作者:陈洪健:京东零售大数据架构师,深耕大数据 10 年,2019 年加入京东,主要负责 OLAP 优化、大数据传输工具生态、流批一体、SRE 建设。
当前企业数据处理广泛采用 Lambda 架构。Lambda 架构的优点是保证了数据的完整性,但缺点是系统的复杂性较高,需要维护两套系统,并且服务层的复杂合并逻辑可能会导致延迟。为了解决数据的完整性和实时性之间的矛盾,京东零售在数据架构上做出了一系列的革新。
本文将从以下四个方面展开介绍:
1. 背景和痛点
2. 迭代和优化
3. 效果和收益
4. 未来展望和规划
01 背景和痛点
1. 数据实时性和完整性的矛盾
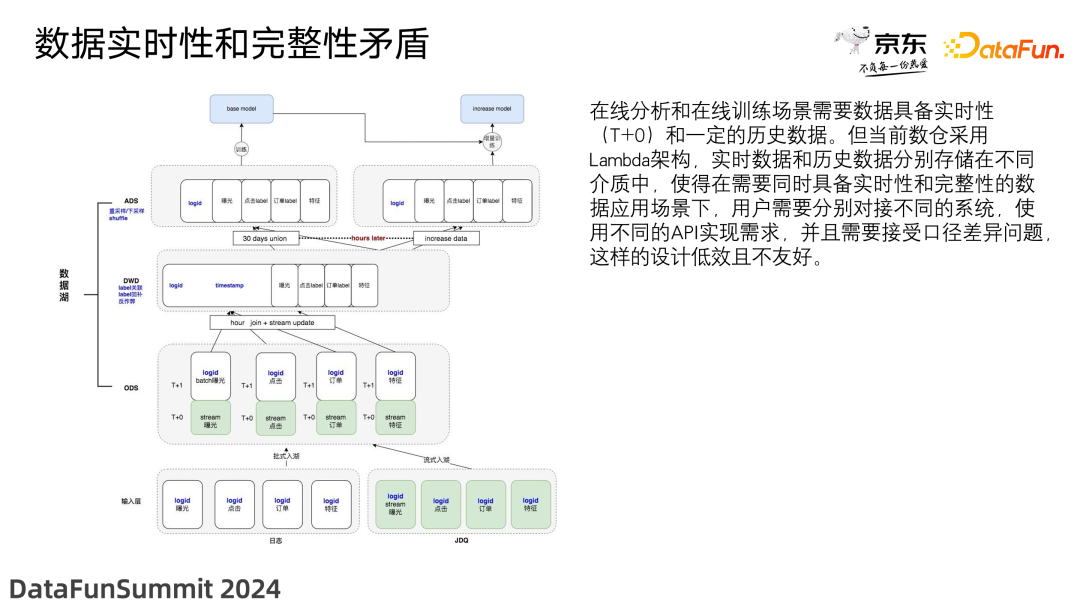
Lambda 架构设计的初衷是同时提供即时的实时数据处理和高度精确的批量数据处理,但是这种架构也带来了数据实时性和完整性的矛盾。
在线分析和在线训练场景需要数据具备实时性(T+0)和一定的历史数据。但当前实时数据和历史数据分别存储在不同介质中,使得在需要同时具备实时性和完整性的数据应用场景下,用户需要分别对接不同的系统,使用不同的 API 实现需求,并且需要接受口径差异问题,这样的设计低效且不友好。
2. 架构维护成本高
当前京东的数据处理架构分为离线处理和实时处理两条链路,离线处理的流程分为业务接入、采集服务、埋点数据存储、数据入仓、数仓 BDM 层、数仓 FDM 层、数仓 GDM 层等。实时处理的流程分为业务接入、采集服务、Kafka 缓存/Topic 划分、Flink 处理、Kafka 缓存/Topic 划分等。这样的架构存在着以下问题:
