GR-ConvNet
文章目录
- GR-ConvNet
- 前言
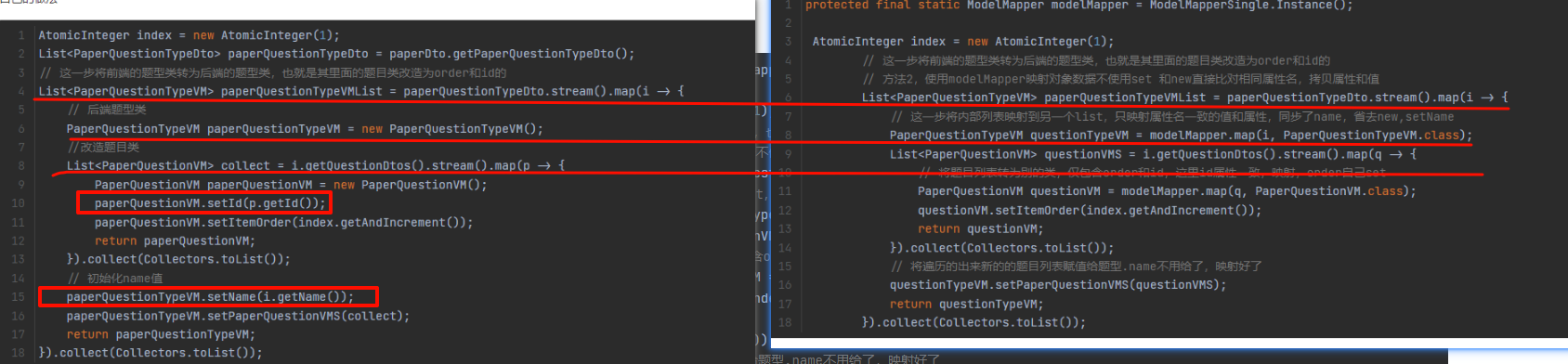
- 一、引言
- 二、相关研究
- 三、问题阐述
- 四、方法
- A.推理模块
- B.控制模块
- C.模型结构
- D.训练方法
- E.损失函数
- 五、评估
- A.数据集
- B.抓取评判标准
- 六、实验
- A.设置
- B.家庭测试物体
- C.对抗性测试物体
- D.混合物体
- 七、结果
- A.康奈尔数据集
- B.Jacquard数据集
- C.抓取新物体
- D.混合物体
- E.错误案例分析
- 八、结论
- 九、总结
前言
在这篇论文中,我们提出了一种模块化的机器系统,它可以生成以及执行对陌生物体的对映抓取。我们提出了一个全新的GR-ConvNet网络模型,它可以从n个输入通道以快速的时间去产生鲁棒的抓取。我们在标准数据集和大量的家庭物体上评估了提出的网络模型结构。我们在康奈尔和Jacquard数据集上取得了很高的精度。并且,我们也在家庭物体和陌生物体上也取得了很高的精度。使用的是7自由度的机器人臂。
一、引言
机器人操纵很出名,讲了一个故事。
对于陌生的物体(及训练时未见过的物体),我们提出了一种模块化的未知的机器人方法去抓取它。我们提出了一个GR-ConvNet网络去对一个N通道数图像的每一个像素进行对映抓取。我们使用 “生成式” 这个术语来将我们的方法与其他输出抓取概率或对抓取候选进行分类以预测最佳抓取的技术区分开来。
过去的抓取工作通常作为一个抓取矩形,并且需要从多个抓取可能中选取出最好的。与之不同的是我们的网络最终输出的是三张图片,这就使得我们可以对于多个物体进行抓取。此外,我们的网络也可以一次性地从多个物体中去推断多个抓取矩形,因此可以减少全面的计算时间。

