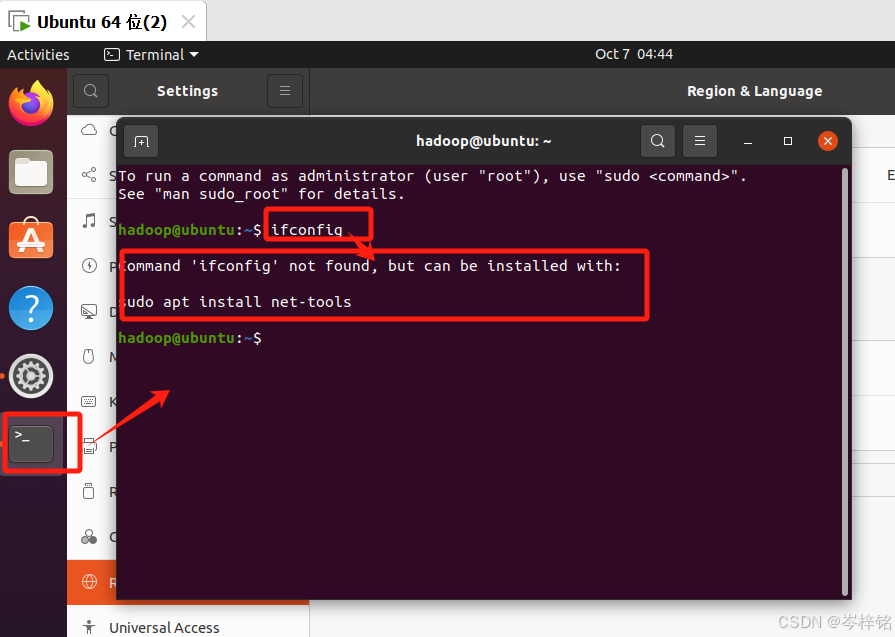
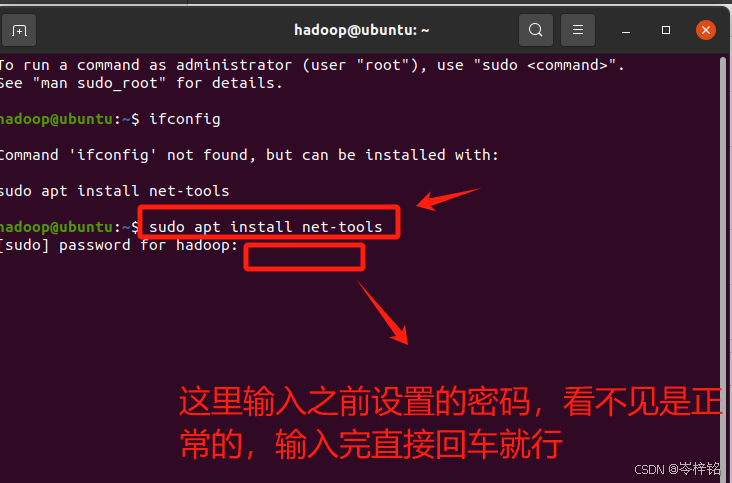
输入命令【sudo apt install net-tools】执行后即可安装
然后再输入ifconfig查看所有网络接口的信息
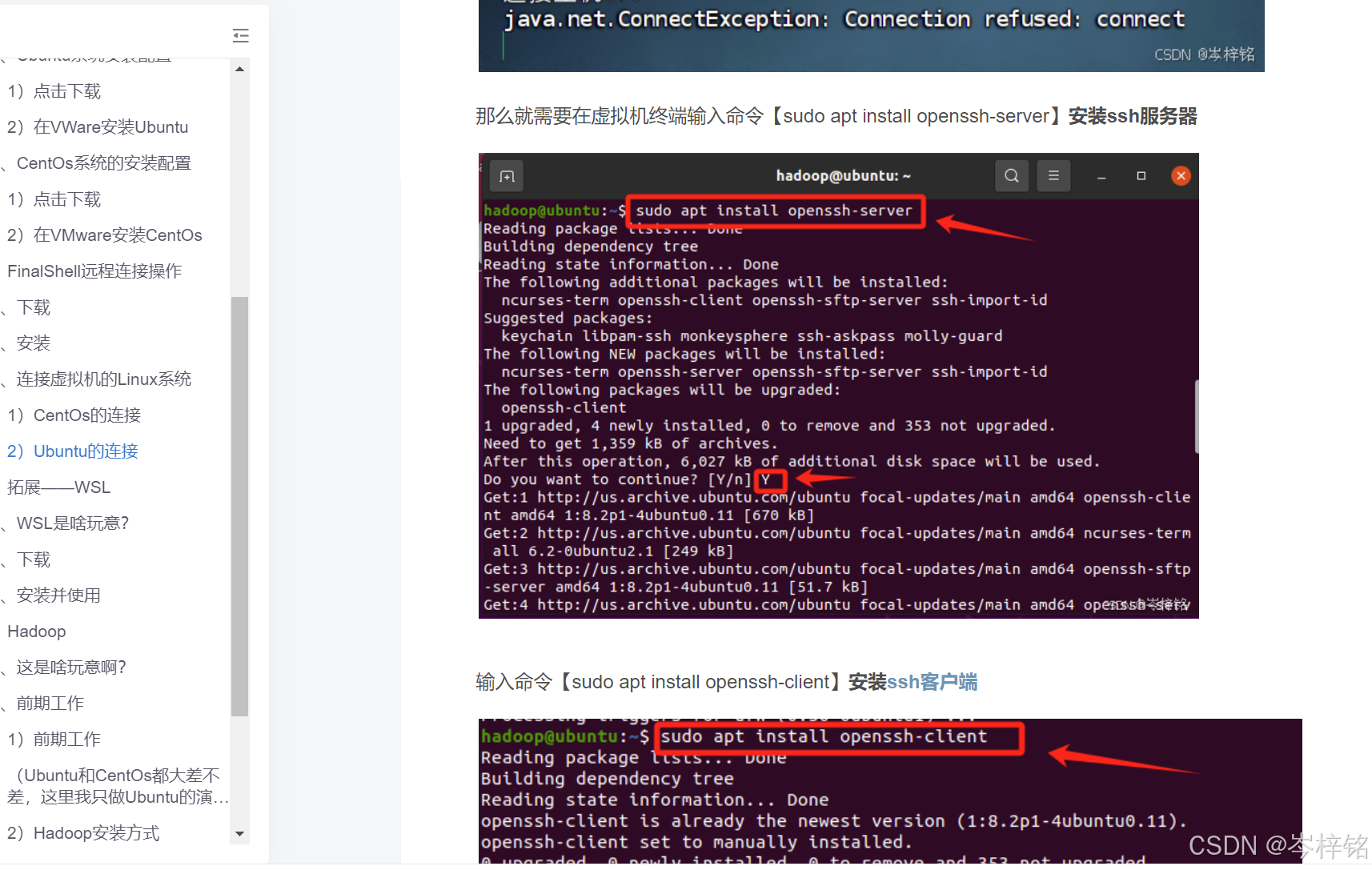
这时还没完!Ubantu一般会默认安装openssh-client,但是有的系统经常会未安装openssh-server。此时直接用FinalShell连接Ubuntu可能会连接失败。
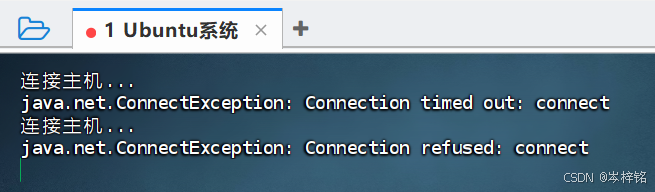
那么就需要在虚拟机终端输入命令【sudo apt install openssh-server】安装ssh服务器
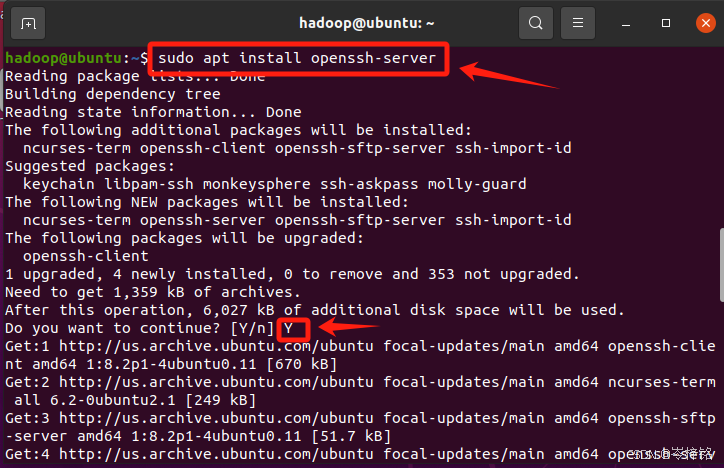
输入命令【sudo apt install openssh-client】安装ssh客户端
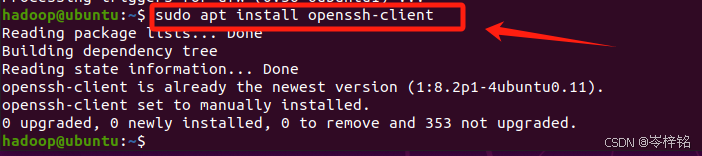
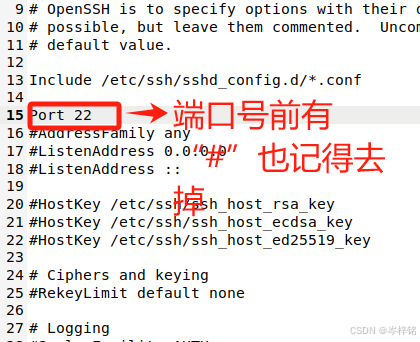
然后输入命令 【sudo gedit /etc/ssh/ssh_config】配置ssh客户端,去掉PasswordAuthentication yes前面的#号,以及端口号22前面可能有#,有的去掉。修改完后摁【Ctrl + S】保存后,点“叉叉”退出。

