作者:彭博,上海人工智能实验室与上海交大2023级联培博士。
最近的工作已经成功地将大规模文本到图像模型扩展到视频领域,产生了令人印象深刻的结果,但计算成本高,需要大量的视频数据。在这项工作中,我们介绍了ConditionVideo,这是一种无需训练的文本到视频生成方法,基于提供的条件、视频和输入文本,通过利用现成的文本到图像生成方法(例如,Stable Diffusion)的功能。ConditionVideo从随机噪声或给定场景视频生成逼真的动态视频。我们的方法明确地将运动表示分解为条件引导和场景运动组件。为此,ConditionVideo模型设计了一个UNet分支和一个控制分支。为了提高时间相干性,我们引入了稀疏双向时空注意(sBiST-Attn)。三维控制网络扩展了传统的二维控制网络模型,旨在通过额外利用时域的双向帧来增强条件生成的准确性。我们的方法在帧一致性、片段评分和条件准确性方面表现优异,优于其他方法。目前文章已被AAAI 2024会议接收,代码已开源到Github。

Arxiv 链接:https://arxiv.org/abs/2310.07697
Github 链接: GitHub - pengbo807/ConditionVideo: Training-Free Condition-Guided Text-to-Video Generation

贡献
-
我们提出了一种无需训练的视频生成方法,该方法利用现成的文本到图像生成模型生成具有逼真动态背景的条件引导视频。
-
我们的方法通过一个包括U-Net分支和条件控制分支的pipeline,将运动表征分解为条件引导和场景运动组件
-
我们引入稀疏双向时空注意(sBiST-Attn)和三维条件控制分支,提高了条件精度和时间一致性。
方法
ConditionVideo利用引导注释(表示为 Condition)和可选参考场景(表示为Video)来生成逼真的视频。接下来,我们首先介绍我们的无训练pipeline,接着介绍我们建模运动的方法。而后,我们提出了稀疏双向时空注意(sBiST-Attn)机制。最后,我们给出3D控制分支的详细解释。
无训练采样Pipeline
图2描绘了我们提出的无训练采样Pipeline。利用从预训练的图像扩散模型的编码器解码器D(E(·)),我们逐帧在RGB空间和潜在空间之间进行视频变换。我们的ConditionVideo模型包含两个分支:一个UNet分支和一个3D控制分支。文本描述被输入到两个分支中。根据用户对定制或随机背景的偏好,UNet分支接受参考背景视频的隐层编码或随机噪声ϵ_b。条件会在加入随机噪声ϵc后被送入3D控制分支。
我们的控制分支使用ControlNet的原始权重。如图2右侧所示,我们通过使用1×3×3内核将2D卷积转换为3D,并用我们提出的sBiST-Attn模块替换self-attention模块。我们保持其他输入输出机制与之前相同。
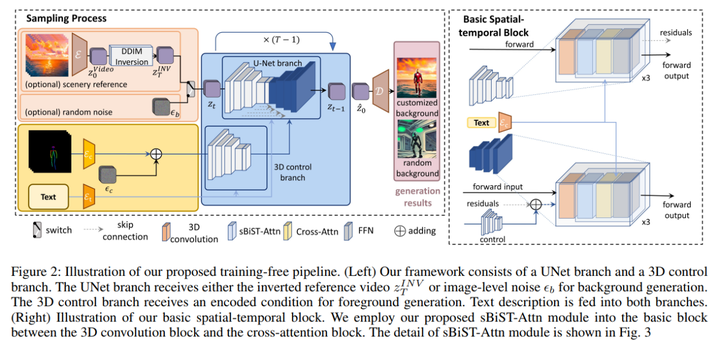
运动表征策略
在传统的生成扩散模型中,噪声向量 ϵ 是从独立同分布的高斯分布中采样的,即 ϵ ∼ N(0, I),然后被控制分支和UNet分支共享。然而,如果我们遵循原始机制,让逆向背景视频的潜在代码被两个分支共享,我们观察到背景生成结果将会模糊。这是因为使用相同的潜在代码生成前景和背景假设前景角色与背景有强烈的关系。受此启发,我们明确将视频运动表示解耦为两个组成部分:背景运动和前景运动。背景运动由UNet分支生成,其潜在代码表示为背景噪声 ϵb ∼ N(0, I)。前景运动由给定的条件注释表示,而前景的外观表示是从噪声 ϵc ∼ N(0, I)生成的。
为了实现连续生成帧之间的时间一致性,我们调查了促进创建连贯视频的选定噪声模式。通过确保控制分支产生准确的条件控制,可以建立前景生成的一致性。在生成背景时,我们可以采取两种方法。第一种是使用背景噪声 ϵb 创建背景。第二种方法是从参考风景视频的逆向潜在代码生成背景。值得注意的是,我们观察到,当原始视频经历DDIM逆转时,其中存在的动态运动相关性被保留下来。因此,我们利用这种潜在的运动相关性来生成背景视频。
在采样过程中,第一步前向过程 t = T 时,我们将背景隐变量 z_T^{INV} 或 ϵ_b 输入UNet分支,将条件 Cond 输入我们的3D控制分支。然后,在随后的逆向步骤 t = T - 1, .., 0 中,我们将去噪后的隐变量 z_t 输入UNet分支,同时仍然使用 Ccond 作为3D控制分支的输入。采样算法的详细信息展示在算法1中。

