-
目录说明
bin: 启动脚本
conf: 配置文件
doc: 帮助文档
drivers: 数据库连接驱动(注意不同版本驱动的存放目录差别,详见readme.md)
jdk: jdk
kdms: kdms程序
lib: 程序包
logs: 日志
result: 迁移报告
-
配置数据库连接信息
进入KDTS-CLI/conf目录下,打开application.yml文件,根据源库类型设置当前激活的源库配置(active: mysql),如下所示:
在正确设置application.yml中的active项后,打开对应配置文件(datasource-mysql.yml),按实际运行环境进行配置即可。
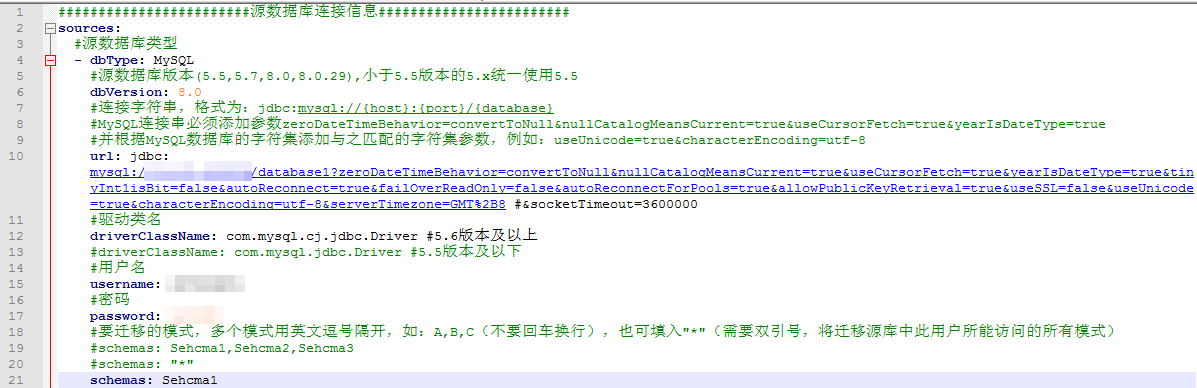
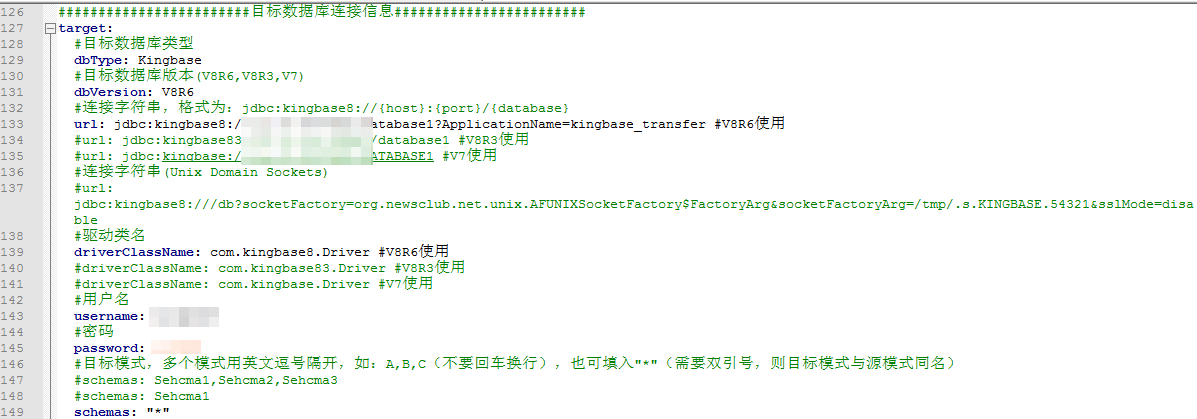
配置源端数据库连接信息、目标数据库连接信息
编辑conf/datasource-mysql.yml文件,编辑源端和目标端连接信息,包括url、driver-class-name、username、password信息,如下图所示:
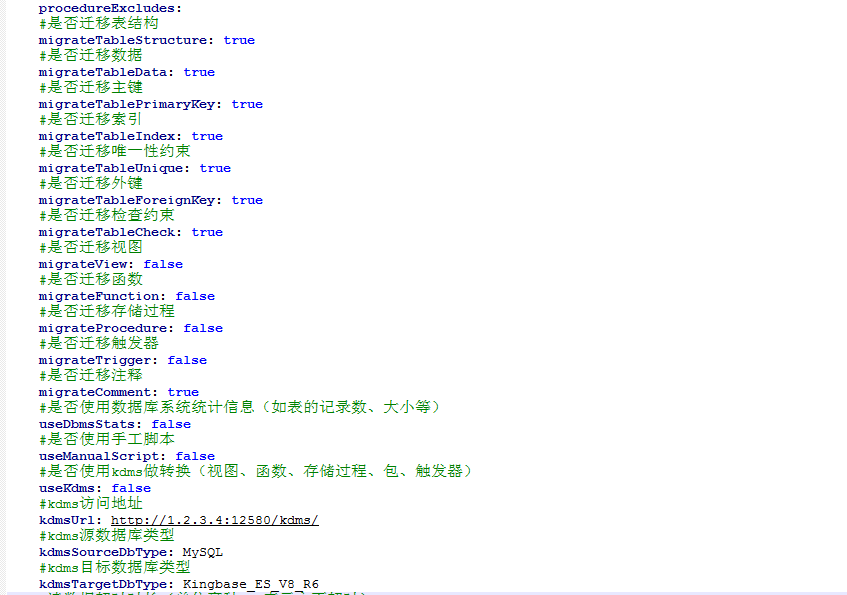
配置要迁移的源库模式,数据库对象,涉及到的参数见下图:
迁移配置参数说明
编辑conf/datasource-mysql.yml文件有多个配置参数,可灵活使用。以下列举常用的配置参数。
fetchSize:
游标提取记录数(每次和服务器交互提取的数据行数,加大该值可提升读取效率,但会增加内存开销(一次将指定数量的数据取回放在缓存中))。
tableWithLargeObjectFetchSize:
含大对象数据表的游标提取记录数(同上,只是此参数针对有大对象字段的表)。
tableWithBigLargeObjectFetchSize:
大表拆分阈值行数(当表的行数超过此值时,将对表进行拆分,每块的记录数为此值和表总记录数除以“拆分最大块数”中的最大值)。
largeTableSplitThresholdRows:
大表拆分阈值行数(当表的行数超过此值时,将对表进行拆分,每块的记录数为此值和表总记录数除以“拆分最大块数”中的最大值)。
largeTableSplitThresholdSize:
大表拆分阈值大小(单位为M)(当表的数据大小(普通字段+大对象字段)超过此值时,将对表进行拆分)。
largeTableSplitMaxChunkNum:
大表拆分最大块数(每张表的最大拆分块数,应不超过总的读线程数)。
largeTableSplitConditionFile:
大表拆分条件定义文件(优先于按行数和大小拆分)。
tableDataFilterConditionFile:
表数据过滤条件定义文件。
useKdms:
是否使用kdms做转换(视图、函数、存储过程、包、触发器)。