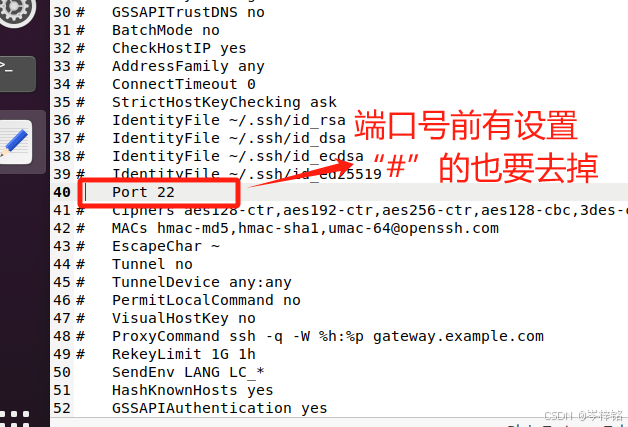

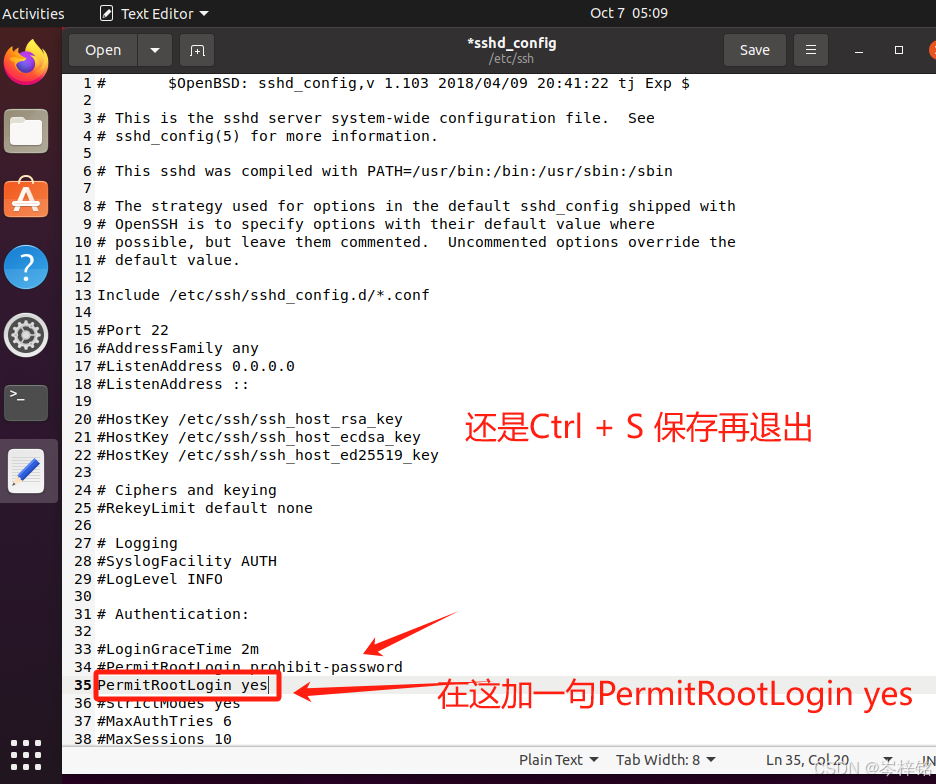
然后输入命令【sudo gedit /etc/ssh/sshd_config】配置ssh服务器,在PermitRootLogin prohibit-password加一句【PermitRootLogin yes】(加了这个后在finalshell等可以直接root连接虚拟机,用root连接才可以上传文件),以及端口号22前面可能有#,有的去掉。修改完后摁【Ctrl + S】保存后,点“叉叉”退出。