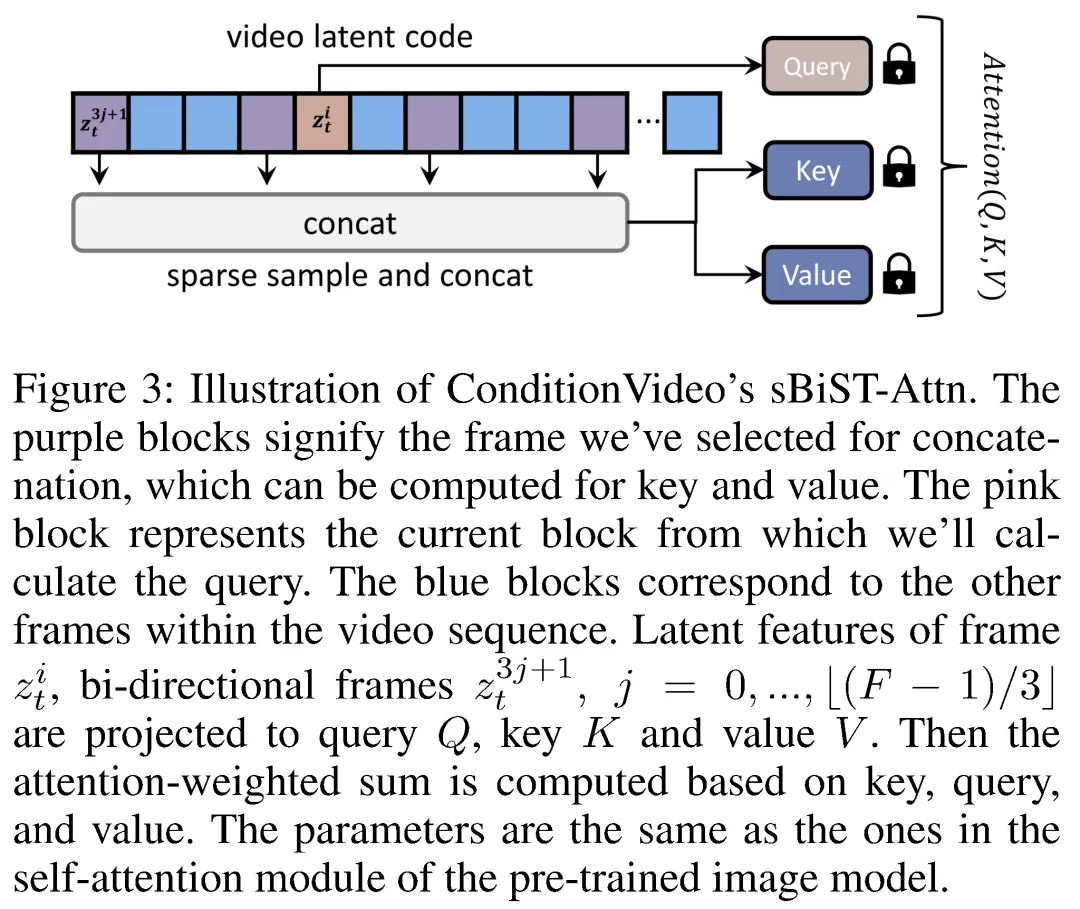
稀疏双向时空注意力机制(sBiST-Attn)
考虑到时间连贯性和计算复杂性,我们提出了一种稀疏双向时空注意机制(sBiST-Attn),如图3所示。对于视频潜在张量 zti,i = 1, ..., F,注意力矩阵是在帧 zti 及其双向帧之间计算的,采样间隔为3。这个间隔是在权衡帧一致性和计算成本之后选择的。对于 zt 中的每个 zti,我们从其帧 zit 中导出查询特征。键和值特征是从双向帧 z3j+1t 中导出的,j = 0, ..., ⌊(F - 1)/3⌋。从数学上讲,我们的 sBiST-Attn 可以表示为:
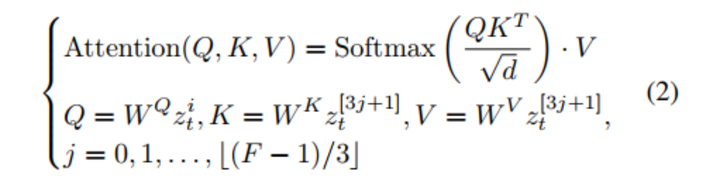