kdmsUrl:
kdms访问地址,前提是useKdms: true
writeBatchSize:
批量提交记录数(行数据)。
writeBatchByteSize:
批量提交数据大小(单位M)。
lobInMemoryThresholdSize:
大对象数据读入内存阈值(单位兆,默认128M)。
dropExistingObject:
删除目标库中已存在的对象(如表、视图等)。
truncateTable:
是否默认清空目标库中已存在的表数据。
renameObject:
目标数据库对象重命名,除表名、列名外的其他对象: pk、fk、constraint、unique constraint、index 等。


-
线程相关设置
线程相关设置可根据实际服务器配置按比例调整,如果与目标数据库运行在同一服务器上,应将绝大部分资源分配给数据库。
进入 KDTS-CLI/conf目录下,参照 thread-config_sample.json 文件新建 thread-config.json 文件,设置线程池配置,如下图所示:

数据迁移属于IO密集型操作,涉及网络络IO和磁盘IO的交互,一旦发生IO,线程就会处于等待状态,当IO结束,数据准备好后,线程才会继续执行。为提升数据迁移的效率可以多设置⼀些线程池中线程的数量,避免任务等待,线程可以去做更多的迁移任务,提高并发处理效率。但不是线程数设置的越高,效率就越高,线程上下文切换是有代价的。 对于IO密集型线程数的设置公式为:线程数 = CPU核心数/(1-阻塞系数) ,其中阻塞系数一般为0.8~0.9之间,取0.9则:
双核CPU: 2/(1-0.9) = 20
64核2路CPU: 64*2/(1-0.9) = 1280
-
启动脚本
-
进入 KDTS-CLI/bin 目录下,编辑: startup.sh
-
检查JDK的路径是否正确
JAVA_PATH=${BASE_PATH}/jdk
-
启动运行脚本
进入 KDTS-CLI/bin目录,执行: ./startup.sh
-
-
查看迁移报告及问题处理
可以在运行日志(kdts_plus_***.log)中查看到迁移整个过程的信息,包括任务启动、迁移进程、结果汇总
可查看result下的迁移结果(在形如“result/2021-12-02_15-15-15/Sehcma1”目录下)
index.html--报告主页面
detail_XXX.html--XXX详细信息(如表结构、表数据、表主键等)
FailedScript--失败脚本目录
IgnoredScript--略过脚本目录
SuccessScript--成功脚本目录
在迁移过程中一旦某个对象创建失败,KDTS会将该对象的创建sql保留到本次迁移任务文件夹下的FailedScript目录下*.sql文件,用户可以手动修改后通过Ksql或者KStudio工具手动执行。