图一将我们提出的系统结构进行了全面的展示。它由两个主要部分构成:推断模块和控制模块。
推断模块:它的输入是从RGB-D照相机中获取的RGB图像和与之相连的灰度图像。图像在进行GR-ConvNet网络前需要进行提前处理(裁剪)来匹配网络的尺寸。最终网络输出抓取质量,角度和宽度图像,我们以此来进行推断对应的抓取姿势。
控制模块:该控制模块由一个任务控制器组成,它准备并生成一个方案去通过推断模块输出的抓取姿势来完成拾取和放置任务。它通过使用轨迹规划器和控制器的 ROS(机器人操作系统)接口将所需的动作传达给机器人。
论文主要的贡献有如下几点:
a.我们提出了模块化的机器人系统,它可以对场景中的物体进行预测,计划和完成对映抓取。并且代码为开源的。
b.我们提出了一个全新的GRconv-Net网络,它可以从相机的视角预测合适的对映抓取。
c.我们在公开可使用的数据集上测试了我们的模型并且在康奈尔数据集和Jacquard取得了高达97.7%和94.6%的精度。
d.我们证明了我们所提出的模型是可以部署在机器人手臂上的,并且对于家庭和陌生物体分别达到了95.4%和93%的抓取成功率。
二、相关研究
各种抓取方法介绍。
三、问题阐述
在这个工作中,我们将问题定义为:从某个场景的N个通道数的图像中预测对映的抓取并且将其用机器人执行抓取。
不像[1][2][4]论文中的五维抓取代表,我们使用改进了的版本。
我们将机器人坐标系中的抓取姿态表示为:
其中,P=(x,y,z)是物体的中心位置,θ(r)是物体对应于Z轴的旋转量,W(r)是物体对应的抓取宽度。Q是抓取的质量分数。
我们从一个具有高度h和宽度w的n通道图像I=n×h×w中检测抓取,其可以定义为:

(x,y)对应于图像中的抓取中心,θ(i)是相机参考系中的旋转量,W(i)是物体在图像坐标系中的宽度,Q与公式一中的相同。
Q抓取质量得分表明了抓取的质量,并且它的值是在0-1之间的,越接近于1表示抓取的越成功。“Θi” 表示在每个点处抓取目标物体所需的角旋转量的对映测量值,它被表示为在区间 [−π/2,π/2] 内的值。“Wi” 是所需的宽度,它以均匀深度的度量来表示,并且被表示为在 [0,Wmax] 像素范围内的值。Wmax 是对映夹具的最大宽度。
为了完成图像到机器人的转化,我们使用接下来的公式去将图像相关的数据转化为机器人参考系。

Tci是使用相机固有的参数将图片空间转化进相机的3D空间的转化公式。
Trc通过相机姿势校准值将相机空间转化如机器人空间。
这种方法可被用到一张图像的多个抓取中。所有的抓取集合可以被表为:

θ,W,和Q代表了抓取角度,抓取宽度和抓取得分三张图像,使用公式二可以分别计算出图像中每个像素的值。
四、方法
我们提出了一个多模块化的系统去对场景中的物体进行预测,计划和执行对映抓取。所提出系统的结构详细为图1。推理模块被用来对相机视野中的物体去进行预测合适的抓取姿势。控制模块使用这些抓取姿势来计划和生成机器人轨道去完成对映抓取。
A.推理模块
推理模块由三部分组成。第一,输入图像经由随机裁剪,调整和规范化来进行预处理。如果输入图像有灰度图像,则将其通过[20]的方法进行修复来获取深度表示。GR-ConvNet网络的输入图像大小为224×224。我们使用的是n个通道的输入,因此输入图像的通道数并不仅仅被限制为一种特定的类型,例如RGB-only或者Depth-only。因此,可以使其匹配于各种形态的输入图像。第二部分,通过经由GR-ConvNet网络提取出的图像特征,最终输出三张图像分别代表抓取角度,抓取宽度和抓取质量得分。第三部分通过三张输出图像来推断出抓取姿势。
B.控制模块
控制模块主要包含一个任务控制器,它可以完成拾取和放置以及校准任务。控制器需要得到推理模块中输出的抓取姿势,并返回给抓取质量分数最高的那个抓取姿势。抓取姿势然后从相机坐标转化为机器人坐标,使用文献【31】的转化方法。此外,所述机器人框架中的抓取姿态通过 ROS 接口使用反向运动学的动作,用于规划执行拾取和放置的轨迹。这然后机器人执行计划的轨迹。由于我们使用的是模块化方法和 ROS 集成,因此该系统可以适应任何机械臂。
C.模型结构