-
离线批处理的 ETL 任务繁重,当前的埋点日志入仓采用自运维的 Plumber 任务,对物理机资源有强依赖,日常需求达到百台,大促期间更需大量扩容。但整个互联网的趋势是降本增效,如何在减少物理机使用的情况下满足业务需求成为我们需要解决的问题。
-
实时数据为达到秒级处理,通常采用 Kafka+Flink 的架构实现,整体计算和存储资源消耗较高。实际业务中存在着低优先级或者实时性要求不高的场景,在目前的架构下无法灵活实现,存在资源浪费的情况。
-
离线处理的链路冗长,不含中间表的情况下,也需要至少四层的计算。另外,T+1 批处理的时间集中,如果遇到数据量级波动,网络堵塞,或者机器故障等情况,都会严重影响任务产出。比如波动时 GDM 资产完成时间可能超过 4:00,任务爆发雪崩并开始集中抢占资源,导致大量任务延迟。

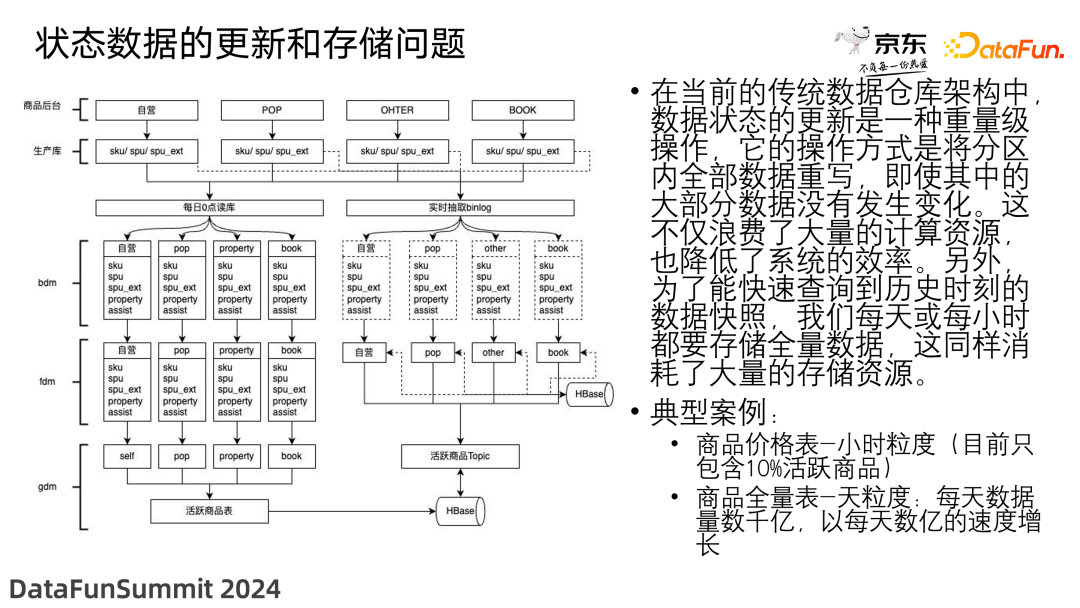
3. 状态数据的更新和存储问题
在当前的数据仓库架构中,数据状态的更新是一种重量级操作,它的操作方式是将分区内全部数据重写,即使其中的大部分数据没有发生变化。这不仅浪费了大量的计算资源,也降低了系统的效率。另外,为了能快速查询到历史时刻的数据快照,我们每天或每小时都要存储全量数据,这同样消耗了大量的存储资源。