最后执行【sudo /etc/init.d/ssh restart】 重启ssh服务

然后现在,就是跟CentOs的操作一样
然后再打开FinalShell,点击左上角的“文件夹”小图标,然后再点击弹窗里左上角的小图标,点击【SSH连接(Linux)】
然后输入刚刚查到的虚拟机的ip地址,以及这个虚拟机的用户名、密码
创建成功后,就会显示在弹窗,此时我们双击它,就可以开始发起连接
然后就会弹出弹窗,这是连接信息已经发送过来,我们只需要点击【接受并保存】
最后检测是否连接成功,分别在FinalShell跟VMware虚拟机中输入【ls】这个命令,如果返回的结果一样的话,就是连接成功

五、拓展——WSL
这个也是一个拓展知识,很多学校百分之一百不会教,这也不是重点,但是越老越多现代开发者在逐步抛弃使用虚拟机来操作Linux操作系统的方法,而采用WSL操作Linux,那我们最好也学一下,以免跟时代落后了。

1、WSL是啥玩意?
那这到底是是个啥玩意?简单一句话:【就是在Window系统上直接安装并操作Linux系统】,你可以不再下载一堆什么傻鸟虚拟机之类的东西,直接安装Linux系统到你的电脑,然后在电脑终端输入命令行就可以用了。
那么这里我就只用Ubuntu这个Linux系统来进行演示了
2、下载

3、安装并使用
现在在准备安装之前,先做这么几个操作,【Win + R】,输入【optionalfeatures】
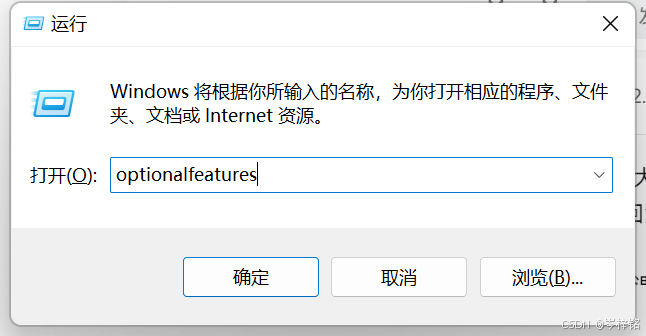
弹出这个窗口之后,勾上【适用于Linux得Windows子系统】和【虚拟机平台】两个选项
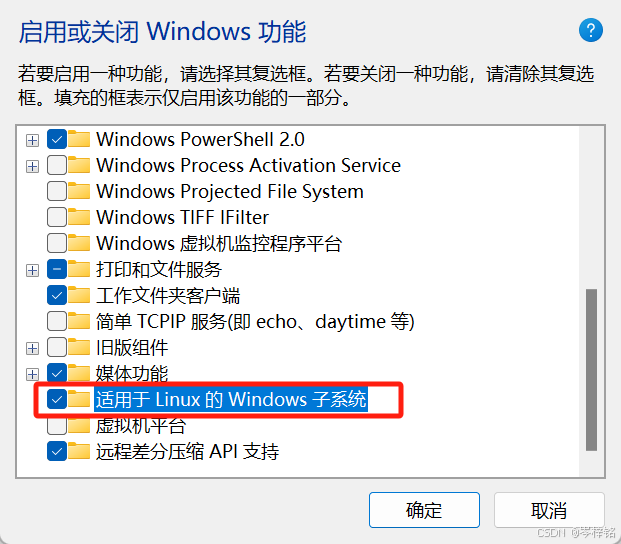
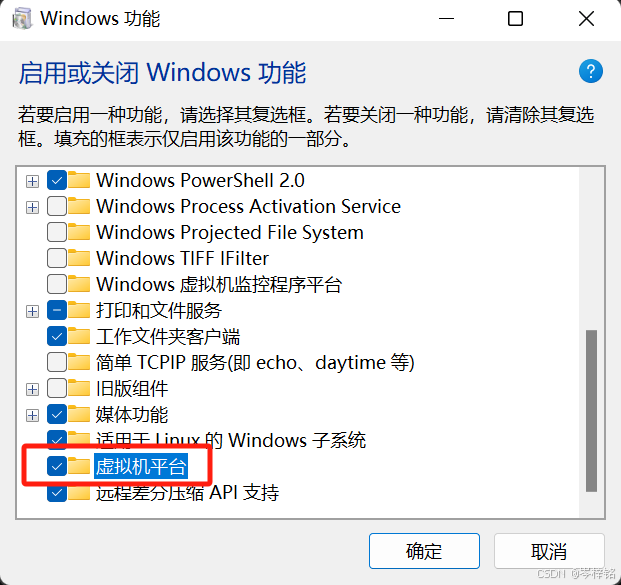
点击确定之后,会要你重启,你就直接耐心重启一下
最好执行一下这个命令
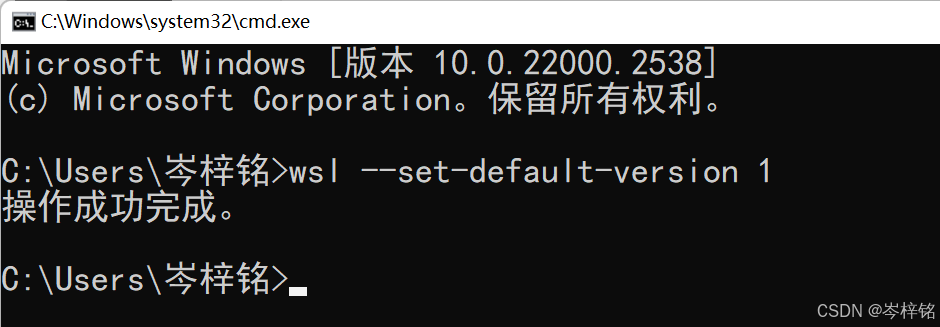
然后我们回到微软商店此时Ubuntu如果已经下载好了,点击【打开】就可以开始安装

