前言
以<深入理解计算机系统>(以下称“本书”)内容为基础,对程序的整个过程进行梳理。本书内容对整个计算机系统做了系统性导引,每部分内容都是单独的一门课.学习深度根据自己需要来定
引入
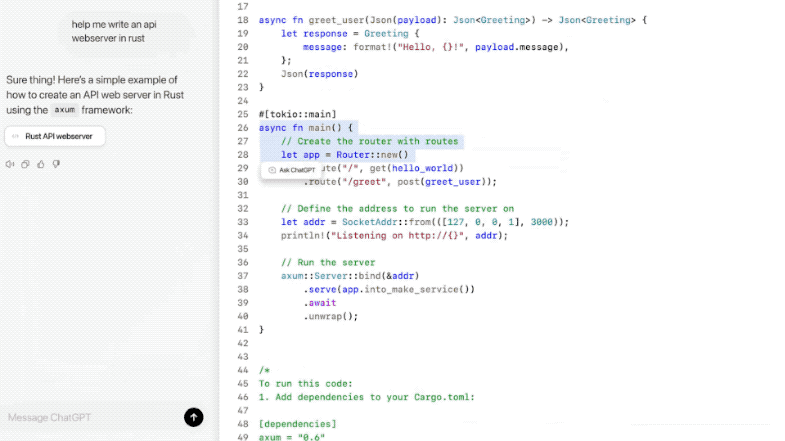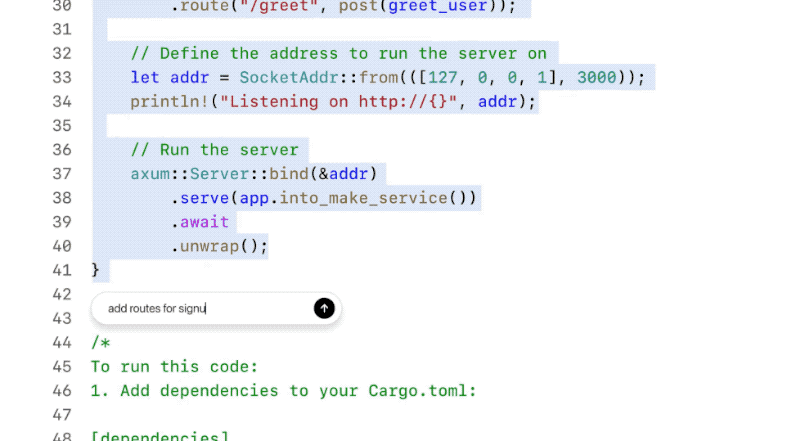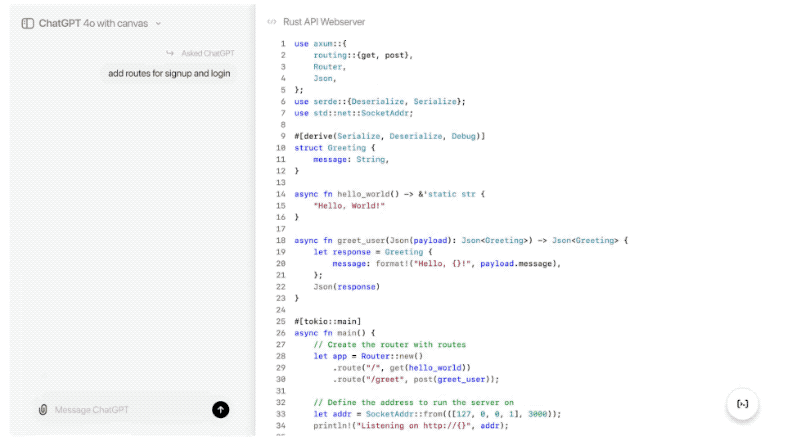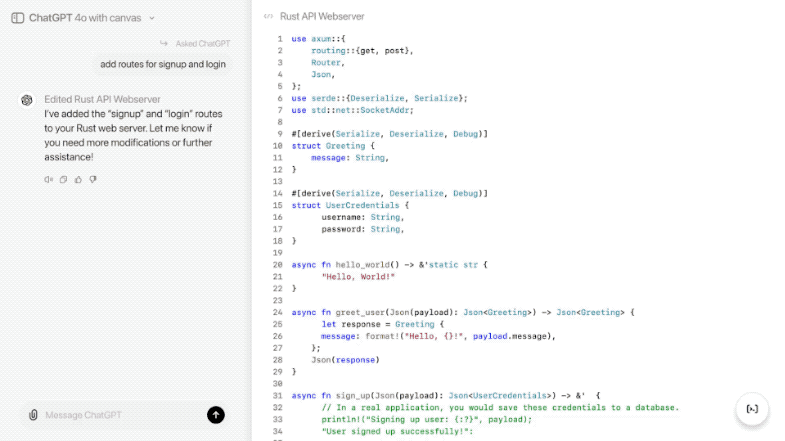
汇编代码传递数据的机制令人费解.而这部分内容又是比较基础的,需要有个清楚的认识,所以专门列一篇帖子来探索.move指令和leaq指令的区别,其他指令可以类比这两个指令.