举个例子,对于流量数据,我们通常关注 PV 和 UV,也就是累加的数量和去重的数量,那么按天增量存储就很容易计算出相应的指标,计算最近三十天的访问量只需要累加最近三十天每天的数量即可;但是对于存在 Update 场景的数据,比如每天商品都会发生增加,删除和修改,那么我们计算 SKU 和 SPU 等指标,主流解决方案就是每天加工一份商品全量表,更进一步考虑如果每天商品的变化数量只在 10%,却要按天产出全量数据,那么数据的重复存储,以及数仓中每一层的大量计算,都使得数据产出的性价比较低。
02 迭代和优化
针对上述架构、更新和存储中存在的问题,我们进行了一系列的改造。
1. 架构变更
-
流量涉及的生产库写实时 Topic:原先埋点数据采集过后写入 CFS,HDFS 接入 CFS 数据开始入仓,改造后 CFS 上的数据成为实质上的 Topic。
-
将处理的离线 MR 作业改为流处理的 Flink 作业:使用 Flink 任务采集 CFS 的 Topic 数据,来代替数仓中使用 MR 做引擎的 ETL 任务,提升数据时效。
-
将数据通过 Flink 作业写入 Hudi 表:Hudi 旨在将流处理和批处理的优势结合起来,允许处理增量数据,这意味着可以仅处理自上次查询以来发生变化的数据,而不是每次都加载整个数据集;同时提供了索引和事务的支持,如 Bloom Filter 索引和列值索引有助于查询加速,对事务的支持可以保证多并发写入下的数据一致性。
-
对数据进行逻辑加工和不同表的 JOIN,生成 GDM/RDDM 对外开放模型表。