然后安装好之后就会弹出一个弹窗
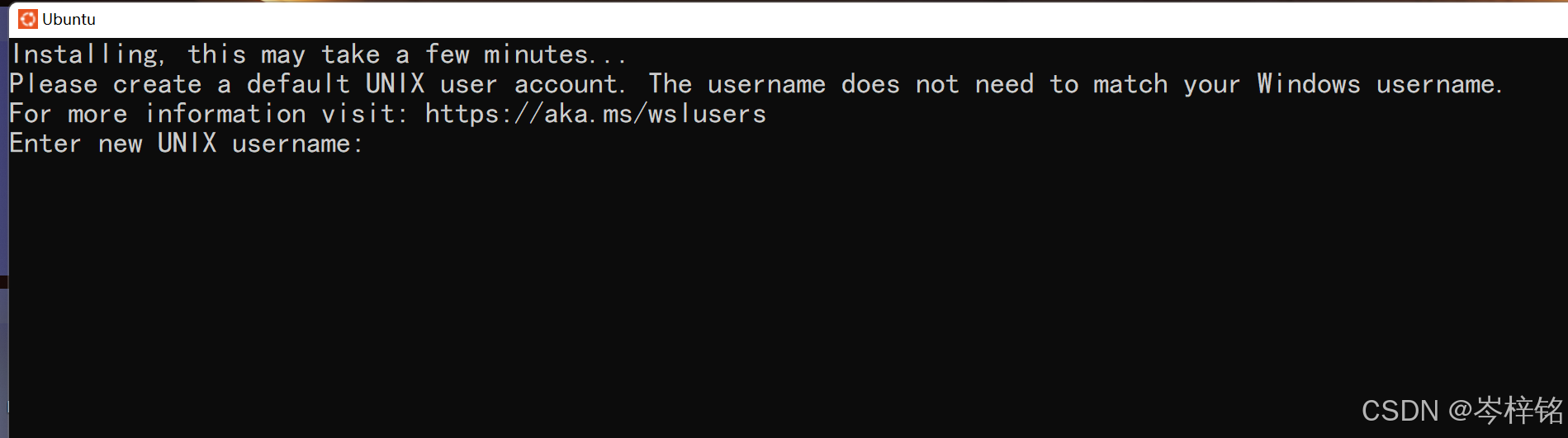
这里依次输入账号(username)、密码(password,记住密码那里输入东西看不见是正常的,你只管输入完按回车就行了),然后一直回车,然后就成功安装好一个Ubuntu系统到你的window系统里了
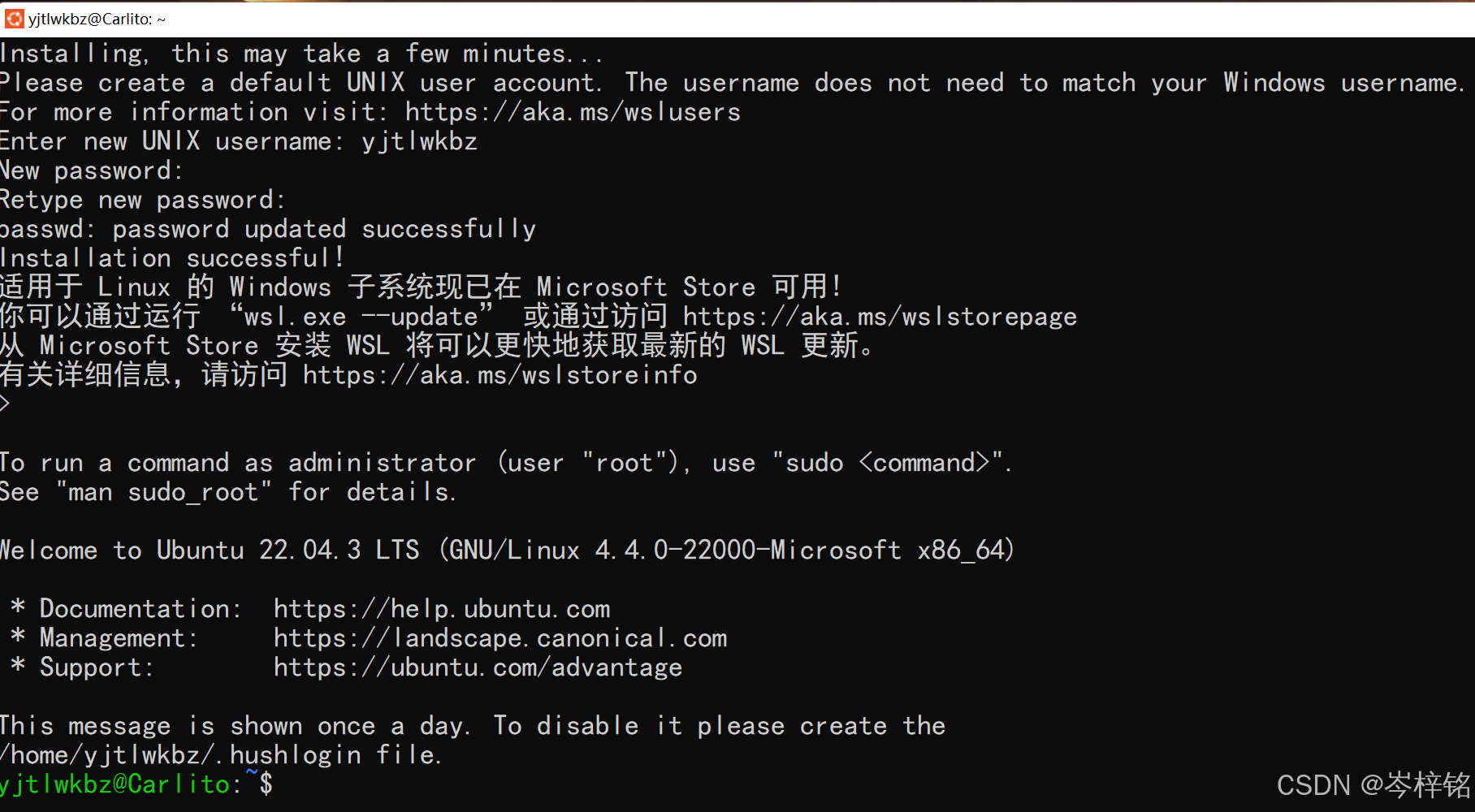
那么这就是一个没有图形化界面、纯命令行操作的页面了,以后我们想要打开这个窗口的时候,正常在window搜索Ubuntu就可以打开了
当然还有一种打开方式就是用我们window终端来操作Ubuntu
我们右键开始按钮,点击【Window终端】
点击下面图标