3D控制分支
逐帧条件引导通常是有效的,但有时网络可能无法正确解释引导,导致条件输出不一致。鉴于条件运动的连续性,ConditionVideo 提出通过参考相邻帧来增强条件对齐的方法。如果由于控制弱而导致某个帧未能正确对齐,其他正确对齐的帧可以提供更多实质性的条件对齐信息。有鉴于此,我们设计我们的控制分支以时间方式运行,我们选择用 sBiST-Attn 模块替换自注意模块,并将二维卷积扩展到三维。替换的注意力模块可以考虑先前和后续的帧,从而增强我们的控制效果。
实验结果
我们基于ControlNet和Stable Diffusion 1.5的预训练权重实现我们的模型。我们为每个视频生成24帧,分辨率为512×512像素。在推理过程中,我们使用与Tune-A-Video相同的采样设置。更多细节可以在https://arxiv.org/abs/2310.07697的附录D中找到。我们将我们的方法与Tune-A-Video、ControlNet和Text2Video-Zero进行比较。对于Tune-A-Video,我们首先对提取条件的视频进行微调,然后从条件视频的相应噪声潜码中进行采样。
比较实验
定性比较
我们对基于pose、canny和depth信息的视觉比较呈现在图4、5和6中。Tune-A-Video在与我们给定的条件和文本描述很好地对齐方面存在困难。ControlNet在条件对齐精度方面有所改进,但缺乏时间一致性。尽管Text2Video能够制作出质量卓越的视频,但我们仍然发现并用图中的红圈标出了一些小瑕疵。我们的模型超越了所有其他模型,展示了出色的条件对齐质量和帧一致性。

定量比较
我们使用三个指标评估所有方法:Frame Consistency,Clip Score,和Pose Accuracy。由于其他条件难以评估,我们仅使用姿势准确性评估条件一致性。不同条件的结果显示在表1中,我们在所有条件下都实现了最高的Frame Consistency和Clip Score,表明我们的方法在时间一致性和文本对齐方面表现最佳。我们的姿势-视频对齐也比其他三种技术更好。这些条件是从120个不同视频中随机生成的。

Ablation Study
我们对条件控制分支、时间模块和3D控制分支进行了消融实验,结果如图7中所示。在我们的研究中,我们单独修改每个元素进行比较分析,确保所有其他设置保持不变。

条件控制分支
我们评估了使用和不使用姿势的性能,如图7所示。没有姿势条件时,视频被固定为图像,而使用姿势控制则允许生成带有特定时间语义信息的视频。
时间模块
无训练视频生成严重依赖于有效的空间-时间建模。为了评估我们的时间注意模块的效果,我们移除了我们的sBiST-注意机制,并将其替换为非时间自注意机制、稀疏因果注意机制和稠密注意机制,稠密注意机制关注所有关键帧和值。结果展示在表3中。时间和非时间注意的比较强调了时间建模对于生成时间一致性视频的重要性。通过与稀疏因果注意机制进行比较,我们证明了ConditionVideo的sBiST注意机制的有效性,表明了将双向帧的信息融入能够比仅使用先前帧提高性能。此外,我们观察到在帧一致性方面,我们的方法与密集注意机制之间几乎没有差异,尽管后者的生成时间是我们的两倍以上。

3D控制分支
我们将我们的3D控制分支与按帧处理条件的2D版本进行了比较。对于2D分支,我们使用了原始的ControlNet条件分支。这两个控制分支在Frame Consistency,Clip Score,和Pose Accuracy方面进行了评估。表4的结果显示,我们的3D控制分支在姿势准确性方面优于2D控制分支,同时保持了相似的帧一致性和Clip Score。这证明了额外考虑双向帧可以增强姿势控制。
讨论与结论
在本文中,我们提出了ConditionVideo,这是一种无需训练即可生成生动运动视频的方法。这项技术利用了独特的运动表达,由背景视频和条件数据信息化,并利用我们的sBiST-Attn机制和3D控制分支来增强帧一致性和条件对齐能力。我们的实验表明,ConditionVideo可以制作高质量视频,这在视频生成和AI驱动的内容创建方面标志着一个重要的进步。在我们的实验中,我们发现我们的方法能够生成长视频。此外,这种方法与ControlVideo的层次采样器兼容,该采样器用于生成长视频。尽管基于条件的和时间注意在维持视频连贯性方面有效,但我们也注意到了像姿势数据这样条件稀疏的视频中的闪烁等挑战。为了解决这个问题,一个潜在的解决方案为融入更密集采样的控制输入和额外的时间相关结构。
论文链接:
https://arxiv.org/abs/2310.07697
Github 链接:
GitHub - pengbo807/ConditionVideo: Training-Free Condition-Guided Text-to-Video Generation