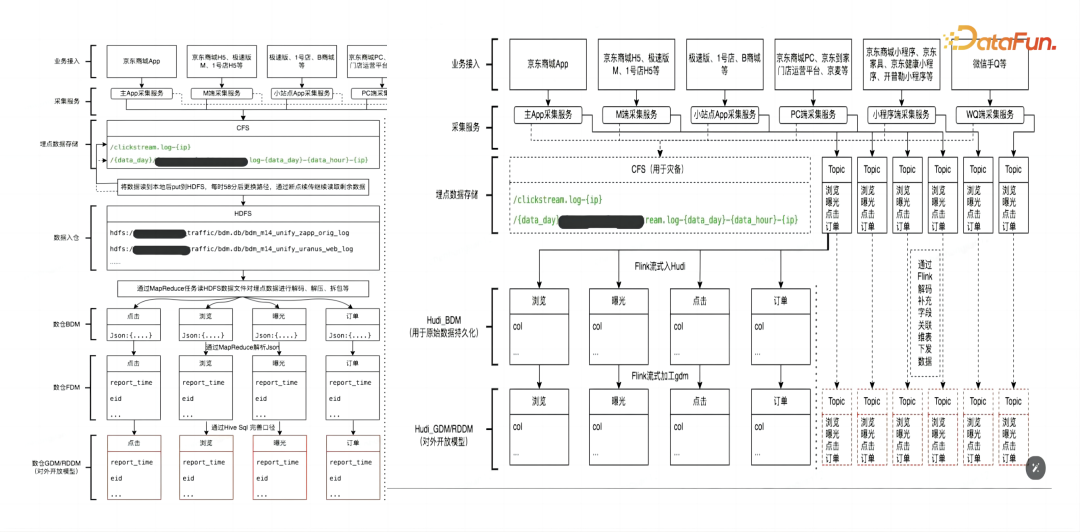
2. 多流合并
如下图所示,商品后台包括自营、pop、book 和其它一些业态,从生产库实时抽取 binlog 日志,生成对应的流。在 BDM 层,直接通过 Flink 任务将对应的 binlog 日志,变成 Hudi 的 BDM 表。在 BDM 到 FDM 层,做了一些简单的加工。再往后是全量商品表和不同维度表的更新。在这一流程中,具体的改进点如下:
(1)存储模型变为分区表+MOR+Bucket 的组合来提升性能
-
降低list 操作频次、计算离线往期分区大小,Bucket 不超过 2GB
-
为了减少小文件,将非分区表改为了分区表
-
限定保留版本数 288/分钟、25/小时(版本数*平均提交周期),定时 clean、Archive
-
Flink fdm 层'compaction.async.enabled' = 'false',spark 层创建合并任务进行异步 Compaction 操作
-
Flink 切换到 Spark 引擎 eventtime.field=ts 保持数据更新规则一致
(2)降低成本
-
多表资源复用,把原本分散在各个业务形态中的数据进行了合并处理,从而降低资源成本
-
建设 DMS 系统自动建表,表增删改统一管控收口,创建相关任务,并实现了对任务状态和异常的可视化,使异常定位和处理变得非常便捷,从而降低了人力成本
(3)数据一致性
-