然后就可以获得window终端窗口样式的Ubuntu界面了
六、Hadoop
1、这是啥玩意啊?
Hadoop是Apache软件基金会开发的分布式系统基础架构,用以提供:
- 分布式数据存储
- 分布式资源调度
- 分布式数据计算
为一体的整体解决方案。
这【三个功能】对应Hadoop里的【三个核心组件】:


那么对于我们大数据学习者而言,Hadoop就是一款分布式大数据操作的软件,它跟springboot、vue、pytorch这些一样,就是一个架构、一个框架,别人写好了底层代码我们直接用。
然后它可以部署到1台或者多台服务器节点上共同工作,个人或企业利用Hadoop就可以构建大型的服务器集群,完成海量的数据存储和计算。
【拓展(大数据方向面试会问到的内容)】
Hadoop1、Hadoop2、Hadoop3的版本发展变化:

2、前期工作
1)前期工作
(Ubuntu和CentOs都大差不差,这里我只做Ubuntu的演示,因为要应付作业)
【这一步选做,可有可无,有的话以后方便点】
首先我们下载一些基本配置,好方便我们后续操作
首先我们配置一下Ubuntu下载的镜像地址,这可以方便我们之后下载安装别的工具快一点







接下来是两个方式来进行你自己物理计算机跟虚拟机之间文件传输的办法:
- 1、你可以采用安装【VMtools】来进行一个计算机跟虚拟机之间复制粘贴的操作
- 2、你也可以开启【共享文件夹】来指定虚拟机和计算机的某个文件夹之间进行文件共享传输
【方法一】
安装VMtools,这个软件可以帮助我们将物理计算机跟虚拟机之间进行文件传输
首先如果你的vmware里点击上面【虚拟机】有这个【安装VMware Tools(T)】你就点他
如果跟我一样是灰色的没法点,那么右键你的虚拟机,点击【设置】,记得给虚拟机先关机!!!
点【CD/DVD】,然后点【使用ISO映像文件】
然后导入【linux.iso】这个文件,这个文件在你安装VMware这个软件的目录的根目录下
然后点到【选项】,点【VMware Tools】勾选【将客户时间与主机同步】
然后重启虚拟机,就能看到多了一个光盘
打开光盘文件,其中有一个名为 VMwareTools…tar.gz 的压缩包,将这个压缩包移动到你想解压的目录(例如 /home/Documents/VMTools)
然后点击这个压缩包,右键选择“extract here”解压到当前目录
然后进入到 vmware-tools-distrib 目录,右键点【Open in Terminal】用终端打开
输入 sudo ./vmware-install.pl 回车,接着就是输入 yes 再一直回车了。
然后再重启虚拟机,就发现可以直接复制粘贴了













【方法二】
点击【设置】,点击【选项】,点击【共享文件夹】,然后勾选【总是启用】
;
然后在下面添加你要共享的文件夹在计算机哪个位置
;
这里建议大家创建一个教【shared_folders】的文件夹,专门用于与虚拟机共享的
;
然后,【Ctrl + Alt + T】打开虚拟机的终端,输入【ls /mnt/hgfs】就能看到我们共享的那个文件夹
这个命令的意思就是【列出根目录下/mnt目录下/hgfs目录下的所有文件】,我们的共享文件夹就是在Linux系统里的这个地方
;
如果没有,就说明共享文件夹失败,就可能是跟Linux系统的Open-VM-Tools的安装和配置有关
首先执行输入【sudo apt-get install open-vm-tools-dkms】安装Open-VM-Tools
然后执行这个命令【sudo vim /etc/systemd/system/mnt-hgfs.mount】
如果报错:sudo: vim: command not found,就说明系统缺少
vim编辑器,而sudo命令需要用到编辑器来编辑文件执行下面两个命令安装vim
sudo apt-get update sudo apt-get install vim然后再执行【sudo vim /etc/systemd/system/mnt-hgfs.mount】
然后就会跳转到vim编辑器,这是一个执行sudo命令的地方
进去之后,先摁【i】进入编辑模式(否则摁 什么键盘都无效),然后将这段命令复制粘贴进去
[Unit] Description=VMware mount for hgfs DefaultDependencies=no Before=umount.target ConditionVirtualization=vmware After=sys-fs-fuse-connections.mount [Mount] What=vmhgfs-fuse Where=/mnt/hgfs Type=fuse Options=default_permissions,allow_other [Install] WantedBy=multi-user.target然后摁【Esc】退出编辑模式,然后直接输入【:wq】保存,摁下【回车】退出
ss
最后执行下面两句命令,开启共享文件夹服务
sudo systemctl enable mnt-hgfs.mount sudo systemctl start mnt-hgfs.mount重现检查【ls /mnt/hgfs】,就会发现有了共享文件夹