图二显示出了所提出的GR-ConvNet网络模型,它是一个生成性的结构。它得到一个n维通道数的输入图像,然后以三个图像的形式输出多像素的抓取。n通道的输入图像依次通过三个卷积层,五个residual层和反卷积层来生成四张图像。这些输出图像由抓取质量得分,以cos2θ和sin2θ形式输出的所需角度和末端执行器所需的抓取宽度组成。由于对映抓取装置所需角度在【-Π/2 - Π/2】之间,所以我们使用cos2θ和sin2θ来输出独一无二的值来生成所需的角度。
卷积层对于输入图像提取出了特征。然后提取出的特征进入到了5个residual层。我们都明白,网络层数的增加可以提高精度。但是,当你超过了特定的一个层数时,可能会导致梯度消失或者维度错误,最终导致饱和和精度的下降。因此,使用residual层可以使我们更好的学习。当图像经过了这些卷积和Residual层之后,图像的大小下降到了56×56,这是很难去解码的。因此为了更好的解码和获得图像的空间特征,我们对图像通过反卷积进行上采样操作。这样,我们就可以获得和输入图像尺寸大小一样的输出图像。
我们的网络总共有1900900个参数,相比于【4】【22】【29】来说变少了。因此当使用和该装置类似的数以百万参数和复杂结构的抓取预测装置时,我们的相对来说性价比更高并且更块的。
D.训练方法

我们可以训练我们的模型端对端地学习匹配函数γ(I,D)=Gi,具体方法是通过最小化以输入图像场景为条件的的负对数似然来实现。
公式五:

模型是使用Adam优化器和标准的梯度下降和小批量SGD技术来进行训练的。学习率被设定为10的-3次方,mini-batch为8。我们使用三个随机种子来训练并且说明了它们的均值。
E.损失函数
对于我们的网络我们分析了各种的损失函数并且在训练几次后发现平滑的L1损失函数在处理梯度爆炸的效果最好。我们将其定义为:

Gi是预测值,Gi^是真实值。
五、评估
A.数据集
大型对映抓取的数据集的数量并不是很多。表二对公开可用的对映抓取的数据集做了一个总结。我们使用表中的两种数据集进行了训练和评估。第一个是康奈尔数据集,很标准。第二个是Jacquard数据集,比康奈尔大。