数据保序:表主键 Hash 分组传输
-
数据完整性:根据 Hudi 的心跳机制和业务的时间窗去判断数据的完整性, Precombine=业务时间,多个时间编写多时间 payload 函数进行更新
(4)可持续性
-
健壮性,对数据积压、任务异常、数据时延等创建监控策略进行监控
-
元数据更新,业务变更带来的分析库结构变更
-
稳定性,实现了资源隔离,保证上游集中刷数、定时跑批时的稳定性
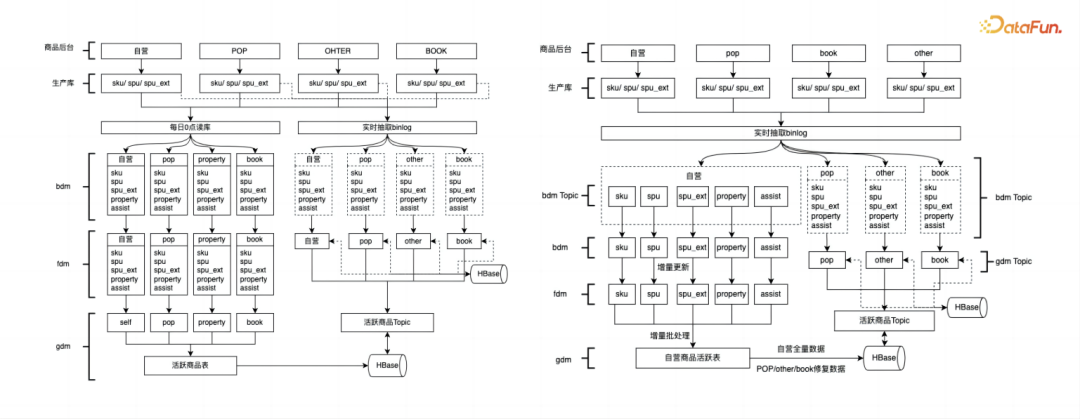
3. 外键关联
Hudi 在大表的外键关联场景下存在问题,为了保证数据的完整性和准确性,我们的解决方案是整合 Flink 和 Spark。流转批 eventtime 下发,具体做法为,每 10min 一批次,执行以下操作:
-
SKU 增量数据关联维表(SPU)全量数据
-
SPU 增量数据关联 SKU FDM 全量数据
-
union 后写入 m03 表
关联复杂降低策略:分主体进行维度建模,分层存储,对中间业态采用临时表。
过载控制:记录级限流,资源配置模型。
开发方式:FlinkSQL+SparkSQL 能力增强:
-
Hudi 维度表的能力,维表 lookup
-
MOR 表增量读优化,优先读取 Log 文件
-
Spark 与 Flink 混写一致性优化(索引、数据格式、eventtime 等)。spark 任务 compaction 数据 call run_compaction(op => 'run', path => '{path}');