3、Hadoop安装方式
这里推荐一篇最完整的厦门大学大数据Hadoop安装教程参考:大数据技术原理与应用 第二章 大数据处理架构Hadoop 学习指南_厦大数据库实验室博客
Hadoop的安装方式有三种,分别是单机模式,伪分布式模式,分布式模式。
- 单机模式:单机模式:Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
- 伪分布式模式:Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
- 分布式模式:使用多个节点构成集群环境来运行Hadoop。
1)单机和伪分布式安装方式(也就是在一台虚拟机安装)
根据厦门大学hadoop安装教程是:
- 如果系统是Linux,请参照下面给出的教程进行安装:
在Ubuntu系统上安装Hadoop请参考:
(1)《大数据技术原理与应用(第2版)》教材请参考: Hadoop安装教程-单机-伪分布式配置-Hadoop2.6.0(2.7.1)-Ubuntu14.04(16.04)
(2)《大数据技术原理与应用(第3版)》教材(已经在2020年12月出版,教材官网)请参考:Hadoop安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04)在CentOS系统上安装Hadoop请参考:
Hadoop安装教程-伪分布式配置-CentOS6.4-Hadoop2.6.0需要注意以下几点:
系统用户名使用hadoop
不要修改/etc/hosts 默认的localhost地址,如果已经修改请重新把127.0.0.1映射到localhost如果系统是Mac,请参照下面给出的链接进行安装:
Mac 安装Hadoop教程-单机-伪分布式配置
【首先创建hadoop用户】
如果你安装 Ubuntu 的时候不是用的 "hadoop" 用户,那么需要增加一个名为 hadoop 的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m hadoop -s /bin/bash(这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。)
【拓展】
Ubuntu终端复制粘贴快捷键: 在Ubuntu终端窗口中,复制粘贴的快捷键需要加上 shift,即粘贴是 ctrl+shift+v。
接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
sudo adduser hadoop sudo最后注销当前用户(点击屏幕右上角的齿轮,选择注销),返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
【更新apt】
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
sudo apt-get update 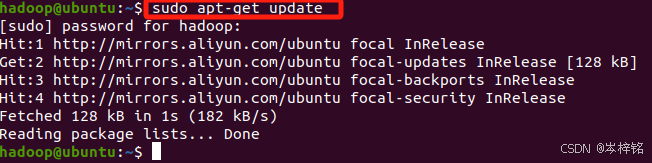
那么如果跟着我教程第六大点的第(1)点“前期准备”走的话,这里就能很快执行完毕,因为我们的安装源用的是国内的镜像源很方便。那如果不是的话,怕安装的慢的话,就还请回到第六大点的第(1)点“前期准备”完成步骤

另外我在第六大点的第(1)点“前期准备”也教大家下载配置了vim编辑器,没有安装的也请执行如下命令再执行一次,因为以后的sudo命令都要用到vim编辑器。

【安装SSH、配置SSH无密码登陆】
前面我也在第四大点的第3小点讲述了要在Ubuntu系统安装SSH的步骤,如果跳过了的话,还请返回看一下(就是执行一下【ssh localhost】这个命令)

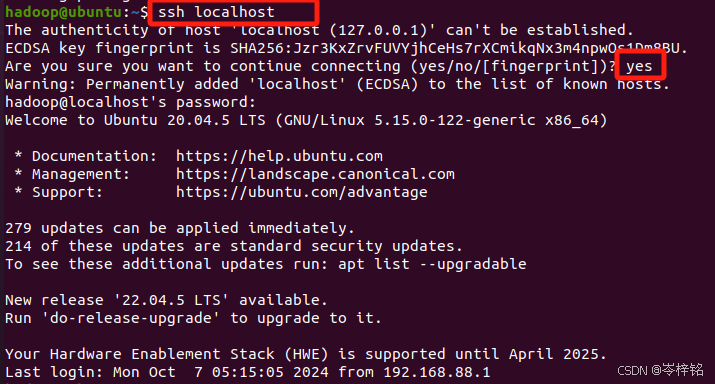
然后安装后,可以使用如下命令登陆本机:
ssh localhost此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:(一条一条的执行)
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权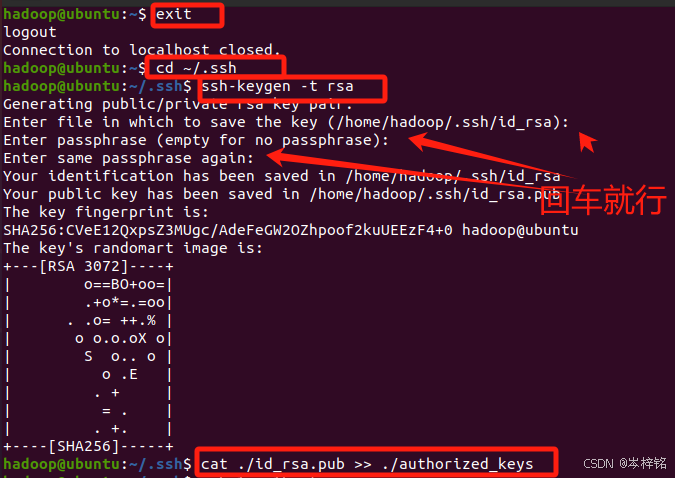
此时再用 【ssh localhost】 命令,无需输入密码就可以直接登陆了,如下图所示。

【安装Java环境】
需要按照下面步骤来自己手动安装JDK1.8。
我们已经把JDK1.8的安装包jdk-8u162-linux-x64.tar.gz放在了百度云盘
通过网盘分享的文件:jdk-8u162-linux-x64.tar.gz
链接: https://pan.baidu.com/s/1dRVkEHh8afHsdS3CAQFjQg?pwd=4zgt 提取码: 4zgt

在Linux命令行界面中,执行如下Shell命令(注意:当前登录用户名是hadoop):
(Linux基础:cd就是进入某个目录,“ / ”是Linux系统的主目录,一般我们在文件夹看不到这一层,只能看到用户主目录“ home ”,下面命令的意思就是【进入根目录下的usr目录下的lib目录】)
cd /usr/lib(这一条命令就是:在刚刚进入的【/usr/lib】目录下创建【jvm】目录,用来存放JDK文件)
sudo mkdir jvm然后,我们刚刚在物理计算机window系统下已经把刚刚百度网盘的JDK文件下载好了,两种方法可以让我们的虚拟机的Ubuntu系统也能用
【方法一】就是用我们前期准备安装好的VMtools把文件直接复制粘贴进【/usr/lib/jvm】来
【方法二】开启了共享文件夹的话,就可以放到我们window系统下的那个【shared_folder】,这样我们在虚拟机的Ubuntu系统也就能看到了
然后注意,我们的共享文件夹在【/mnt/hgfs】目录下,然后不管用方法一还是方法二,最终都是要把JDK文件放到【/usr/lib/jvm】这层目录下
但是这一层目录一般虚拟机看不见,我们只能看到用户主目录【home】。
要点下面的【+ Other Locations】,再点【Computer】,这才是Linux系统的【/】根目录,相当于window系统的【我的电脑】