康奈尔数据集的扩展版由1035个640×480像素的RGB-D图像构成,其中包含240个不同的真实物体,5110个成功抓取,2909个失败抓取。带注释的真实数据由几个矩形框构成,分别代表了抓取每个物体的可能性。但是,对于我们的GR-ConvNet网络来说,这个数据集是比较小的。因此我们我们使用随机裁剪,放缩和旋转对数据集进行了增广,最终高效的获得了51k的抓取例子。在训练中只有成功的抓取才参与训练。
Jacquard数据集是建立在ShapeNet上的一个子集,ShapeNet是一个大型的CAD模型数据库。它包含了54k的RGB-D图像并且还有成功抓取姿势的注释(在一个类似的环境中)。总的来说,它包含1.1M个抓取例子。由于这个数据集足够大了,所以不需要对图像进行增广。
B.抓取评判标准
为了对于结果有一个公平的比较,我们使用了由【26】提出的矩形框评判方法去展现我们系统的表现。根据这个标准,当一个抓取满足以下两个条件时才可定义为有效抓取:
1.真实值和预测值抓取框的IoU值必须大于25%。
2.预测值和真实值抓取框 的抓取方向的偏移要小于30°。
这种标准需要一个抓取矩形框,但是我们的模型是通过公式2输出一个基于图像的Gi^来表示抓取的。因此,为了将基于图像的表示转化为矩形框的表示,对应输出图像每个像素的值都映射到与之对应的矩形框表示中。。
六、实验
在我们的实验中,我们通过以下数据来评估了我们的方法:
a.两个标准数据集
b.家庭物体
c.对抗性物体
d.混合物体
A.设置
介绍使用了什么相机,机器人臂以及在什么环境下训练的。
B.家庭测试物体
C.对抗性测试物体
D.混合物体
工业化的应用例如仓库中需要能够将多个物体单独取出,就像一片杂物一样。因此,为了测试这种情况。我们拿出60个没有见过的物体并将他们跑了10次。每次运行从先前未见过的新物体中选择一组不同的物体来创建一个杂乱的场景。如图 5 所示为一个例子。当相机视野中没有物体时,每次运行终止。
七、结果
在这部分中,我们讨论了我们实验的结果。我们在康奈尔数据集和Jacquard数据集上训练了GR-ConvNet网络并且在每个不同大小的数据,不同种类的训练数据上进行了测试,最终说明我们的模型足以处理任何物体。此外,我们发现我们的模型不仅可以对一个单独的物体进行抓取,而且可以对混乱的多个物体进行抓取。
图4展现出模型对于没有见过的物体的显著的结果。输出图像Gi由抓取质量得分Q,抓取所需角度θ,还有所需抓取角度W构成。它也包括了在RGB图像种代表物体的矩形框。
此外,我们通过衡量我们的网络在不同类型物体上的性能,展示了我们的方法相比于与其他方法的可行性。同样,我们也通过不同的输入形态来评估我们的模型。模型被测试的形态类型包括:单形态输入例如只有RGB图像或者只有深度图像,多形态输入例如RGB-D图像。表三展现出我们的网络在多形态输入时取得了更好的精度(RGB-D图像)。这可能是因为多形态输入更好的学习了图像输入的特征。
A.康奈尔数据集
我们遵循【1】,【2】,【4】,【23】,【16】中的交叉验证方法,以及基于图像的基于物体的数据划分。表三展现出我们系统相较于其他方法的长处。使用RGB-D图像在基于图像划分我们获得了最高的97.9%和基于物体划分96.6%的结果。在之前没有见过物体上取得的结果表明对于不同种类的物体我们都可以获得健壮性的抓取。在康奈尔数据集上的图像增广提高了网络的整体表现。此外,超快的20ms表明我们的模型可以适用于真实场景的抓取。
B.Jacquard数据集
对于Jacquard数据集,我们采用90%作为数据集,剩下的10%作为训练集。由于它比康奈尔大很多,所以不需要进行图像增广。我们基于多形态(RGB-D图像)和最终输出结果获得了最高的94.6%。表四说明我们的模型不仅在康奈尔数据集上获得了最高的精度,也在Jacquard数据集上取得了同样的效果。
C.抓取新物体
随着在两个标准数据集上取得了前所未有的效果,我们也采用相同的方法对真实世界中新物体进行了实验。我们使用真实世界中35个家庭物体和10个对抗性物体对模型进行了测试。每种物体在测试时都选用了10个不同的位置和方向。最终取得了很高的精度。
表5和图4的结果表明该网络有能力对之前未见过的物体进行抓取,除了透明瓶。
D.混合物体
随着对于新物体的抓取成功,我们的模型也可以对混合场景中多个物体执行多次抓取。每次run只有当场景中没有物体才可以视为结束,并且取得了 93.5%的精度。尽管模型只能在单独物体上进行训练,但它有能力去多种物体进行抓取。
E.错误案例分析
在本次实验中,只有一小部分可以被视为失败案例。对于这些案例,它们拥有极小的抓取得分并且当机械臂关闭时滑落下来的次数较多。这可能因为相机中获得的不准确的深度信息,也可能是因为抓取夹和相近的物体进行碰撞。。
另一种无法抓取的场景是透明的瓶子。这可能是因为相机由于光反射获得了准确的深度信息。但是,通过将其与RGB图像结合,最终对于透明瓶子可得到一个不错的抓取。
八、结论
对于抓取新奇的物体我们基于GR-ConvNet网络提出了一种模块化的解决方案。它使用n通道的输入数据去提取特征最终可以对图像中每个像素推断出对应的抓取框。我们评估网络使用了两个标准的数据集,最终获得了前所未有的精度。同时我们也对混乱场合中抓取新物体进行了验证。结果表明我们的系统对于之前从未见过的物体可以预测和执行准确的抓取。此外,非常小的推理时间使得我们的系统可以适用于闭环的机器人抓取。
在未来的工作中,我们将使用多种的抓取臂。对于反射物体我们也会使用深度预测技术去更好的对其抓取。这也许会提高例如透明瓶抓取的成功率。
九、总结
文章的翻译到此结束,接下来就该去啃代码了!
代码重点:数据集的读入以及预处理操作。
得分,角度,宽度图像如何得出,以及最终如何整合在一起。
函数γ如何算出的。
如何判定为有效抓取的?
验证集的划分。