-
状态后端表 TTL 设定,表级别 TTL
-
持续稳定:异常恢复、监控告警增强,对数据积压、限流、checkpoint 失败、处理流量等问题及时处理。
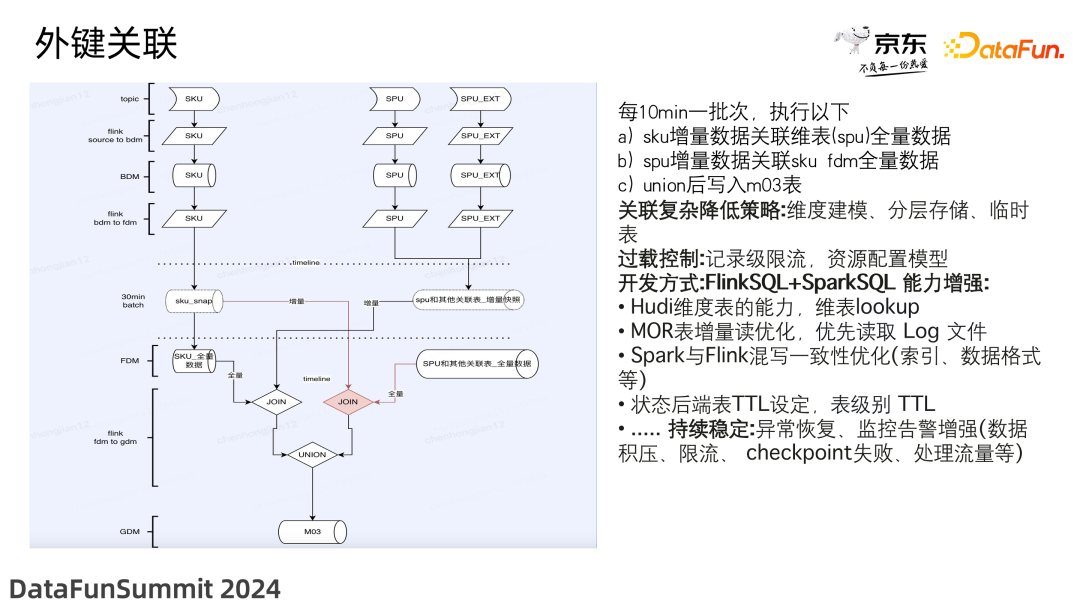
4. 查询优化
(1)数据缓存
-
Hudi 元数据缓存
-
Block 级文件缓存:通过将外部存储系统的原始数据按照一定策略切分成多个 block 后,缓存至 StarRocks 的本地 BE 节点,从而避免重复的远端数据拉取开销,实现热点数据查询分析性能的进一步提升。
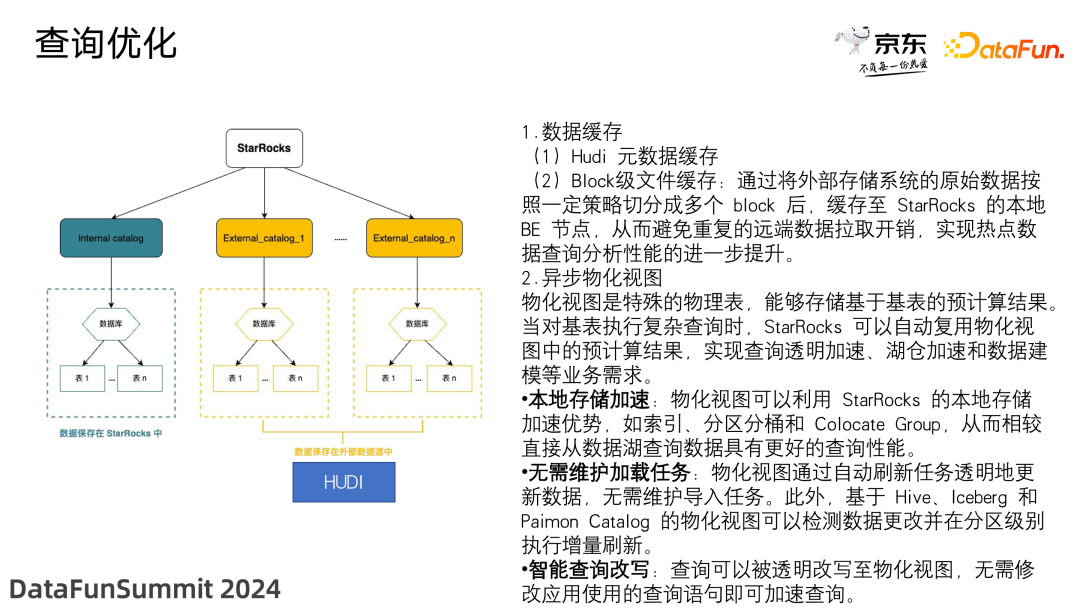
(2)异步物化视图
物化视图是特殊的物理表,能够存储基于基表的预计算结果。当对基表执行复杂查询时,StarRocks 可以自动复用物化视图中的预计算结果,实现查询透明加速、湖仓加速和数据建模等业务需求。
具体实现如下:
-
本地存储加速:物化视图可以利用 StarRocks 的本地存储加速优势,如索引、分区分桶和 Colocate Group,从而相较直接从数据湖查询数据具有更好的查询性能。
-
无需维护加载任务:物化视图通过自动刷新任务透明地更新数据,无需维护导入任务。此外,基于 Hive、Iceberg 和 Paimon Catalog 的物化视图可以检测数据更改并在分区级别执行增量刷新。
-
智能查询改写:查询可以被透明改写至物化视图,无需修改应用使用的查询语句即可加速查询。