这里还有一个问题就是,移动压缩文件并解压也有很多方法,如果你采用将home目录的文件先复制粘贴移动到根目录,再在根目录里解压的话,就是这样:
我们创建虚拟机的时候会发现,设置用户名那里不能用【root】这个名字,是因为所有Linux的管理员就是root,一般用户没有权限进入修改【Computer】这个Linux系统的【根目录】内容,所以我们需要先修改一下权限,执行以下命令切换权限
sudo -i
然后不管是用【方法一】还是【方法二】,你都要用【cd命令】找到这个文件,可以一级一级的往下找,用【ls命令】检查这集目录下的所有文件,直到找到JDK文件的地方
使用【cp命令】进行复制粘贴,【cp [文件] [要粘贴到的地方]】
cp [文件] [要粘贴到的地方]
然后在这个目录将JDK压缩包解压(记住,一定要解压到【/usr/lib/jvm】这个目录)
sudo tar -zxvf [压缩包名字]










除了上面的方法,还有一种方法更为便捷,执行下面这种指令
sudo tar -zxvf [该文件的绝对路径或相对路径] -C [你想解压的地方] # 比如:sudo tar -zxf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm
这样就直接免去一大堆步骤了,一步到位

接下来执行下面两个命令,设置环境变量
cd ~ vim ~/.bashrc
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc

这时,可以使用如下命令查看是否安装成功:
java -version如果能够在屏幕上返回如下信息,则说明安装成功:

【安装hadoop】
同理我们可以去官网下载:Apache Hadoop



当然官网的速度可能会很慢,也可以去这个百度网盘下载
通过网盘分享的文件:hadoop-2.7.1.tar.gz
链接: https://pan.baidu.com/s/1TAH7ZDvGGQWIn6lh9tOpSw?pwd=455g 提取码: 455g

同理,在电脑window下载好之后,不管是放那个共享文件夹里,或者自己手动用VMtools复制粘贴进虚拟机Linux系统,最终都是要解压到根目录【/usr】这个目录里的其中一个目录下
然后记住区别就是:
JDK是解压到【/usr/lib/jvm】,Hadoop是解压到【/usr/local】
然后为了方便演示,我就直接进入到虚拟机把它拖到【Downloads】下载目录,然后进入到【home/Dowloads】这层目录,从这开始将这个文件路径直接一次性解压到
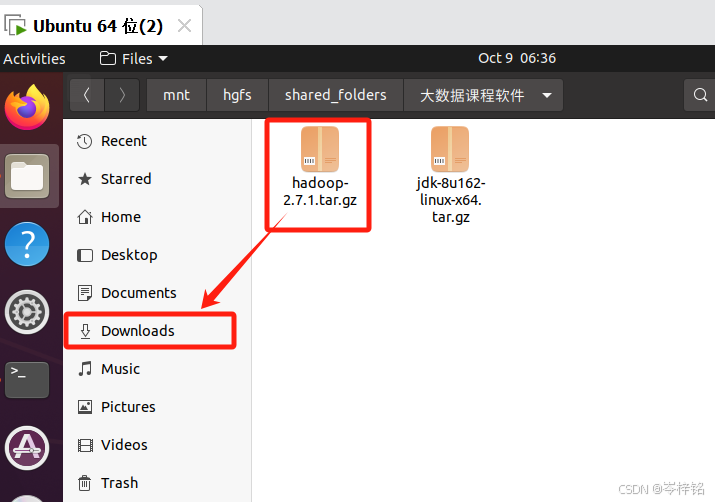
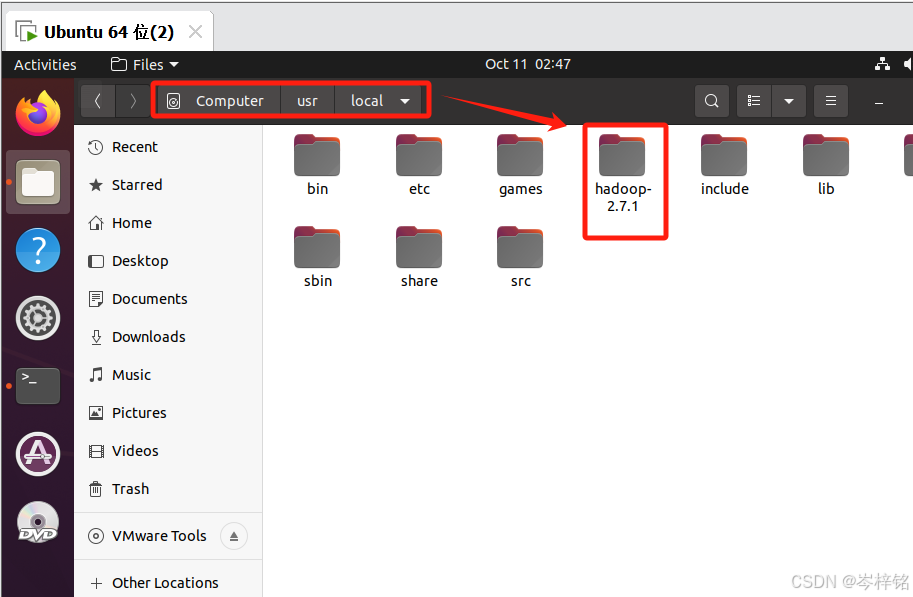
然后执行下面命令直接把hadoop压缩包解压到【/usr/local】
sudo tar -zxf [hadoop文件的绝对或相对路径] -C [要解压到的地方]
# 比如:sudo tar -zxf ~/Downloads/hadoop-2.7.1.tar.gz -C /usr/local
然后就能看到解压成功
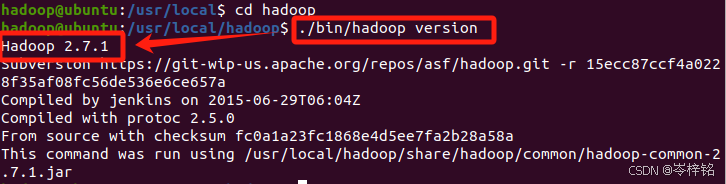
然后进入【/usr/local】目录,给它改一下文件名字
sudo mv ./hadoop-2.7.1/ ./hadoop![]()