本贴主要讲几个方面内容:move指令和leaq的对比,变量和指针的映射,以及指针的实现.
一.move指令和leaq的对比
前面理解计算机系统_程序的机器级表示(二):寄存器,操作数,数据传送,程序栈-CSDN博客提到了数据的模型,由地址和数值组成.在汇编代码的指令中,数据是以立即数和地址出现的. 所有的指令都是在yo地址(操作数指示符的内容有阐述),或以立即数形式出现.
然而在不同指令中的地址,表达的意思可能不一致,有的是地址,有的是数值.
例如:move指令操作数值;leaq指令操作地址.如图所示
笔者觉得其他指令对数据的操作可以参照这两个指令,操作数值或地址(二选一).
示例代码:
movew $0x3,0xff00 //讲0x3传给地址0xff00
movew 0xff00,%ax //讲0xff00里的数值传给%ax,此时%ax里的值是0x3
leaq 0xff00,%rax //%rax里的值是0xff00二.变量和指针的映射
计算机内部对数据的存储,只有0和1两种状态.数据模型中,地址值和数值,表达方式是一样的,通常用十六进制0x来表示.
寄存器或内存中存放的数值,由程序员的使用方式来决定他们是具体的数字还是地址.例如:
movew $0x3,0xff00
movew $0xff00,0xff40
movew 0xff40,%ax 此时%ax表示从0xff40传入的值,即0xff00.而(%rax)表示取以传进来的值0xff00,为地址的值0x3.
汇编语言中的数据和高级语言的数据表示
汇编语言中的数据,地址和数值是一体的,既没有"数据类型"这个概念(有数据长度的区分),也没有明确区分"数值"和"指针",由使用者自己解释.高级语言不但区分了数据类型,在类型相同的情况下还区分出了"变量"和"指针" . 下面试着找他们的映射关系(伪代码不保证准确只谈思路)
1>变量
以下两种写法的结果看起来差不多
//汇编指令
movew $0x3,0xff00
//c语言写法
short int a=3; 在C语言代码中,变量a的底层是一个地址0xff00,所以变量相当于给地址取了个名称.这样做的好处是方便程序员表达,以及使用者的理解.当然还有其他问题要解决,比如short类型是怎样定义的,和其他类型是怎么区分的.这个问题是编译器设计者解决的,只是使用可以不用关心.
2>指针
以下两种写法的结果差不多(忽略数据类型)
//汇编指令
movew $0x3,0xff00
leaq 0xff00,%rax
moveq %rax,0xff08 //将地址0xff00放入0xff08
movew $0x4,(0xff08) //0xff08的值等于0xff00,加括号取以0xff00为地址的值并修改为4
//c语言写法
short int a=3;
short int* p=&a;
*p=4; //修改a地址的数据为4变量a的地址0xff00,他的指针p的值被设置为0xff08.
观察一下难道不是多此一举吗?C语言中特意多用了一个字(2个字节)的空间来放地址
movew $0x4,0xff00 //替代C语言的汇编代码C语言如果在函数里,要修改传入值,就必须传入指针了,这是他的设计机制决定的..汇编直接修改内存里的值就能达到目的. 从这里也可以看出,汇编占的空间会比C语言小.
两种方式的比较
高级语言易懂,写代码更方便.底层语言工作效率更高,但编写效率低.而且C语言学了再用汇编语言写的话,会令人烦躁(属于给自己找理由,如果都会用更好).
举个例子:变量之间赋值,
C语言直接写short int b=a;汇编语言写的话,要经过寄存器(规定了内存之间不能直接赋值)
三.指针的实现
上面不是说过了指针吗?寄存器%rsp始终指向栈首元素,还要能访问栈内其他数据.就是说要实现指针指向一个数据块. 示意图如下:
代码:
//以下非代码,是想在对应地址内插入的数据,
$0x123,0xff00
$0x456,0xff08
$0x789,0xff10
//以下是操作代码
leaq 0xff10,%rsp //栈内第一个元素
movdq $0x789,(%rsp)
//入栈
subq 8,%rsp //地址值减8
movq $0x456,(%rsp) //压入数据

![[M数学] lc3164. 优质数对的总数 II(因数分解+倍增+推公式+思维+好题)](https://i-blog.csdnimg.cn/direct/195a6679824f4ce185cdc166dc73c808.png)




![【三】【算法】P1007 独木桥,P1012 [NOIP1998 提高组] 拼数,P1019 [NOIP2000 提高组] 单词接龙](https://i-blog.csdnimg.cn/direct/a00d137520a84858bc42d8846efa820b.png)