03 效果和收益
以上介绍了我们整体架构的优化,在抽取数据时,通过 Flink 对数据进行加工,生成大表做连接时又利用了 Spark 的相关能力,最终在 BI 查询部分,又通过 StarRocks 进行了加速。这些优化为我们带来了诸多收益。
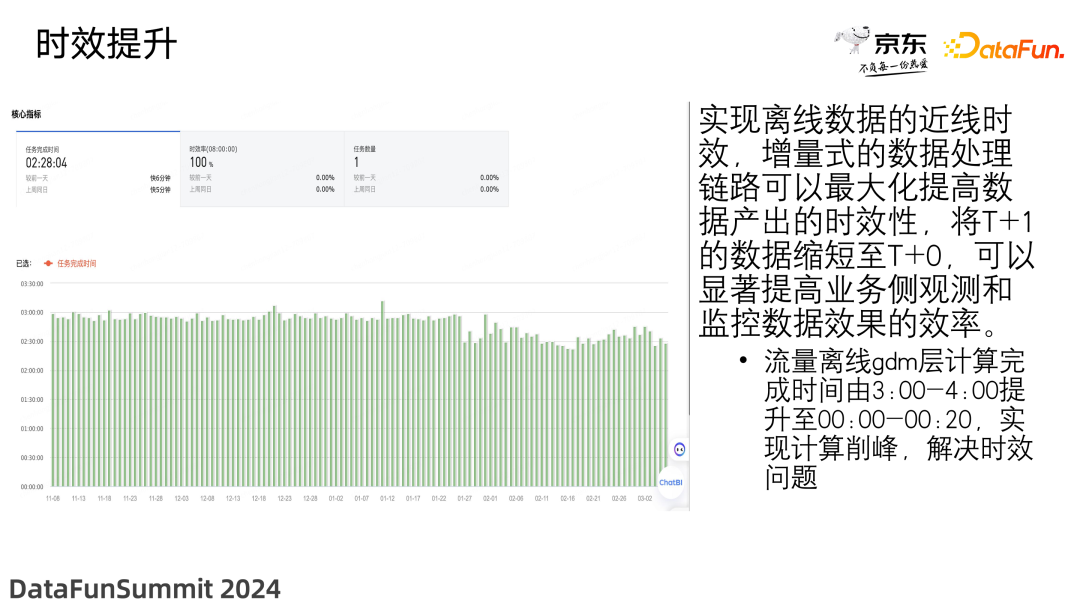
1. 时效提升
实现了离线数据的近线时效,原本 3:00-4:00 才能完成的计算现在提升到了 0:00-0:20,仅用 20 分钟即可完成。另外,通过增量式的数据处理链路,最大化地提高了数据产出的时效性。
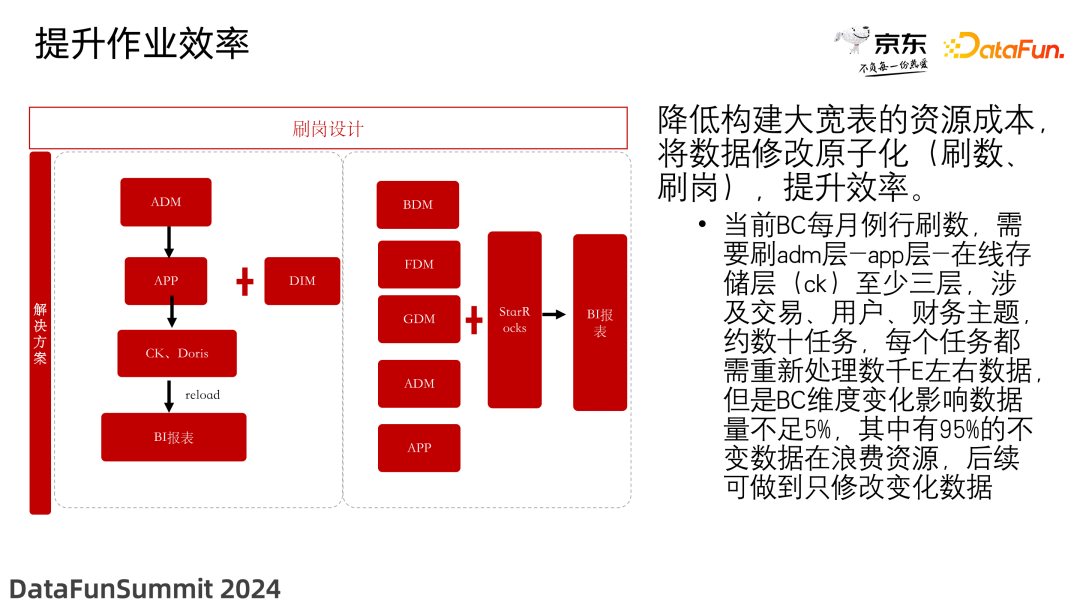
2. 作业效率提升
降低了构建大宽表的资源成本,将数据修改原子化(刷数、刷岗),使效率得到了大幅提升。当前 BC 每月例行刷数,需要刷 ADM 层-APP 层-在线存储层(ClickHouse)至少三层,涉及交易、用户、财务主题,约数十任务,每个任务都需重新处理数千 E 左右数据,但是 BC 维度变化影响数据量不足 5%,其中有 95% 的不变数据在浪费资源,后续可做到只修改变化数据。
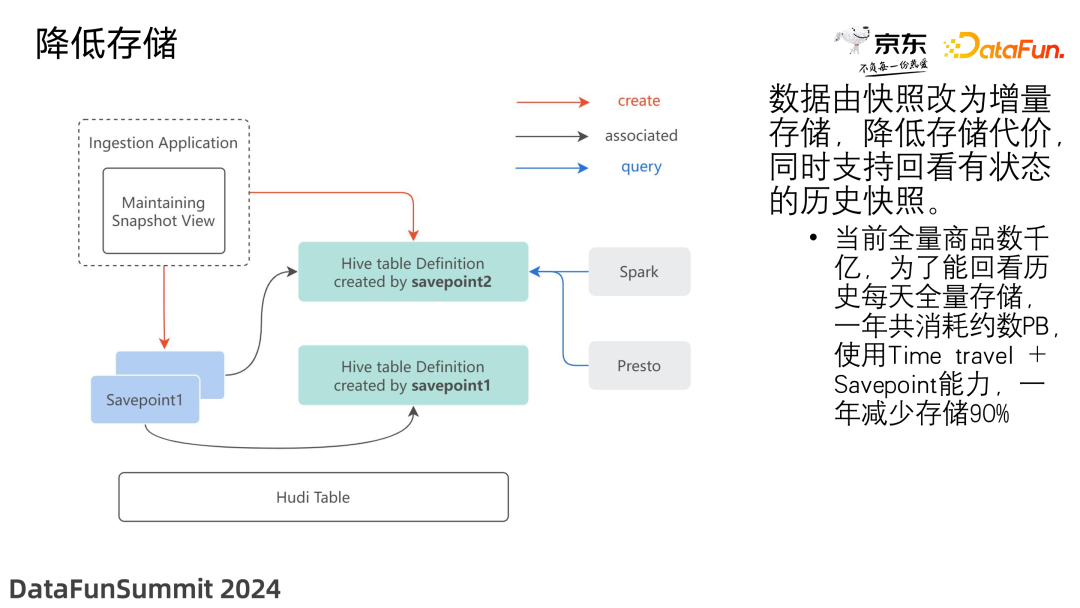
3. 存储节约
数据由快照改为增量存储,降低了存储代价,同时支持回看有状态的历史快照。当前全量商品数千亿,为了能回看历史每天全量存储,一年共消耗约数 PB,使用 Time travel +Savepoint 能力,一年减少存储 90%。