2)分布式安装方式
(1)在集群上分布式安装Hadoop,请参考:
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS(2)使用Docker搭建Hadoop分布式集群,请参考实验室博客文章《使用Docker搭建Hadoop分布式集群》。
到此为止,Hadoop的安装指南已经结束,如果想学习第3章《Hadoop文件系统》,请参考第3章的学习指南:
大数据技术原理与应用 第三章 学习指南
(留白)暂时先不更新,内容比较多,后期再更新。
4、Hadoop配置
1)单机和伪分布式配置
【单机模式】:Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
【伪分布式】:Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于【/usr/local/hadoop/etc/hadoop/】 中,伪分布式需要修改2个配置文件 【core-site.xml】 和 【hdfs-site.xml】 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
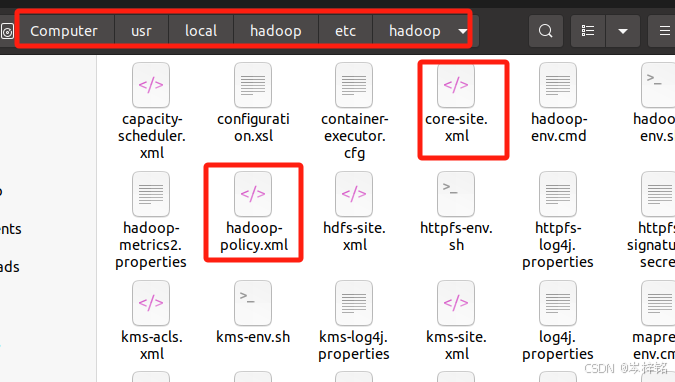
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便,执行下面命令)
gedit ./etc/hadoop/core-site.xml

将当中的<configuration></configuration>修改
配置下面代码进去(记住!不要擅自修改空格、缩进,一个空格字符都会导致失败,直接粘贴进去)
<property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property>


同样的,修改配置文件 hdfs-site.xml:
gedit ./etc/hadoop/hdfs-site.xml
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property>


(解释,可看可不看,没啥大碍)
Hadoop配置文件说明:
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop ./bin/hdfs namenode -format
成功的话会显示


接着开启 NameNode 和 DataNode 守护进程。这个命令就是一键启动整个Hadoop
cd /usr/local/hadoop ./sbin/start-dfs.sh
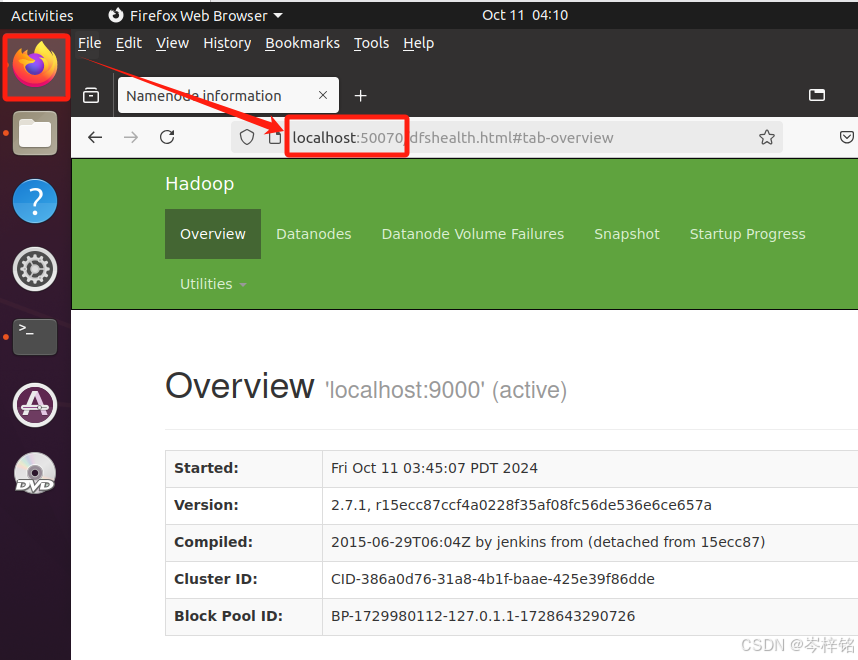
【拓展】



反正记住,从此之后你就配好了hadoop,每次想要开启都要手动输入【./start-all.sh】来开启,开启之后,就可以打开虚拟机自带的火狐浏览器,输入这个网址验证hadoop是否开启了:【http://localhost:50070】
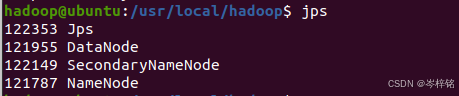
执行【jps】也能看到对应的节点信息
2)分布式配置
参考: (留白)暂时先不更新,内容比较多,后期再更新。
在平时的学习中,我们使用伪分布式就足够了。如果需要安装 Hadoop 集群,请查看Hadoop集群安装配置教程。
相关教程
- 使用Eclipse编译运行MapReduce程序: 使用 Eclipse 可以方便的开发、运行 MapReduce 程序,还可以直接管理 HDFS 中的文件。
- 使用命令行编译打包运行自己的MapReduce程序: 有时候需要直接通过命令来编译、打包 MapReduce 程序。
参考资料
- Apache Hadoop 3.3.6 – Hadoop: Setting up a Single Node Cluster.
- Hadoop集群(第5期)_Hadoop安装配置 - 虾皮 - 博客园
- Hadoop2.x在Ubuntu系统中编译源码 | micmiu - 软件开发+生活点滴










![[M数学] lc3164. 优质数对的总数 II(因数分解+倍增+推公式+思维+好题)](https://i-blog.csdnimg.cn/direct/195a6679824f4ce185cdc166dc73c808.png)




![【三】【算法】P1007 独木桥,P1012 [NOIP1998 提高组] 拼数,P1019 [NOIP2000 提高组] 单词接龙](https://i-blog.csdnimg.cn/direct/a00d137520a84858bc42d8846efa820b.png)