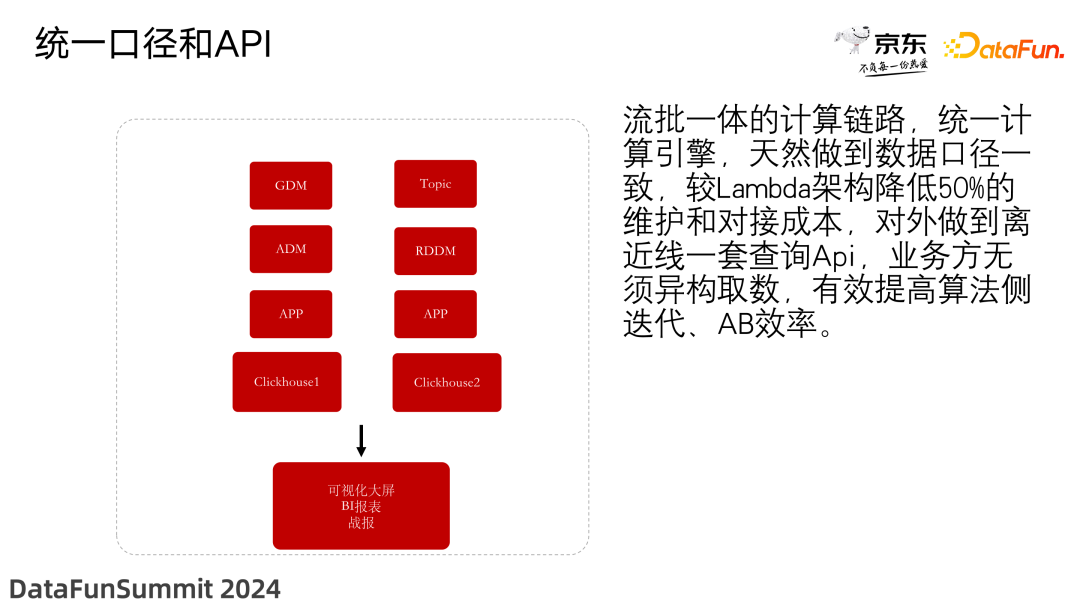
4. 统一口径和 API
采用流批一体的计算链路,统一了计算引擎,天然做到了数据口径一致,较 Lambda 架构降低了 50% 的维护和对接成本。对外实现了离近线一套查询 API,业务方无须异构取数,有效提高了算法侧迭代和 AB 实验的效率。
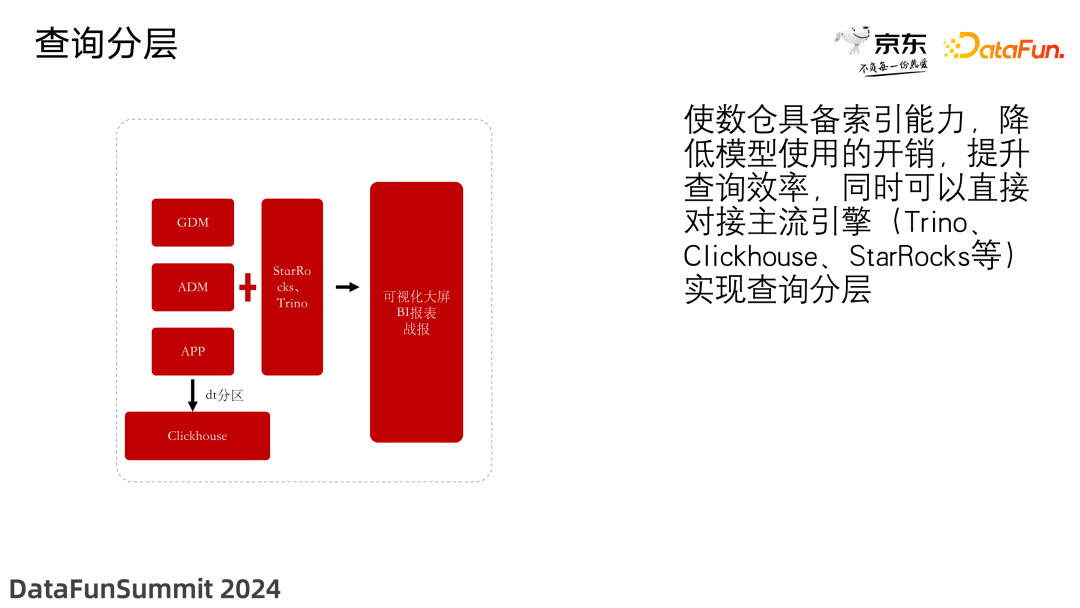
5. 查询分层
使数仓具备索引能力,降低了模型使用的开销,提升了查询效率,同时可以直接对接主流引擎(Trino、ClickHouse、StarRocks 等),实现了查询分层。
04 未来展望和规划
目前我们正在推进以下改进:
-
容灾措施(机房宕机、任务重启、数据修复等)。
-
与批任务的资源隔离,实现弹性伸缩能力,优化资源消耗。
-
针对 Hudi 流式写入带来的小文件问题,我们尝试了通过定时的 compaction,以及分桶、分区等方式,进一步将开发一些插件使问题得到自动的解决。
-
数据免疫系统建设。
-
提升 Hudi 表的自管理能力,降低维护成本。



![Unity 从零开始的框架搭建1-2 事件的发布-订阅-取消的小优化及调用对象方法总结[半干货]](https://i-blog.csdnimg.cn/direct/b4e9d85f4a6945129c10eccb094ffeeb.png)